历史的尘埃
Unix作为一个举世闻名的操作系统已有40余年的历史,围绕着这个古老的操作系统的发展又衍生出了一系列外围软件生态群,其中一个非常重要的组件就是shell。它是操作系统最外层的接口,负责直接面向用户交互并提供内核服务,包括命令行接口(CLI)或图形界面接口(GUI)两种形式。以CLI为例,它提供一套命令规范,是一种解释性语言,将用户输入经过解释器(interpreter)输出使其转化成真正的系统调用,实现人机交互的功能。
和操作系统一样,shell也经历了一个漫长的演变史。如今大部分资料讲述最古老的shell都是从1977年的Bourne Shell说起的,它最初移植到Unix V7上,被追认整个shell家族成员的鼻祖,后来的种群都是从其身上分支出来的。
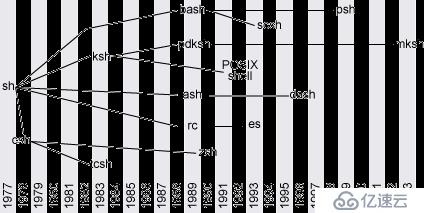
对于1977年之前的历史很多资料大多一笔带过或略过不提。事实上,第一个移植到Unix上的shell却不是Steve Bourne写的,早在1975年5月,贝尔实验室就对外发布了第一个广泛传播的Unix版本——Unix V6(之前开发的版本只供内部研究之用),其根目录下的/bin/sh是第一个Unix自带的shell,由Ken Thompson写的,因此也被称为Thompson Shell。甚至,更早可以追溯到1971年的时候,Thompson Shell就作为一个独立于内核的应用程序而实现了,只不过从1975年正式问世到1977年被取代,短短两年的寿命使得它很少为大多数人所认识。
关于Thompson Shell被取代的原因在后文中会给出说明,这里着重介绍一下该shell本身的一些技术细节。坦白讲,关于Thompson Shell的资料有点稀缺,但至少还能从网上找到源代码和在线文档。Thompson Shell本身是由一个不足900行代码的解释器和一些外部命令工具组件(utilities)构成,用K&R C写成,下面给出各个组件的相关源码和文档链接。
- 解释器sh:解析各种shell命令,包括内置命令和外部命令;源码sh.c;安装路径/bin/sh;手册sh(1)。
- 内置命令手册包括chdir(1),login(1),newgrp(1),shift(1),wait(1)。
下面是外部命令:
- exit命令:退出一个文件;源码exit.c;安装路径/bin/exit;手册exit(1)。
- goto命令:在一个文件内跳转shell控制流程;源码goto.c;安装路径/bin/goto;手册goto(1)。
- if命令:条件判断表达式,是test命令的前身;源码if.c;安装路径/bin/if), 手册if(1)。
- glob命令:扩展命令参数通配符;源码glob.c;安装路径/etc/glob;手册glob(8)。
命令结构和规范
尽管后来遭“埋汰”,Thompson Shell仍有着不容否认的历史地位,其最大的价值在于它奠定了shell命令语言结构和规范的基础,而且其解释器具有跨平台的可移植性,并影响到了后来包括Bourne Shell在内的各种脚本语言设计实现。下面我们就以其中5个特性重温一些大家已经耳熟能详的命令规范,你也可以通过sh(1)手册查看原始资料。
- 过滤器/管道线(filter/pipeline)。这绝对是要载入Unix史册的发明,创立者是Douglas McIlroy,Thompson Shell引入并实现了这个伟大的概念——一个或多个命令组成一根过滤器的链条,由’|'或’^'符号分隔。除最后一个命令之外,每个命令的标准输出都被作为下一个命令的标准输入。这样每个命令都作为一个独立的进程来运行,并通过管道与邻近的进程相连接。圆括弧内的命令序列整体上可以替代单个命令作为过滤器实现,比如用户可以输入”(A;B)|C”。
