жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
дҪҝз”ЁIBM WebSphere Portalжһ„е»әдјҒдёҡй—ЁжҲ·зі»з»ҹжҳҜз”ЁжҲ·жҜ”иҫғзқҝжҷәзҡ„дёҖдёӘйҖүжӢ©пјҢдҪҶжҳҜз”ұдәҺPortalдә§е“ҒжҜ”иҫғеӨҚжқӮпјҢе®•жңәжҲ–жҖ§иғҪдҪҺд№ҹйҖҡеёёжҳҜз”ЁжҲ·иҫғдёәеӨҙз–јзҡ„й—®йўҳгҖӮз»Ҹеёёжңүе®ўжҲ·й—ЁжҲ·дёҠзәҝеҗҺеҮәзҺ°йЎөйқўз©әзҷҪжҲ–ж— жі•и®ҝй—®пјҢз”ҡиҮіе®•жңәзҡ„й—®йўҳпјҢд»ӨдәәеӨҙз–јдёҚе·ІгҖӮжң¬ж–Үд»ҘIBM Portalеёёи§ҒжҖ§иғҪдҪҺдёӢжҲ–е®•жңәзҡ„еёёи§ҒеҺҹеӣ еҲҶжһҗпјҢ并д»Ҙ笔иҖ…еҚҒеҮ е№ҙзҡ„дә§е“Ғе®һж–Ҫз»ҸйӘҢжҸҗеҮәжҷ®дј—жҖ§зҡ„и§ЈеҶіжҺӘж–ҪгҖӮ
WebSphere PortalжҖ§иғҪ瓶йўҲйҖҡеёёиў«еҲ’еҲҶдёәеҰӮдёӢе…«еӨ§йҡ”зҰ»еҢәпјҢжҜҸдёӘйҡ”зҰ»еҢәзҡ„жҖ§иғҪдҪҺдёӢйғҪжңүеҸҜиғҪеёҰжқҘз”ЁжҲ·и®ҝй—®йҖҹеәҰж…ўгҖҒзі»з»ҹеӨұеҺ»е“Қеә”гҖҒз©әзҷҪйЎөгҖҒйЎөйқўж— жі•жҳҫзӨәз”ҡиҮіе®•жңәзҡ„жғ…еҶөгҖӮеҰӮеӣҫпјҡ
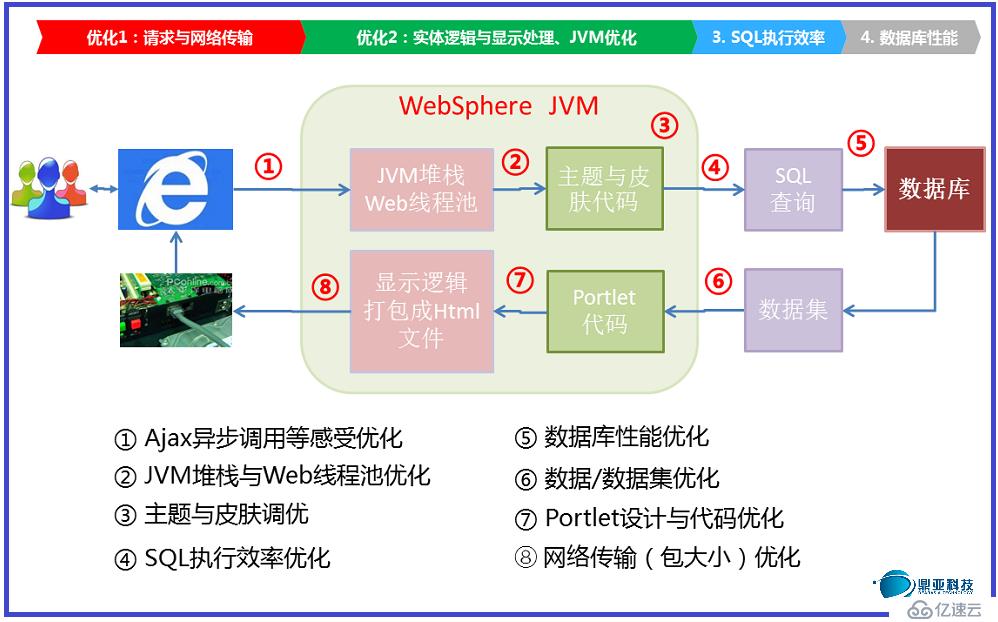
жҺҘдёӢжқҘжҲ‘们дҫқж¬Ўд»Ӣз»Қиҝҷе…«еӨ§йҡ”зҰ»еҢәзҡ„й—®йўҳзӮ№е’ҢжҖ§иғҪдјҳеҢ–зӯ–з•Ҙпјҡ
дёҖгҖҒAjaxејӮжӯҘи°ғз”Ёзӯүж„ҹеҸ—дјҳеҢ–пјҡ
AjaxејӮжӯҘи°ғз”Ёж„ҹеҸ—дјҳеҢ–жҢҮзҡ„жҳҜйҖҡиҝҮжҠҖжңҜжүӢж®өпјҢеңЁе…¶д»–ж–№йқўйғҪе·Із»ҸиҫҫеҲ°жңҖдҪідјҳеҢ–зҡ„еүҚжҸҗдёӢпјҢе……еҲҶеҲ©з”ЁејӮжӯҘи°ғз”ЁзӯүжҠҖжңҜпјҢжҸҗй«ҳз”ЁжҲ·йҖҹеәҰж„ҹеҸ—пјҢдҪҶе®һиҙЁдёҠпјҢзі»з»ҹзҡ„ж•ҙдҪ“жҖ§иғҪ并жңӘжҸҗеҚҮгҖӮ
пјҲдёҖпјүй—®йўҳеҲҶжһҗ
иҝҷз§Қжғ…еҶөйҖҡеёёеҮәзҺ°еңЁзҷ»еҪ•еҗҺиҝӣе…ҘйҰ–йЎөж—¶зҡ„дҪ“йӘҢдёҠпјҢе°Өе…¶жҳҜеҪ“йҰ–йЎөйғЁзҪІзҡ„PortletжҜ”иҫғеӨҡзҡ„ж—¶еҖҷпјҢжӣҙжңүз”ҡиҖ…пјҢеӨҡдёӘPortletиҰҒи°ғз”ЁеҗҺеҸ°зҡ„иө„жәҗжҲ–иҖ…йҖ»иҫ‘еӨ„зҗҶпјҢжҜҸдёӘPortletзҡ„е“Қеә”ж—¶й—ҙйғҪжҜ”иҫғж…ўпјҢеҰӮжһңиҰҒзӯүеҲ°жүҖжңүPortletеҲқе§ӢеҢ–е®ҢжҜ•й—ЁжҲ·йҰ–йЎөжүҚжҳҫзӨәеҮәжқҘпјҢйӮЈд№Ҳз”ЁжҲ·зӯүеҫ…зҡ„ж—¶й—ҙеҸҜжғіиҖҢзҹҘпјҢиҝҷе°ҶеёҰз»ҷз”ЁжҲ·йқһеёёе·®зҡ„дҪ“йӘҢгҖӮ
пјҲдәҢпјүдјҳеҢ–зӯ–з•Ҙ
IBM WebSphere PortalеҲҶдёәй—ЁжҲ·е®№еҷЁе’ҢPortletе®№еҷЁдёӨйғЁеҲҶз»„жҲҗпјҢPortalе®№еҷЁеҠ иҪҪе®ҢжҜ•еҗҺеҶҚеҠ иҪҪPortletе®№еҷЁгҖӮPortalе®№еҷЁеҠ иҪҪж—¶дё»иҰҒжҳҜзј–иҜ‘并еӨ„зҗҶдё»йўҳзҡ®иӮӨгҖҒе®№еҷЁиҝҗиЎҢжүҖдҫқиө–зҡ„еҗ„з§Қзұ»еә“гҖҒж•°жҚ®еә“зӯүиө„жәҗпјӣPortletе®№еҷЁеҲҷжҳҜе…Ҳжңүзҷ»еҪ•PortletдёҺLdapйҖҡдҝЎйүҙжқғпјҢд№ӢеҗҺжҜҸдёӘPortletиҝӣе…ҘinitпјҲпјүж–№жі•еҠ иҪҪеҗ„з§Қд»ҘжқҘжҸҗдәӨпјҢ然еҗҺиҝӣе…ҘdoServiceпјҲпјүеӨ„зҗҶеҗ„з§ҚдёҡеҠЎйҖ»иҫ‘пјҢеҫ—еҲ°еӨ„зҗҶз»“жһңе№¶дј иҫ“еӣһй—ЁжҲ·еҗҺпјҢз»ҹдёҖзј–иҜ‘жҲҗHtmlж јејҸпјҢдёҺй—ЁжҲ·е®№еҷЁзј–иҜ‘еҮәжқҘзҡ„Htmlж–Ү件е…ұеҗҢжӢјиЈ…жҲҗдёҖдёӘHtmlж–Ү件е‘ҲзҺ°еҮәжқҘгҖӮеӨҡдёӘPortletе®ҢжҲҗдёҡеҠЎйҖ»иҫ‘并иҝ”еӣһз»“жһңзҡ„ж—¶й—ҙй•ҝзҹӯдёҚдёҖпјҢзі»з»ҹй»ҳи®ӨиҰҒзӯүеҲ°жүҖжңүPortletеӣһдј