жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
BI зі»з»ҹзҡ„еёёи§Ғз»“жһ„жҳҜпјҡеүҚз«ҜжҳҜ BI еә”з”ЁпјҢиҙҹиҙЈеӨҡз»ҙеҲҶжһҗзҡ„з”ЁжҲ·ж“ҚдҪңе’Ңз»“жһңе‘ҲзҺ°пјӣеҗҺеҸ°жҳҜж•°жҚ®еә“ / ж•°жҚ®д»“еә“пјҢиҙҹиҙЈж•°жҚ®и®Ўз®—е’ҢеӯҳеӮЁгҖӮеүҚз«Ҝе’ҢеҗҺеҸ°д№Ӣй—ҙз”Ё SQL дҪңдёәжҺҘеҸЈгҖӮ
е®һйҷ…еә”з”ЁдёӯпјҢеёёеёёеҮәзҺ°еҗҺеҸ°ж•°жҚ®д»“еә“еҺӢеҠӣиҝҮйҮҚзҡ„й—®йўҳгҖӮй—®йўҳиЎЁзҺ°дёәеүҚз«Ҝе“Қеә”ж—¶й—ҙиҝҮй•ҝпјҢж•°жҚ®д»“еә“еҸҚеә”йҖҹеәҰеҸҳж…ўгҖӮ
еёёи§Ғзҡ„и§ЈеҶіж–№жЎҲжҳҜеңЁж•°жҚ®д»“еә“е’Ңеә”з”Ёд№Ӣй—ҙеҶҚеўһеҠ дёҖдёӘеүҚзҪ®ж•°жҚ®еә“гҖӮдҪҶжҳҜеүҚзҪ®ж•°жҚ®еә“е’ҢеҗҺеҸ°ж•°жҚ®д»“еә“д№Ӣй—ҙеҫҲйҡҫе®һзҺ°ж•°жҚ®зҡ„и·Ҝз”ұе’Ңж··еҗҲи®Ўз®—пјҢдҫӢеҰӮпјҡи®ҝй—®йў‘ж¬ЎеҫҲй«ҳзҡ„зғӯзӮ№ж•°жҚ®ж”ҫеңЁеүҚзҪ®ж•°жҚ®еә“пјҢеӨ§йҮҸеҶ·ж•°жҚ®ж”ҫеңЁж•°жҚ®д»“еә“дёӯпјҢжҹҘиҜўж—¶жҢүз…§дёҖе®ҡ规еҲҷжқҘеҶіе®ҡи®ҝй—®еүҚзҪ®ж•°жҚ®еә“иҝҳжҳҜеҗҺеҸ°ж•°жҚ®д»“еә“гҖӮиҖҢеҰӮжһңеүҚзҪ®ж•°жҚ®еә“е’ҢеҗҺеҸ°ж•°жҚ®д»“еә“жҳҜдёҚеҗҢзҡ„дә§е“ҒпјҢиҝҳиҰҒиҖғиҷ‘ SQL зҡ„зҝ»иҜ‘й—®йўҳгҖӮ
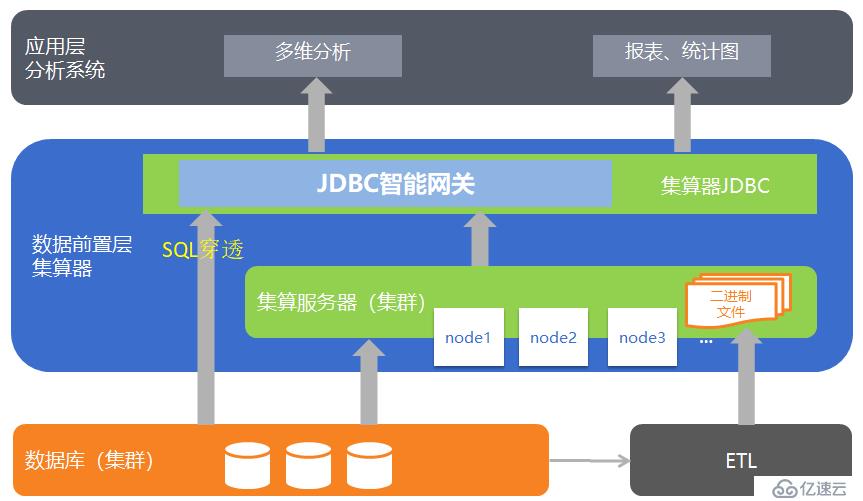
дҪңдёәж•°жҚ®и®Ўз®—дёӯй—ҙ件пјҲDCMпјүпјҢжһ„е»әзӢ¬з«Ӣзҡ„ж•°жҚ®еүҚзҪ®еұӮжҳҜйӣҶз®—еҷЁзҡ„йҮҚиҰҒеә”з”ЁжЁЎејҸгҖӮж•°жҚ®еүҚзҪ®еұӮе°Ҷ BI зі»з»ҹйҮҚжһ„дёәдёүеұӮз»“жһ„пјҡж•°жҚ®еӯҳеӮЁеҸҠжү№йҮҸж•°жҚ®и®Ўз®—еұӮз”ұж•°жҚ®еә“жүҝжӢ…пјӣж•°жҚ®еүҚзҪ®еҸҠзј“еӯҳеұӮз”ұйӣҶз®—еҷЁжүҝжӢ…пјӣж•°жҚ®еҲҶжһҗеұ•зҺ°еұӮз”ұеӨҡз»ҙеҲҶжһҗе·Ҙе…·жҲ–иҖ…жҠҘиЎЁе·Ҙе…·жүҝжӢ…гҖӮ
йӣҶз®—еҷЁеҸҜд»Ҙи„ұзҰ»ж•°жҚ®еә“иҝӣиЎҢж•°жҚ®зј“еӯҳе’ҢзӢ¬з«Ӣзҡ„еӨҚжқӮи®Ўз®—пјҢеҗҢж—¶е…·еӨҮеҸҜзј–зЁӢзҪ‘е…іжңәеҲ¶пјҢеҸҜд»ҘеңЁзј“еӯҳи®Ўз®—е’Ң SQL йҖҸдј д№Ӣй—ҙиҮӘз”ұеҲҮжҚўгҖӮеҲ©з”ЁйӣҶз®—еҷЁе®ҢжҲҗеүҚзҪ®еұӮж•°жҚ®и®Ўз®—пјҢеҸҜд»ҘдёҺж•°жҚ®еә“жүҝжӢ…зҡ„жү№йҮҸж•°жҚ®и®Ўз®—д»»еҠЎеҲҶзҰ»пјҢ并且дёҚеҝ…еҶҚе»әи®ҫеҸҰеӨ–дёҖдёӘж•°жҚ®еә“гҖӮ
йӣҶз®—еҷЁеҸҜд»Ҙе°ҶзғӯзӮ№ж•°жҚ®гҖҒиҝ‘жңҹж•°жҚ®ж”ҫеңЁж•°жҚ®еүҚзҪ®еұӮпјҢд»ҺиҖҢиө·еҲ°ж•°жҚ®зј“еӯҳзҡ„дҪңз”ЁпјҢеҸҜд»Ҙжңүж•ҲжҸҗй«ҳж•°жҚ®и®Ўз®—зҡ„йҖҹеәҰпјҢеҮҸе°‘з”ЁжҲ·зӯүеҫ…ж—¶й—ҙгҖӮ
зі»з»ҹжһ¶жһ„еӣҫеҰӮдёӢпјҡ
еүҚеҸ° BI зі»з»ҹпјҢиҰҒй’ҲеҜ№и®ўеҚ•ж•°жҚ®еҒҡиҮӘеҠ©жҹҘиҜўгҖӮжҹҘиҜўзҡ„еҝ…йҖүжқЎд»¶жҳҜи®ўиҙӯж—ҘжңҹгҖӮдёәдәҶз®ҖеҢ–иө·и§ҒпјҢеүҚеҸ° BI зі»з»ҹз”Ё tomcat жңҚеҠЎеҷЁдёӯзҡ„ jdbc.jsp жқҘжЁЎжӢҹгҖӮ
йӣҶз®—еҷЁ JDBC е’ҢжҷәиғҪзҪ‘е…ійӣҶжҲҗеңЁеә”з”Ёзі»з»ҹдёӯгҖӮjdbc.jsp жЁЎд»ҝ BI еә”з”Ёзі»з»ҹпјҢдә§з”ҹз¬ҰеҗҲйӣҶз®—еҷЁз®ҖеҚ•жҹҘиҜўи§„иҢғзҡ„ SQLпјҢйҖҡиҝҮйӣҶз®—еҷЁ JDBC жҸҗдәӨз»ҷйӣҶз®—еҷЁжҷәиғҪзҪ‘е…іеӨ„зҗҶгҖӮ
ж•°жҚ®жқҘиҮӘдәҺ ORACLE ж•°жҚ®еә“ demo дёӯзҡ„ ORDERS иЎЁгҖӮORDERS и®ўеҚ•иЎЁжҳҜе…ЁйҮҸж•°жҚ®пјҢйӣҶз®—еҷЁеҸӘеӯҳеӮЁжңҖиҝ‘дёүе№ҙзҡ„ж•°жҚ®пјҢжҜ”еҰӮпјҡ2015 е№ҙ -2018 е№ҙгҖӮж—Ҙжңҹд»Ҙи®ўиҙӯж—ҘжңҹдёәеҮҶгҖӮ
з”ЁдёӢйқўзҡ„ orders.sql ж–Ү件еңЁ ORACLE ж•°жҚ®еә“дёӯе®ҢжҲҗ ORDERS иЎЁзҡ„е»әиЎЁе’Ңж•°жҚ®еҲқе§ӢеҢ–гҖӮ
зӮ№еҮ»дёӢиҪҪ orders.sql
еңЁйӣҶз®—еҷЁдёӯпјҢж–°е»әдёҖдёӘж•°жҚ®жәҗ orclпјҢиҝһжҺҘ ORACLE ж•°жҚ®еә“гҖӮз”Ё SPL иҜӯиЁҖи„ҡжң¬ etl1.dfx е°ҶжңҖиҝ‘дёүе№ҙзҡ„ж•°жҚ®йў„е…ҲиҜ»еҸ–еҲ°йӣҶз®—еҷЁйӣҶж–Ү件 orders.btx дёӯгҖӮSPL и„ҡжң¬еҰӮдёӢпјҡ
| A | B | |
|---|---|---|
| 1 | =year(now())-3 | |
| 2 | =connect(вҖңorclвҖқ) | =A2.cursor@d(вҖңselect * from orders where to_char(orderdate,вҖҳyyyyвҖҷ)>=?вҖқ,A1) |
| 3 | =file(вҖңC:/tomcat6/webapps/gateway/WEB-INF/data/orders.btxвҖқ) | |
| 4 | =A3.export@z(B2) | >A2.close() |
д»Һ SPL и„ҡжң¬еҸҜд»ҘзңӢеҮәпјҢеҸӘиҰҒеңЁ A4 еҚ•е…ғж јдёӯз”ЁдёҖеҸҘ export е°ұеҸҜд»Ҙе°Ҷж•°жҚ®еә“дёӯзҡ„ж•°жҚ®еҜјеҮәеҲ°ж–Ү件дёӯгҖӮйӣҶж–Ү件жҳҜйӣҶз®—еҷЁеҶ…зҪ®зҡ„дәҢиҝӣеҲ¶ж–Үд»¶ж јејҸпјҢйҮҮз”ЁдәҶз®ҖеҚ•еҺӢзј©жңәеҲ¶пјҢзӣёеҗҢж•°жҚ®йҮҸжҜ”ж•°жҚ®еә“зҡ„еҚ з”Ёз©әй—ҙдјҡжӣҙе°ҸгҖӮ@z йҖүйЎ№иЎЁзӨәеҶҷеҮәеҸҜд»ҘеҲҶж®өзҡ„ж–Ү件пјҢеҫҲйҖӮеҗҲеёёеёёйңҖиҰҒ并иЎҢзҡ„еӨҡз»ҙеҲҶжһҗзұ»иҝҗз®—гҖӮ