- 命令序列和后台进程。分号’;'指示多个命令序列化执行。’&’符号指示该命令在后台异步执行,使得前面的管道线不必等待其终止,仅仅报告一个进程id,这样用户以后可以通过kill命令与它通信。有益于进程管理。
- I/O重定向。它利用了Unix设计上的一个重要特性——一切皆文件,用三个符号表示:”重定向输出,如果文件不存在则创建它,如果文件存在则截断它;’>>’追加模式重定向输出,如果文件不存在则创建它,如果文件存在则追加输出至末尾处。
- 通配符扩展(globbing)。通配符的概念源自于正则表达式,使得解释器智能地处理用户不完全输入,比如记不清文件名、一次性输入多个文件等。’?'匹配任意单一字符;’*'匹配任意字符串(包括空串);成对’['和']‘定义了字符集合一个类,可匹配方括号内任意成员,用’-'两端可指定一系列连续字符匹配范围。
- 参数传递。这里主要引入了位置参数和选项参数的概念:’$n’指示shell调用的第n个参数替代;还定义了两个选项参数’-t’和’-c’,前者用于交互,导致shell从标准输入中读入一行作为用户执行的系统命令,后者指示shell将附带的下一个参数作为命令执行(可正确处理换行符),是对’-t’的补充,特别是调用者已经读取了命令其中某些字符的情况下。如果不带选项参数则直接读取文件名
解释器的原理与实现
接下来马上要进入核心部分了,为了搞懂shell解释器原理,我们要对其整个工作流程做个描述(这里给出一份带注解的sh.c源码剖析)。读过《编译原理》的同学知道,解释器的实现跟编译器差不多,只不过省略了生成目标代码这一步,直接将用户输入(shell命令)转化成输出(系统调用)。软件前端是一致的,包括预处理、词法扫描、语法分析和语义分析,最后还要附加一个进程管理。当然相较于现代编译器,Thompson Shell解释器在算法和规模上都要简单得多,不过原理上是相通的,何况年代上要比Lex & Yacc还要早。麻雀虽小,五脏俱全,对于初学者来说,从Thompson Shell去入手编译原理或许不失为一种好选择。
预处理(preprocessor)
同C预处理器需要事先将源代码中包含的宏和头文件展开一样,Thompson Shell首先需要处理命令中的选项参数和位置参数。选项参数有两种’-t’和’-c’,决定了shell从标准输入还是参数缓存中读取字符(见sh(1))。此外字符序列中还要处理反斜杠’\’,判断是转义字符还是行接续符,前者对下一个字符设置引用标识,表明做普通字符处理,后者将紧邻其后换行符过滤掉。
位置参数是美元符号’$’打头的,后带一个数字,如’$n’,预处理器对shell命令参数从头开始计数,返回数字n指定的参数位置。如果遇上double’$$’,则表示当前的进程标识,调用getpid()获取。
注意到预处理器需要一次读取多个字符,这样就会多读一个不必要的字符。对此解释器提供了一种预读(peek)方式,即每次从输入流读取一个字符时,放入一个预读缓存里(只有一个int大小的堆栈),也叫回退(push back)。此后先从预读缓存中读取,如果缓存被读完,则从输入流中读取。
词法扫描(lexical scanning)
经过预处理后的字符序列将被切割成为一系列词法记号(token),安置在token列表中,扫描器将对以下几类字符做如下处理。
- 空格和tab:简单过滤。
- 引号:需要成对出现,字符本身被过滤,一对引号之间所有字符都被设置引用标识,作为一个token。
- 元字符:如’&’,’|'等,字符本身作为一个单独token。
- 其他字符:一律填充token,直到碰上以上字符分隔为止。
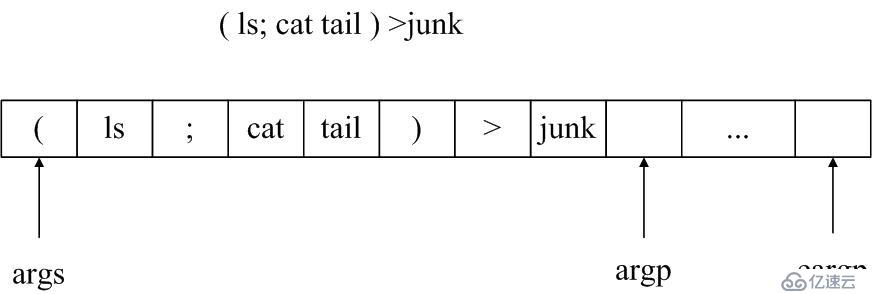
