жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
Flinkзҡ„еёёи§Ғй—®йўҳиҜҠж–ӯжҖқи·ҜжҳҜд»Җд№ҲпјҢй’ҲеҜ№иҝҷдёӘй—®йўҳпјҢиҝҷзҜҮж–Үз« иҜҰз»Ҷд»Ӣз»ҚдәҶзӣёеҜ№еә”зҡ„еҲҶжһҗе’Ңи§Јзӯ”пјҢеёҢжңӣеҸҜд»Ҙеё®еҠ©жӣҙеӨҡжғіи§ЈеҶіиҝҷдёӘй—®йўҳзҡ„е°ҸдјҷдјҙжүҫеҲ°жӣҙз®ҖеҚ•жҳ“иЎҢзҡ„ж–№жі•гҖӮ
1.еёёи§Ғиҝҗз»ҙй—®йўҳ
ж–Үдёӯд»Ӣз»Қзҡ„дҪңдёҡиҝҗиЎҢзҺҜеўғдё»иҰҒжҳҜеңЁйҳҝйҮҢе·ҙе·ҙйӣҶеӣўеҶ…пјҢжһ„е»әеңЁ Hadoop з”ҹжҖҒд№ӢдёҠзҡ„ Flink йӣҶзҫӨпјҢеҢ…еҗ« YarnгҖҒHDFSгҖҒZK зӯү组件пјӣдҪңдёҡжҸҗдәӨжЁЎејҸйҮҮз”Ё yarn per-job Detached жЁЎејҸгҖӮ
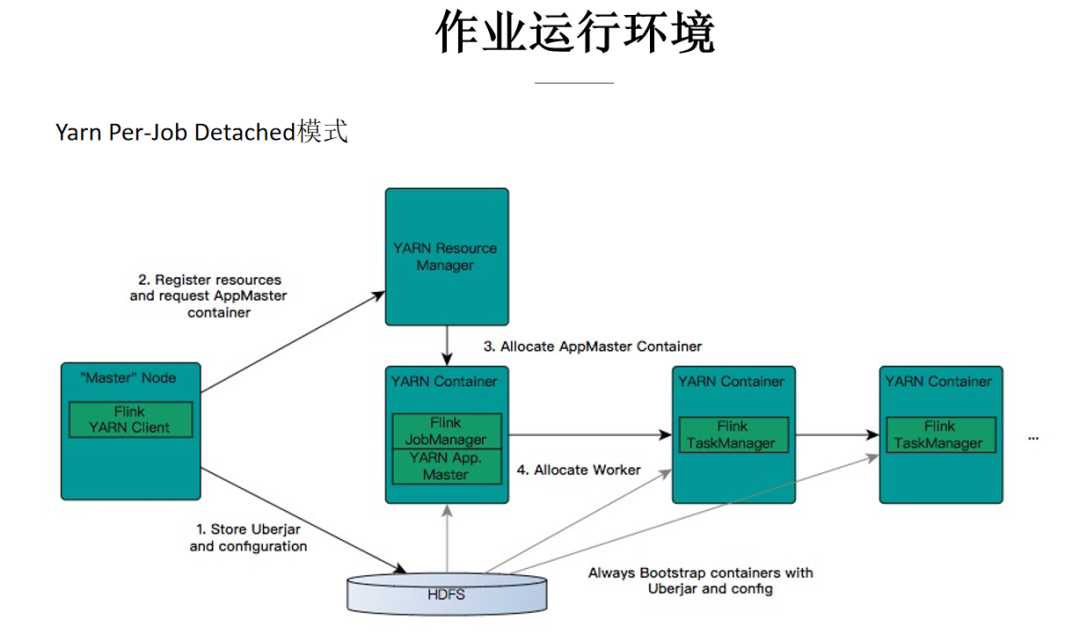
第1жӯҘпјҢдҪңдёҡжҸҗдәӨжҳҜйҖҡиҝҮ Flink Yarn ClientпјҢе°Ҷз”ЁжҲ·жүҖеҶҷзҡ„дҪңдёҡд»Јз Ғд»ҘеҸҠзј–иҜ‘еҘҪзҡ„ jar еҢ…дёҠдј еҲ° HDFS дёҠпјӣ
第2жӯҘ Flink Client дёҺ Yarn ResourceManager иҝӣиЎҢйҖҡдҝЎпјҢз”іиҜ·жүҖйңҖиҰҒзҡ„зҡ„ Container иө„жәҗпјӣ
第3жӯҘпјҢResourceManager 收еҲ°иҜ·жұӮеҗҺдјҡеңЁйӣҶзҫӨдёӯзҡ„ NodeManager еҲҶй…ҚеҗҜеҠЁ AppMaster зҡ„ Container иҝӣзЁӢпјҢAppMaster дёӯеҢ…еҗ« Flink JobManager жЁЎеқ—е’Ң Yarn йҖҡдҝЎзҡ„ ResourceManager жЁЎеқ—пјӣ