B2 еҚ•е…ғж јдёӯж•°жҚ®еә“жёёж Үзҡ„ @d йҖүйЎ№пјҢиЎЁзӨәд»Һ ORACLE ж•°жҚ®еә“дёӯеҸ–ж•°зҡ„ж—¶еҖҷе°Ҷ numeric еһӢж•°жҚ®иҪ¬жҚўжҲҗ double еһӢпјҢзІҫеәҰеҜ№дәҺйҮ‘йўқиҝҷж ·зҡ„еёёи§Ғж•°еҖје®Ңе…Ёи¶іеӨҹдәҶгҖӮеҰӮжһңжІЎжңүиҝҷдёӘйҖүйЎ№е°ұдјҡй»ҳи®ӨиҪ¬жҚўжҲҗ big decimal еһӢж•°жҚ®пјҢи®Ўз®—жҖ§иғҪдјҡеҸ—еҲ°иҫғеӨ§еҪұе“ҚгҖӮ
и„ҡжң¬еҸҜд»Ҙз”Ё windows жҲ–иҖ… linux е‘Ҫд»ӨиЎҢзҡ„ж–№ејҸжү§иЎҢпјҢз»“еҗҲе®ҡж—¶д»»еҠЎпјҢеҸҜд»Ҙе®ҡж—¶жү§иЎҢжү№йҮҸд»»еҠЎгҖӮwindows е‘Ҫд»ӨиЎҢзҡ„и°ғз”Ёж–№ејҸжҳҜпјҡ
C:\Program Files\raqsoft\esProc\bin>esprocx.exe C: \etl1.dfx
linux е‘Ҫд»ӨжҳҜ:
/raqsoft/esProc/bin/esprocx.sh /gateway/etl1.dfx
йӣҶз®—еҷЁ JDBC жҷәиғҪзҪ‘е…іжҺҘ收еҲ° SQL еҗҺпјҢиҪ¬з»ҷ gateway1.dfx зЁӢеәҸеӨ„зҗҶгҖӮgateway1.dfx еҲӨж–ӯжҳҜеҗҰдёүе№ҙеҶ…зҡ„жҹҘиҜўпјҢеҰӮжһңжҳҜпјҢе°ұжҠҠиЎЁеҗҚжҚўжҲҗж–Ү件еҗҚпјҢжҹҘжң¬ең°ж–Ү件 orders.btx иҝ”еӣһз»“жһңгҖӮеҰӮжһңдёҚжҳҜпјҢжҠҠ SQL иҪ¬жҚўжҲҗ ORACLE ж јејҸпјҢжҸҗдәӨж•°жҚ®еә“еӨ„зҗҶгҖӮ
1гҖҒдёӢйқўзҡ„ gateway зӣ®еҪ•еӨҚеҲ¶еҲ° tomcat зҡ„еә”з”Ёзӣ®еҪ•гҖӮ
зӮ№еҮ»дёӢиҪҪ gateway.zip
зӣ®еҪ•з»“жһ„еҰӮдёӢеӣҫпјҡ
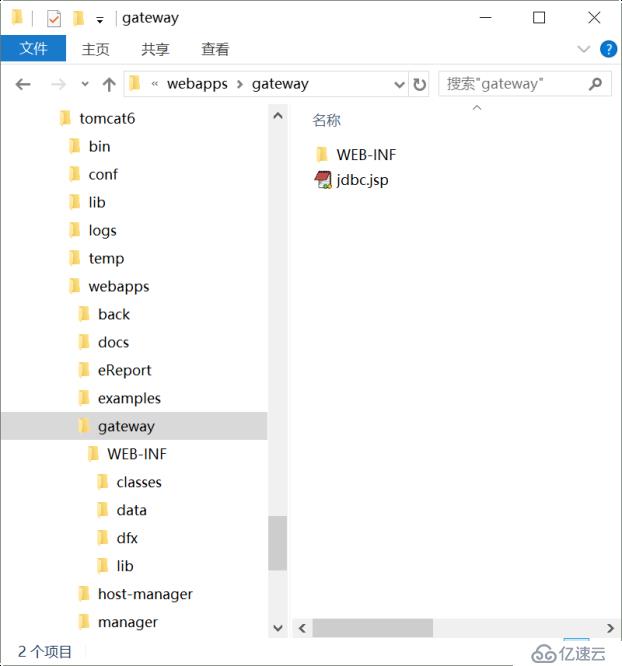
жіЁж„Ҹпјҡй…ҚзҪ®ж–Ү件еңЁ classes дёӯпјҢеңЁе®ҳзҪ‘дёҠиҺ·еҸ–зҡ„жҺҲжқғж–Ү件д№ҹиҰҒж”ҫеңЁ classes зӣ®еҪ•дёӯгҖӮйӣҶз®—еҷЁзҡ„ Jar еҢ…иҰҒж”ҫеңЁ lib зӣ®еҪ•дёӯпјҲйңҖиҰҒе“Әдәӣ jar иҜ·еҸӮз…§йӣҶз®—еҷЁж•ҷзЁӢпјүгҖӮеҸҰеӨ–пјҢиҝҳйңҖиҰҒжЈҖжҹҘе’Ңдҝ®ж”№ raqsoftConfig.xml дёӯзҡ„еҰӮдёӢй…ҚзҪ®пјҡ
<mainPath>C:\\\tomcat6\\\webapps\\\gateway\\\WEB-INF\\\dfx\\</mainPath> <JDBC> <load>Runtime,Server\\</load> <gateway>gateway1.dfx\\</gateway> </JDBC> <mainPath>C:\\tomcat6\\webapps\\gateway\\WEB-INF\\dfx\</mainPath> <JDBC> <load>Runtime,Server\</load> <gateway>gateway1.dfx\</gateway> </JDBC><mainPath>C:\\\tomcat6\\\webapps\\\gateway\\\WEB-INF\\\dfx\\</mainPath><JDBC><load>Runtime,Server\\</load><gateway>gateway1.dfx\\</gateway> </JDBC> <mainPath>C:\\tomcat6\\webapps\\gateway\\WEB-INF\\dfx\</mainPath><JDBC><load>Runtime,Server\</load><gateway>gateway1.dfx\</gateway></JDBC>
иҝҷйҮҢж Үзӯҫзҡ„еҶ…е®№е°ұжҳҜзҪ‘е…і dfx ж–Ү件гҖӮеңЁ BI зі»з»ҹдёӯи°ғз”ЁйӣҶз®—еҷЁ JDBC ж—¶пјҢжүҖжү§иЎҢзҡ„ SQL йғҪе°ҶдәӨз”ұзҪ‘е…іж–Ү件еӨ„зҗҶгҖӮеҰӮжһңдёҚй…ҚзҪ®иҝҷдёӘж ҮзӯҫпјҢJDBC жҸҗдәӨзҡ„иҜӯеҸҘйғҪиў«йӣҶз®—еҷЁеҪ“дҪңи„ҡжң¬зӣҙжҺҘи§Јжһҗиҝҗз®—пјҢиҖҢж— жі•е®һзҺ°еёҢжңӣзҡ„и·Ҝз”ұ规еҲҷгҖӮ
2гҖҒзј–иҫ‘ gateway зӣ®еҪ•дёӯзҡ„ jdbc.jspпјҢжЁЎжӢҹеүҚеҸ°з•ҢйқўжҸҗдәӨ sql еұ•зҺ°з»“жһңгҖӮ
<%@ page language="java" import="java.util.*" pageEncoding="utf-8"%>
<%@ page import="java.sql.*" %>
<body>
<%
String driver = "com.esproc.jdbc.InternalDriver";
String url = "jdbc:esproc:local\\://";
try {
Class.forName(driver);
Connection conn = DriverManager.getConnection(url);
Statement statement = conn.createStatement();
String sql ="select top 10 ORDERID,CUSTOMERID,EMPLOYEEID,ORDERDATE,AMOUNT from ORDERS where ORDERDATE=date('2015-07-18') and AMOUNT>100
";
out.println("Data gateway test page v1 <br><br><br><pre>");
out.println("и®ўеҚ•ID"+"\\\t"+"е®ўжҲ·ID"+"\\\t"+"йӣҮе‘ҳID"+"\\\t"+"и®ўиҙӯж—Ҙжңҹ"+"\\\t"+"и®ўеҚ•йҮ‘йўқ"+"<br>");
ResultSet rs = statement.executeQuery(sql);
int f1,f6;
String f2,f3,f4;
float f5;
while (rs.next()) {
f1 = rs.getInt("ORDERID");
f2 = rs.getString("CUSTOMERID");
f3 = rs.getString("EMPLOYEEID");
f4 = rs.getString("ORDERDATE");
f5 = rs.getFloat("AMOUNT");
out.println(f1+"\\\t"+f2+"\\\t"+f3+"\\\t"+f4+"\\\t"+f5+"\\\t"+"<br>");
}