е®ҢжүҖжңүж•°жҚ®еҗҺжүҚз»ҹдёҖе‘ҲзҺ°гҖӮйӮЈд№ҲпјҢе“Қеә”ж—¶й—ҙжңҖй•ҝзҡ„йӮЈдёӘPortletжүҖйңҖзҡ„ж—¶й—ҙе°ұжҲҗдёәжңЁжЎ¶дёҠжңҖзҹӯзҡ„йӮЈеқ—жңЁжқҝгҖӮе№ёеҘҪпјҢWebSphere Portalд»Һ7.0зүҲжң¬ејҖе§Ӣж”ҜжҢҒAjaxејӮжӯҘеҠ иҪҪжҠҖжңҜпјҢжң¬еұӮеӨ„зҗҶзҡ„дјҳеҢ–йҖ»иҫ‘жҳҜйҮҮз”ЁPortletејӮжӯҘеҠ иҪҪжҠҖжңҜпјҢеҚідҪҝеҪ“еҸӘжңү1дёӘPortletеӨ„зҗҶе®ҢжҜ•пјҢд№ҹдәӨз”ұй—ЁжҲ·е®№еҷЁжү“еҢ…е‘ҲзҺ°еҮәжқҘпјҢеҗҺз»ӯжҜҸдёӘPortletеӨ„зҗҶе®ҢжҜ•еҗҺйҖҗдёҖеҠ иҪҪпјҢзӣҙиҮіеҠ иҪҪе®ҢжҜ•гҖӮе°ұз”ЁжҲ·жқҘиҜҙпјҢд»–дјҡеңЁиҫғзҹӯзҡ„ж—¶й—ҙеҶ…е…ҲзңӢеҲ°й—ЁжҲ·йҰ–йЎөпјҢе’ҢеҮ дёӘPortletж Ҹзӣ®пјҢиҝҷж—¶еҖҷз”ЁжҲ·зҡ„жіЁж„ҸеҠӣиў«еҗёеј•еҲ°е·Із»Ҹе‘ҲзҺ°еҮәжқҘзҡ„PortletдёҠйқўпјҢеү©дҪҷеҮ дёӘйҖҗдёҖеҠ иҪҪзҡ„Portletз”ЁжҲ·дјҡйҷҚдҪҺж„ҹзҹҘпјҢжүҖд»Ҙж•ҙдҪ“дёҠз”ЁжҲ·зҡ„ж„ҹеҸ—иҫғеҘҪгҖӮ
иҝҷжҳҜдёҖз§Қи®ҫи®ЎжҖқжғіпјҢйңҖиҰҒеә”з”ЁеҲ°й—ЁжҲ·зі»з»ҹе»әи®ҫзҡ„еҗ„дёӘи§’иҗҪгҖӮдҫӢеҰӮпјҡйҰ–йЎөдё»йўҳзҡ®иӮӨйғЁеҲҶеҸҜиғҪи®ҫи®ЎжҲҗ6еј еӣҫзүҮжқҘеӣһж»ҡеҠЁпјҢеҪўжҲҗдёҖдёӘеҠЁз”»ж’ӯж”ҫзҡ„ж•ҲжһңгҖӮжҹҗдәӣжһҒз«ҜеңәжҷҜдёӢдҫӢеҰӮеҪ“зҪ‘з»ңдј иҫ“йҖҹеәҰиҫғдҪҺиҖҢ6еј еӣҫзүҮзҡ„дҪ“з§ҜеҸҲиҫғеӨ§ж—¶пјҢеҰӮжһңзӯүеҲ°6еј еӣҫзүҮе®Ңе…Ёдј иҫ“е®ҢжҜ•жүҚеҠ иҪҪеҠЁз”»ж’ӯж”ҫеҠҹиғҪпјҢеҲҷз”ЁжҲ·ж„ҹеҸ—д№ҹдјҡиҫғе·®пјҢеҸҳйҖҡзҡ„ж–№жі•жҳҜеҪ“дёӢиҪҪ第1еј еӣҫзүҮж—¶пјҢйҖҡиҝҮд»Јз ҒжҺ§еҲ¶е…Ҳе°Ҷиҝҷеј еӣҫзүҮжҳҫзӨәеҮәжқҘпјҢ然еҗҺзӯүе…¶дҪҷ5еј еӣҫзүҮдёӢиҪҪе®ҢжҜ•еҗҺеҶҚжү§иЎҢеҠЁз”»ж’ӯж”ҫйҖ»иҫ‘пјҢиҝҷж ·з”ЁжҲ·зҡ„ж„ҹеҸ—д№ҹдјҡеӨ§еӨ§жҸҗеҚҮгҖӮ
дәҢгҖҒJVMе Ҷж ҲдёҺWebзәҝзЁӢжұ дјҳеҢ–
JVMе Ҷж ҲдјҳеҢ–дёҺWebзәҝзЁӢжұ дјҳеҢ–жҢҮзҡ„жҳҜPortalе®№еҷЁжң¬иә«зҡ„JVMе’Ңе…¶д»–еҗ„йЎ№еҸӮж•°зҡ„дјҳеҢ–пјҢд№ҹе°ұжҳҜJVMе®№еҷЁжң¬иә«д»ҘеҸҠеһғеңҫеӣһ收зӯ–з•Ҙзҡ„й…ҚзҪ®гҖӮ
пјҲдёҖпјүй—®йўҳеҲҶжһҗ
WebSphere PortalжңҚеҠЎиҝҗиЎҢеңЁWebSphere Application Serverе®№еҷЁдёҠзҡ„дёҖдёӘзӢ¬з«ӢжңҚеҠЎеҷЁпјҢ既然жҳҜJVMе®№еҷЁе°ұдјҡжңүеӨ§е°ҸйҷҗеҲ¶гҖӮеӨ„зҗҶз”ЁжҲ·иҜ·жұӮзҡ„жҜҸдёӘйҖ»иҫ‘еӨ„зҗҶйғҪйңҖиҰҒеңЁJVMдёӯејҖиҫҹеҶ…еӯҳеҢәеҹҹпјҢз”ЁдәҺеӯҳеӮЁжҡӮеӯҳж•°жҚ®е…ұCPUеҸҠCPUзҡ„дәҢзә§зј“еӯҳи°ғеҸ–жү§иЎҢдәҢиҝӣеҲ¶иҝҗз®—гҖӮзү№еҲ«жҳҜжңүдәӣиҙЁйҮҸдёҚй«ҳзҡ„д»Јз ҒеңЁеҚ з”ЁеҶ…еӯҳеӨ„зҗҶе®Ңд№ӢеҗҺжІЎжңүеҸҠж—¶жү§иЎҢclearпјҲпјүж–№жі•жё…з©әиҮӘе·ұеҚ з”Ёзҡ„еҶ…еӯҳпјҢиҖҢеҚ•зӢ¬дҫқйқ JVMжң¬иә«зҡ„еһғеңҫеӣһ收еӨ„зҗҶжңәеҲ¶е…¶еӨ„зҗҶиғҪеҠӣжҳҜжңүйҷҗзҡ„гҖӮдәӢе®һдёҠпјҢ3.5Gзҡ„еҶ…еӯҳжҳҜеҫҲе®№жҳ“иў«еҚ з”Ёе…үзҡ„гҖӮ