第4жӯҘпјҢеңЁ JobManager дёӯж №жҚ®дҪңдёҡзҡ„ JobGraph з”ҹжҲҗ Execution GraphпјҢResourceManager жЁЎеқ—еҗ‘ Yarn зҡ„ ResourceManager йҖҡдҝЎпјҢз”іиҜ· TaskManager йңҖиҰҒзҡ„ container иө„жәҗпјҢиҝҷдәӣ container з”ұ Yarn зҡ„ NodeManger иҙҹиҙЈжӢүиө·гҖӮжҜҸдёӘ NodeManager д»Һ HDFS дёҠдёӢиҪҪиө„жәҗпјҢеҗҜеҠЁ Container(TaskManager)пјҢ并еҗ‘ JobManager жіЁеҶҢпјӣJobManger дјҡйғЁзҪІдёҚеҗҢзҡ„ task д»»еҠЎеҲ°еҗ„дёӘ TaskManager дёӯжү§иЎҢгҖӮ
жҢҮе®ҡиө„жәҗеӨ§е°Ҹ
жҸҗдәӨж—¶пјҢжҢҮе®ҡжҜҸдёӘ TaskManagerгҖҒJobManager дҪҝз”ЁеӨҡе°‘еҶ…еӯҳпјҢCPU иө„жәҗгҖӮ
з»ҶзІ’еәҰиө„жәҗжҺ§еҲ¶
йҳҝйҮҢе·ҙе·ҙйӣҶеӣўеҶ…дё»иҰҒйҮҮз”Ё ResourceSpec ж–№ејҸжҢҮе®ҡжҜҸдёӘ Operator жүҖйңҖзҡ„иө„жәҗеӨ§е°ҸпјҢдҫқжҚ® task зҡ„并еҸ‘иҒҡеҗҲжҲҗ container иө„жәҗеҗ‘ Yarn з”іиҜ·гҖӮ
JM й«ҳеҸҜз”ЁпјҢAppMaster(JobManager) ејӮеёёеҗҺпјҢеҸҜд»ҘйҖҡиҝҮ Yarn зҡ„ APP attempt дёҺ ZooKeeper жңәеҲ¶жқҘдҝқиҜҒй«ҳеҸҜз”Ёпјӣ
ж•°жҚ®й«ҳеҸҜз”ЁпјҢдҪңдёҡеҒҡ checkpoint ж—¶пјҢTaskManager дјҳе…ҲеҶҷжң¬ең°зЈҒзӣҳпјҢеҗҢж—¶ејӮжӯҘеҶҷеҲ° HDFSпјӣеҪ“дҪңдёҡеҶҚж¬ЎеҗҜеҠЁж—¶еҸҜд»Ҙд»Һ HDFS дёҠжҒўеӨҚеҲ°дёҠж¬Ў checkpoint зҡ„зӮ№дҪҚ继з»ӯдҪңдёҡжөҒзЁӢгҖӮ
