您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
可以把 SQL 分为两个部分:数据操作语言 (DML) 和 数据定义语言 (DDL)。
SQL (结构化查询语言)是用于执行查询的语法。但是 SQL 语言也包含用于更新、插入和删除记录的语法。
查询和更新指令构成了 SQL 的 DML 部分:
SELECT - 从数据库表中获取数据
UPDATE - 更新数据库表中的数据
DELETE - 从数据库表中删除数据
INSERT INTO - 向数据库表中插入数据
SQL 的数据定义语言 (DDL) 部分使我们有能力创建或删除表格。我们也可以定义索引(键),规定表之间的链接,以及施加表间的约束。
SQL 中最重要的 DDL 语句:
CREATE DATABASE - 创建新数据库
ALTER DATABASE - 修改数据库
CREATE TABLE - 创建新表
ALTER TABLE - 变更(改变)数据库表
DROP TABLE - 删除表
CREATE INDEX - 创建索引(搜索键)
DROP INDEX - 删除索引
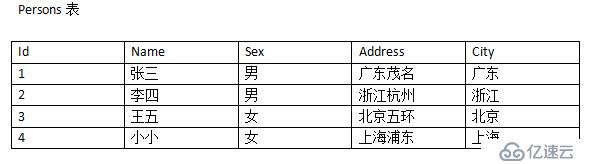
use test
create table Persons(
Id int primary key,
Name varchar(14) not null,
Sex varchar(13) not null,
Address varchar(20) not null,
City varchar(20) not null
)
insert into Persons values(1,'张三','男','广东茂名','广东');
insert into Persons values(2,'李四','男','浙江杭州','浙江');
insert into Persons values(3,'王五','女','北京五环','北京');
insert into Persons values(4,'小小','女','上海浦东','上海');
select * from Persons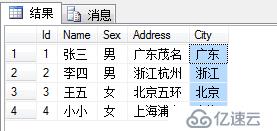
语法:
SELECT 列名称 FROM 表名称
查看某列数据
select Name from Persons 可以查询多列用“,”隔开
select Name,Sex from Persons
select * from sysdatabases; #查看所以库 (*代表所有)
use tongji #切换tongji库
select * from sys.tables #查看所有表查看schema,user的存储过程
SELECT * FROM SYS.DATABASE_PRINCIPALS
SELECT * FROM SYS.SCHEMAS
SELECT * FROM SYS.SERVER_PRINCIPALS查看DEPT表所有内容
select * from DEPT 查看DEPT表中deptno为101的内容
select * from DEPT where deptno='101';select distinct语句
关键词 DISTINCT 用于返回唯一不同的值
语法:
SELECT DISTINCT 列名称 FROM 表名称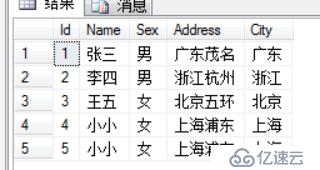
select distinct Name,Sex from Persons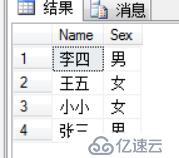
SQL SELECT INTO----可用于创建表的备份文件
SQL SELECT INTO 语法
您可以把所有的列插入新表:
SELECT * INTO new_table_name [IN externaldatabase]
FROM old_tablename或者只把希望的列插入新表:
SELECT column_name(s) INTO new_table_name [IN externaldatabase]
FROM old_tablename制作 "Persons" 表的备份复件
select * into Persons_backup from Persons;子句可用于向另一个数据库中拷贝表:
SELECT *INTO Persons IN 'Backup.mdb'
FROM Persons如果我们希望拷贝某些域,可以在 SELECT 语句后列出这些域:
SELECT LastName,FirstNameINTO Persons_backup
FROM Personsuse master
create database test创建test登陆用户,密码为123,默认库为tongji
create login test with password='123',default_database=tongji为登陆用户创建数据库用户test1(create user),默认库为dbo