out.println("</pre>");
rs.close();
conn.close();
} catch (ClassNotFoundException e) {
System.out.println("Sorry,can`t find the Driver!");
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
%>
</body>
<%@ page language="java" import="java.util.*" pageEncoding="utf-8"%>
<%@ page import="java.sql.*" %>
<body>
<%
String driver = "com.esproc.jdbc.InternalDriver";
String url = "jdbc:esproc:local\://";
try {
Class.forName(driver);
Connection conn = DriverManager.getConnection(url);
Statement statement = conn.createStatement();
String sql ="select top 10 ORDERID,CUSTOMERID,EMPLOYEEID,ORDERDATE,AMOUNT from ORDERS where ORDERDATE=date('2015-07-18') and AMOUNT>100
";
out.println("Data gateway test page v1 <br><br><br><pre>");
out.println("и®ўеҚ•ID"+"\\t"+"е®ўжҲ·ID"+"\\t"+"йӣҮе‘ҳID"+"\\t"+"и®ўиҙӯж—Ҙжңҹ"+"\\t"+"и®ўеҚ•йҮ‘йўқ"+"<br>");
ResultSet rs = statement.executeQuery(sql);
int f1,f6;
String f2,f3,f4;
float f5;
while (rs.next()) {
f1 = rs.getInt("ORDERID");
f2 = rs.getString("CUSTOMERID");
f3 = rs.getString("EMPLOYEEID");
f4 = rs.getString("ORDERDATE");
f5 = rs.getFloat("AMOUNT");
out.println(f1+"\\t"+f2+"\\t"+f3+"\\t"+f4+"\\t"+f5+"\\t"+"<br>");
}
out.println("</pre>");
rs.close();
conn.close();
} catch (ClassNotFoundException e) {
System.out.println("Sorry,can`t find the Driver!");
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
%>
</body><%@ page language="java" import="java.util.*" pageEncoding="utf-8"%>
<%@ page import="java.sql.*" %>
<body>
<%
String driver = "com.esproc.jdbc.InternalDriver";
String url = "jdbc:esproc:local\\://";try {
Class.forName(driver);
Connection conn = DriverManager.getConnection(url);
Statement statement = conn.createStatement();
String sql ="select top 10 ORDERID,CUSTOMERID,EMPLOYEEID,ORDERDATE,AMOUNT from ORDERS where ORDERDATE=date('2015-07-18') and AMOUNT>100
";out.print
ln("Data gateway test page v1 <br><br><br><pre>");out.println("и®ўеҚ•ID"+"\\\t"+"е®ўжҲ·ID"+"\\\t"+"йӣҮе‘ҳID"+"\\\t"+"и®ўиҙӯж—Ҙжңҹ"+"\\\t"+"и®ўеҚ•йҮ‘йўқ"+"<
br>");
ResultSet rs = statement.executeQuery(sql);int f1,f6;
String f2,f3,f4;float f5;while (rs.next()) {
f1 = rs.getInt("ORDERID");
f2 = rs.getString("CUSTOMERID");
f3 = rs.getString("EMPLOYEEID");
f4 = rs.getString("ORDERDATE");
f5 = rs.getFloat("AMOUNT");out.println(f1+"\\\t"+f2+"\\\t"+f3+"\\\t"+f4+"\\\t"+f5+"\\\t"+"<br>");
}out.println("</pre>");
rs.close();
conn.close();
} catch (ClassNotFoundException e) {
System.out.println("Sorry,can`t find the Driver!");
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
%>
</body>
<%@ page language="java" import="java.util.*" pageEncoding="utf-8"%>
<%@ page import="java.sql.*" %>
<body>
<%
String driver = "com.esproc.jdbc.InternalDriver";
String url = "jdbc:esproc:local\://";try {
Class.forName(driver);
Connection conn = DriverManager.getConnection(url);
Statement statement = conn.createStatement();
String sql ="select top 10 ORDERID,CUSTOMERID,EMPLOYEEID,ORDERDATE,AMOUNT from ORDERS where ORDERDATE=date('2015-07-18') and AMOUNT>100"
;out.print
ln("Data gateway test page v1 <br><br><br><pre>");out.println("и®ўеҚ•ID"+"\\t"+"е®ўжҲ·ID"+"\\t"+"йӣҮе‘ҳID"+"\\t"+"и®ўиҙӯж—Ҙжңҹ"+"\\t"+"и®ўеҚ•йҮ‘йўқ"+"<br>");
ResultSet rs = statement.executeQuery(sql);int f1,f6;
String f2,f3,f4;float f5;while (rs.next()) {