Processing time
Processing time жҳҜжҢҮ task еӨ„зҗҶж•°жҚ®ж—¶жүҖеңЁжңәеҷЁзҡ„зі»з»ҹж—¶й—ҙ
Event time
Event time жҳҜжҢҮж•°жҚ®еҪ“дёӯжҹҗдёҖж•°жҚ®еҲ—зҡ„ж—¶й—ҙ
Ingestion time
Ingestion time жҳҜжҢҮеңЁ flink source иҠӮзӮ№ж”¶еҲ°иҝҷжқЎж•°жҚ®ж—¶зҡ„зі»з»ҹзі»з»ҹж—¶й—ҙ
иҮӘе®ҡд№ү Source жәҗи§ЈжһҗдёӯеҠ е…Ҙ Gauge зұ»еһӢжҢҮж ҮеҹӢзӮ№пјҢжұҮжҠҘеҰӮдёӢжҢҮж Үпјҡ
и®°еҪ•жңҖж–°зҡ„дёҖжқЎж•°жҚ®дёӯзҡ„ event timeпјҢеңЁжұҮжҠҘжҢҮж Үж—¶дҪҝз”ЁеҪ“еүҚзі»з»ҹж—¶й—ҙ - event timeгҖӮ
и®°еҪ•иҜ»еҸ–еҲ°ж•°жҚ®зҡ„зі»з»ҹж—¶й—ҙ-ж•°жҚ®дёӯзҡ„ event timeпјҢзӣҙжҺҘжұҮжҠҘе·®еҖјгҖӮ
delay = еҪ“еүҚзі»з»ҹж—¶й—ҙ вҖ“ ж•°жҚ®дәӢ件时й—ҙ(event time)
иҜҙжҳҺпјҡеҸҚеә”еӨ„зҗҶж•°жҚ®зҡ„иҝӣеәҰжғ…еҶөгҖӮ
fetch_delay = иҜ»еҸ–еҲ°ж•°жҚ®зҡ„зі»з»ҹж—¶й—ҙ- ж•°жҚ®дәӢ件时й—ҙ(event time)
иҜҙжҳҺпјҡеҸҚеә”е®һж—¶и®Ўз®—зҡ„е®һйҷ…еӨ„зҗҶиғҪеҠӣгҖӮ
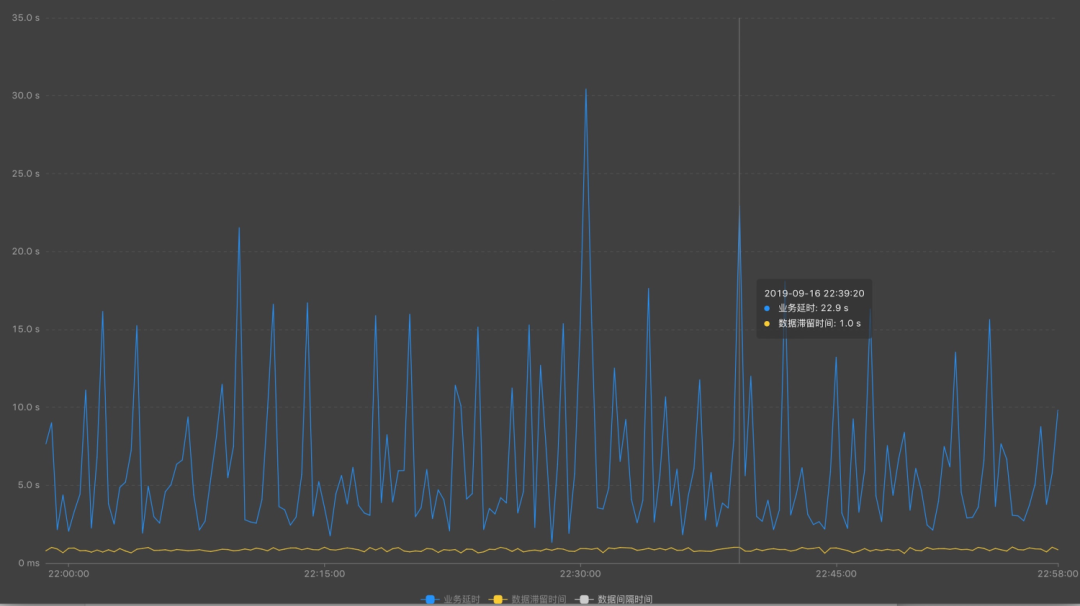
д»ҺдёҠжёёжәҗеӨҙпјҢжҹҘзңӢжҜҸдёӘжәҗеӨҙ并еҸ‘жғ…еҶө
жҳҜеҗҰдёҠжёёж•°жҚ®зЁҖз–ҸеҜјиҮҙ
дҪңдёҡжҖ§иғҪй—®йўҳ