举一个例子,当我们输入命令”(ls; cat tail) >junk”,那么token列表映像将是这样的:
语法分析(syntax parser)
语法分析就是将token列表中的元素作为表达式(expression)并以节点为单位构建语法树,简单命令是一个表达式,而复合命令以及命令序列是多个表达式的组合。Thompson Shell中以简单数组作为语法树的容器,实际上这是结构体的一种变形,只不过每个成员字段大小都一样(都是sizeof int)而已。一个语法树节点最多有6个字段(大小根据类型可变),分别是
- DTYP(节点类型):每个节点都有唯一的类型,又分为四种——TCOM(简单命令)、TPAR(复合命令)、TFIL(过滤器/管道线)、TLST(命令序列)。
- DLEF(左子树节点):相当于链表指针,根据DTYP定义有所不同。如过滤器类型左子树节点为前一个命令的输出重定向文件,右子树节点为后一个命令的输入重定向文件。
- DRIG(右子树节点):同上。
- DFLG(节点属性):这是个标志位(flag),决定该节点包含命令的属性以及以什么样的状态执行。
- DSPR(子命令):两重含义,对于简单命令,该字段为空;对于复合命令,该字段指向子语法树节点。
- DCOM(命令字符):引用命令字符序列。
语法树节点生成顺序根据token列表中每个元素的优先级(priority)而定,首先遍历整个列表,找到优先级最高的token作为根节点,再分别生成左右子树,这是一种最简单的自顶向下(top-down)解决方案。各个token优先级视DTYP字段而定
| 优先级 | Token | DTYP |
| 第一级 | ‘&’ ’;’ ’\n’ | TLST |
| 第二级 | ‘|’ ’^’ | TFIL |
| 第三级 | ’(‘ ’)’ | TPAR |
| 第四级 | 其它字符 | TCOM |
语法树的构建过程中还使用了一种基于“有限状态机(finite-state machine)”的动态规划算法,其实现是将整个逻辑流程划分为四个状态:syntax、syn1、syn2、syn3,对应于上面token优先级,程序在每个状态下都生成一个相应类型的节点,同时还生成四种策略,以决议下一步将转移到何种状态(根据优先级搜索对应的token)。这个四种策略分别是
- 生成左子树:左边token列表递进到下层状态。
- 生成右子树:右边token列表并回溯到上层状态或递归调用。
- 找不到对应token:保持原有token列表递进到下层状态。
- 生成节点:直接返回节点。
当我们遍历完整个token列表后,程序总是能返回最初的调用点,即根节点上,从而生成一棵完整的语法树。这种算法的好处是程序员不必关注具体实现的每个细枝末节,只要关注相应的状态并制定对应的转移策略即可。还值得一提的是每个转移策略都是发生在赋值语句或返回语句上,并使用函数实参保存临时变量,这样就避免了调用次数过多导致堆栈溢出。
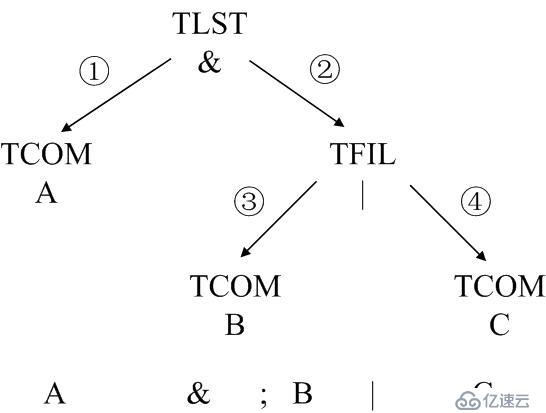
依旧举两个个例子,比如命令”A & ; B | C”对应的语法树
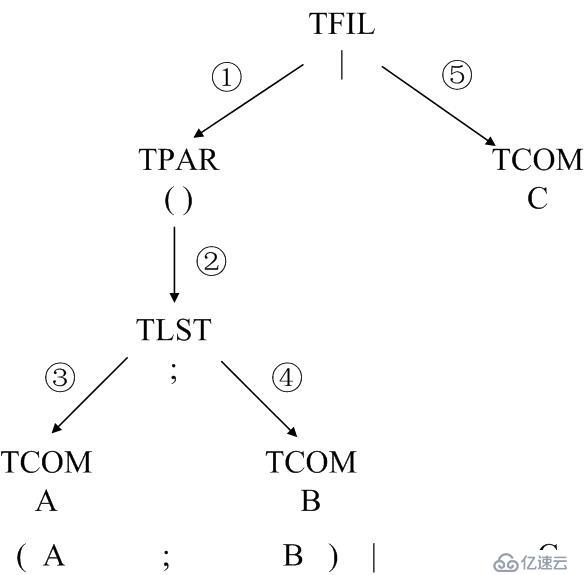
命令”(A ; B) | C”对应的语法树:
语义分析(Semantic Analyzer)
语法分析仅仅停留在token表达式合法性层面上,它并不知道该表达式是否有意义,比如哪些命令是要后台运行,哪些命令的I/O被重定向到管道线上,通配符该如何扩展等等,这时候要靠语义分析了。这里的“语义”体现在对特殊字符的动态处理以及语法树节点的字段设置,根据上下文(context)而定。比如对于元字符’>’,我们要判断输出重定向到哪个文件,是截断还是追加。对于通配符’?'、’*'和’[...]‘,我们要决定对哪些字符进行扩展,这些在/etc/glob中专门处理。对于语法树节点,除了自身固有属性之外,还需要继承上层节点的属性,以及下推属性到下层子树节点,下面列了一张表格说明。