f1 = rs.getInt("ORDERID");
f2 = rs.getString("CUSTOMERID");
f3 = rs.getString("EMPLOYEEID");
f4 = rs.getString("ORDERDATE");
f5 = rs.getFloat("AMOUNT");out.println(f1+"\\t"+f2+"\\t"+f3+"\\t"+f4+"\\t"+f5+"\\t"+"<br>");
}out.println("</pre>");
rs.close();
conn.close();
} catch (ClassNotFoundException e) {
System.out.println("Sorry,can`t find the Driver!");
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
%>
</body>еҸҜд»ҘзңӢеҲ°пјҢjsp дёӯе…ҲиҝһжҺҘйӣҶз®—еҷЁзҡ„ JDBCпјҢ然еҗҺжҸҗдәӨжү§иЎҢ SQLгҖӮжӯҘйӘӨе’ҢдёҖиҲ¬зҡ„ж•°жҚ®еә“е®Ңе…ЁдёҖж ·пјҢе…·жңүеҫҲй«ҳзҡ„е…је®№жҖ§е’ҢйҖҡз”ЁжҖ§гҖӮеҜ№дәҺ BI е·Ҙе…·жқҘиҜҙпјҢиҷҪ然жҳҜз•Ңйқўж“ҚдҪңжқҘиҝһжҺҘ JDBC е’ҢжҸҗдәӨ SQLпјҢдҪҶжҳҜеҹәжң¬еҺҹзҗҶе’Ң jsp е®Ңе…ЁдёҖж ·гҖӮ
3гҖҒжү“ејҖ dfx зӣ®еҪ•дёӯзҡ„ gateway1.dfxпјҢи§ӮеҜҹзҗҶи§Ј SPL д»Јз ҒгҖӮ
йҰ–е…ҲпјҢеҸҜд»ҘзңӢеҲ° gateway1.dfx дј е…ҘеҸӮж•°жҳҜ sql е’Ң argsпјҢдҫӢеҰӮдј е…Ҙ SQLпјҡ
select top 10 ORDERID,CUSTOMERID,EMPLOYEEID,ORDERDATE,AMOUNT from ORDERS where ORDERDATE=date(вҖҳ2015-07-18вҖҷ) and AMOUNT>100гҖӮ
жҺҘдёӢжқҘпјҢеҸҜд»ҘзңӢеҲ° SPL и„ҡжң¬еҰӮдёӢпјҡ
| A | B | C | |
|---|---|---|---|
| 1 | =filename=вҖңC:/tomcat6/webapps/gateway/WEB-INF/data/orders.btxвҖқ | ||
| 2 | =sql.sqlparse@w().split(" ") | =A2.select@1(like(~,вҖңORDERDATE=date(вҖҳ????-??-??вҖҷ)вҖқ)) | |
| 3 | =mid(right(B2,14),3,10) | =year(now())-year(date(A3)) | |
| 4 | if B3<=3 | =connect() | =sql=replace(sql,вҖңfrom ORDERSвҖқ,"from "+filename) |
| 5 | =B4.cursor@x(sql) | return B5 | |
| 6 | else | =connect(вҖңorclвҖқ) | =sql=sql.sqltranslate(вҖңORACLEвҖқ) |
| 7 | =B6.cursor@x(sql) | return B7 |
иҜҙжҳҺпјҡ
A1пјҡе®ҡд№үйӣҶз®—еҷЁйӣҶж–Ү件зҡ„з»қеҜ№и·Ҝеҫ„гҖӮ
A2пјҡи§Јжһҗ SQLпјҢиҺ·еҸ– where еӯҗеҸҘпјҢ并用з©әж јжқҘжӢҶеҲҶжҲҗеәҸеҲ—гҖӮ
B2гҖҒA3пјҡеңЁ A2 еәҸеҲ—жүҫеҲ°еҝ…йҖүжқЎд»¶и®ўиҙӯж—ҘжңҹпјҢиҺ·еҸ–ж—ҘжңҹеҖјгҖӮ
B3пјҡи®Ўз®—и®ўиҙӯж—Ҙжңҹзҡ„е№ҙд»Ҫе’ҢеҪ“еүҚж—Ҙжңҹе№ҙд»Ҫзӣёе·®еҮ е№ҙгҖӮ
A4пјҡеҲӨж–ӯзӣёе·®зҡ„е№ҙд»ҪжҳҜеҗҰи¶…иҝҮ 3 е№ҙгҖӮ
B4-C5пјҡеҰӮжһңдёҚи¶…иҝҮ 3 е№ҙпјҢе°ұиҝһжҺҘж–Ү件系з»ҹгҖӮе°Ҷ SQL дёӯзҡ„ from и®ўеҚ•пјҢжӣҝжҚўжҲҗ from ж–Ү件еҗҚгҖӮжү§иЎҢ SQL еҫ—еҲ°жёёж Ү并иҝ”еӣһгҖӮ
B6-C7пјҡеҰӮжһңи¶…иҝҮ 3 е№ҙпјҢе°ұиҝһжҺҘж•°жҚ®еә“гҖӮе°Ҷ SQL зҝ»иҜ‘жҲҗз¬ҰеҗҲ ORACLE ж•°жҚ®еә“规иҢғзҡ„ SQL, жү§иЎҢ SQL еҫ—еҲ°жёёж Ү并иҝ”еӣһгҖӮ
4гҖҒеҗҜеҠЁ tomcatпјҢеңЁжөҸи§ҲеҷЁдёӯи®ҝй—® http://localhost:8080/gateway/jdbc.jspпјҢжҹҘзңӢз»“жһңгҖӮ

иҝҳеҸҜд»Ҙ继з»ӯжөӢиҜ•еҰӮдёӢжғ…еҶөпјҡ
(1) и¶…еҮәдёүе№ҙзҡ„жҹҘиҜў
sql =вҖңselect top 10 ORDERID,CUSTOMERID,EMPLOYEEID,ORDERDATE,AMOUNT from ORDERS where ORDERDATE=date(вҖҳ2014-07-18вҖҷ) and AMOUNT>100вҖқ;
з”ұдәҺж—Ҙжңҹ 2014 е№ҙе·Із»Ҹи¶…еҮәдёүе№ҙзҡ„йҷҗеҲ¶пјҢжүҖд»ҘеңЁ C6 дёӯ SQL дјҡиў«зҝ»иҜ‘жҲҗ ORACLE 规иҢғеҰӮдёӢпјҡ
SELECT * FROM (select ORDERID,CUSTOMERID,EMPLOYEEID,ORDERDATE,AMOUNT from ORDERS where ORDERDATE=TO_DATE(вҖҳ2014-07-18вҖҷ,вҖҳYYYY-MM-DDвҖҷ) and AMOUNT>100)t WHERE ROWNUM<=10
(2) еҲҶз»„жұҮжҖ»
sql =вҖңselect CUSTOMERID,EMPLOYEEID,sum(AMOUNT) и®ўеҚ•жҖ»йўқ,count(1) и®ўеҚ•ж•°йҮҸ from ORDERS where ORDERDATE=date(вҖҳ2015-07-18вҖҷ) group by CUSTOMERID,EMPLOYEEIDвҖқ;
(3) 并иЎҢжҹҘиҜў
sql="select /*+ parallel (4) */
top 10 ORDERID,CUSTOMERID,EMPLOYEEID,ORDERDATE,AMOUNT from ORDERS where ORDERDATE=date(вҖҳ2015-07-18вҖҷ) and AMOUNT>100"
е’Ң ORACLE зұ»дјјпјҢйӣҶз®—еҷЁз®ҖеҚ• SQL д№ҹж”ҜжҢҒ /*+ parallel (4) */ иҝҷж ·зҡ„并иЎҢжҹҘиҜўгҖӮ