Flink Failover дё»иҰҒжңүдёӨзұ»пјҢдёҖзұ»жҳҜ Job Manager зҡ„ FailoverпјҢиҝҳжңүдёҖзұ»жҳҜ Task Manager зҡ„ FailoverгҖӮ
Yarn й—®йўҳ вҖ“ иө„жәҗйҷҗеҲ¶
HDFS й—®йўҳ - Jar еҢ…иҝҮеӨ§пјҢHDFS ејӮеёё
JobManager иө„жәҗдёҚи¶іпјҢж— жі•е“Қеә” TM жіЁеҶҢ
TaskManager еҗҜеҠЁиҝҮзЁӢдёӯејӮеёё
йҮҚеҗҜзӯ–з•Ҙй…ҚзҪ®й”ҷиҜҜ
йҮҚеҗҜж¬Ўж•°иҫҫеҲ°дёҠйҷҗ
2.еӨ„зҗҶж–№ејҸ
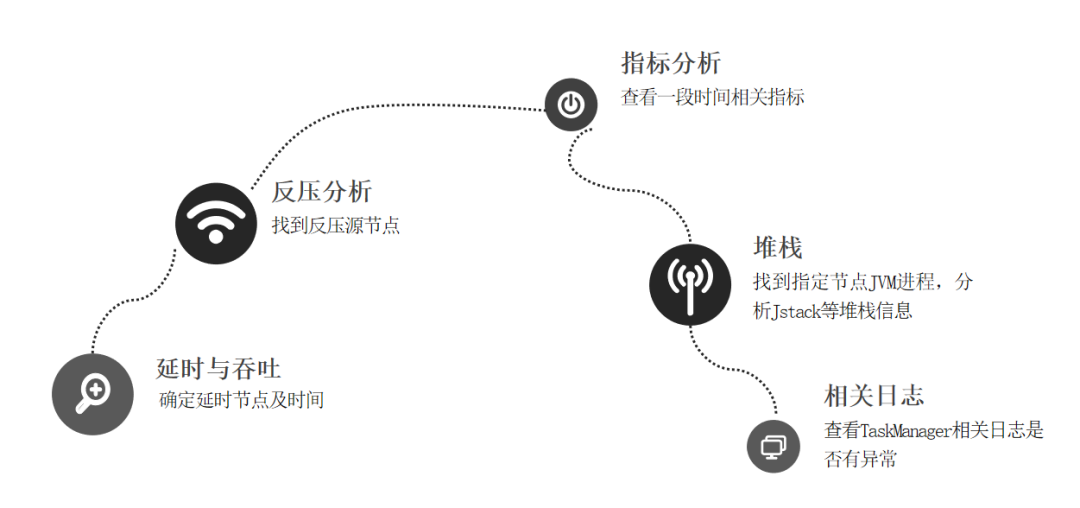
йҖҡиҝҮ delayгҖҒfetch_delay еҲӨж–ӯжҳҜеҗҰдёҠжёёзЁҖз–ҸеҜјиҮҙ延时жҲ–иҖ…дҪңдёҡжҖ§иғҪдёҚи¶іеҜјиҮҙ延时
зЎ®е®ҡ延时еҗҺпјҢйҖҡиҝҮеҸҚеҺӢеҲҶжһҗпјҢжүҫеҲ°еҸҚеҺӢиҠӮзӮ№
еҲҶжһҗеҸҚеҺӢиҠӮзӮ№жҢҮж ҮеҸӮж•°
йҖҡиҝҮеҲҶжһҗ JVM иҝӣзЁӢжҲ–иҖ…е Ҷж ҲдҝЎжҒҜ
йҖҡиҝҮжҹҘзңӢ TaskManager зӯүж—Ҙеҝ—
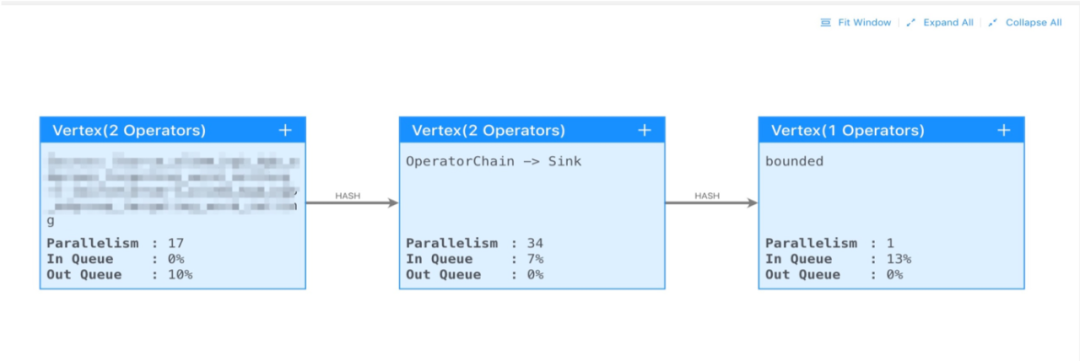
и§ӮеҜҹ延时дёҺ tps жҢҮж Үд№Ӣй—ҙе…іиҒ”пјҢжҳҜеҗҰз”ұдәҺ tps зҡ„ејӮеёёеўһй«ҳпјҢеҜјиҮҙдҪңдёҡжҖ§иғҪдёҚ足延时
жүҫеҲ°еҸҚеҺӢзҡ„жәҗеӨҙгҖӮ
иҠӮзӮ№д№Ӣй—ҙзҡ„ж•°жҚ®дј иҫ“ж–№ејҸ shuffle/rebalance/hashгҖӮ
иҠӮзӮ№еҗ„并еҸ‘зҡ„еҗһеҗҗжғ…еҶөпјҢеҸҚеҺӢжҳҜдёҚжҳҜз”ұдәҺж•°жҚ®еҖҫж–ңеҜјиҮҙгҖӮ
дёҡеҠЎйҖ»иҫ‘пјҢжҳҜеҗҰжңүжӯЈеҲҷпјҢеӨ–йғЁзі»з»ҹи®ҝй—®зӯүгҖӮIO/CPU 瓶йўҲпјҢеҜјиҮҙиҠӮзӮ№зҡ„жҖ§иғҪдёҚи¶ігҖӮ
