网络爬虫,又被称为“网页蜘蛛,网络机器人”,在FOAF社区中间,经常被称为“网页追逐者”。网络爬虫,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。

网络爬虫,按照系统结构和实现技术,大致可以分为:“通用网络爬虫、聚焦网络爬虫、增量式网络爬虫、深层网络爬虫”等四种不同类型。实际上,网络爬虫系统,通常是由几种爬虫技术相结合实现的。
一、 通用网络爬虫
通用网络爬虫,又称“全网爬虫”,爬行对象从一些种子URL(统一资源定位符) 扩充到整个万维网,主要为“门户站点搜索引擎”和“大型Web服务提供商”采集数据。由于商业原因,它们的技术细节很少被公布出来。这类网络爬虫的爬行范围和数量巨大,对于爬行速度和存储空间要求较高,对于爬行页面的顺序要求相对较低,同时由于等待刷新的页面太多,通常采用“并行工作”的方式,但需要较长时间才能刷新一次页面。通用网络爬虫,虽然存在着一定的缺陷,但它适用于为搜索引擎平台搜索广泛的主题,有较强的应用价值。
二、聚焦网络爬虫
聚焦网络爬虫,又称“主题网络爬虫”,是指选择性地爬行,那些与预先定义好的主题相关的页面的网络爬虫。和通用网络爬虫相比,聚焦网络爬虫只需要爬行与主题相关的页面,极大地节省了硬件和网络资源,保存的页面也由于数量少而更新快,还可以很好地满足一些特定人群对特定领域信息的需求。
聚焦网络爬虫和通用网络爬虫相比,增加了“链接评价模块”以及“内容评价模块”。聚焦网络爬虫爬行策略实现的关键是,评价页面内容和链接的重要性。不同的方法计算出的重要性不同,由此导致链接的访问顺序也不同。
三、增量式网络爬虫
是指对已下载网页采取增量式更新,和只爬行新产生的或者已经发生变化网页的爬虫,它能够在一定程度上保证,所爬行的页面是尽可能新的页面。
和周期性爬行和刷新页面的网络爬虫相比,增量式爬虫只会在需要的时候爬行新产生或发生更新的页面 ,并不重新下载没有发生变化的页面,可有效减少数据下载量,及时更新已爬行的网页,减小时间和空间上的耗费,但是增加了爬行算法的复杂度和实现难度。
四、深层网络爬虫
Web 页面,按存在方式可以分为“表层网页”和“深层网页”。表层网页是指传统搜索引擎可以索引的页面,以超链接可以到达的静态网页为主构成的 Web 页面。
深层网页是那些大部分内容不能通过静态链接获取的、隐藏在搜索表单后的,只有用户提交一些关键词才能获得的 Web 页面。例如:那些用户注册后内容才可见的网页,就属于深层网页。
随着计算机网络的迅速发展,万维网成为大量信息的载体,如何有效地提取并利用这些信息成为一个巨大的挑战。搜索引擎,例如传统的“通用搜索引擎”平台:Google(谷歌)、Yahoo!(雅虎)、百度等,作为一个辅助人们检索万维网信息的工具,成为互联网用户访问万维网的入口和渠道。
但是,这些“通用搜索引擎平台”也存在着一定的局限性,如:
1、 不同领域、不同职业、不同背景的用户,往往具有不同的检索目的和需求,通用搜索引擎所返回的结果,包含了大量用户并不关心的网页,或者与用户搜索结果无关的网页。
2、 通用搜索引擎的目标是,实现尽可能大的网络覆盖率,有限的搜索引擎服务器资源,与无限的网络数据资源之间的矛盾将进一步加深。
3、 万维网数据形式的丰富和网络技术的不断发展,图片、数据库、音频、视频多媒体等不同数据大量出现,通用搜索引擎往往对这些信息含量密集,且具有一定结构的数据无能为力,不能很好地发现和获取。
4、通用搜索引擎,大多提供基于“关键字”的检索,难以支持根据语义信息提出的查询。