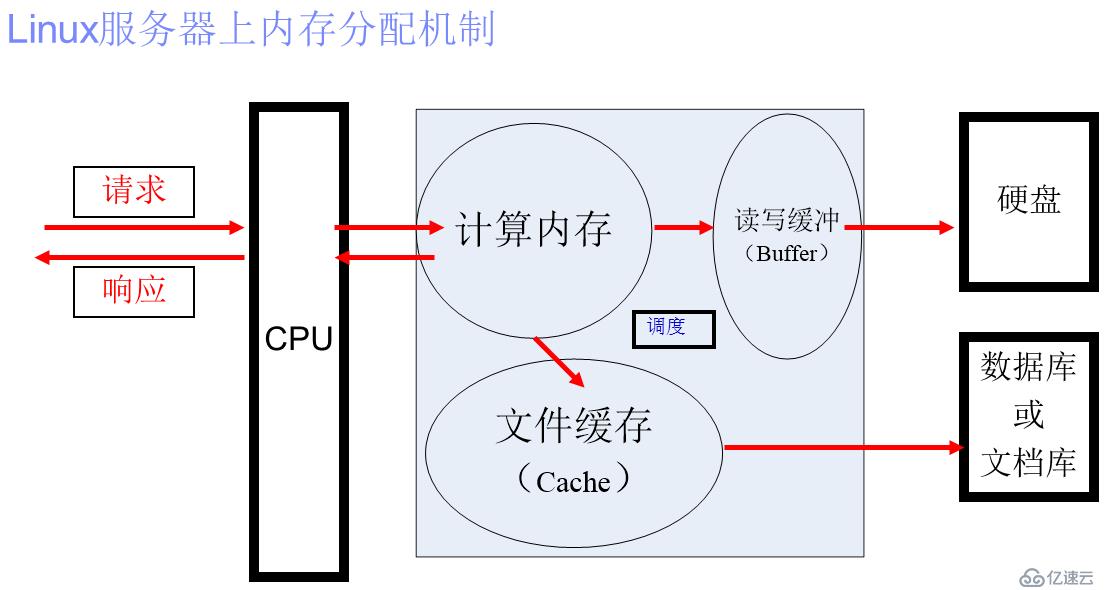
еҪ“е·Із»ҸеҚ з”Ёзҡ„еҶ…еӯҳеӨ§дәҺJVMжң¬иә«й…ҚзҪ®зҡ„еҶ…еӯҳеӨ§е°ҸиҖҢдё”жӯӨж—¶JVMиҝҳжңӘиҝӣиЎҢеһғеңҫеӣһ收时пјҢе°ұдјҡеҮәзҺ°жІЎжңүеӨҡдҪҷзҡ„еҶ…еӯҳз”ЁжқҘеӯҳеӮЁжӣҙеӨҡз”ЁжҲ·ж–°еўһзҡ„еӨ„зҗҶиҜ·жұӮдәҶпјҢиҝҷж—¶еҖҷзҡ„иЎЁзҺ°е°ұжҳҜж–°иҜ·жұӮйңҖиҰҒзӯүеҫ…JVMйҮҠж”ҫеҶ…еӯҳпјҢиҖҢJVMеҰӮжһңдёҚйҮҠж”ҫеҶ…еӯҳпјҢеҲҷз”ЁжҲ·дҪ“йӘҢе°ұжҳҜйЎөйқўдёҖзӣҙз©әзҷҪпјҢзӣҙиҮіи¶…ж—¶еҗҺжҳҫзӨәвҖңйЎөйқўж— жі•е“Қеә”вҖқгҖҒвҖңзҪ‘йЎөж— жі•жҳҫзӨәвҖқзӯүй”ҷиҜҜпјҢз”ҡиҮіHungдҪҸжҲ–иҖ…CrashжҺүпјҢиҝҷе°ұжҳҜе®•жңәгҖӮ
пјҲдәҢпјүдјҳеҢ–зӯ–з•Ҙ
WebSphere PortalжңҚеҠЎиҝҗиЎҢеңЁWebSphere Application Serverе®№еҷЁдёҠзҡ„дёҖдёӘзӢ¬з«ӢжңҚеҠЎеҷЁпјҢйҖҡеёё64дҪҚжңәеҷЁдёҠдјҡжҢҮе®ҡJVMзҡ„жңҖеӨ§е Ҷж ҲеӨ§е°Ҹдёә3.5GпјҢеӣ дёәи¶…иҝҮ3.5GеҗҺеҚ•зәҜдҫқиө–JVMжң¬иә«зҡ„еһғеңҫеӣһ收жңәеҲ¶еңЁиҝҮеӨ§зҡ„JVMе Ҷж ҲйҮҢеӣһ收жү§иЎҢж•ҲзҺҮеҸҚиҖҢдјҡйҷҚдҪҺеҫҲеӨҡпјҢиҝҷйҮҢиҝҳйңҖиҰҒй…ҚзҪ®ж–°з”ҹд»ЈеҶ…еӯҳзҡ„еӨ§е°ҸзӯүгҖӮеҪ“然пјҢеҰӮжһңжҳҜиҖҒејҸзҡ„32дҪҚжңәеҷЁпјҢеҲҷJVMжңҖеӨ§еӨ§е°ҸдёҚеҸҜи¶…иҝҮ1.8GпјҢеӣ дёә32дҪҚжңәеҷЁдёҠжңҖеӨ§еҜ»еқҖиғҪеҠӣе°ұжҳҜ2GиҖҢе·ІгҖӮ
еҗҢж—¶Portalжң¬иә«зҡ„еӨҡзәҝзЁӢжңәеҲ¶еҪ“з”ЁжҲ·и®ҝй—®йҮҸиҫғеӨ§иҖҢеҸҲдёҚиғҪеҸҠж—¶йҮҠж”ҫж—¶д№ҹдјҡеҘҪз”ЁиҫғеӨҡзҡ„WebContainerпјҢйҖҡеёёжҲ‘们дјҡе°ҶзәҝзЁӢжұ дёӘж•°и°ғеӨ§10еҖҚгҖӮеҰӮжһңж—Ҙеҝ—дёӯзҲҶеҮәвҖңsome threads is hung пјҢwaiting forвҖҰвҖқзӯүзұ»дјјзҡ„й”ҷиҜҜж—¶пјҢеҫҲеҸҜиғҪе°ұжҳҜзәҝзЁӢжұ е·Із»ҸдёҚеӨҹз”ЁдәҶгҖӮеҪ“然пјҢиҝҷж—¶еҖҷжҲ‘们йҰ–е…Ҳеҫ—жҺ’йҷӨзЁӢеәҸй”ҷиҜҜеҜјиҮҙзҡ„зәҝзЁӢжұ дёҚйҮҠж”ҫеҜјиҮҙиҖ—е°Ҫзҡ„еҺҹеӣ пјҢеҰӮжһңжҺ’йҷӨжӯӨйЎ№пјҢе…«жҲҗе°ұжҳҜзәҝзЁӢжұ дёӘж•°еӨӘе°‘еҜјиҮҙзҡ„гҖӮиҖҢиҝҷз§Қй”ҷиҜҜйқһеёёдёҘйҮҚпјҢдјҡзӣҙжҺҘеҜјиҮҙйЎөйқўз©әзҷҪгҖҒйЎөйқўж— жі•жҳҫзӨәзӯүз”ЁжҲ·е“Қеә”дёўеӨұзҡ„жғ…еҶөпјҢдёҚд№…е°ұдјҡеҜјиҮҙе®•жңәгҖӮ
дёүгҖҒдё»йўҳдёҺзҡ®иӮӨи°ғдјҳ
дё»йўҳдёҺзҡ®иӮӨдјҳеҢ–жҢҮзҡ„жҳҜе®ўжҲ·дёәдәҶйҖӮеә”е®ҡеҲ¶еҢ–йңҖжұӮпјҢдјҡдёәе®ўжҲ·ејҖеҸ‘дёҖеҘ—жҲ–еӨҡеҘ—й—ЁжҲ·дё»йўҳдёҺзҡ®иӮӨпјҲеҚіпјҡThemes е’Ң SkinsпјүгҖӮ笔иҖ…е·Із»ҸйҒҮеҲ°еӨҡ家客жҲ·з”ұдәҺдё»йўҳзҡ®иӮӨзҡ„й—®йўҳеҜјиҮҙзі»з»ҹжҖ§иғҪдҪҺдёӢжҲ–иҖ…е®•жңәзҡ„жғ…еҶөеҸ‘з”ҹдәҶгҖӮ
пјҲдёҖпјүй—®йўҳеҲҶжһҗ