第дёҖз§Қи§ЈеҶіеҠһжі•жҳҜеҲ©з”Ёеә”з”ЁжңҚеҠЎеҷЁзҡ„иө„жәҗгҖӮеңЁе№¶еҸ‘йҮҸеҫҲеӨ§пјҢжҲ–иҖ…ж•°жҚ®йҮҸеҫҲеӨ§зҡ„жғ…еҶөдёӢпјҢеә”з”ЁжңҚеҠЎеҷЁдјҡеҮәзҺ°иҫғеӨ§еҺӢеҠӣгҖӮиҝҷз§Қжғ…еҶөдёӢпјҢжҺЁиҚҗз”ЁзӢ¬з«Ӣзҡ„иҠӮзӮ№жңҚеҠЎеҷЁиҝӣиЎҢж•°жҚ®и®Ўз®—гҖӮиҠӮзӮ№жңҚеҠЎеҷЁеҸҜд»ҘиҝӣиЎҢжЁӘеҗ‘жү©еұ•пјҢеә”еҜ№еӨ§е№¶еҸ‘жҲ–еӨ§ж•°жҚ®йҮҸи®Ўз®—зҡ„еҺӢеҠӣгҖӮ
йӣҶз®—еҷЁ JDBC жҷәиғҪзҪ‘е…іжҺҘеҸ—еҲ° SQL еҗҺпјҢиҪ¬з»ҷ gateway2.dfx зЁӢеәҸеӨ„зҗҶгҖӮgateway2.dfx и°ғз”ЁиҠӮзӮ№жңҚеҠЎеҷЁдёҠзҡ„ gatewayServer2.dfx иҝӣиЎҢи®Ўз®—гҖӮgatewayServer2.dfx еҲӨж–ӯжҳҜеҗҰдёүе№ҙеҶ…зҡ„жҹҘиҜўпјҢеҰӮжһңжҳҜпјҢе°ұжҠҠиЎЁеҗҚжҚўжҲҗж–Ү件еҗҚпјҢжҹҘжң¬ең°ж–Ү件 orders.btx иҝ”еӣһз»“жһңгҖӮеҰӮжһңдёҚжҳҜдёүе№ҙеҶ…зҡ„жҹҘиҜўпјҢжҠҠ sql иҪ¬жҚўжҲҗ ORACLE ж јејҸпјҢжҸҗдәӨж•°жҚ®еә“еӨ„зҗҶгҖӮ
1гҖҒдёӢйқўзҡ„ gatewayServer зӣ®еҪ•еӨҚеҲ¶еҲ°йңҖиҰҒзҡ„зӣ®еҪ•гҖӮйӣҶз®—еҷЁзҡ„иҠӮзӮ№жңҚеҠЎеҷЁе…·еӨҮи·Ёе№іеҸ°зҡ„зү№жҖ§пјҢеҸҜд»ҘиҝҗиЎҢеңЁд»»дҪ•ж”ҜжҢҒ Java зҡ„ж“ҚдҪңзі»з»ҹдёҠпјҢйғЁзҪІж–№жі•еҸӮи§ҒйӣҶз®—еҷЁж•ҷзЁӢгҖӮиҝҷйҮҢеҒҮи®ҫж”ҫеҲ° windows ж“ҚдҪңзі»з»ҹзҡ„ C зӣҳж №зӣ®еҪ•гҖӮ
зӮ№еҮ»дёӢиҪҪ gatewayServer.zip
2гҖҒдҝ®ж”№еүҚйқўзҡ„ dfxпјҢе°Ҷ A3 ж”№дёә =file(вҖңC:/gatewayServer/data/orders.btxвҖқ)пјҢеҸҰеӯҳдёә etl2.dfxгҖӮдҝ®ж”№еҘҪзҡ„ etl2.dfx еңЁ c:\gatewayServer зӣ®еҪ•гҖӮ
3гҖҒжү“ејҖеә”з”ЁжңҚеҠЎеҷЁдёӯзҡ„ C:\tomcat6\webapps\gateway\WEB-INF\dfx\gateway2.dfxпјҢи§ӮеҜҹзҗҶи§Ј SPL д»Јз ҒгҖӮеҸӮж•°дёҚеҸҳпјҢиҝҳжҳҜдј е…Ҙзҡ„ sql е’Ң argsгҖӮ
| A | B | |
|---|---|---|
| 1 | =callx(вҖңgatewayServer2.dfxвҖқ,[sql];[вҖң127.0.0.1:8281вҖқ]) | |
| 2 | return A1.ifn() |
A1пјҡи°ғз”ЁиҠӮзӮ№жңәдёҠзҡ„ gatewayServer2.dfxгҖӮеҸӮж•°жҳҜ [sql]пјҢдёӯжӢ¬еҸ·иЎЁзӨәеәҸеҲ—пјҢжӯӨж—¶жҳҜеҸӘжңүдёҖдёӘжҲҗе‘ҳзҡ„еәҸеҲ—гҖӮ[вҖң127.0.0.1:8281вҖқ] жҳҜиҠӮзӮ№жңәзҡ„еәҸеҲ—пјҢйҮҮз”Ё IP: з«ҜеҸЈеҸ·зҡ„ж–№ејҸгҖӮиҠӮзӮ№жңәжҳҜйӣҶзҫӨзҡ„ж—¶еҖҷпјҢеҸҜд»ҘжңүеӨҡдёӘ IP ең°еқҖпјҢдҫӢеҰӮпјҡ["IP1:PORT1вҖі,"IP2:PORT2вҖі,вҖңIP3:PORT3вҖқ]гҖӮ
A2пјҡиҝ”еӣһ A1 и°ғз”Ёзҡ„з»“жһңгҖӮеӣ дёәи°ғз”Ёз»“жһңеҸҜд»ҘжҳҜеәҸеҲ—пјҢжүҖд»ҘиҰҒз”Ё ifn еҮҪж•°жүҫеҲ°еәҸеҲ—дёӯ第дёҖдёӘдёҚдёәз©әзҡ„жҲҗе‘ҳпјҢе°ұжҳҜ SQL еҜ№еә”зҡ„иҝ”еӣһз»“жһңгҖӮ
дҝ®ж”№ C:\tomcat6\webapps\gateway\WEB-INF\classes\raqsoftConfig.xml дёӯзҡ„еҰӮдёӢй…ҚзҪ® gateway1.dfx ж”№дёә gateway2.dfxгҖӮ
<JDBC> <load>Runtime,Server\\</load> <gateway>gateway2.dfx\\</gateway> </JDBC> <JDBC> <load>Runtime,Server\</load> <gateway>gateway2.dfx\</gateway> </JDBC><JDBC><load>Runtime,Server\\</load><gateway>gateway2.dfx\\</gateway></JDBC> <JDBC><load>Runtime,Server\</load><gateway>gateway2.dfx\</gate way></JDBC>
4гҖҒеҗҜеҠЁиҠӮзӮ№жңҚеҠЎеҷЁгҖӮ
иҝҗиЎҢ esprocs.exe, еҰӮдёӢеӣҫпјҡ
зӮ№еҮ»й…ҚзҪ®жҢүй’®пјҢй…ҚзҪ®зӣёе…іеҸӮж•°пјҡ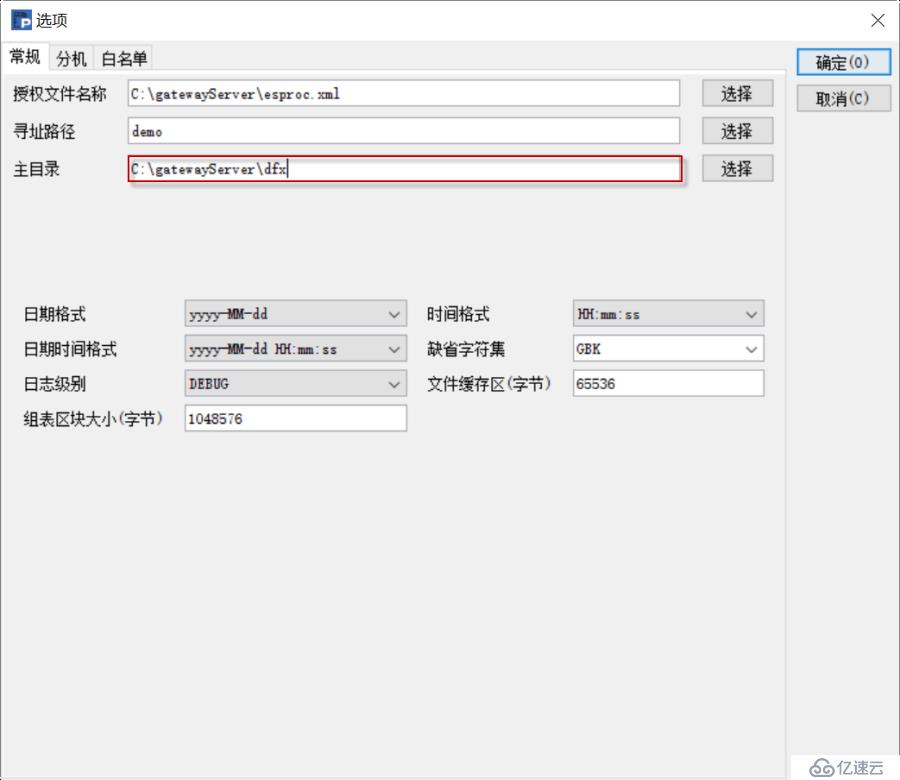
зӮ№еҮ»зЎ®е®ҡеҗҺпјҢиҝ”еӣһдё»з•ҢйқўпјҢзӮ№еҮ»еҗҜеҠЁжҢүй’®гҖӮ
5гҖҒжү“ејҖ C:\gatewayServer\dfx\gatewayServer2.dfxпјҢи§ӮеҜҹзҗҶи§Ј SPL д»Јз ҒгҖӮ
| A | B | C | |
|---|---|---|---|
| 1 | =filename=вҖңC:/gatewayServer/data/orders.btxвҖқ | ||
| 2 | =sql.sqlparse@w().split(" ") | =A2.select@1(like(~,вҖңORDERDATE=date(вҖҳ????-??-??вҖҷ)вҖқ)) | |
| 3 | =mid(right(B2,14),3,10) | =year(now())-year(date(A3)) | |
| 4 | if B3<=3 | =connect() | =sql=replace(sql,вҖңfrom ORDERSвҖқ,"from "+filename) |
| 5 | =B4.cursor@x(sql) | return B5 | |
| 6 | else | =connect(вҖңorclвҖқ) | =sql=sql.sqltranslate(вҖңORACLEвҖқ) |
| 7 | =B6.cursor@x(sql) | return B7 |
д»Јз Ғеҹәжң¬е’ҢеүҚйқўзҡ„ gateway1.dfx дёҖиҮҙгҖӮеҢәеҲ«жҳҜиҝҷдёӘ dfx жҳҜеңЁиҠӮзӮ№жңҚеҠЎеҷЁ unitServer дёҠжү§иЎҢзҡ„пјҢж•°жҚ®жҳҜеӯҳеңЁиҠӮзӮ№жңҚеҠЎеҷЁдёҠгҖӮ