为了解决上述问题,定向抓取相关网页资源的“聚焦网络爬虫”应运而生。聚焦网络爬虫,是一个自动下载网页的程序,它根据既定的抓取目标,有选择的访问万维网上的网页与相关的链接,获取所需要的信息。
与“通用网络爬虫”不同,聚焦网络爬虫并不追求大的覆盖,而是将目标定为抓取“与某一特定主题内容相关的网页”,为面向主题的用户查询,准备数据资源。
“聚焦网络爬虫”的工作原理以及关键技术概述:
网络爬虫,是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。
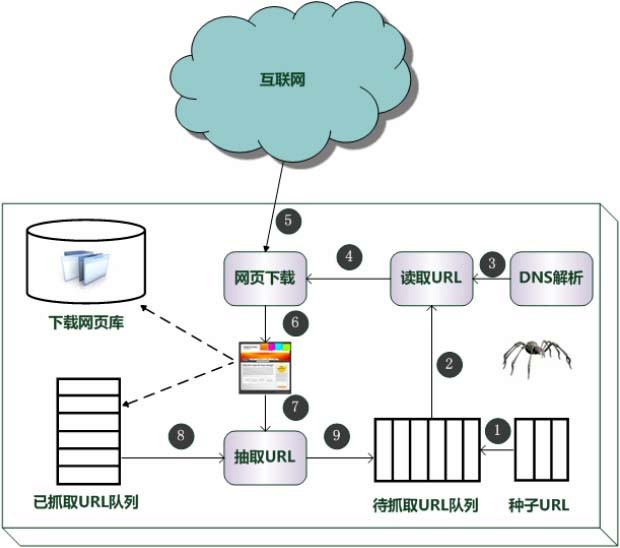
传统爬虫,从一个或若干初始网页的URL(统一资源定位符)开始,获得初始网页上的URL(统一资源定位符),在抓取网页的过程中,不断从当前页面上抽取新的URL(统一资源定位符)放入队列,直到满足系统的一定停止条件。
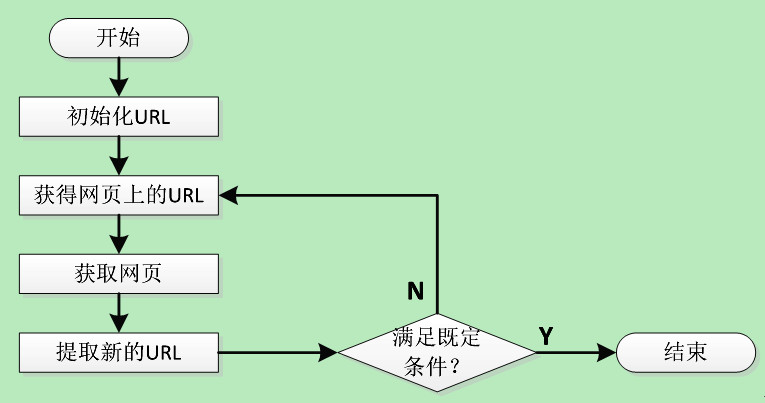
“聚焦网络爬虫”的工作流程较为复杂,需要根据一定的“网页分析算法”过滤与主题无关的链接,保留有用的链接,并将其放入等待抓取的URL(统一资源定位符)队列。然后,它将根据一定的搜索策略,从队列中选择下一步要抓取的网页URL(统一资源定位符),并重复上述过程,直到达到系统的某一条件时停止。
另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索。对于“聚焦网络爬虫”来说,这一过程所得到的分析结果,还可能对以后的抓取过程给出反馈和指导。
相对于通用网络爬虫,聚焦网络爬虫还需要解决三个主要问题:
1、对抓取目标的描述或定义;
2、对网页或数据的分析与过滤;
3、对URL(统一资源定位符)的搜索策略。
网络爬虫遇到的问题:
早在2007 年底,互联网上的网页数量就已经超出160 亿个,研究表明接近30%的页面是重复的。动态页面的存在,客户端、服务器端脚本语言的应用,使得指向相同Web信息的 URL(统一资源定位符)数量呈指数级增长。
上述特征使得网络爬虫面临一定的困难,主要体现在 Web信息的巨大容量,使得爬虫在给定的时间内,只能下载少量网页。有研究表明,没有哪个搜索引擎能够索引超出16%的互联网Web 页面,即使能够提取全部页面,也没有足够的空间来存储。
为了提高爬行效率,爬虫需要在单位时间内尽可能多的获取高质量页面,这是它面临的难题之一。
当前有五种表示页面质量高低的方式:1、页面与爬行主题之间的相似度;2、页面在 Web 图中的入度大小;3、指向它的所有页面平均权值之和;4、页面在 Web 图中的出度大小;5、页面的信息位置。
为了提高爬行速度,网络爬虫通常会采取“并行爬行”的工作方式,这种工作方式也导致了新的问题:
1、重复性(并行运行的爬虫或爬行线程同时运行时,增加了重复页面);
2、质量问题(并行运行时,每个爬虫或爬行线程只能获取部分页面,导致页面质量下降);
3、通信带宽代价(并行运行时,各个爬虫或爬行线程之间不可避免要进行一些通信,需要耗费一定的带宽资源)。
并行运行时,网络爬虫通常采用三种方式:
1、独立方式(各个爬虫独立爬行页面,互不通信);
2、动态分配方式(由一个中央协调器动态协调分配 URL 给各个爬虫);
3、静态分配方式(URL 事先划分给各个爬虫)。
亿速云,作为一家专业的IDC(互联网数据中心)业务服务提供商、拥有丰富行业积淀的专业云计算服务提供商,一直专注于技术创新和打造更好的服务品质,致力于为广大用户,提供高性价比、高可用性的“裸金属服务器、云服务器、高防服务器、高防IP、香港服务器、日本服务器、美国服务器、SSL证书”等专业产品与服务。