дё»йўҳзҡ®иӮӨеҜјиҮҙзҡ„жҖ§иғҪдҪҺдёӢжҲ–е®•жңәдё»иҰҒдҪ“зҺ°еңЁдёӨдёӘж–№йқўпјҡ第дёҖпјҢиҝҮеӨҡзҡ„дё»йўҳжҲ–зҡ®иӮӨгҖӮеҫҲеӨҡз”ЁжҲ·дёәдәҶдё°еҜҢй—ЁжҲ·зҡ„и§Ҷи§үж•ҲжһңпјҢдјҡиҰҒжұӮејҖеҸ‘е•ҶејҖеҸ‘еӨҡеҘ—дё»йўҳе’Ңзҡ®иӮӨпјҢеҮ д№ҺжҜҸеј дё»йЎөйқўйғҪиҰҒдҪҝз”ЁеҚ•зӢ¬зҡ„дёҖеҘ—дё»йўҳпјҢжҜҸеҘ—дё»йўҳдёӢжҜҸдёӘPortletйғҪиҰҒдҪҝз”ЁдёҖдёӘеҚ•зӢ¬зҡ„зҡ®иӮӨгҖӮжҲ‘们зҹҘйҒ“пјҢPortalйҮҢжҜҸеҘ—дё»йўҳжҲ–иҖ…жҜҸеҘ—зҡ®иӮӨйғҪеңЁеҚ•зӢ¬зҡ„дёҖдёӘж–Ү件еӨ№йҮҢдёүеҚҒеӨҡдёӘж–Ү件жӢјиЈ…зј–иҜ‘еҮәжқҘзҡ„гҖӮз”ЁжҲ·еңЁдҪҝз”Ёй—ЁжҲ·зі»з»ҹж—¶пјҢеӨҡеҘ—дё»йўҳдёҺзҡ®иӮӨиў«еҠ иҪҪпјҢиҝҷж„Ҹе‘ізқҖжңүж•°зҷҫз”ҡиҮіж•°еҚғдёӘjspжҲ–иҖ…jspf,css,js,jpgзӯүж–Ү件被еҠ иҪҪиҝӣеҶ…еӯҳпјҢеӨӘж¶ҲиҖ—зі»з»ҹиө„жәҗдәҶпјҒиҝҷз§Қжғ…еҶөеӨҡеҸ‘з”ҹеңЁдёҖдәӣеҜ№й—ЁжҲ·и§Ҷи§үж•ҲжһңиҰҒжұӮиҫғй«ҳзҡ„е®ўжҲ·йӮЈйҮҢпјӣ第дәҢгҖҒдё»йўҳжҲ–зҡ®иӮӨж–Ү件дёӯеӯҳеңЁиҙЁйҮҸдёҚй«ҳзҡ„д»Јз ҒпјҢдҫӢеҰӮпјҡжңүдәӣдё»йўҳзҡ®иӮӨйҮҢеӯҳеңЁжӯ»еҫӘзҺҜпјҢжҲ–иҖ…йңҖиҰҒиҜ»еҸ–е…¶д»–зі»з»ҹз”ҡиҮідә’иҒ”зҪ‘дёҠзҡ„дёҖдәӣиө„жәҗпјҢеҪ“еӨ–еӣҙзі»з»ҹжІЎжңүеҸҠж—¶еӨ„зҗҶ并иҝ”еӣһз»“жһңж—¶пјҢдё»йўҳзҡ®иӮӨдёҖзӣҙеңЁзӯүеҫ…иҝҷдёӘиө„жәҗпјҢеҰӮжһңиө„жәҗжІЎжңүиў«иҝ”еӣһпјҢе°ұеҫ—зӯүеҲ°и¶…ж—¶пјҢеҰӮжһңи¶…ж—¶дәҶйғҪеңЁзӯүеҫ…зҡ„иҜқпјҢе°ұеҫҲжҳҺжҳҫең°еҮәзҺ°йЎөйқўз©әзҷҪжҲ–жҳҫзӨәдёҚеҮәжқҘдәҶгҖӮ
пјҲдәҢпјүдјҳеҢ–зӯ–з•Ҙ
笔иҖ…ејәзғҲе»әи®®пјҢиғҪйҖҡиҝҮдёҖдәӣеҸӮж•°еҢ–зҡ„ж–№ејҸи§ЈеҶізҡ„й—®йўҳе°ҪйҮҸйҖҡиҝҮеҸӮж•°еҢ–зҡ„ж–№ејҸпјҢдҫӢеҰӮеӨҡдёӘйғЁй—Ёй—ЁжҲ·зҡ„дё»йўҳзҡ®иӮӨдҪҝз”ЁеҗҢдёҖеҘ—дё»йўҳпјҢйҖҡиҝҮеҸӮж•°еҢ–дё»йўҳдёҠзҡ„LogoеӣҫзүҮпјҢеҸӮж•°еҢ–ж–Үеӯ—зӯүж–№ејҸе®һзҺ°еҗ„дёӘйғЁй—Ёй—ЁжҲ·зҪ‘з«ҷзҡ„жҳҫзӨәж•Ҳжһңе·®ејӮпјӣеҗҢж ·зҡ„пјҢжҜҸеҘ—дё»йўҳе°ҪйҮҸдёҚиҰҒи¶…иҝҮ5еҘ—зҡ®иӮӨпјҢиҝҳжҳҜйҖҡиҝҮеҸӮж•°еҢ–зҡ„ж–№ејҸжқҘиҝӣиЎҢPortletдёҚеҗҢйЈҺж јзҡ„е‘ҲзҺ°гҖӮ
иҮідәҺдё»йўҳзҡ®иӮӨд»Јз ҒеұӮйқўпјҢе»әи®®йЎ№зӣ®з»„иҠұеӨ§еҠӣж°”дёҘж јжЈҖжҹҘжңүжІЎжңүеӯҳеңЁжӯ»еҫӘзҺҜгҖҒиҜ»еҸ–еӨ§ж•°жҚ®йҮҸгҖҒдёҚеҸҠж—¶йҮҠж”ҫеҶ…еӯҳзӯүдҪҺиҙЁйҮҸд»Јз ҒгҖҒзӯүеҫ…дҫқиө–зі»з»ҹе“Қеә”зӯүдҪҺиҙЁйҮҸйҖ»иҫ‘гҖӮеҜ№дёҚжҮӮд»Јз Ғзҡ„е®ўжҲ·жқҘиҜҙеҰӮжһңиҰҒйҮҮз”ЁйҖҶжҺЁзҡ„ж–№ејҸеҲӨж–ӯжҳҜеҗҰеӯҳеңЁд»Јз ҒиҙЁйҮҸзҡ„жғ…еҶөпјҢеҲҷеҸҜд»ҘдҪҝз”ЁLoadRunnerеҜ№зі»з»ҹиҝӣиЎҢжҠ—з–ІеҠіжөӢиҜ•пјҢйҖҡиҝҮиҖҗеҺӢжөӢиҜ•пјҢи®©зі»з»ҹдҪҺиҙЁйҮҸд»Јз ҒеҜ№еҶ…еӯҳгҖҒCPUзӯүзҡ„ж¶ҲиҖ—е’ҢдҫөеҚ е°ҪйҮҸиЎЁзҺ°еҮәжқҘгҖӮйјҺдәҡ科жҠҖеҸҜд»Ҙдёәе…ЁеӣҪзҡ„з”ЁжҲ·Г—Г—Г—иғҪи°ғдјҳж–№йқўзҡ„е…Қиҙ№еҹ№и®ӯе’ҢеҺӢеҠӣжөӢиҜ•ж–№йқўзҡ„жҢҮеҜјгҖҒеҹ№и®ӯгҖӮ
еӣӣгҖҒSQLжү§иЎҢж•ҲзҺҮдјҳеҢ–
й—ЁжҲ·жҖ§иғҪдҪҺжҲ–иҖ…е®•жңәй—®йўҳдёҚд»…д»…жҳҜз”ұдәҺеҶ…еӯҳиҖ—е°ҪеҜјиҮҙзҡ„пјҢиҝҳжңүCPUе’ҢзЎ¬зӣҳгҖӮSQLжү§иЎҢж•ҲзҺҮжҳҜеҗҢж—¶еҸҜиғҪеҜ№иҝҷдёүж–№йқўйҖ жҲҗжҚҹиҖ—зҡ„йҮҚиҰҒеӣ зҙ д№ӢдёҖгҖӮ
пјҲдёҖпјүй—®йўҳеҲҶжһҗ