create user test1 for login test with default_schema=dbo创建DEPT表(要先去到库里执行)
create table DEPT
(
DEPTNO int primary key,
DNAME VARCHAR(14),
LOC VARCHAR(13)
)数据类型(data_type)规定了列可容纳何种数据类型。下面的表格包含了SQL中最常用的数据类型:
数据类型 描述
integer(size)
int(size)
smallint(size)
tinyint(size) 仅容纳整数。在括号内规定数字的最大位数。
decimal(size,d)
numeric(size,d) 容纳带有小数的数字。
"size" 规定数字的最大位数。"d" 规定小数点右侧的最大位数。
char(size) 容纳固定长度的字符串(可容纳字母、数字以及特殊字符)。
在括号中规定字符串的长度。
varchar(size) 容纳可变长度的字符串(可容纳字母、数字以及特殊的字符)。
在括号中规定字符串的最大长度。
date(yyyymmdd) 容纳日期。
您可以在表中创建索引,以便更加快速高效地查询数据。
用户无法看到索引,它们只能被用来加速搜索/查询。
注释:更新一个包含索引的表需要比更新一个没有索引的表更多的时间,这是由于索引本身也需要更新。因此,理想的做法是仅仅在常常被搜索的列(以及表)上面创建索引。
SQL CREATE INDEX 语法
在表上创建一个简单的索引。允许使用重复的值:
CREATE INDEX index_name ON table_name (column_name)
注释:"column_name" 规定需要索引的列。
SQL CREATE UNIQUE INDEX 语法
在表上创建一个唯一的索引。唯一的索引意味着两个行不能拥有相同的索引值。
CREATE UNIQUE INDEX index_name ON table_name (column_name)
假如您希望索引不止一个列,您可以在括号中列出这些列的名称,用逗号隔开:
create index sed on Persons (City,Name);语法
INSERT INTO 表名称 VALUES (值1, 值2,....)
我们也可以指定所要插入数据的列:
INSERT INTO table_name (列1, 列2,...) VALUES (值1, 值2,....)
插入数据
insert into DEPT VALUES(101,'ACCOUNTING','NEW YORK');
INSERT INTO DEPT VALUES(102,'RESEARCH','DALLAS');
INSERT INTO DEPT VALUES(103,'SALES','CHICAGO');
INSERT INTO DEPT VALUES(104,'OPERATIONS','BOSTON');--指定列中插入数据
insert into Persons (Name,Sex) values('大大','女')语法:
UPDATE 表名称 SET 列名称 = 新值 WHERE 列名称 = 某值
为Name是大大的人添加Address
update Persons set Address='南京' where Name='大大'为Name是大大的人修改Address,City
update Persons set Address='中山',City='南京' where Name='大大'DELETE 语句用于删除表中的行。
语法
DELETE FROM 表名称 WHERE 列名称 = 值
删除ID号为5的内容
delete from Persons where Id=5可以在不删除表的情况下删除所有的行。这意味着表的结构、属性和索引都是完整的:
DELETE FROM table_name
或者:
DELETE * FROM table_name通过使用drop语句,可以轻松地删除索引、表和数据库。
SQL DROP TABLE 语句
DROP TABLE 语句用于删除表(表的结构、属性以及索引也会被删除):
DROP TABLE 表名称
SQL DROP DATABASE 语句
DROP DATABASE 语句用于删除数据库:
DROP DATABASE 数据库名称
用于 Microsoft SQLJet (以及 Microsoft Access) 的语法:
DROP INDEX index_name ON table_nameALTER TABLE 语句用于在已有的表中添加、修改或删除列。
SQL ALTER TABLE 语法
如需在表中添加列,请使用下列语法:
ALTER TABLE table_name
ADD column_name datatype
要删除表中的列,请使用下列语法:
ALTER TABLE table_name
DROP COLUMN column_name
注释:某些数据库系统不允许这种在数据库表中删除列的方式 (DROP COLUMN column_name)。