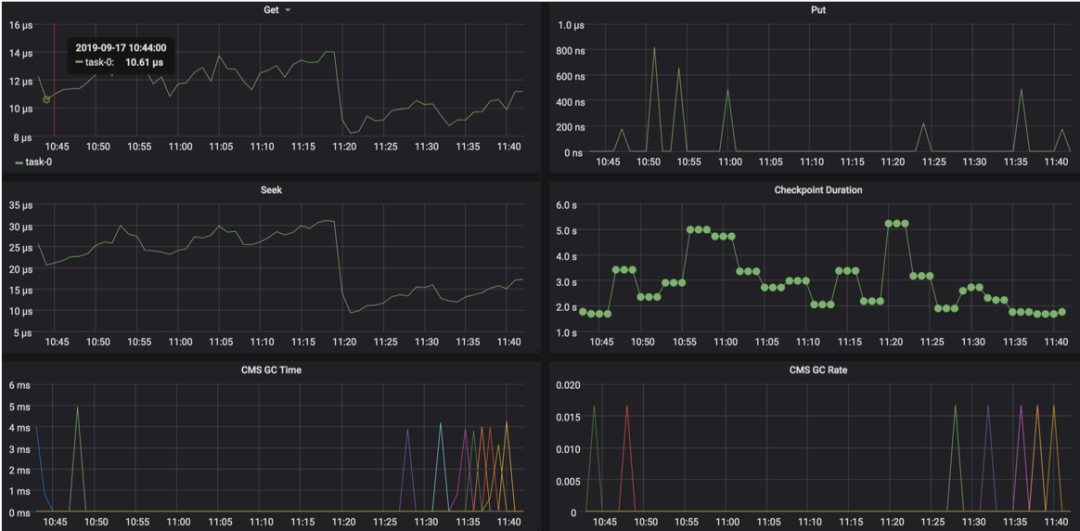
GC иҖ—ж—¶еӨҡй•ҝ
зҹӯж—¶й—ҙеҶ…еӨҡж¬Ў GC
state жң¬ең°зЈҒзӣҳзҡ„ IO жғ…еҶө
еӨ–йғЁзі»з»ҹи®ҝ问延时зӯүзӯү
еңЁ TaskManager жүҖеңЁиҠӮзӮ№,жҹҘзңӢзәҝзЁӢ TIDгҖҒCPU дҪҝз”Ёжғ…еҶөпјҢзЎ®е®ҡжҳҜ CPUпјҢиҝҳжҳҜ IO й—®йўҳгҖӮ
ps H -p ${javapid} -o user,pid,ppid,tid,time,%cpu,cmd#иҪ¬жҚўдёә16иҝӣеҲ¶еҗҺжҹҘзңӢtidе…·дҪ“е Ҷж Ҳjstack ${javapid} > jstack.log

еўһеҠ еҸҚеҺӢиҠӮзӮ№зҡ„并еҸ‘ж•°гҖӮ
и°ғж•ҙиҠӮзӮ№иө„жәҗпјҢеўһеҠ CPUпјҢеҶ…еӯҳгҖӮ
жӢҶеҲҶиҠӮзӮ№пјҢе°Ҷ chain иө·жқҘзҡ„ж¶ҲиҖ—иө„жәҗиҫғеӨҡзҡ„ operator жӢҶеҲҶгҖӮ
дҪңдёҡжҲ–йӣҶзҫӨдјҳеҢ–пјҢйҖҡиҝҮдё»й”®жү“ж•ЈпјҢж•°жҚ®еҺ»йҮҚпјҢж•°жҚ®еҖҫж–ңпјҢGC еҸӮж•°пјҢJobmanager еҸӮж•°зӯүж–№ејҸи°ғдјҳгҖӮ
жҹҘзңӢдҪңдёҡ failover ж—¶жү“еҚ°зҡ„дёҖдәӣж—Ҙеҝ—дҝЎжҒҜ
жҹҘзңӢ failover зҡ„ Subtask жүҫеҲ°жүҖеңЁ Taskmanager иҠӮзӮ№
з»“еҗҲ Job/Taskmanager зӯүж—Ҙеҝ—дҝЎжҒҜ
з»“еҗҲ Yarn е’Ң OS зӯүзӣёе…іж—Ҙеҝ—
3.дҪңдёҡз”ҹе‘Ҫе‘Ёжңҹ
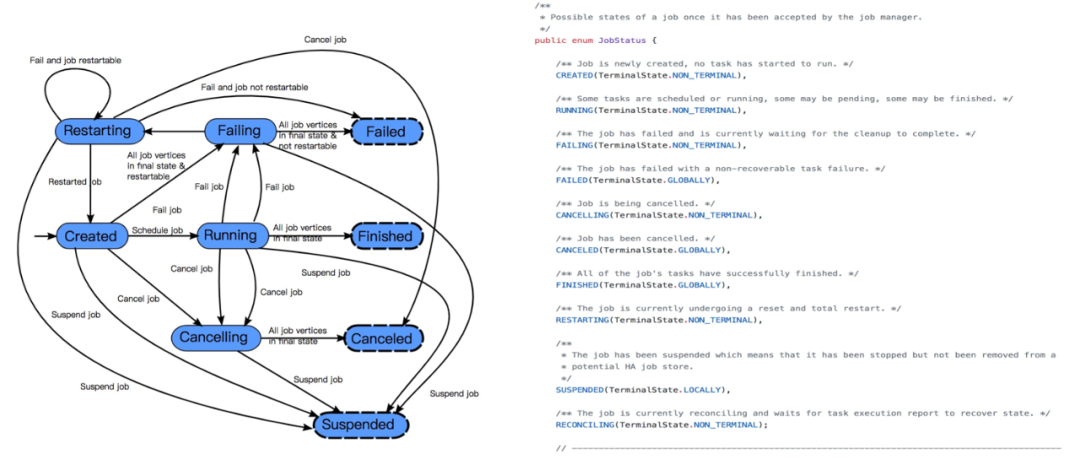
дёҠеӣҫдёӯеҸҜд»ҘзңӢеҲ°дҪңдёҡзҡ„ж•ҙдёӘзҠ¶жҖҒиҪ¬жҚўгҖӮд»ҺдҪңдёҡеҲӣе»әгҖҒеҲ°иҝҗиЎҢгҖҒеӨұиҙҘпјҢйҮҚеҗҜпјҢжҲҗеҠҹзӯүж•ҙдёӘз”ҹе‘Ҫе‘ЁжңҹгҖӮ