SQLжү§иЎҢж•ҲзҺҮзҡ„жҚҹе®ійҖҡеёёдҪ“зҺ°еңЁеҰӮдёӢдёӨдёӘж–№йқўпјҡпјҲ1пјүSQLж…ўжҹҘиҜўжҲ–иҖ…иҜӯеҸҘжү§иЎҢеӨ§ж•°жҚ®йҮҸзҡ„жҹҘиҜўе№¶иҝ”еӣһдәҶеӨ§ж•°жҚ®йҮҸзҡ„жҹҘиҜўз»“жһңпјҢдҫӢеҰӮжҹҗе®ўжҲ·дёҖдёӢеӯҗжҹҘиҜўеҮә4000дёҮжқЎз”ЁжҲ·зҷ»еҪ•и®°еҪ•е№¶жү“еҚ°еңЁдәҶдё»йўҳж–Ү件йҮҢпјҢиҝҷдәӣеӨ§ж•°жҚ®йҮҸж—ўдјҡеҚ з”ЁеҶ…еӯҳпјҢеҸҲдјҡж¶ҲиҖ—CPUпјҢз”ҡиҮіеҶҷе…ҘдёҖдәӣзЎ¬зӣҳж–Ү件пјҢеӨ©й•ҝж—Ҙд№…еҜјиҮҙзЎ¬зӣҳиў«еҚ ж»ЎиҖҢе®•жңәгҖӮSQLж…ўжҹҘиҜўеҲҷдјҡеёҰжқҘеӨ§йҮҸзҡ„з”ЁжҲ·зӯүеҫ…ж—¶й—ҙгҖӮпјҲ2пјүSQLиҜӯеҸҘжү§иЎҢж¬Ўж•°иҝҮеӨҡжҲ–жӯ»еҫӘзҺҜгҖӮзі»з»ҹиҰҒжҹҘиҜўдёҖз»„ж•°жҚ®ж—¶пјҢйңҖиҰҒеҲ°еӨҡеј иЎЁйҮҢжү§иЎҢеӨҡз»„жҹҘиҜўе№¶жӢјиЈ…еӨ„зҗҶиҝ”еӣһзҡ„з»“жһңпјҢжҲ–иҖ…жҹҗдәӣжһҒз«ҜжқЎд»¶еҮәеҸ‘SQLжү§иЎҢжӯ»еҫӘзҺҜпјҢж—ўж¶ҲиҖ—еӨ§йҮҸзҡ„CPUиө„жәҗеҸҲдёҚиҝ”еӣһз»“жһңпјҢе®•жңәд№ҹе°ұжҳҜдёҚеҸҜйҒҝе…Қзҡ„дәҶгҖӮ
пјҲдәҢпјүдјҳеҢ–зӯ–з•Ҙ
еҠЎеҝ…йҖҡиҝҮејәеЈ®зҡ„д»Јз Ғе®ЎжҹҘпјҲCode ReviewпјүиҜҶеҲ«еҮәSQLж…ўжҹҘиҜўгҖҒеӨ§ж•°жҚ®йҮҸжҹҘиҜўгҖҒжӯ»еҫӘзҺҜзӯүй—®йўҳпјҢ并еҗҲзҗҶи®ҫи®ЎиЎЁз»“жһ„пјҢеҗҲзҗҶи®ҫи®ЎSQLиҜӯеҸҘгҖӮдёҺдёҠдёҖиҠӮзӣёеҗҢпјҢеҜ№дёҚжҮӮд»Јз Ғзҡ„е®ўжҲ·жқҘиҜҙеҰӮжһңиҰҒйҮҮз”ЁйҖҶжҺЁзҡ„ж–№ејҸеҲӨж–ӯжҳҜеҗҰеӯҳеңЁд»Јз ҒиҙЁйҮҸзҡ„жғ…еҶөпјҢеҲҷеҸҜд»ҘдҪҝз”ЁLoadRunnerеҜ№зі»з»ҹиҝӣиЎҢжҠ—з–ІеҠіжөӢиҜ•пјҢйҖҡиҝҮиҖҗеҺӢжөӢиҜ•пјҢи®©зі»з»ҹдҪҺиҙЁйҮҸд»Јз ҒеҜ№еҶ…еӯҳгҖҒCPUзӯүзҡ„ж¶ҲиҖ—е’ҢдҫөеҚ е°ҪйҮҸиЎЁзҺ°еҮәжқҘгҖӮйјҺдәҡ科жҠҖеҸҜд»Ҙдёәе…ЁеӣҪзҡ„з”ЁжҲ·Г—Г—Г—иғҪи°ғдјҳж–№йқўзҡ„е…Қиҙ№еҹ№и®ӯе’ҢеҺӢеҠӣжөӢиҜ•ж–№йқўзҡ„жҢҮеҜјгҖҒеҹ№и®ӯгҖӮжүҖи°“зҡ„жҠ—з–ІеҠіжөӢиҜ•жҢҮзҡ„жҳҜпјҢеҪ•еҲ¶е°ҪеҸҜиғҪиҰҶзӣ–жүҖжңүйЎөйқўгҖҒжүҖжңүйҖ»иҫ‘зҡ„еҠҹиғҪзӮ№пјҢ并и®ҫзҪ®LoadRunnerеңЁжІЎжңүжҖқиҖғж—¶й—ҙзҡ„еүҚжҸҗдёӢпјҢиҝӣиЎҢй•ҝиҫҫ72е°Ҹж—¶зҡ„иҖҗд№…жҖ§жөӢиҜ•пјҢжүҖи°“вҖңж—Ҙд№…и§ҒдәәеҝғвҖқпјҢе“ӘжҖ•SQLжү§иЎҢж•ҲзҺҮзЁҚеҫ®жңүдёҖзӮ№зӮ№дҪҺдёӢпјҢиө„жәҗжңүдёҖзӮ№зӮ№жІЎжңүеҸҠж—¶йҮҠж”ҫзҡ„пјҢйҖҡиҝҮй«ҳејәеәҰзҡ„иҖҗеҺӢжөӢиҜ•пјҢд№ҹдјҡи®©й—®йўҳж— йҷҗж”ҫеӨ§пјҢжңҖз»ҲжҡҙйңІеҮәжқҘгҖӮ
дә”гҖҒж•°жҚ®еә“жҖ§иғҪдјҳеҢ–
ж•°жҚ®еә“жҖ§иғҪдјҳеҢ–жҢҮзҡ„жҳҜж•°жҚ®еә“жң¬иә«зҡ„еҸӮж•°дјҳеҢ–пјҢд»ҘеҸҠWebSphereдҪҝз”Ёж•°жҚ®жәҗиҝһжҺҘжұ зҡ„еҸӮж•°дјҳеҢ–гҖӮ
пјҲдёҖпјүй—®йўҳеҲҶжһҗ
IBM WebSphere PortalдҪҝз”Ёж•°жҚ®жәҗиҝһжҺҘжұ еҚій•ҝиҝһжҺҘзҡ„ж–№ејҸжҸҗдҫӣж•°жҚ®еә“жңҚеҠЎпјҢжүҖд»ҘдёҚеҗҲзҗҶзҡ„ж•°жҚ®жәҗиҝһжҺҘжұ й…ҚзҪ®дјҡеҜјиҮҙж•°жҚ®еә“еӨ„зҗҶйҖ»иҫ‘зӯүеҫ…ж—¶й—ҙиҝҮй•ҝжҲ–иҖ…е®•жңәгҖӮдҫӢеҰӮпјҡеҰӮжһңжҹҗдәӣPortletеә”з”Ёйў‘з№ҒиҜ»еҸ–ж•°жҚ®еә“пјҢиҖҢиҝһжҺҘжұ зҡ„дёӘж•°иҝҮдҪҺпјҢе°ұдјҡжңүеӨ§йҮҸзҡ„ж•°жҚ®еә“иҜ»еҶҷйҖ»иҫ‘еңЁжҺ’йҳҹзӯүеҫ…ж•°жҚ®еә“иҝһжҺҘпјҢз”ҡиҮіи¶…ж—¶еҗҺеҜјиҮҙе®•жңәпјҢжңҖзӣҙжҺҘзҡ„еҗҺжһңе°ұжҳҜз”ЁжҲ·зҡ„еҫҲеӨҡPortletеә”з”ЁдёҖзӣҙеҲқе§ӢеҢ–дёҚеҮәжқҘпјҢеҺҹеӣ жҳҜеңЁзӯүеҫ…е…¶д»–йҖ»иҫ‘йҮҠж”ҫж•°жҚ®жәҗиҝһжҺҘжұ еҗҺиҝӣиЎҢж•°жҚ®еә“иҜ»еҶҷж“ҚдҪңгҖӮ