要改变表中列的数据类型,请使用下列语法:
ALTER TABLE table_name
ALTER COLUMN column_name datatype
在Order表里增加一列
alter table Orders add Id nchar(10); 在Persons表里添加一列,增加内容
alter table Persons add Birthday datetime;
update Persons set Birthday='1991-03-26' where Id=1删除Birthday列
alter table Persons drop column Birthday**语法:
SELECT 列名称 FROM 表名称 WHERE 列 运算符 值
下面的运算符可在 WHERE 子句中使用:
操作符 描述
= 等于
<> 不等于
大于
< 小于
= 大于等于
<= 小于等于
BETWEEN 在某个范围内**
LIKE 搜索某种模式
注释:在某些版本的 SQL 中,操作符 <> 可以写为 !=。
查询居住在北京的人select * from Persons where City='北京';注意:SQL 使用单引号来环绕文本值(大部分数据库系统也接受双引号)。如果是数值,请不要使用引号。
and |or运算符
and:两者皆成立select * from Persons where Name='王五' and Sex='女';or:一者成立便可
select * from Persons where Name='王五' or Sex='女';我们也可以把 AND 和 OR 结合起来(使用圆括号来组成复杂的表达式):
select * from Persons where (Name='王五' or Sex='女') and Address='北京五环';order by语句
ORDER BY 语句用于根据指定的列对结果集进行排序。
ORDER BY 语句默认按照升序对记录进行排序。
如果您希望按照降序对记录进行排序,可以使用 DESC 关键字。
例:以字母顺序显示公司名称(从小到大)select * from Orders order by Company逆序(从大到小)
select * from Orders order by Company desc以逆字母顺序显示公司名称,并以数字顺序显示顺序号:
select * from Orders order by Company desc,OrderNo asc
TOP 子句用于规定要返回的记录的数目。
对于拥有数千条记录的大型表来说,TOP 子句是非常有用的。
注释:并非所有的数据库系统都支持 TOP 子句。
SQL Server 的语法:
SELECT TOP number|percent column_name(s) FROM table_name
查询Persons表中头两条记录
select top 2 * from Persons"Persons" 表中选取 50% 的记录
select top 50 percent * from PersonsLIKE 操作符用于在 WHERE 子句中搜索列中的指定模式。
SQL LIKE 操作符语法
SELECT column_name(s) FROM table_name WHERE column_name LIKE pattern
查询City以“广”开头, %通配符
select * from Persons where City like '广%'like %1---以1结尾
like 1%---以1开头
like %1%---包含1内容
not like %1%---包含1内容
IN 操作符允许我们在 WHERE 子句中规定多个值
SQL IN 语法
SELECT column_name(s) FROM table_name WHERE column_name IN (value1,value2,...)
取出City为广东和北京的人
select * from Persons where City in('广东','北京')操作符 BETWEEN ... AND 会选取介于两个值之间的数据范围。这些值可以是数值、文本或者日期。
SQL BETWEEN 语法
SELECT column_name(s) FROM table_name WHERE column_name
BETWEEN value1 AND value2
重要事项:不同的数据库对 BETWEEN...AND 操作符的处理方式是有差异的。某些数据库会列出介于 "Adams" 和 "Carter" 之间的人,但不包括 "Adams" 和 "Carter" ;某些数据库会列出介于 "Adams" 和 "Carter" 之间并包括 "Adams" 和 "Carter" 的人;而另一些数据库会列出介于 "Adams" 和 "Carter" 之间的人,包括 "Adams" ,但不包括 "Carter" 。
所以,请检查你的数据库是如何处理 BETWEEN....AND 操作符的!
