您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本篇文章为大家展示了深入浅析Java的数据结构中的图,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
1,摘要:
从数据的表示方法来说,有二种表示图的方式:一种是邻接矩阵,其实是一个二维数组;一种是邻接表,其实是一个顶点表,每个顶点又拥有一个边列表。下图是图的邻接表表示。
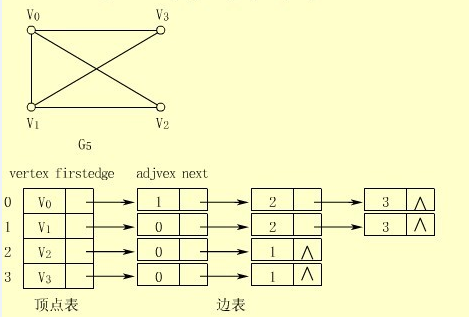
从图中可以看出,图的实现需要能够表示顶点表,能够表示边表。邻接表指是的哪部分呢?每个顶点都有一个邻接表,一个指定顶点的邻接表中,起始顶点表示边的起点,其他顶点表示边的终点。这样,就可以用邻接表来实现边的表示了。如顶点V0的邻接表如下:

与V0关联的边有三条,因为V0的邻接表中有三个顶点(不考虑V0)。
2,具体分析
先来分析边表:
在图中如何来表示一条边?很简单,就是:起始顶点指向结束顶点、就是顶点对<startVertex, endVertex>。在这里,为了考虑边带有权值的情况,单独设计一个类Edge.java,作为Vertex.java的内部类,Edge.java如下:
protected class Edge implements java.io.Serializable {
private VertexInterface<T> vertex;// 终点
private double weight;//权值Edge类中只有两个属性,vertex 用来表示顶点,该顶点是边的终点。weight 表示边的权值。若不考虑带权的情况,就不需要weight属性,那么可以直接定义一个顶点列表 来存放 终点 就可以表示边了。这是因为:这些属性是定义在Vertex.java中,而Vertex本身就表示顶点,如果在Vertex内部定义一个List存放终点,那么该List再加上Vertex所表示的顶点本身,就可以表示与起点邻接的各个点了(称之为这个 起点的邻接表)。这样的边的特点是:边的所有的起始点都相同。
但是为了表示带权的边,因此,新增加weight属性,并用类Edge来封装,这样不管是带权的边还是不带权的边都可以用同一个Edge类来表示。不带权的边将weight赋值为0即可。
再分析顶点表:
定义接口VertexInterface<T>表示顶点的接口,所有的顶点都需要实现这个接口,该接口中定义了顶点的基本操作,如:判断顶点是否有邻接点,将顶点与另一个顶点连接起来...。其次,顶点表中的每个顶点有两个域,一个是标识域:V0,V1,V2,V3 。一个是指针域,指针域指向一个"单链表"。综上,设计一个类Vertex.java 用来表示顶点,其数据域如下:
class Vertex<T> implements VertexInterface<T>, java.io.Serializable {
private T label;//标识标点,可以用不同类型来标识顶点如String,Integer....
private List<Edge> edgeList;//到该顶点邻接点的边,实际以java.util.LinkedList存储
private boolean visited;//标识顶点是否已访问
private VertexInterface<T> previousVertex;//该顶点的前驱顶点
private double cost;//顶点的权值,与边的权值要区别开来现在一一解释Vertex类中定义的各个属性:
label : 用来标识顶点,如图中的 V0,V1,V2,V3,在实际代码中,V0...V3 以字符串的形式表示,就可以用来标识不同的顶点了。
因此,需要在Vertex类中添加获得顶点标识的方法---getLabel()
public T getLabel() {
return label;
}edgeList : 存放与该顶点关联的边。从上面Edge.java中可以看到,Edge的实质是“顶点”,因为,Edge类除去wight属性,就只剩表示顶点的vertex属性了。借助edgeList,当给定一个顶点时,就可以访问该顶点的所有邻接点。因此,Vertex.java中就需要实现根据edgeList中存放的边来遍历 某条边的终点(也即相应顶点的各个邻接点) 的迭代器了。
public Iterator<VertexInterface<T>> getNeighborInterator() {
return new NeighborIterator();
}迭代器的实现如下:
/**Task: 遍历该顶点邻接点的迭代器--为 getNeighborInterator()方法 提供迭代器
* 由于顶点的邻接点以边的形式存储在java.util.List中,因此借助List的迭代器来实现
* 由于顶点的邻接点由Edge类封装起来了--见Edge.java的定义的第一个属性
* 因此,首先获得遍历Edge对象的迭代器,再根据获得的Edge对象解析出邻接点对象
*/
private class NeighborIterator implements Iterator<VertexInterface<T>>{
Iterator<Edge> edgesIterator;
private NeighborIterator() {
edgesIterator = edgeList.iterator();//获得遍历edgesList 的迭代器
}
@Override
public boolean hasNext() {
return edgesIterator.hasNext();
}
@Override
public VertexInterface<T> next() {
VertexInterface<T> nextNeighbor = null;
if(edgesIterator.hasNext()){
Edge edgeToNextNeighbor = edgesIterator.next();//LinkedList中存储的是Edge
nextNeighbor = edgeToNextNeighbor.getEndVertex();//从Edge对象中取出顶点
}
else
throw new NoSuchElementException();
return nextNeighbor;
}
@Override
public void remove() {
throw new UnsupportedOperationException();
}
}visited : 之所以给每个顶点设置一个用来标记它是否被访问的属性,是因为:实现一个数据结构,是要用它去完成某些功能的,如遍历、查找…… 而在图的遍历过程中,就需要标记某个顶点是否被访问了,因此:设置该属性以便实现这些功能。那么,也就需要定义获取顶点是否被访问的isVisited()方法了。