пјҲдәҢпјүдјҳеҢ–зӯ–з•Ҙ
йҖҡеёёжҲ‘们дјҡеңЁWASжҺ§еҲ¶еҸ°дёҠй…ҚзҪ®ж•°жҚ®жәҗиҝһжҺҘжұ зҡ„дёӘж•°дёәзі»з»ҹй»ҳи®Өзҡ„3-6еҖҚпјҢе…·дҪ“и§Ҷеҗ„家客жҲ·зҡ„й—ЁжҲ·еҶ…е®№дҪҝз”Ёж•°жҚ®еә“зҡ„йў‘зҺҮй«ҳдҪҺиҖҢе®ҡгҖӮж•°жҚ®жәҗиҝһжҺҘжұ дёӘж•°иҝҮдҪҺпјҢдјҡйҖ жҲҗPortletйҖ»иҫ‘жҺ’йҳҹзӯүеҫ…жӢүй•ҝе“Қеә”ж—¶й—ҙпјӣдёӘж•°иҝҮй«ҳеҲҷдјҡеҜјиҮҙзі»з»ҹеҸҜз”ЁеҶ…еӯҳйҷҚдҪҺпјҢеӣ дёәжҜҸдёӘж•°жҚ®жәҗиҝһжҺҘжұ дјҡеҚ з”ЁеӨ§зәҰ3Mе·ҰеҸізҡ„еҶ…еӯҳпјҢеҰӮжһңй…ҚзҪ®еҮ зҷҫдёӘж•°жҚ®жәҗиҝһжҺҘжұ пјҢеҲҷд»…д»…ж•°з”ЁдәҺж•°жҚ®еә“иҝһжҺҘзҡ„еҶ…еӯҳе°ұдјҡеҚ з”Ё1дёӘеӨҡGпјҢи®Ўз®—жҲ‘们й…ҚзҪ®дәҶ3.5Gзҡ„JVMпјҢд№ҹжІЎеү©еӨҡе°‘и®Ўз®—еҶ…еӯҳз”ЁдәҺй—ЁжҲ·зҡ„йҖ»иҫ‘еӨ„зҗҶпјҢеҗҢж ·д№ҹдјҡеҜјиҮҙзі»з»ҹзҡ„жҖ§иғҪйҷҚдҪҺжҲ–е®•жңәгҖӮиҝҷйҮҢиҝҳиҰҒејәи°ғж•°жҚ®жәҗиҝһжҺҘжұ зҡ„иҝҮжңҹж—¶й—ҙпјҢдёҚжҒ°еҪ“зҡ„TimeOutд№ҹдјҡеёҰжқҘзӯүеҫ…е“Қеә”жҲ–зі»з»ҹж— жі•еӨ„зҗҶз”ЁжҲ·зҡ„жӯЈеёёиҜ·жұӮгҖӮжңҖеҮҶзЎ®зҡ„дёӘж•°й…ҚзҪ®жқҘжәҗдәҺжңҖдҪіе®һи·өгҖӮзӣҙзҷҪзҡ„иҜҙпјҢе°ұжҳҜйҖҡиҝҮи®ҫзҪ®дёҚеҗҢзҡ„еҸӮж•°еҗҺиҝӣиЎҢеҗҲзҗҶй…ҚзҪ®зҡ„LoadRunnerеҺӢеҠӣжөӢиҜ•пјҢеҺӢеҠӣжөӢиҜ•еңәжҷҜзҡ„и®ҫи®Ўе°ҪйҮҸиҙҙиҝ‘з”ЁжҲ·дҪҝз”Ёзҡ„зңҹе®һеңәжҷҜпјҢжқҘжЁЎжӢҹз”ҹдә§зҺҜеўғзҡ„зңҹе®һзҠ¶еҶөпјҢ然еҗҺйҖҡиҝҮеҜ№жҜ”LoadRunnerеҺӢеҠӣжөӢиҜ•иЎЁзҺ°жңҖеҘҪзҡ„йӮЈз»„пјҢзЎ®е®ҡж•°жҚ®жәҗиҝһжҺҘжұ зҡ„жңҖдҪій…ҚзҪ®гҖӮ
йўқеӨ–зҡ„пјҢйҖҡеёёж•°жҚ®еә“жңҚеҠЎеҷЁе’Ңй—ЁжҲ·жңҚеҠЎеҷЁжҳҜдёҚеҗҢзҡ„жңҚеҠЎеҷЁпјҢдёӯй—ҙжһ¶и®ҫйҳІзҒ«еўҷзҡ„е®ўжҲ·жҜ”дҫӢйқһеёёй«ҳпјҢиҝҷйҮҢжҲ‘们иҰҒејәи°ғдёҖдёӢдёҖе®ҡеҚҸеҠ©е®ўжҲ·еҗҲзҗҶй…ҚзҪ®йҳІзҒ«еўҷзӯ–з•ҘпјҢеӣ дёәйҳІзҒ«еўҷеҲҮж–ӯй—ЁжҲ·дёҺж•°жҚ®еә“д№Ӣй—ҙзҡ„й•ҝиҝһжҺҘиҖҢеҜјиҮҙзҡ„й—ЁжҲ·е®•жңәжЎҲдҫӢйқһеёёд№Ӣй«ҳгҖӮ
е…ӯгҖҒж•°жҚ®/ж•°жҚ®йӣҶдјҳеҢ–
ж•°жҚ®дёҺж•°жҚ®йӣҶдјҳеҢ–жҢҮзҡ„жҳҜж— и®әPortalе®№еҷЁиҝҳжҳҜPortletе®№еҷЁиҜ»еҶҷзҡ„ж•°жҚ®йҮҸеӨ§е°Ҹй—®йўҳпјҢж•°жҚ®йҮҸиҝҮеӨ§дјҡж¶ҲиҖ—еӨ§йҮҸж—¶й—ҙе’Ңз©әй—ҙиө„жәҗпјҢдјҡеҜјиҮҙзі»з»ҹжҖ§иғҪдҪҺдёӢжҲ–е®•жңәгҖӮ
пјҲдёҖпјүй—®йўҳеҲҶжһҗ
Portalдё»йўҳзҡ®иӮӨйҮҢзҡ„д»Јз Ғе’ҢпјҲжҲ–пјүPortletеә”з”ЁйҖ»иҫ‘д»Јз ҒеңЁжү§иЎҢеӨ§ж•°жҚ®йҮҸж“ҚдҪңж—¶пјҢдјҡж¶ҲиҖ—еӨ§йҮҸзҡ„ж—¶й—ҙиө„жәҗгҖҒз©әй—ҙиө„жәҗпјӣж—¶й—ҙиө„жәҗдҪ“зҺ°еңЁCPUеӨ„зҗҶдёҠпјҢз©әй—ҙиө„жәҗдҪ“зҺ°еңЁеҶ…еӯҳеҚ з”ЁдёҠгҖӮж— и®әжҳҜCPUиҝҮдәҺз№ҒеҝҷиҝҳжҳҜеҶ…еӯҳж¶ҲиҖ—иҝҮеӨ§йғҪжҳҜдёҖз§ҚеҚұйҷ©зҡ„дәӢпјҢжңҖеёёз”Ёзҡ„е°ұжҳҜеҲҶж®өиҜ»еҶҷгҖҒеҲҶйЎөжҳҫзӨәгҖҒеӨ§ж•°жҚ®иҪ¬з§»зӯүй—®йўҳгҖӮ
