您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本篇内容介绍了“数据库邻接表有什么特点”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
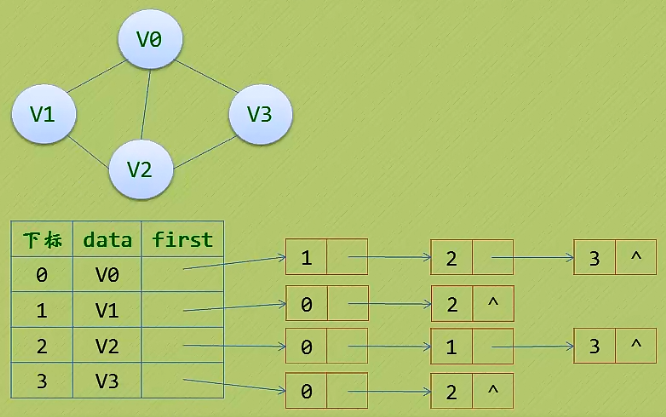
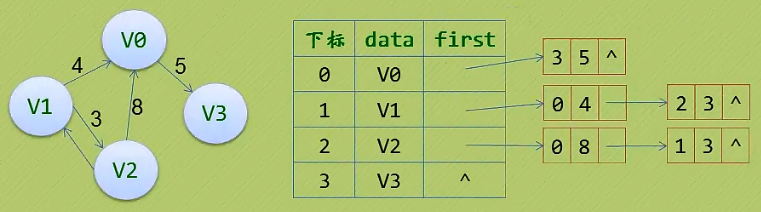
2. 邻接表(无向图)的特点:
有时候邻接矩阵并不是一个很好的选择:
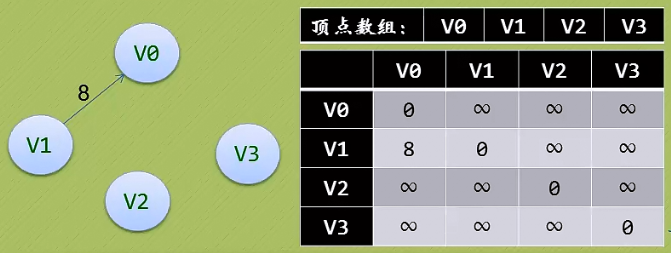
如上图: 边数相对顶点较少,这种结构无疑是存在对存储空间的极大浪费。
邻接表: 数组和链表结合一起来存储。
1.)顶点用一个一位数组存储。
2.)每个顶点Vi的所有邻接点构成一个线性表,由于邻接点的个数不确定,所以我们选择单链表来存储。
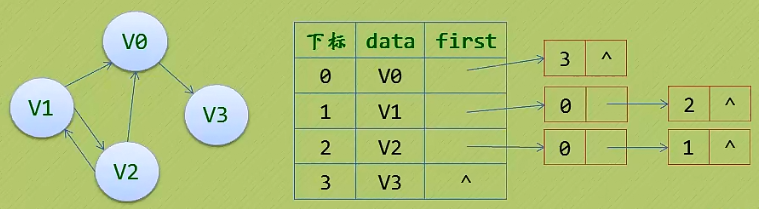
2. 邻接表(有向图)的特点:
把顶点当弧尾建立的邻接表,这样很容易就可以得到每个顶点的出度。
有时为了便于确定顶点的入度或以顶点为弧头的弧,我们可以建立一个有向图的逆邻接表:
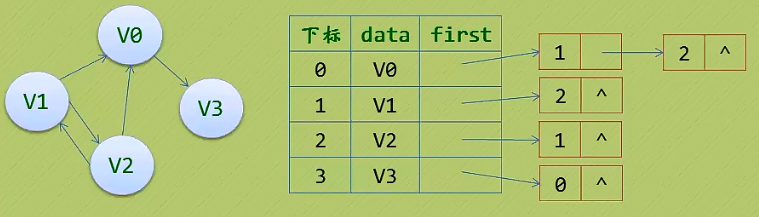
3. 邻接表(网)的特点:
对于带权值的网图,可以在边表结点定义中再增加一个数据域来存储权值即可:
typedef char Vtype //顶点类型
typedef int Etype //权值类型
#definde MAXV 100;
typedef struct edgeNode //边表节点
{
int adjvex; //邻接点 存储该顶点对应的下标
Etype weight;//边 权值
struct edgeNode *next;
}EdgeNode;
typedef struct Vnode //顶点表 节点
{
Vtype data;
EdgeNode* firstEdge;
}VNODE; //
typedef struct
{
VNODE adjlist[MAXV];
int numV;//当前顶点数
int numE;//当前边数
}GraphAdjList;
void CreateALGraph(GraphAdjList* G)
{
int i,j,k;
EdgeNode* e= NULL;
cout<<输入顶点数";
cin>>G->numV;
cout<<输入边数";
cin>>G->numE;
for(i=0;i<G->numV;i++)//建立顶点信息
{
cin >> G->adjlist[i].data; //输入顶点信息
G->adjlist[i].firstEdge = NULL; //边表节点 为空
}
for(k=0;k<numE;k++)//建立边信息
{
cout<<"输入边的开始";
cin>>i;
cout<<"输入边的结尾";
cin>>j;
e = new EdgeNode; //(1,3) 这个线的插入是相互的对于两个点1,3来说 分别不同的因此有两个new
e->adjvex = j;
e->next = G->adjlist[i].firstEdge; //类似与栈里的 node->next = list->head; list->head = node;
G->adjlist[i].firstEdge = e;
e = new EdgeNode;
e->adjvex = i;
e->next = G->adjlist[j].firstEdge;
G->adjlist[j].firstEdge = e;
}
}
对于无向图来说一条边对应都是两个顶点,所以在一次循环中就对i和j分别进行了插入 对于n个顶点e个边来说 O(n+e)
“数据库邻接表有什么特点”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。