5гҖҒйҮҚеҗҜ tomcatпјҢеңЁжөҸи§ҲеҷЁдёӯи®ҝй—® http://localhost:8080/gateway/jdbc.jspпјҢжҹҘзңӢз»“жһңгҖӮ
еҪ“ж•°жҚ®йҮҸеҫҲеӨ§еҗҢж—¶еҸҲйңҖиҰҒз§’зә§зҡ„жҹҘиҜўйҖҹеәҰж—¶пјҢжҲ‘们е»әи®®йҮҮз”ЁйӣҶз®—еҷЁз»„иЎЁжқҘеӯҳеӮЁж•°жҚ®гҖӮз»„иЎЁйҖӮз”Ёзҡ„еңәеҗҲеҢ…жӢ¬пјҡж•°жҚ®иЎЁеӯ—ж®өжңүеҮ еҚҒдёӘз”ҡиҮіжӣҙеӨҡпјӣж•°жҚ®йҮҸеҮ еҚғдёҮиЎҢпјҢеӯҳжҲҗйӣҶж–Ү件еңЁ 1G д»ҘдёҠпјӣжҹҘиҜўиҰҒжұӮз§’зә§е“Қеә”гҖӮ
еҜ№дәҺз®ҖеҚ• SQL жқҘиҜҙпјҢз»„иЎЁж–Ү件зҡ„з”Ёжі•е’ҢйӣҶж–Ү件没жңүд»Җд№ҲдёҚеҗҢ, еҸӘжҳҜж–Ү件еҗҚдёҚдёҖж ·гҖӮgatewayServer2.dfx дёӯеҸӘйңҖиҰҒжҠҠ A1 ж”№дёә =filename=вҖңC:/gatewayServer/data/orders.ctxвҖқпјҢеҸҰеӯҳдёә gatewayServer3.dfxгҖӮзӣёеә”зҡ„ gateway2.dfx дёӯзҡ„ A1 ж”№дёә =callx(вҖңgatewayServer3.dfxвҖқ,[sql];[вҖң127.0.0.1:8281вҖқ])пјҢеҸҰеӯҳдёә gateway3.dfxгҖӮ
дҝ®ж”№ C:\tomcat6\webapps\gateway\WEB-INF\classes\raqsoftConfig.xml дёӯзҡ„еҰӮдёӢй…ҚзҪ® gateway2.dfx ж”№дёә gateway3.dfxгҖӮ
<JDBC> <load>Runtime,Server\\</load> <gateway>gateway3.dfx\\</gateway> </JDBC> <JDBC> <load>Runtime,Server\</load> <gateway>gateway3.dfx\</gateway> </JDBC><JDBC><load>Runtime,Server\\</load><gateway>gateway3.dfx\\</gateway></JDBC> <JDBC><load>Runtime,Server\</load><gateway>gateway3.dfx\</gate way></JDBC>
жҲ‘们йҮҚзӮ№зҗҶи§ЈеҰӮдҪ•ж”№еҶҷ etl иҝҮзЁӢпјҢдҝ®ж”№еүҚйқўзҡ„ etl2.dfxпјҢеҸҰеӯҳдёә etl3.dfxгҖӮ
| A | |
|---|---|
| 1 | =year(now())-3 |
| 2 | =connect(вҖңorclвҖқ) |
| 3 | =A2.cursor@d(вҖңselect CUSTOMERID,EMPLOYEEID,ORDERDATE,ORDERID,AMOUNT from ORDERS where to_char(ORDERDATE,вҖҳyyyyвҖҷ)>=? order by CUSTOMERID,EMPLOYEEID,ORDERDATE,ORDERID",A1) |
| 4 | =file(вҖңC:/gatewayServer/data/orders.ctxвҖқ) |
| 5 | =A4.create(#CUSTOMERID,#EMPLOYEEID,#ORDERDATE,#ORDERID,AMOUNT) |
| 6 | =A5.append(A3) |
| 7 | >A2.close() |
з»„иЎЁдёҺйӣҶж–Ү件дёҚеҗҢпјҢй»ҳи®ӨжҳҜйҮҮз”ЁеҲ—ејҸеӯҳеӮЁзҡ„пјҢж”ҜжҢҒд»»ж„ҸеҲҶж®өзҡ„并иЎҢи®Ўз®—пјҢеҸҜд»Ҙжңүж•ҲжҸҗеҚҮжҹҘиҜўйҖҹеәҰгҖӮеҗҢж—¶пјҢз”ҹжҲҗз»„иЎЁзҡ„ж—¶еҖҷпјҢиҰҒжіЁж„Ҹж•°жҚ®йў„е…ҲжҺ’еәҸе’ҢеҗҲзҗҶе®ҡд№үз»ҙеӯ—ж®өгҖӮжң¬дҫӢдёӯпјҢжҢүз…§з»ҸеёёиҝҮж»ӨгҖҒеҲҶз»„зҡ„еӯ—ж®өпјҢе°Ҷз»ҙеӯ—ж®өзЎ®е®ҡдёәпјҡCUSTOMERID,EMPLOYEEID,ORDERDATE,ORDERIDгҖӮ
A3 еҸ–еҫ—ж•°жҚ®зҡ„ж—¶еҖҷпјҢиҰҒжҢүз…§з»ҙеӯ—ж®өжҺ’еәҸгҖӮеӣ дёә CUSTOMERID,EMPLOYEEID,ORDERDATE еҜ№еә”зҡ„йҮҚеӨҚж•°жҚ®еӨҡпјҢжүҖд»Ҙж”ҫеңЁеүҚйқўжҺ’еәҸпјӣORDERID еҜ№еә”зҡ„йҮҚеӨҚж•°жҚ®е°‘пјҢжүҖд»Ҙж”ҫеңЁеҗҺйқўжҺ’еәҸгҖӮ
A4 дёӯе®ҡд№үз»„иЎЁзҡ„ж—¶еҖҷз”Ё #жқҘиЎЁзӨәз»ҙеӯ—ж®өгҖӮ
йңҖиҰҒиҜҙжҳҺзҡ„жҳҜпјҢз»„иЎЁд№ҹж”ҜжҢҒ并иЎҢжҹҘиҜў /*+ parallel (n) */гҖӮ
BI еә”з”Ёзҡ„зү№зӮ№жҳҜпјҡ
1гҖҒе“Қеә”ж—¶й—ҙиҰҒжұӮй«ҳпјҢдёҖиҲ¬дёҚи¶…иҝҮ 5-10 з§’гҖӮ
2гҖҒжҹҘиҜўеҜ№еә”ж•°жҚ®йҮҸеңЁеҮ зҷҫе…ҶеҲ°еҮ G иҢғеӣҙпјҢеӯ—ж®өжңүеҮ еҚҒдёӘз”ҡиҮідёҠзҷҫдёӘгҖӮ
3гҖҒ并еҸ‘йҮҸиҫғеӨ§пјҢеҮ еҚҒеҲ°еҮ зҷҫдёӘ并еҸ‘гҖӮ
жҖ§иғҪдјҳеҢ–зҡ„ж–№жі•жҳҜпјҡ
1гҖҒйҮҮз”Ёз»„иЎЁпјҢжҸҗй«ҳеҚ•д»»еҠЎжҹҘиҜўзҡ„е“Қеә”йҖҹеәҰгҖӮ
в—Ү ж №жҚ®йңҖжұӮпјҢеҗҲзҗҶе®ҡд№үз»ҙеӯ—ж®өгҖӮ
з»„иЎЁе®ҡд№үзҡ„ж—¶еҖҷпјҢиҰҒжҢүз…§дёҡеҠЎзҡ„йңҖиҰҒзЎ®е®ҡз»ҙеӯ—ж®өгҖӮиҰҒйҖүжӢ©з»ҸеёёдҪңдёәиҝҮж»ӨжқЎд»¶жҲ–иҖ…з”ЁжқҘеҲҶз»„зҡ„еӯ—ж®өдҪңдёәз»ҙеӯ—ж®өпјҢз»ҙеӯ—ж®өеүҚз”Ё #ж ҮиҜҶгҖӮ
в—Ү жҢүз…§з»ҙеӯ—ж®өпјҢйў„е…ҲжҺ’еәҸгҖӮ
иҰҒжҢүз…§з»ҙеӯ—ж®өеҒҡеҘҪж•°жҚ®зҡ„жҺ’еәҸпјҢйҮҚеӨҚи®°еҪ•ж•°еӨҡзҡ„еӯ—ж®өеңЁеүҚйқўпјҢдҫӢеҰӮпјҡжҢүз…§ order by зңҒпјҢеёӮпјҢеҺҝзҡ„еӯ—ж®өйЎәеәҸжқҘжҺ’еәҸпјҢиҖҢдёҚжҳҜеҸҚиҝҮжқҘгҖӮ
в—Ү ж №жҚ®е№¶еҸ‘йҮҸпјҢйҖүжӢ©жҳҜеҗҰ用并иЎҢжҹҘиҜўгҖӮ
并еҸ‘йҮҸжҜ”иҫғеӨ§зҡ„ж—¶еҖҷпјҢеҚ•дёӘ SQL жҹҘиҜўе°ұдёҚе»ә议用并иЎҢжҹҘиҜўдәҶ /*+ parallel (n) */гҖӮ并иЎҢжҹҘиҜўдјҡж¶ҲиҖ—жӣҙеӨҡзҡ„зәҝзЁӢж•°пјҢеҸҚиҖҢдјҡеҪұе“ҚеӨ§зҡ„并еҸ‘жҖ§иғҪгҖӮ