пјҲ1пјүеӨ§ж•°жҚ®йҮҸиҜ»еҶҷгҖӮж•°жҚ®еә“жү§иЎҢеӨ§ж•°жҚ®йҮҸиҜ»еҶҷж—¶пјҢдјҡж¶ҲиҖ—еӨ§йҮҸзҡ„CPUж—¶й—ҙе’ҢеҶ…еӯҳеҚ з”ЁпјҢз”ЁжҲ·е№¶еҸ‘йҮҸдёҖдёҠеҚҮпјҢе°ұеҫҲе®№жҳ“еҜјиҮҙжҖ§иғҪй—®йўҳгҖӮ
пјҲ2пјүеҲҶйЎөжҳҫзӨәгҖӮиҝҷдёӘж— йңҖеӨҡиҜҙпјҢз”ЁжҲ·йҖҡеёёзңӢзҡ„жҳҜеүҚ3йЎөпјҢеҰӮжһңдёҖдёӢеӯҗжҠҠеҮ зҷҫйЎөиҜ»еҸ–иҝҮжқҘпјҢеҶ…еӯҳз©әй—ҙзҡ„еҚ з”ЁжҳҜе·ЁеӨ§зҡ„гҖӮ
пјҲ3пјүеӨ§ж•°жҚ®иҪ¬з§»пјҢжҢҮзҡ„жҳҜжҹҗдәӣиЎЁйҮҢеҸҜиғҪеӯҳеӮЁйқһеёёеӨ§йҮҸзҡ„ж•°жҚ®пјҢдҫӢеҰӮз”ЁжҲ·зҷ»йҷҶж—Ҙеҝ—пјҢж•°жҚ®з§ҜзҙҜи¶ҠжқҘи¶ҠеӨҡпјҢиҜ»еҶҷйҖҹеәҰе°ұдјҡи¶ҠжқҘи¶Ҡж…ўпјҢзі»з»ҹиө„жәҗж¶ҲиҖ—е°ұдјҡи¶ҠжқҘи¶ҠеӨ§пјҢжҖ§иғҪд№ҹе°ұи¶ҠжқҘи¶ҠдҪҺдәҶгҖӮ
пјҲдәҢпјүдјҳеҢ–зӯ–з•Ҙ
й’ҲеҜ№дәҺеёёи§Ғзҡ„иҝҷдәӣй—®йўҳпјҢеҲҶеҲ«д»Ӣз»Қи°ғж•ҙзӯ–з•ҘгҖӮиҝҷйғЁеҲҶе…¶е®һжңҖеӨҡзҡ„д№ҹжҳҜдёҺ常规JavaејҖеҸ‘зӣёеҗҢпјҢиҜ·иҮӘиЎҢеҸӮиҖғгҖӮ
пјҲ1пјүеҲҶж®өиҜ»еҶҷжҢҮзҡ„жҳҜпјҢйҖ»иҫ‘д»Јз ҒеңЁиҜ»еҶҷж•°жҚ®ж—¶пјҢе°ҪйҮҸдёҚиҰҒеӨ§ж•°жҚ®йҮҸиҜ»еҶҷпјҢдҫӢеҰӮеҗ‘ж•°жҚ®еә“жҲ–ж–Ү件系з»ҹдёӯдёҖж¬ЎеҶҷе…Ҙи¶…иҝҮ10дёҮжқЎж•°жҚ®пјҢжҲ–иҖ…иҜ»е…ҘдёҠзҷҫдёҮжқЎж•°жҚ®пјҢиҝҷз§Қж•ҲзҺҮиӮҜе®ҡжһҒдҪҺпјҢе°қиҜ•дҝ®ж”№и®ҫи®ЎпјҢдјҳеҢ–иҜ»еҸ–йҖ»иҫ‘гҖӮ
пјҲ2пјүеҲҶйЎөжҳҫзӨәгҖӮиҝҷдёӘж— йңҖеӨҡиҜҙпјҢжҜҸж¬ЎиҜ»еҶҷжңҖеӨҡ3йЎөпјҢзӯүз”ЁжҲ·зӮ№еҮ»зҝ»йЎөж—¶еҶҚиҜ»еҸ–жӣҙеӨҡзҡ„ж•°жҚ®гҖӮ
пјҲ3пјүеӨ§ж•°жҚ®иҪ¬з§»гҖӮйҖӮз”ЁдәҺжҹҗдәӣиЎЁйҮҢиҰҒеӯҳеӮЁеӨ§ж•°жҚ®йҮҸж—¶пјҢжңҖеҘҪдёҚиҰҒи¶…иҝҮеҚғдёҮжқЎи®°еҪ•зҡ„зә§еҲ«пјҢйҖҡеёёз”ЁеңЁз”ЁжҲ·зҷ»еҪ•ж—Ҙеҝ—зӯүпјҢйҡҸзқҖдҪҝз”Ёж—¶й—ҙзҡ„жҺЁз§»пјҢиЎЁдёӯзҡ„и®°еҪ•жқЎж•°и¶ҠжқҘи¶ҠеӨҡпјҢиҜ»еҸ–зҡ„ж—¶еҖҷд№ҹеҫҲе®№жҳ“ж¶ҲиҖ—иө„жәҗгҖӮ
дёғгҖҒPortletд»Јз ҒдёҺйҖ»иҫ‘дјҳеҢ–
PortletејҖеҸ‘е®һйҷ…дёҠдёҺдј з»ҹзҡ„JavaејҖеҸ‘е№¶ж— дәҢиҮҙпјҢPortletзӯүеҫ…ж•°жҚ®еә“иҝһжҺҘгҖҒжӯ»еҫӘзҺҜзӯүеёҰжқҘзҡ„зі»з»ҹжҖ§иғҪдҪҺдёӢпјҢжҲҗдёәPortletеұӮйқўдјҳеҢ–зҡ„й—®йўҳжң¬иҙЁгҖӮ
пјҲдёҖпјүй—®йўҳеҲҶжһҗ
Portletд»Јз ҒеҜјиҮҙжҖ§иғҪдҪҺдёӢзҡ„жғ…еҶөйҖҡеёёжңүпјҡпјҲ1пјүжү§иЎҢйҖ»иҫ‘ж•ҲзҺҮдҪҺжҲ–жӯ»еҫӘзҺҜеҜјиҮҙPortletе“Қеә”ејӮеёёең°ж…ўпјҢдҫӢеҰӮиҰҒеҲ°еҚҒеҮ еҘ—зі»з»ҹйҮҢиҜ»еҸ–еҗ„дёӘзі»з»ҹзҡ„еҫ…еҠһдҝЎжҒҜзӯүпјӣпјҲ2пјүPortletзӯүеҫ…жҹҗдәӣиө„жәҗиҖҢиҝҷдәӣиө„жәҗжІЎжңүеҸҠж—¶еҠ иҪҪжҲ–иҖ…еҺӢж №е°ұеҠ иҪҪдёҚеҮәжқҘпјҢиҖҢPortletз«ҜжңүжІЎжңүеӨ„зҗҶиҜ»еҸ–дёҚеҮәжқҘж—¶еҖҷзҡ„еҮәй”ҷеӨ„зҗҶпјҢеҜјиҮҙPortletдёҖзӣҙеңЁзӯүеҫ…иө„жәҗпјҢзі»з»ҹзәҝзЁӢHungдҪҸд№ҹе°ұеҫҲжӯЈеёёдәҶгҖӮ