表的 SQL Alias 语法
SELECT column_name(s)
FROM table_name
AS alias_name
列的 SQL Alias 语法
SELECT column_name AS alias_name
FROM table_name
Alias 实例: 使用表名称别名
假设我们有两个表分别是:"Persons" 和 "Product_Orders"。我们分别为它们指定别名 "p" 和 "po"。
现在,我们希望列出 "John Adams" 的所有定单。
我们可以使用下面的 SELECT 语句:
SELECT po.OrderID, p.LastName, p.FirstName
FROM Persons AS p, Product_Orders AS po
WHERE p.LastName='Adams' AND p.FirstName='John'不使用别名的 SELECT 语句:
SELECT Product_Orders.OrderID, Persons.LastName, Persons.FirstName
FROM Persons, Product_Orders
WHERE Persons.LastName='Adams' AND Persons.FirstName='John'从上面两条 SELECT 语句您可以看到,别名使查询程序更易阅读和书写。
在表中存在至少一个匹配时,INNER JOIN 关键字返回行。
**INNER JOIN 关键字语法
SELECT columnname(s) FROM tablename1 INNER JOIN tablename2
ON tablename1.columnname=tablename2.columnname
注释:INNER JOIN 与 JOIN 是相同的。
SQL LEFT JOIN 关键字
LEFT JOIN 关键字会从左表 (table_name1) 那里返回所有的行,即使在右表 (table_name2) 中没有匹配的行。
LEFT JOIN 关键字语法
SELECT column_name(s)
FROM table_name1
LEFT JOIN table_name2
ON table_name1.column_name=table_name2.column_name
注释:在某些数据库中, LEFT JOIN 称为 LEFT OUTER JOIN。
SQL RIGHT JOIN 关键字
RIGHT JOIN 关键字会右表 (table_name2) 那里返回所有的行,即使在左表 (table_name1) 中没有匹配的行。
RIGHT JOIN 关键字语法
SELECT column_name(s)
FROM table_name1
RIGHT JOIN table_name2
ON table_name1.column_name=table_name2.column_name
注释:在某些数据库中, RIGHT JOIN 称为 RIGHT OUTER JOIN。
SQL FULL JOIN 关键字
只要其中某个表存在匹配,FULL JOIN 关键字就会返回行。
FULL JOIN 关键字语法
SELECT column_name(s)
FROM table_name1
FULL JOIN table_name2
ON table_name1.column_name=table_name2.column_name
注释:在某些数据库中, FULL JOIN 称为 FULL OUTER JOIN。
use master
create database test
use test
create user test1 for login test with default_schema=dbo
exec sp_addrolemember 'db_owner','test1'
exec sp_addrolemember 'db_owner','test1'账号管理
禁用账号
alter login test disable
启用账号
alter login test enable;
登录账号改名
alter login test with name=test_t;
修改密码:
alter login test_t with password='123'
数据库用户改名
alter user test1 with name='test_1';
更改数据库用户
alter user test1 with default_schema=test;
删除数据库用户
drop user test1
删除登陆用户
drop login test_t
在搜索数据库中的数据时,SQL 通配符可以替代一个或多个字符。
SQL 通配符必须与 LIKE 运算符一起使用。
在 SQL 中,可使用以下通配符:
"Persons" 表中选取居住的城市以"广" 或 "北" 开头的人
select * from Persons where City like '[广北]%'"Persons" 表中选取居住的城市不以"广" 或 "北" 开头的人
select * from Persons where City like '[^广北]%'约束用于限制加入表的数据的类型。
可以在创建表时规定约束(通过 CREATE TABLE 语句),或者在表创建之后也可以(通过 ALTER TABLE 语句)。
我们将主要探讨以下几种约束:
NOT NULL
UNIQUE
PRIMARY KEY
FOREIGN KEY
CHECK
DEFAULT
SQL NOT NULL 约束
NOT NULL 约束强制列不接受 NULL 值。
NOT NULL 约束强制字段始终包含值。这意味着,如果不向字段添加值,就无法插入新记录或者更新记录。
下面的 SQL 语句强制 "Id_P" 列和 "LastName" 列不接受 NULL 值:
CREATE TABLE Persons
(
Id_P int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255)