2гҖҒеҗҲзҗҶй…ҚзҪ®иҠӮзӮ№жңҚеҠЎеҷЁзҡ„еҸӮж•°пјҢеҸ‘жҢҘжҜҸдёӘиҠӮзӮ№зҡ„жҖ§иғҪгҖӮ
жҜҸеҸ°жңҚеҠЎеҷЁпјҲе®һдҪ“жңәжҲ–иҖ…иҷҡжӢҹжңәпјүиҰҒеҗҜеҠЁдёҖдёӘиҠӮзӮ№жңҚеҠЎеҷЁпјҢжҜҸдёӘиҠӮзӮ№жңҚеҠЎеҷЁеҗҜеҠЁеҲҶжңәзҡ„й…ҚзҪ®з•ҢйқўеҰӮдёӢпјҡ
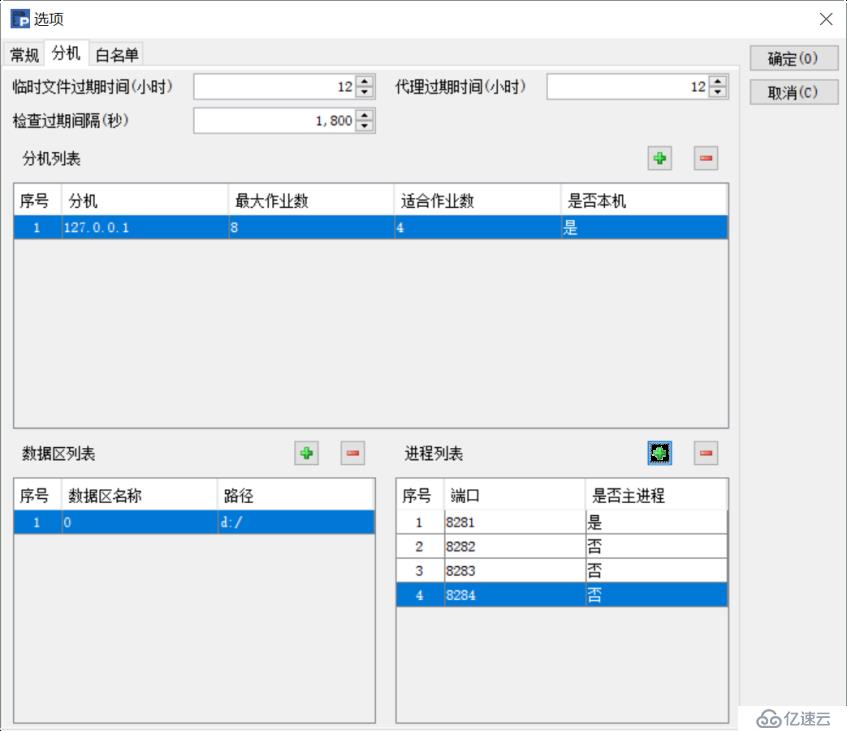
в—Ү ж №жҚ®зЎ¬д»¶иө„жәҗпјҢй…ҚзҪ®иҝӣзЁӢж•°
иҝӣзЁӢеҲ—иЎЁдёӯзҡ„иҝӣзЁӢж•°пјҲд№ҹе°ұжҳҜйҖӮеҗҲдҪңдёҡж•°пјүе»әи®®жҳҜдёҚиҰҒи¶…иҝҮ CPU жҖ»ж ёж•° *2/3гҖӮдҫӢеҰӮпјҡжңҚеҠЎеҷЁжңү 8 дёӘ CPU жҜҸдёӘдёӨж ёпјҢжҖ»ж ёж•°жҳҜ 8*2=16пјҢйӮЈд№ҲиҝӣзЁӢж•°йҮҸе°ұдёҚиҰҒи¶…иҝҮ 16*2/3=10 дёӘгҖӮжңҖеӨ§дҪңдёҡж•°жҺЁиҚҗжҳҜйҖӮеҗҲдҪңдёҡж•° *2пјҢд№ҹе°ұжҳҜ 10*2=20 дёӘгҖӮ
в—Ү е°ҪйҮҸеӨҡеҲҶй…ҚеҶ…еӯҳпјҢдҪҶиҰҒйҒҝе…Қи¶…йҮҸ
иҠӮзӮ№жңҚеҠЎеҷЁжҜҸдёӘиҝӣзЁӢзҡ„жңҖеӨ§еҶ…еӯҳиҰҒе°ҪйҮҸеӨҡеҲҶй…ҚпјҢдҪҶжҳҜжҖ»ж•°еҠ иө·жқҘиҰҒжҜ”е®һйҷ…зҡ„зү©зҗҶеҶ…еӯҳе°ҸпјҢйҒҝе…Қж“ҚдҪңзі»з»ҹз”ЁзЎ¬зӣҳжқҘиЎҘе……еҶ…еӯҳзҡ„дёҚи¶ігҖӮдҫӢеҰӮпјҢжҖ»еҶ…еӯҳжҳҜ 32GпјҢиҝӣзЁӢж•°йҮҸжҳҜ 8 дёӘпјҢйӮЈд№ҲжҜҸдёӘиҝӣзЁӢзҡ„жңҖеӨ§еҶ…еӯҳе°ұдёҚиҰҒеӨ§дәҺ 4GгҖӮй…ҚзҪ®иҝӣзЁӢзҡ„жңҖеӨ§жңҖе°ҸеҶ…еӯҳжҳҜеңЁ C:\Program Files\raqsoft\esProc\bin\config.txt дёӯпјҢдҫӢеҰӮпјҡ
jvm_args=-Xms128m -Xmx4845m жңҖе°ҸеҶ…еӯҳжҳҜ 128MпјҢжңҖеӨ§жҳҜ 4GгҖӮ
3гҖҒжЁӘеҗ‘жү©еұ•иҠӮзӮ№жңҚеҠЎеҷЁпјҢеӨҡжңәеә”еҜ№еӨ§е№¶еҸ‘и®ҝй—®гҖӮ
в—Ү жЁӘеҗ‘жү©еұ•пјҢеә”еҜ№еӨ§е№¶еҸ‘гҖӮ
йҡҸзқҖ并еҸ‘йҮҸзҡ„еўһеӨ§пјҢеҪ“жҖ§иғҪдёҚиғҪж»Ўи¶іиҰҒжұӮзҡ„ж—¶еҖҷпјҢиҰҒеўһеҠ иҠӮзӮ№жңҚеҠЎеҷЁзҡ„ж•°йҮҸпјҢйҖҡиҝҮжЁӘеҗ‘жү©еұ•жқҘж»Ўи¶ійңҖжұӮгҖӮ
в—Ү еўһеҠ жңҚеҠЎеҷЁеҲ—иЎЁй…ҚзҪ®йЎ№гҖӮ
иҝҷж—¶еҖҷиҰҒдҝ®ж”№ gateway3.dfx дёӯзҡ„ callx еҮҪж•°зҡ„жңҚеҠЎеҷЁеәҸеҲ—еҸӮж•°гҖӮеҸҜд»Ҙе°ҶжңҚеҠЎеҷЁеәҸеҲ—еҸӮж•°еҶҷеҲ°й…ҚзҪ®ж–Ү件дёӯпјҢиҝҷж ·е°ұеҸҜд»ҘдёҚеҝ…жҜҸж¬ЎйғҪдҝ®ж”№ dfx ж–Ү件дәҶгҖӮ
4гҖҒдҪҝз”Ёжң¬жңәзЎ¬зӣҳж•°жҚ®иҝӣиЎҢи®Ўз®—пјҢйҒҝе…Қи·ЁзҪ‘з»ңи®ҝй—®гҖӮ
зЎ¬зӣҳзҡ„ IO йҖҹеәҰжҳҜжҜ”иҫғжңүдҝқиҜҒзҡ„гҖӮ
иҠӮзӮ№жңҚеҠЎеҷЁйҖҡиҝҮзҪ‘з»ңеҺ»еҸ–е…¶д»–жңҚеҠЎеҷЁдёҠзҡ„ж•°жҚ®пјҢжҲ–иҖ…йҖҡиҝҮи®ҝй—®е…ұдә«еӯҳеӮЁдёҠзҡ„ж•°жҚ®пјҢз»ҸеёёдјҡеҮәзҺ°зҪ‘з»ңйҳ»еЎһзҡ„жғ…еҶөпјҢйҷҚдҪҺжҹҘиҜўе“Қеә”йҖҹеәҰгҖӮеӣ жӯӨпјҢе°ҪеҸҜиғҪжҜҸеҸ°иҠӮзӮ№жңҚеҠЎеҷЁд»…д»…жү§иЎҢжң¬жңәдёҠзҡ„ж•°жҚ®пјҢдёҚиҰҒи·ЁзҪ‘з»ңи®ҝй—®гҖӮ
еҸҜзј–зЁӢж•°жҚ®и·Ҝз”ұжҳҜж•°жҚ®и®Ўз®—дёӯй—ҙ件пјҲDCMпјүзҡ„йҮҚиҰҒеә”з”ЁеңәжҷҜгҖӮ
еңЁеүҚиҝ°зҡ„дҫӢеӯҗдёӯпјҢж•°жҚ®и·Ҝз”ұзҡ„зӯ–з•ҘжҳҜпјҡжңҖиҝ‘дёүе№ҙзҡ„ж•°жҚ®дҪңдёәзғӯж•°жҚ®ж”ҫи·Ҝз”ұеҲ°йӣҶз®—еҷЁдёӯи®Ўз®—пјҢе…¶д»–ж•°жҚ®дҪңдёәеҶ·ж•°жҚ®пјҢи·Ҝз”ұеҲ°ж•°жҚ®еә“дёӯи®Ўз®—гҖӮ
зұ»дјјзҡ„и·Ҝз”ұ规еҲҷиҝҳжңүпјҡжңҖиҝ‘дёүеӨ©е’ҢжңҖиҝ‘еҚҒдәҢдёӘжңҲзҡ„жңҖеҗҺдёҖеӨ©зҡ„ж•°жҚ®дҪңдёәзғӯж•°жҚ®пјҢи·Ҝз”ұеҲ°йӣҶз®—еҷЁдёӯи®Ўз®—пјҢе…¶д»–ж•°жҚ®и·Ҝз”ұеҲ°ж•°жҚ®еә“жұҮжҖ»и®Ўз®—гҖӮ
еҜ№дәҺеҶ·зғӯж•°жҚ®и®Ўз®—и·Ҝз”ұ规еҲҷпјҢжң¬зҜҮеҸӘд»Ӣз»ҚдәҶдёҖж¬ЎжҹҘиҜўеҸӘж¶үеҸҠеҶ·жҲ–зғӯж•°жҚ®зҡ„жғ…еҶөпјҢеҰӮжһңеңЁдёҖж¬ЎжҹҘиҜўдёӯеҸҜиғҪеҗҢж—¶ж¶үеҸҠеҶ·зғӯдёӨз§Қж•°жҚ®пјҢжҲ‘们е°ҶеңЁеҗҺз»ӯж–Үз« дёӯиҝӣиЎҢд»Ӣз»ҚгҖӮ
е®һйҷ…еә”з”ЁдёӯпјҢж•°жҚ®и·Ҝз”ұзҡ„规еҲҷеҸҜиғҪдјҡеҫҲеӨҚжқӮе’ҢеӨҡеҸҳпјҢйҖҡиҝҮй…ҚзҪ®жқҘе®һзҺ°дјҡйқһеёёеӣ°йҡҫпјҢз”Ёзј–зЁӢзҡ„ж–№ејҸе®һзҺ°жҳҜжңҖдҪіж–№жЎҲгҖӮйҮҮз”ЁйӣҶз®—еҷЁзҡ„зј–зЁӢиҜӯиЁҖ SPL жқҘе®һзҺ°еӨҚжқӮзҡ„ж•°жҚ®и·Ҝз”ұ规еҲҷжҳҜжңҖз®ҖеҚ•е’ҢжңҖй«ҳж•Ҳзҡ„гҖӮйӣҶз®—еҷЁж”ҜжҢҒеӨҡж ·жҖ§ејӮжһ„ж•°жҚ®жәҗзҡ„ж··еҗҲи®Ўз®—пјҢеҸҜд»Ҙзј–зЁӢе®һзҺ°ж¶үеҸҠеҲ°еҗ„з§ҚејӮжһ„ж•°жҚ®жәҗзҡ„еӨҚжқӮж•°жҚ®и·Ҝз”ұ规еҲҷгҖӮ
з”ЁдҪңеӨҡз»ҙеҲҶжһҗеҗҺеҸ°ж—¶пјҢж•°жҚ®и®Ўз®—дёӯй—ҙ件пјҲDCMпјүиҰҒжҸҗдҫӣеҝ…иҰҒзҡ„ SQL и§ЈжһҗдёҺзҝ»иҜ‘еҠҹиғҪгҖӮ
ж•°жҚ®и·Ҝз”ұзҡ„е®һзҺ°зҰ»дёҚејҖйӣҶз®—еҷЁеҜ№ SQL иҜӯеҸҘзҡ„и§Јжһҗе’Ңзҝ»иҜ‘гҖӮйҰ–е…ҲиҰҒз”ЁйӣҶз®—еҷЁзҡ„ SQL и§ЈжһҗиғҪеҠӣпјҢжүҫеҲ° where жқЎд»¶дёӯзҡ„ж—Ҙжңҹеӯ—ж®өпјҢ然еҗҺж №жҚ®и§„еҲҷжқҘеҶіе®ҡи·Ҝз”ұеҲ°ж–Ү件иҝҳжҳҜж•°жҚ®еә“гҖӮеҰӮжһңжҳҜи·Ҝз”ұеҲ°ж•°жҚ®еә“пјҢйӮЈд№ҲиҰҒжҠҠйӣҶз®—еҷЁзҡ„ж ҮеҮҶ SQL зҝ»иҜ‘жҲҗж•°жҚ®еә“зҡ„ SQLпјҢе°ұиҰҒз”ЁеҲ°йӣҶз®—еҷЁзҡ„ SQL зҝ»иҜ‘иғҪеҠӣгҖӮ