иҝҷйҮҢйңҖиҰҒжіЁж„Ҹзҡ„жҳҜ reconciling зҡ„зҠ¶жҖҒпјҢиҝҷдёӘзҠ¶жҖҒиЎЁзӨә yarn дёӯ AppMaster йҮҚж–°еҗҜеҠЁпјҢжҒўеӨҚе…¶дёӯзҡ„ JobManager жЁЎеқ—пјҢиҝҷдёӘдҪңдёҡдјҡд»Һ created иҝӣе…ҘеҲ° reconciling зҡ„зҠ¶жҖҒпјҢзӯүеҫ…е…¶д»– Taskmanager жұҮжҠҘпјҢжҒўеӨҚ JobManager зҡ„ failoverпјҢ然еҗҺд»Һ reconciling еҶҚеҲ°жӯЈеёё runningгҖӮ
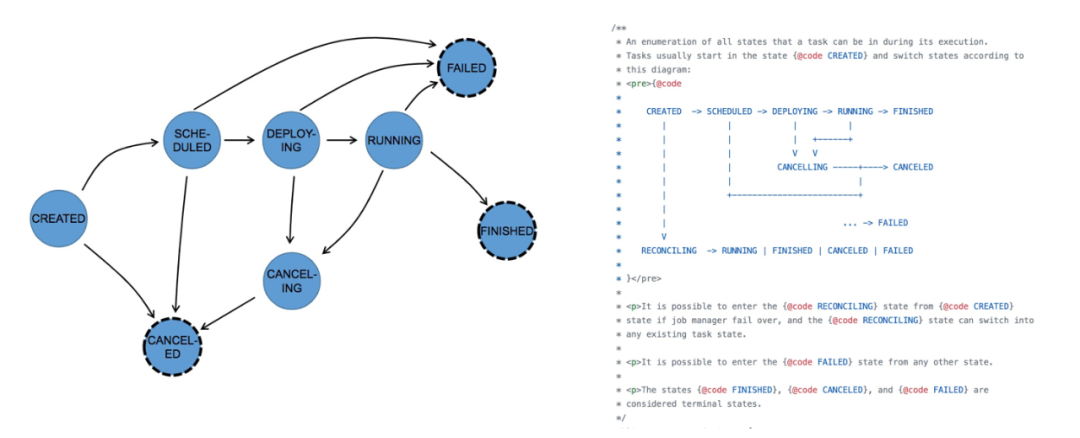
дёҠеӣҫжҳҜдҪңдёҡзҡ„ Task зҠ¶жҖҒиҪ¬жҚўпјҢйңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢдҪңдёҡзҠ¶жҖҒеӨ„дәҺ running зҠ¶жҖҒж—¶пјҢ并дёҚж„Ҹе‘ізқҖдҪңдёҡдёҖе®ҡеңЁиҝҗиЎҢж¶Ҳиҙ№дҝЎжҒҜгҖӮеңЁжөҒејҸи®Ўз®—дёӯеҸӘжңүзӯүжүҖжңүзҡ„ task йғҪеңЁ running ж—¶пјҢдҪңдёҡжүҚз®—зңҹжӯЈиҝҗиЎҢгҖӮ
йҖҡиҝҮи®°еҪ•дҪңдёҡеҗ„дёӘйҳ¶ж®өзҡ„зҠ¶жҖҒеҸҳеҢ–пјҢеҪўжҲҗз”ҹе‘Ҫе‘ЁжңҹпјҢжҲ‘们иғҪеҫҲжё…жҘҡең°еұ•зӨәдҪңдёҡжҳҜд»Җд№Ҳж—¶еҖҷејҖе§ӢиҝҗиЎҢгҖҒд»Җд№Ҳж—¶еҖҷеӨұиҙҘпјҢд»ҘеҸҠ taskmanager failover зӯүе…ій”®дәӢ件пјҢиҝӣдёҖжӯҘиғҪеҲҶжһҗеҮәйӣҶзҫӨдёӯжңүеӨҡе°‘дёӘдҪңдёҡжӯЈеңЁиҝҗиЎҢпјҢеҪўжҲҗ SLA ж ҮеҮҶгҖӮ
4.е·Ҙе…·еҢ–з»ҸйӘҢ