public boolean isVisited() {
return visited;
}previousVertex 属性 ,在求图中某两个顶点之间的最短路径时,在从起始顶点遍历过程中,需要记录下遍历到某个顶点时的前驱顶点, previousVertex 属性就派上用场了。因此,需要有判断和获取顶点的前驱顶点的方法:
public boolean hasPredecessor() {//判断顶点是否有前驱顶点
return this.previousVertex != null;
}
public VertexInterface<T> getPredecessor() {//获得前驱顶点
return this.previousVertex;
}cost 属性:用来表示顶点的权值。注意,顶点的权值与边的权值是不同的。比如求无权图(默认是边不带权值)的最短路径时,如何求出顶点A到顶点B的最短的路径?由定义,该最短路径其实就是A走到B经历的最少边数目。因此,就可以用 cost 属性来记录A到B之间的距离是多少了。比如说,A 先走到 C 再走到B;初始时,A的 cost = 0,由于 A 是 C 的前驱,A到B需要经历C,C 的 cost 就是 c.previousVertex.cost + 1,直至 B,就可以求出 A 到 B 的最短路径了。详细算法及实现将会在第二篇博客中给出。
因此,针对 cost 属性,Vertex.java需要实现的方法如下:
public void setCost(double newCost) {
cost = newCost;
}
public double getCost() {
return cost;
} 3,总结:
从上可以看出,设计一个数据结构时,该数据结构需要包含哪些属性不是随意的,而是先确定该数据结构需要完成哪些功能(如,图的DFS、BFS、拓扑排序、最短路径),这些功能的实现需要借助哪些属性(如,求最短路径需要记录每个顶点的前驱顶点,就需要 previousVertex)。然后,去定义这些属性以及关于该属性的基本操作。设计一个合适的数据结构,当借助该数据结构来实现算法时,可以有效地降低算法的实现难度和复杂度!
Vertex.java的完整代码如下:
package graph;
import java.util.Iterator;
import java.util.LinkedList;
import java.util.List;
import java.util.NoSuchElementException;
class Vertex<T> implements VertexInterface<T>, java.io.Serializable {
private T label;//标识标点,可以用不同类型来标识顶点如String,Integer....
private List<Edge> edgeList;//到该顶点邻接点的边,实际以java.util.LinkedList存储
private boolean visited;//标识顶点是否已访问
private VertexInterface<T> previousVertex;//该顶点的前驱顶点
private double cost;//顶点的权值,与边的权值要区别开来
public Vertex(T vertexLabel){
label = vertexLabel;
edgeList = new LinkedList<Edge>();//是Vertex的属性,说明每个顶点都有一个edgeList用来存储所有与该顶点关系的边
visited = false;
previousVertex = null;
cost = 0;
}
/**
*Task: 这里用了一个单独的类来表示边,主要是考虑到带权值的边
*可以看出,Edge类封装了一个顶点和一个double类型变量
*若不需要考虑权值,可以不需要单独创建一个Edge类来表示边,只需要一个保存顶点的列表即可
* @author hapjin
*/
protected class Edge implements java.io.Serializable {
private VertexInterface<T> vertex;// 终点
private double weight;//权值
//Vertex 类本身就代表顶点对象,因此在这里只需提供 endVertex,就可以表示一条边了
protected Edge(VertexInterface<T> endVertex, double edgeWeight){
vertex = endVertex;
weight = edgeWeight;
}
protected VertexInterface<T> getEndVertex(){
return vertex;
}
protected double getWeight(){
return weight;
}
}
/**Task: 遍历该顶点邻接点的迭代器--为 getNeighborInterator()方法 提供迭代器
* 由于顶点的邻接点以边的形式存储在java.util.List中,因此借助List的迭代器来实现
* 由于顶点的邻接点由Edge类封装起来了--见Edge.java的定义的第一个属性
* 因此,首先获得遍历Edge对象的迭代器,再根据获得的Edge对象解析出邻接点对象
*/
private class NeighborIterator implements Iterator<VertexInterface<T>>{
Iterator<Edge> edgesIterator;
private NeighborIterator() {
edgesIterator = edgeList.iterator();//获得遍历edgesList 的迭代器
}
@Override
public boolean hasNext() {
return edgesIterator.hasNext();
}
@Override
public VertexInterface<T> next() {
VertexInterface<T> nextNeighbor = null;
if(edgesIterator.hasNext()){
Edge edgeToNextNeighbor = edgesIterator.next();//LinkedList中存储的是Edge
nextNeighbor = edgeToNextNeighbor.getEndVertex();//从Edge对象中取出顶点
}
else
throw new NoSuchElementException();
return nextNeighbor;
}
@Override
public void remove() {
throw new UnsupportedOperationException();
}
}