| DTYP | DLEF/DRIG | DFLG | DSPR |
| TLST | 可以为空,也可以是其它节点,类型可以是TLST/TFIL/TCOM | 自身属性为0;如果带’&’,则下推属性FINT|FAND|FPRS到左右子树(忽略信号、后台异步,打印pid) | 空 |
| TFIL | 必须同时存在、,类型只能是TCOM或TPAR | 自身属性继承自上层TLST;下推FPIN到左子树节点;下推FPOU到右子树节点。 | 空 |
| TPAR | 空 | 继承上层的TLST和TFIL;如果是追加模式重定向输出,加上FCAT;如果是复合命令中最后一个子命令,加上FPAR, 将不会fork子进程。 | 子命令 |
| TCOM | 左子树节点为输入重定向文件,右子树为节点输出重定向文件。 | 空 |
执行命令(Executor)
当前面一系列步骤之后,如果错误计数为0,则解释器从语法树的根节点开始,深度优先遍历所有节点,并根据前面语法和语义分析得到的类型和属性,一一执行所包含的命令,以生成最后的系统调用。
对于命令序列(TLST)节点,从左至右顺序执行子树节点命令。
对于过滤器(TFIL)节点,创建管道文件句柄,作为左右子树的重定向文件。
对于简单命令(TCOM)和复合命令(TPAR)节点,首先筛选出系统内置命令(built-in),对于剩下的外部命令则fork一个子进程执行它。如果是复合命令中最后一个子命令,那么仍在原来的进程上执行而不必创建新进程。可执行文件路径按先后顺序搜索:①本地路径;②/bin;③/usr/bin。
多进程环境下,特别要注意文件句柄管理。命令间共享标准输入输出设备之外,还会重定向到管道线,而父进程在fork之后子进程会获取一份文件句柄拷贝,所以父进程必须在fork之后立即关闭闲置的管道线句柄(如果有的话)以免造成资源泄漏,子进程也将在重定向之后关闭管道线句柄。
对于后台命令需要打印pid,但不需要响应中断信号,父进程也不必等待子进程终止。其余进程命令执行中可捕获中断信号,并转入相应的处理函数。
解释器用内置的errno全局变量保存进程终止状态,并生成终止报告(termination report),系统调用wait()用于返回终止进程的pid并输出报告消息索引。
孰优孰劣
尽管Thompson Shell是一款优秀的命令解释器,还产生了多项历史创举,但遗憾的是依然得不到命运女神的垂青,这要归咎于其自身的缺陷——功能单一、命令分散、控制流过于简单,尚无法用来编写脚本(script)。随着Unix日益壮大,它已经无法应付趋于繁杂的编程项目了。那时还出现了一个叫John Mashey的人写的PWB Shell(又叫做Mashey Shell),基于Thompson Shell做了些改进,扩展了命令集,增加了shell变量,还增加了if-then-else-endif,for,while等控制逻辑。不幸的是它比Thompson Shell更短命,因为1977年它遇上了一个强劲的对手。
没错,那就是Bourne Shell,它的主要优点是真正实现了结构化脚本编程,比之前的shell实现得都要好,更要命的是它与前两个shell都不兼容,于是一场标准化的论战开始了。在David G. Korn(ksh作者)写的“ksh – An Extensible High Level Language”一文中提及,Steve Bourne和John Mashey在三次连续的Unix用户组集会上争论他们各自的理由。在这些集会之间,各自增进他们的shell来拥有对方的功能。还设立了一个委员会来选择标准shell,最终还是选择了Bourne shell作为标准。