пјҲдәҢпјүдјҳеҢ–зӯ–з•Ҙ
иҝҷйңҖиҰҒеҗҲзҗҶи®ҫи®ЎPortletе®һзҺ°йҖ»иҫ‘гҖӮдҫӢеҰӮпјҡз»ҹдёҖеҫ…еҠһPortletпјҢжҲ‘们еҸҜд»ҘйҮҮз”ЁйҖҶеҗ‘жҺЁйҖҒзҡ„ж–№ејҸпјҢеҪ“еҗ„дёӘдёҡеҠЎзі»з»ҹдә§з”ҹж–°зҡ„еҫ…еҠһдәӢйЎ№ж—¶пјҢдё»еҠЁжҺЁйҖҒеҲ°й—ЁжҲ·зј“еҶІж•°жҚ®еә“пјҲеҸҜд»Ҙи®ӨдёәжҳҜBrokerеұӮпјүпјҢ然еҗҺPortletзӣҙжҺҘеҲ°зј“еҶІж•°жҚ®еә“дёҖдёӘиЎЁйҮҢиҜ»еҸ–еҫ…еҠһжқЎзӣ®пјҢиҝҷж ·еҸҜд»ҘжҸҗй«ҳPortletжҖ§иғҪиҫҫж•°еҚҒеҖҚгҖӮ
第дәҢпјҢйҖҡиҝҮдёҘж јзҡ„д»Јз ҒжЈҖжҹҘж¶ҲйҷӨPortletдёӯиө„жәҗзӯүеҫ…гҖҒжӯ»еҫӘзҺҜзӯүй—®йўҳгҖӮиҝҷдёӘй—®йўҳзҡ„жЈҖжҹҘдёҺжҷ®йҖҡзҡ„JavaејҖеҸ‘е№¶ж— дәҢиҮҙпјҢжң¬ж–ҮдёҚеҶҚиөҳиҝ°гҖӮ
е…«гҖҒзҪ‘з»ңдј иҫ“пјҲеҢ…еӨ§е°ҸпјүдјҳеҢ–
жҳҫзӨәйҖ»иҫ‘е’Ңжү“еҢ…йҖ»иҫ‘дјҳеҢ–еӨҡеҸ‘з”ҹеңЁзҪ‘з»ңйҖҹеәҰдёҚеӨӘй«ҳзҡ„е®ўжҲ·еңәжҷҜдёӯпјҢе°Өе…¶жҳҜйғЁзҪІеңЁдә‘з«ҜжҲ–иҖ…дә’иҒ”зҪ‘дёҠзҡ„е®ўжҲ·пјҢжҢҮзҡ„жҳҜиҝҮеӨ§зҡ„ж•°жҚ®йҮҸдј иҫ“еҜјиҮҙдәҶз”ЁжҲ·е“Қеә”ж—¶й—ҙеӨӘж…ўпјҢж…ўеҲ°з”ЁжҲ·д»Ҙдёәзі»з»ҹе®•жңәдәҶгҖӮеӨҮжіЁпјҡеҰӮжһңдј иҫ“ж—¶й—ҙи¶…ж—¶пјҢйӮЈе°ұзңҹе®•жңәдәҶгҖӮ
пјҲдёҖпјүй—®йўҳеҲҶжһҗ
жҲ‘们зҹҘйҒ“пјҢжүҖжңүз”ЁжҲ·зҡ„иҜ·жұӮйғҪжҳҜйҖҡиҝҮжңҚеҠЎеҷЁз«Ҝе”ҜдёҖзҡ„зҪ‘зәҝеҮәеҸЈдёҺз”ЁжҲ·зҡ„е®ўжҲ·з«Ҝз”өи„‘пјҲжҲ–жүӢжңәпјүе»әз«ӢжҜ”зү№жөҒдј иҫ“зҡ„гҖӮе»әи®ҫжҜҸдёӘз”ЁжҲ·и®ҝй—®й—ЁжҲ·йңҖиҰҒдј иҫ“3Mзҡ„ж•°жҚ®жөҒйҮҸпјҢиҝҷ3MеҢ…еҗ«дәҶйҖ»иҫ‘еӨ„зҗҶе®ҢжҲҗд№ӢеҗҺзј–иҜ‘еҮәжқҘзҡ„cssж–Ү件пјҢjssж–Ү件пјҢhtmlж–Ү件пјҢjpg/pngзӯүеӣҫзүҮж–Ү件пјҢеҒҮи®ҫжңү300дёӘз”ЁжҲ·еңЁе№¶еҸ‘и®ҝй—®пјҢеҲҷиҝҷ300дёӘз”ЁжҲ·дёҖе…ұйңҖиҰҒдј иҫ“3Mx300=900Mж•°жҚ®жөҒйҮҸгҖӮеҰӮжһңжҲ‘们жңҚеҠЎеҷЁз”іиҜ·зҡ„еёҰе®ҪжҳҜзҷҫе…ҶпјҢд№ҹе°ұжҳҜжҜҸз§’й’ҹиғҪдј иҫ“12.5Mж•°жҚ®пјҢеҲҷеҚідҪҝеҮәеҺ»йҖ»иҫ‘еӨ„зҗҶзҡ„ж—¶й—ҙпјҢиҝӣзҪ‘и·Ҝдј иҫ“зҡ„ж¶ҲиҖ—пјҢе°ұйңҖиҰҒ900MйҷӨд»Ҙ12.5M/SзӯүдәҺ72з§’пјҢиҝҷжҳҜдёҖдёӘеӨҡд№ҲеәһеӨ§зҡ„ж•°жҚ®пјҢжҜҸдёӘз”ЁжҲ·е…үзӯүеҫ…дј иҫ“е°ұиҰҒзӯүеҫ…72з§’
пјҲдәҢпјүдјҳеҢ–зӯ–з•Ҙ
еңЁдёҚеҪұе“ҚеӣҫзүҮи§ӮзңӢж•Ҳжһңзҡ„жғ…еҶөдёӢпјҢжҲ‘们е»әи®®з”ЁжҲ·е°ҪйҮҸйҷҚдҪҺеӣҫзүҮзҡ„еӨ§е°ҸпјҢеҜ№зЁӢеәҸејҖеҸ‘иҖ…жқҘиҜҙпјҢеңЁдёҚеҪұе“ҚеҠҹиғҪзҡ„еүҚжҸҗдёӢпјҢе°ҪйҮҸдёәjsж–Ү件гҖҒcssж–Ү件зӯүеҮҸиӮҘпјҢе°Ҷе…¶дҪ“з§ҜйҷҚеҲ°жңҖдҪҺпјҢе°ҪйҮҸйҷҚдҪҺзҪ‘и·Ҝдј иҫ“еёҰжқҘзҡ„з”ЁжҲ·дҪ“йӘҢж¶ҲиҖ—гҖӮдҪңдёәзі»з»ҹжһ¶жһ„еёҲжҲ–йЎ№зӣ®з»ҸзҗҶпјҢиҰҒе……еҲҶи°ғз ”пјҢе……еҲҶиҖғиҷ‘еҲ°зңҹе®һзҡ„з”ЁжҲ·е№¶еҸ‘жғ…еҶөпјҢ并еҚҸеҠ©з”ЁжҲ·иҙӯд№°жҲ–еҲҶй…ҚеҗҲзҗҶзҡ„зҪ‘з»ңеёҰе®ҪгҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