еҰӮдҪ•еҺ»иЎЎйҮҸдёҖдёӘдҪңдёҡжҳҜеҗҰжӯЈеёёпјҹ
延时дёҺеҗһеҗҗ
еҜ№дәҺ Flink дҪңдёҡжқҘиҜҙпјҢжңҖе…ій”®зҡ„жҢҮж Үе°ұжҳҜ延时е’ҢеҗһеҗҗгҖӮеңЁеӨҡе°‘ TPS ж°ҙдҪҚзҡ„жғ…еҶөдёӢпјҢдҪңдёҡжүҚдјҡејҖе§Ӣ延时.
еӨ–йғЁзі»з»ҹи°ғз”Ё
д»ҺжҢҮж ҮдёҠиҝҳеҸҜд»Ҙе»әз«ӢеҜ№еӨ–йғЁзі»з»ҹи°ғз”Ёзҡ„иҖ—ж—¶з»ҹи®ЎпјҢжҜ”еҰӮиҜҙз»ҙиЎЁ joinпјҢsink еҶҷе…ҘеҲ°еӨ–йғЁзі»з»ҹйңҖиҰҒж¶ҲиҖ—еӨҡе°‘ж—¶й—ҙпјҢжңүеҠ©дәҺжҲ‘们жҺ’йҷӨеӨ–йғЁзҡ„дёҖдәӣзі»з»ҹејӮеёёзҡ„дёҖдәӣеӣ зҙ гҖӮ
еҹәзәҝз®ЎзҗҶ
е»әз«ӢжҢҮж Үеҹәзәҝз®ЎзҗҶгҖӮжҜ”еҰӮиҜҙ state и®ҝй—®иҖ—ж—¶пјҢе№іж—¶жІЎжңү延时зҡ„ж—¶еҖҷпјҢstate и®ҝй—®иҖ—ж—¶жҳҜеӨҡе°‘пјҹжҜҸдёӘ checkpoint зҡ„ж•°жҚ®йҮҸеӨ§жҰӮжҳҜеӨҡе°‘пјҹеңЁејӮеёёжғ…еҶөдёӢпјҢиҝҷдәӣйғҪжңүеҠ©дәҺжҲ‘们еҜ№ Flink зҡ„дҪңдёҡзҡ„й—®йўҳиҝӣиЎҢжҺ’жҹҘгҖӮ
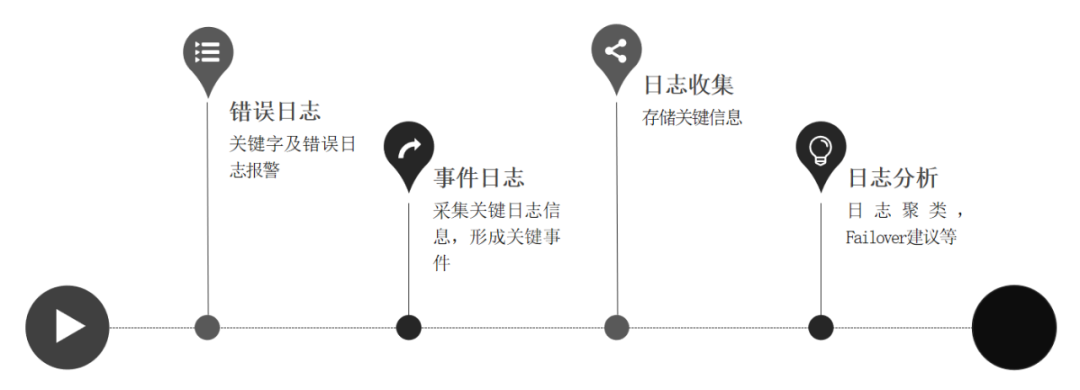
й”ҷиҜҜж—Ҙеҝ—
JobManager жҲ–иҖ… TaskManager зҡ„е…ій”®еӯ—еҸҠй”ҷиҜҜж—Ҙеҝ—жҠҘиӯҰгҖӮ
дәӢ件ж—Ҙеҝ—
JobManager жҲ–иҖ… TaskManager зҡ„зҠ¶жҖҒеҸҳеҢ–еҪўжҲҗе…ій”®дәӢ件记еҪ•гҖӮ
еҺҶеҸІж—Ҙеҝ—收йӣҶ
еҪ“дҪңдёҡз»“жқҹеҗҺпјҢжғіиҰҒеҲҶжһҗй—®йўҳпјҢйңҖиҰҒд»Һ Yarn зҡ„ History Server жҲ–е·Із»ҸйҮҮйӣҶзҡ„ж—Ҙеҝ—зі»з»ҹдёӯжүҫеҺҶеҸІдҝЎжҒҜгҖӮ