йӣҶз®—еҷЁзҡ„ SQL и§Јжһҗз”Ё sqlparse()еҮҪж•°е®һзҺ°пјҢSQL зҝ»иҜ‘з”Ё sqltranslate() еҮҪж•°е®һзҺ°гҖӮ
SQL жҖ§иғҪдјҳеҢ–д№ҹжҳҜж•°жҚ®и®Ўз®—дёӯй—ҙ件пјҲDCMпјүеҝ…дёҚеҸҜе°‘зҡ„иғҪеҠӣгҖӮ
BI еә”з”Ёе…Ғи®ёз”ЁжҲ·жӢ–жӢҪз”ҹжҲҗ SQLпјҢе°ұдјҡеҮәзҺ°еҫҲеӨҡжҖ§иғҪдёҚй«ҳзҡ„ SQLгҖӮжҜ”еҰӮзӣҙжҺҘеңЁжҳҺз»ҶжҹҘиҜўзҡ„ SQL еӨ–йқўеҠ дёҠдёҖеұӮ count жқҘз»ҹи®Ўз»“жһңжҖ»жқЎж•°пјҡselect count(1) from (select f1,f2,f3,f4вҖҰf30 from table1 where f1=1 and 1=1)гҖӮжӯӨж—¶еӯҗжҹҘиҜўдёӯзҡ„ f1 еҲ° f30 еҰӮжһңе…ЁйғЁеҸ–еҮәпјҢе°ұдјҡйҷҚдҪҺжҹҘиҜўзҡ„жҖ§иғҪгҖӮ1=1 иҝҷж ·зҡ„иҝҮж»ӨжқЎд»¶д№ҹдјҡйҖ жҲҗжІЎжңүж„Ҹд№үзҡ„ж—¶й—ҙж¶ҲиҖ—гҖӮ
йӣҶз®—еҷЁз®ҖеҚ• SQL еј•ж“ҺпјҢеҸҜд»Ҙе®ҢжҲҗиҮӘеҠЁжҹҘиҜўдјҳеҢ–гҖӮеҺ»жҺү 1=1 иҝҷж ·дёҚеҝ…иҰҒзҡ„жқЎд»¶пјҢд№ҹдёҚдјҡеҸ–еҮәжүҖжңүеӯ—ж®өжқҘе®ҢжҲҗ countгҖӮд»ҺиҖҢе®һзҺ° SQL и§Јжһҗе’ҢдјҳеҢ–пјҢжңүж•Ҳзҡ„жҸҗй«ҳжҹҘиҜўжҖ§иғҪгҖӮ
зұ»дјјзҡ„пјҢиҝҳжңү select top 10 f1,f2 from table1 order by f1гҖӮйӣҶз®—еҷЁдјҡйҮҮз”Ёе°Ҹз»“жһңйӣҶжҜ”иҫғзҡ„ж–№ејҸе®һзҺ°гҖӮеҸҜд»ҘеҒҡеҲ°ж— йЎ»еӨ§жҺ’еәҸпјҢеҸӘйҒҚеҺҶдёҖиҫ№ж•°жҚ®еҚіеҸҜеҫ—еҲ°йңҖиҰҒзҡ„з»“жһңпјҢжңүж•ҲжҸҗеҚҮжҹҘиҜўйҖҹеәҰгҖӮ
е…Ҳиҝӣзҡ„ж•°жҚ®еӯҳеӮЁж–№ејҸпјҢжҳҜж•°жҚ®и®Ўз®—дёӯй—ҙ件пјҲDCMпјүжҲҗеҠҹе®һж–Ҫзҡ„йҮҚиҰҒдҝқйҡңгҖӮ
йӣҶз®—еҷЁз»„иЎЁйҮҮз”ЁеҲ—еӯҳж–№ејҸеӯҳеӮЁж•°жҚ®пјҢеҜ№дәҺеӯ—ж®өзү№еҲ«еӨҡзҡ„е®ҪиЎЁжҹҘиҜўпјҢжҖ§иғҪжҸҗеҚҮзү№еҲ«жҳҺжҳҫгҖӮз»„иЎЁйҮҮз”Ёзҡ„еҲ—еӯҳжңәеҲ¶е’Ң常规еҲ—еӯҳжҳҜдёҚеҗҢзҡ„гҖӮ常规еҲ—еӯҳпјҲжҜ”еҰӮ parquet ж јејҸпјүпјҢеҸӘиғҪеҲҶеқ—д№ӢеҗҺпјҢеҶҚеңЁеқ—еҶ…еҲ—еӯҳпјҢеңЁеҒҡ并иЎҢи®Ўз®—зҡ„ж—¶еҖҷжҳҜеҸ—йҷҗзҡ„гҖӮз»„иЎЁзҡ„еҸҜ并иЎҢеҺӢзј©еҲ—еӯҳжңәеҲ¶пјҢйҮҮз”ЁеҖҚеўһеҲҶж®өжҠҖжңҜпјҢе…Ғи®ёд»»ж„ҸеҲҶж®өзҡ„并иЎҢи®Ўз®—пјҢеҸҜд»ҘеҲ©з”ЁеӨҡ CPU ж ёзҡ„и®Ўз®—иғҪеҠӣжҠҠзЎ¬зӣҳзҡ„ IO еҸ‘жҢҘеҲ°жһҒиҮҙгҖӮ
з»„иЎЁз”ҹжҲҗзҡ„ж—¶еҖҷпјҢиҰҒжҢҮе®ҡз»ҙеӯ—ж®өпјҢж•°жҚ®жң¬иә«жҳҜжҢүз…§з»ҙеӯ—ж®өжңүеәҸеӯҳж”ҫзҡ„пјҢеёёз”Ёзҡ„жқЎд»¶иҝҮж»Өи®Ўз®—дёҚдҫқиө–зҙўеј•д№ҹиғҪдҝқиҜҒй«ҳжҖ§иғҪгҖӮж–Ү件йҮҮз”ЁеҺӢзј©еӯҳеӮЁпјҢеҮҸе°ҸеңЁзЎ¬зӣҳдёҠеҚ з”Ёзҡ„з©әй—ҙпјҢиҜ»еҸ–жӣҙеҝ«гҖӮз”ұдәҺйҮҮз”ЁдәҶеҗҲйҖӮзҡ„еҺӢзј©жҜ”пјҢи§ЈеҺӢзј©еҚ з”Ёзҡ„ CPU ж—¶й—ҙеҸҜд»ҘеҝҪз•ҘдёҚи®ЎгҖӮ
з»„иЎЁд№ҹеҸҜд»ҘйҮҮеҸ–иЎҢеӯҳе’Ңе…ЁеҶ…еӯҳеӯҳеӮЁж•°жҚ®пјҢж”ҜжҢҒеҶ…еӯҳж•°жҚ®еә“ж–№ејҸиҝҗиЎҢгҖӮ
ж•ҸжҚ·зҡ„йӣҶзҫӨиғҪеҠӣеҸҜд»ҘдҝқиҜҒж•°жҚ®и®Ўз®—дёӯй—ҙ件пјҲDCMпјүзҡ„й«ҳжҖ§иғҪе’Ңй«ҳеҸҜз”ЁжҖ§гҖӮ
йӣҶз®—еҷЁиҠӮзӮ№жңҚеҠЎеҷЁжҳҜзӢ¬з«ӢиҝӣзЁӢпјҢеҸҜд»ҘжҺҘеҸ—йӣҶз®—еҷЁзҪ‘е…ізЁӢеәҸзҡ„и®Ўз®—иҜ·жұӮ并иҝ”еӣһз»“жһңгҖӮеҜ№дәҺ并еҸ‘и®ҝй—®зҡ„жғ…еҶөпјҢеҸҜд»ҘеҸ‘з»ҷеӨҡдёӘжңҚеҠЎеҷЁеҗҢж—¶и®Ўз®—пјҢжҸҗй«ҳ并еҸ‘е®№йҮҸгҖӮеҜ№дәҺеҚ•дёӘеӨ§и®Ўз®—д»»еҠЎзҡ„жғ…еҶөпјҢеҸҜд»ҘеҲҶжҲҗеӨҡдёӘе°Ҹд»»еҠЎпјҢеҸ‘з»ҷеӨҡдёӘжңҚеҠЎеҷЁеҗҢж—¶и®Ўз®—пјҢиө·еҲ°еӨ§ж•°жҚ®е№¶иЎҢи®Ўз®—зҡ„дҪңз”ЁгҖӮ
йӣҶз®—еҷЁйӣҶзҫӨи®Ўз®—ж–№жЎҲпјҢе…·еӨҮж•ҸжҚ·зҡ„жЁӘеҗ‘жү©еұ•иғҪеҠӣпјҢ并еҸ‘йҮҸжҲ–иҖ…ж•°жҚ®йҮҸеӨ§ж—¶еҸҜд»ҘйҖҡиҝҮеҝ«йҖҹеўһеҠ иҠӮзӮ№жқҘи§ЈеҶігҖӮйӣҶз®—еҷЁйӣҶзҫӨд№ҹе…·еӨҮе®№й”ҷиғҪеҠӣпјҢеҚіжңүдёӘеҲ«иҠӮзӮ№еӨұж•Ҳж—¶иҝҳиғҪзЎ®дҝқж•ҙдёӘйӣҶзҫӨиғҪе·ҘдҪңпјҢи®Ўз®—д»»еҠЎиғҪ继з»ӯжү§иЎҢе®ҢжҜ•пјҢиө·еҲ°еӨҡжңәзғӯеӨҮе’ҢдҝқиҜҒй«ҳеҸҜз”ЁжҖ§зҡ„дҪңз”ЁгҖӮ
дҪңдёәж•°жҚ®и®Ўз®—дёӯй—ҙ件пјҲDCMпјүпјҢйӣҶз®—еҷЁе®һзҺ°зҡ„ж•°жҚ®и®Ўз®—зҪ‘е…іе’Ңи·Ҝз”ұпјҢеҸҜд»Ҙи§ЈеҶіж•°жҚ®д»“еә“ж— жі•ж»Ўи¶іжҖ§иғҪиҰҒжұӮпјҢеҶ·зғӯж•°жҚ®еҲҶејҖеҸҲиҰҒж··еҗҲи®Ўз®—зҡ„еңәжҷҜпјҢдёҚд»…д»…йҷҗдәҺеүҚз«ҜжҳҜ BI зҡ„жғ…еҶөгҖӮдҫӢеҰӮпјҡеӨ§еұҸеұ•зӨәгҖҒз®ЎзҗҶй©ҫ驶иҲұгҖҒе®һж—¶жҠҘиЎЁгҖҒеӨ§ж•°жҚ®йҮҸжё…еҚ•жҠҘиЎЁгҖҒжҠҘиЎЁжү№йҮҸи®ўйҳ…зӯүзӯүгҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