于是从Unix V7开始就有了前面所说的”Bourne Shell Family”。然而历史上没有完美的技术,随着八、九十年代操作系统迅猛发展,针对Bourne Shell的诟病也越来越多了。在解释器本身实现上,我看到网上一个对其评价是“universally considered to be one of the most horrible C code ever written”,至于原因去看一下mac.h就知道了,包括基本运算符、关键字在内的大量宏定义使得整个代码看上去简直不是C写的,也许Bourne是想把解释器打造成自己独特的风格吧,也难怪后来的bash以“born again”命名就是对其祖先的戏谑性调侃。另外内存管理上的一些毛病带来平台可移植性问题,至于其中的技术细节有点高级,超出本文范畴。
Thompson Again Shell?
虽然历史没有给Thompson Shell一个机会,但它并非就此同Unix V6那样一同沦为开源博物馆上的古老“化石”。作为出自顶级***之手的作品,作为伴随Unix那样伟大操作系统一同曾经流行计算机的产物,至今仍受国内外程序员的缅怀,或将其改写,或为其作注。比如国外一个站点v6shell.org上就实现了一个免费开源的可移植性shell,它兼容并扩充原来的Thompson Shell并且可用来做脚本编程。再比如中国程序员寒蝉退士在其个人博客上发布了一个注解版,并对原版做了一些改写,主要是将K&R C转为ANSI C,并且符合POSIX规范,使原本晦涩难懂的源码变得清晰易读起来。正是因为接触到他的版本激起了我对老Unix的考古兴趣,才有了这篇“考古笔记”。我在想不知今后会不会像bash那样,出一个tash来呢?
一些感想
本来全文应该就此结束了,但此时此刻不禁想多说几句。这篇笔记当初并非有意而为之,在hacking源码的过程中感想积累多了也就逐渐成章了。看代码、作注解、查资料、写此文,前后历经四个多礼拜,是在繁杂的工作中“挤乳沟”挤出来的零散时间片拼凑起来的,虽然文字不长但也算耗费了一番心血,酸甜苦辣心中自明,体会到踏上社会之后潜下心做研究之艰难。如今面对这样一份不到900行写成的,没有一行多余的代码,简洁(clarity)、干净(clean)、快速(fast),这就是Pure C的魅力,我深为这种厚重的编程功力所折服,正所谓“大道至简”吧。虽然要完全弄懂它需要很多时间,但我相信这种代价却是值得的。
最后再八卦一下,2011年Dennis Ritchie去世了,有人生前问过他“学C需要多久才能成为熟练开发者并写出重要产品代码?”,Ritchie回答“我不知道,我从没去学过C。”(I don’t know. I never had to learn C.)其实这里已经给出了答案——那就是没有比去阅读Unix源代码更好的选择了,某种意义上C语言就是为Unix而生的。

参考资料
The Unix Heritage Society:Unix社区遗产,上面有v6和v7以及其它一些衍生版本的操作系统源代码。
The Traditional Bourne Shell Family:Bourne Shell家族简史。
v6shell:osh,一个基于Thompson Shell的开源可移植性old shell。
寒蝉退士的博客:Thompson Shell的一个注解版。
Evolution of shells in Linux:简述Linux Shell演变史。
附录一个中文注释的 shell源码