ж—Ҙеҝ—еҲҶжһҗ
жңүдәҶ JobManagerпјҢTaskManager зҡ„ж—Ҙеҝ—д№ӢеҗҺпјҢеҸҜд»ҘеҜ№еёёи§Ғзҡ„ failover зұ»еһӢиҝӣиЎҢиҒҡзұ»пјҢж ҮжіЁеҮәдёҖдәӣеёёи§Ғзҡ„ failoverпјҢжҜ”еҰӮиҜҙ OOM жҲ–иҖ…дёҖдәӣеёёи§Ғзҡ„дёҠдёӢжёёи®ҝй—®зҡ„й”ҷиҜҜзӯүзӯүгҖӮ
дҪңдёҡжҢҮж Ү/дәӢ件 - TaskmanagerпјҢJobManager
Yarn дәӢ件 - иө„жәҗжҠўеҚ пјҢNodeManager Decommission
жңәеҷЁејӮеёё - е®•жңәгҖҒжӣҝжҚў
Failover ж—Ҙеҝ—иҒҡзұ»
еңЁеҒҡдәҶиҝҷдәӣжҢҮж Үе’Ңж—Ҙеҝ—зҡ„еӨ„зҗҶд№ӢеҗҺпјҢеҸҜд»ҘеҜ№еҗ„组件зҡ„дәӢ件иҝӣиЎҢе…іиҒ”пјҢжҜ”еҰӮиҜҙеҪ“ TaskManager failover ж—¶пјҢжңүеҸҜиғҪжҳҜеӣ дёәжңәеҷЁзҡ„ејӮеёёгҖӮд№ҹеҸҜд»ҘйҖҡиҝҮ Flink дҪңдёҡи§Јжһҗ Yarn зҡ„дәӢ件пјҢе…іиҒ”дҪңдёҡдёҺ Container иө„жәҗжҠўеҚ пјҢNodeManager дёӢзәҝзҡ„дәӢ件зӯүгҖӮ
е…ідәҺFlinkзҡ„еёёи§Ғй—®йўҳиҜҠж–ӯжҖқи·ҜжҳҜд»Җд№Ҳй—®йўҳзҡ„и§Јзӯ”е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢеҰӮжһңдҪ иҝҳжңүеҫҲеӨҡз–‘жғ‘жІЎжңүи§ЈејҖпјҢеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“дәҶи§ЈжӣҙеӨҡзӣёе…ізҹҘиҜҶгҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