)
SQL UNIQUE 约束
UNIQUE 约束唯一标识数据库表中的每条记录。
UNIQUE 和 PRIMARY KEY 约束均为列或列集合提供了唯一性的保证。
PRIMARY KEY 拥有自动定义的 UNIQUE 约束。
请注意,每个表可以有多个 UNIQUE 约束,但是每个表只能有一个 PRIMARY KEY 约束。
SELECT column_name(s) FROM table_name1
UNION
SELECT column_name(s) FROM table_name2
UNION 操作符用于合并两个或多个 SELECT 语句的结果集。
请注意,UNION 内部的 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每条 SELECT 语句中的列的顺序必须相同。
注释:默认地,UNION 操作符选取不同的值。如果允许重复的值,请使用 UNION ALL。
SELECT column_name(s) FROM table_name1
UNION ALL
SELECT column_name(s) FROM table_name2
另外,UNION 结果集中的列名总是等于 UNION 中第一个 SELECT 语句中的列名。
--use test
--go
--create table employees_China (
--E_ID int primary key,
--E_NAME VARCHAR(15) NOT NULL
--)
--INSERT INTO employees_China VALUES(01,'Zhuang,Hua')
--INSERT INTO employees_China VALUES(02,'Wang,Wei')
--INSERT INTO employees_China VALUES(03,'Yang,Ming')
--
--
--create table employees_USA (
--E_ID int primary key,
--E_NAME VARCHAR(15) NOT NULL
--)
--INSERT INTO employees_USA VALUES(01,'Adams,John')
--INSERT INTO employees_USA VALUES(02,'Bush,George')
--INSERT INTO employees_USA VALUES(03,'Yang,Ming')列出所有在中国和美国的不同的雇员名:
SELECT E_NAME FROM employees_USA UNION SELECT E_NAME FROM employees_China注释:这个命令无法列出在中国和美国的所有雇员。在上面的例子中,我们有两个名字相同的雇员,他们当中只有一个人被列出来了。UNION 命令只会选取不同的值。
SQL PRIMARY KEY 约束
PRIMARY KEY 约束唯一标识数据库表中的每条记录。
主键必须包含唯一的值。
主键列不能包含 NULL 值。
每个表都应该有一个主键,并且每个表只能有一个主键。
SQL CREATE VIEW 语法
CREATE VIEW view_name AS
SELECT column_name(s)
FROM table_name
WHERE condition
注释:视图总是显示最近的数据。每当用户查询视图时,数据库引擎通过使用 SQL 语句来重建数据。
您可以使用下面的语法来更新视图:
SQL CREATE OR REPLACE VIEW Syntax
CREATE OR REPLACE VIEW view_name AS
SELECT column_name(s)
FROM table_name
WHERE conditionSQL 撤销视图
您可以通过 DROP VIEW 命令来删除视图。
SQL DROP VIEW Syntax
DROP VIEW view_name下面的表格列出了 SQL Server 中最重要的内建日期函数:
函数 描述
GETDATE() 返回当前日期和时间
DATEPART() 返回日期/时间的单独部分
DATEADD() 在日期中添加或减去指定的时间间隔
DATEDIFF() 返回两个日期之间的时间
CONVERT() 用不同的格式显示日期/时间
SQL AVG() 语法
SELECT AVG(column_name) FROM table_name
查询平均值
select avg(OrderPrice) as OrderNoavg from Orders;我们希望找到 OrderPrice 值高于 OrderPrice 平均值的客户。
select Company from Orders where OrderPrice >(select avg(OrderPrice) from Orders)COUNT() 函数返回匹配指定条件的行数。
SQL COUNT(column_name) 语法
COUNT(column_name) 函数返回指定列的值的数目(NULL 不计入):
SELECT COUNT(column_name) FROM table_name
SQL COUNT() 语法
COUNT() 函数返回表中的记录数:
SELECT COUNT(*) FROM table_name
SQL COUNT(DISTINCT column_name) 语法
COUNT(DISTINCT column_name) 函数返回指定列的不同值的数目:
SELECT COUNT(DISTINCT column_name) FROM table_name
注释:COUNT(DISTINCT) 适用于 ORACLE 和 Microsoft SQL Server,但是无法用于 Microsoft Access。
SQL COUNT(column_name) 实例
我们拥有下列 "Orders" 表:
O_Id OrderDate OrderPrice Customer
1 2008/12/29 1000 Bush