/**Task: 生成一个遍历该顶点所有邻接边的权值的迭代器
* 权值是Edge类的属性,因此先获得一个遍历Edge对象的迭代器,取得Edge对象,再获得权值
* @author hapjin
*
* @param <Double> 权值的类型
*/
private class WeightIterator implements Iterator{//这里不知道为什么,用泛型报编译错误???
private Iterator<Edge> edgesIterator;
private WeightIterator(){
edgesIterator = edgeList.iterator();
}
@Override
public boolean hasNext() {
return edgesIterator.hasNext();
}
@Override
public Object next() {
Double result;
if(edgesIterator.hasNext()){
Edge edge = edgesIterator.next();
result = edge.getWeight();
}
else throw new NoSuchElementException();
return (Object)result;//从迭代器中取得结果时,需要强制转换成Double
}
@Override
public void remove() {
throw new UnsupportedOperationException();
}
}
@Override
public T getLabel() {
return label;
}
@Override
public void visit() {
this.visited = true;
}
@Override
public void unVisit() {
this.visited = false;
}
@Override
public boolean isVisited() {
return visited;
}
@Override
public boolean connect(VertexInterface<T> endVertex, double edgeWeight) {
// 将"边"(边的实质是顶点)插入顶点的邻接表
boolean result = false;
if(!this.equals(endVertex)){//顶点互不相同
Iterator<VertexInterface<T>> neighbors = this.getNeighborInterator();
boolean duplicateEdge = false;
while(!duplicateEdge && neighbors.hasNext()){//保证不添加重复的边
VertexInterface<T> nextNeighbor = neighbors.next();
if(endVertex.equals(nextNeighbor)){
duplicateEdge = true;
break;
}
}//end while
if(!duplicateEdge){
edgeList.add(new Edge(endVertex, edgeWeight));//添加一条新边
result = true;
}//end if
}//end if
return result;
}
@Override
public boolean connect(VertexInterface<T> endVertex) {
return connect(endVertex, 0);
}
@Override
public Iterator<VertexInterface<T>> getNeighborInterator() {
return new NeighborIterator();
}
@Override
public Iterator getWeightIterator() {
return new WeightIterator();
}
@Override
public boolean hasNeighbor() {
return !(edgeList.isEmpty());//邻接点实质是存储是List中
}
@Override
public VertexInterface<T> getUnvisitedNeighbor() {
VertexInterface<T> result = null;
Iterator<VertexInterface<T>> neighbors = getNeighborInterator();
while(neighbors.hasNext() && result == null){//获得该顶点的第一个未被访问的邻接点
VertexInterface<T> nextNeighbor = neighbors.next();
if(!nextNeighbor.isVisited())
result = nextNeighbor;
}
return result;
}
@Override
public void setPredecessor(VertexInterface<T> predecessor) {
this.previousVertex = predecessor;
}
@Override
public VertexInterface<T> getPredecessor() {
return this.previousVertex;
}
@Override
public boolean hasPredecessor() {
return this.previousVertex != null;
}
@Override
public void setCost(double newCost) {
cost = newCost;
}
@Override
public double getCost() {
return cost;
}
//判断两个顶点是否相同
public boolean equals(Object other){
boolean result;
if((other == null) || (getClass() != other.getClass()))
result = false;
else
{
Vertex<T> otherVertex = (Vertex<T>)other;
result = label.equals(otherVertex.label);//节点是否相同最终还是由标识 节点类型的类的equals() 决定
}
return result;
}
}上述内容就是深入浅析Java的数据结构中的图,你们学到知识或技能了吗?如果还想学到更多技能或者丰富自己的知识储备,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。