2 2008/11/23 1600 Carter
3 2008/10/05 700 Bush
4 2008/09/28 300 Bush
5 2008/08/06 2000 Adams
6 2008/07/21 100 Carter
现在,我们希望计算客户 "Carter" 的订单数。
我们使用如下 SQL 语句:
SELECT COUNT(Customer) AS CustomerNilsen FROM Orders
WHERE Customer='Carter'以上 SQL 语句的结果是 2,因为客户 Carter 共有 2 个订单:
CustomerNilsen
2
查看表中总行数
SELECT COUNT(*) AS NUMBER FROM ORDERS去掉重复行
SELECT COUNT(DISTINCT Company) AS NUMBER FROM ORDERSFIRST() 函数返回指定的字段中第一个记录的值。
提示:可使用 ORDER BY 语句对记录进行排序。
SQL FIRST() 语法
SELECT FIRST(column_name) FROM table_name
sql2005不支持
MAX() 函数
MAX 函数返回一列中的最大值。NULL 值不包括在计算中。
SELECT MAX(column_name) FROM table_name
注释:MIN 和 MAX 也可用于文本列,以获得按字母顺序排列的最高或最低值。
查找OrderPrice列中最大值
select max(OrderPrice) as maxprice from OrdersMIN() 函数
MIN 函数返回一列中的最小值。NULL 值不包括在计算中。
SQL MIN() 语法
SELECT MIN(column_name) FROM table_name
注释:MIN 和 MAX 也可用于文本列,以获得按字母顺序排列的最高或最低值。
select min(OrderPrice) as maxprice from OrdersSUM 函数返回数值列的总数(总额)。
SQL SUM() 语法
SELECT SUM(column_name) FROM table_name
查看orderprice列总和
select sum(OrderPrice) as maxprice from Orders
GROUP BY 语句用于结合合计函数,根据一个或多个列对结果集进行分组。
SQL GROUP BY 语法
SELECT column_name, aggregate_function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name
我们希望查找每个客户的总金额(总订单)。
select Company,sum(OrderPrice)as sumprice from Orders group by CompanyHAVING 子句
在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与合计函数一起使用。
SELECT column_name, aggregate_function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name
HAVING aggregate_function(column_name) operator value
查找客户 "IBM" 或 "Apple" 拥有超过 1500 的订单总金额。
select Company,sum(OrderPrice)as sumprice from Orders where Company='IBM' OR Company='Apple' group by Company having sum(OrderPrice) >1500UPPER 函数把字段的值转换为大写。
SQL UPPER() 语法
SELECT UPPER(column_name) FROM table_name
全换成大写
select upper(Company) as upname from OrdersLOWER()函数
语法同上
全换成小写
select lower(Company) as upname from OrdersLEN 函数返回文本字段中值的长度。
SQL LEN() 语法
SELECT LEN(column_name) FROM table_name
取“Company” 的值的长度
select lEN(Company) as LENname from OrdersROUND 函数用于把数值字段舍入为指定的小数位数。
SQL ROUND() 语法
SELECT ROUND(column_name,decimals) FROM table_name
参数 描述
column_name 必需。要舍入的字段。
decimals 必需。规定要返回的小数位数
把名称和价格舍入为最接近的整数
select ProductName,round(UnitPrice,0) as roundprice from productsNOW 函数返回当前的日期和时间。
提示:如果您在使用 Sql Server 数据库,请使用 getdate() 函数来获得当前的日期时间。
SQL NOW() 语法
SELECT NOW() FROM table_name
select ProductName,UnitPrice, getdate() as date from products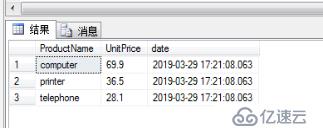
修改日期格式
select ProductName,UnitPrice, CONVERT( VARCHAR(10),getdate(),23) as date from products参考资料:
http://www.w3school.com.cn/sql/sql_view.asp
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。