您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
URL,全称是UniformResourceLocator, 中文叫统一资源定位符,是互联网上用来标识某一处资源的地址。以下面这个URL为例,介绍下普通URL的各部分组成:
http://www.example.com:8080/hello/world?boardID=5&ID=24618&page=1#name
一个完整的URL包括以下几部分:
1.协议部分:该URL的协议部分为“http:”,这代表网页使用的是HTTP协议。在Internet中可以使用多种协议,如HTTP,FTP等等本例中使用的是HTTP协议。在"HTTP"后面的“//”为分隔符
2.域名部分:该URL的域名部分为“www.example.com”。一个URL中,也可以使用IP地址作为域名使用
3.端口部分:跟在域名后面的是端口,域名和端口之间使用“:”作为分隔符。端口不是一个URL必须的部分,如果省略端口部分,将采用默认端口,http默认80, https默认443
4.虚拟目录部分:从域名后的第一个“/”开始到最后一个“/”为止,是虚拟目录部分。虚拟目录也不是一个URL必须的部分。本例中的虚拟目录是“/hello/”
5.文件名部分:从域名后的最后一个“/”开始到“?”为止,是文件名部分,如果没有“?”,则是从域名后的最后一个“/”开始到“#”为止,是文件部分,如果没有“?”和“#”,那么从域名后的最后一个“/”开始到结束,都是文件名部分。本例中的文件名是“world"。文件名部分也不是一个URL必须的部分,如果省略该部分,则使用默认的文件名
6.锚部分:从“#”开始到最后,都是锚部分。本例中的锚部分是“name”。锚部分也不是一个URL必须的部分
7.参数部分:从“?”开始到“#”为止之间的部分为参数部分,又称搜索部分、查询部分。本例中的参数部分为“boardID=5&ID=24618&page=1”。参数可以允许有多个参数,参数与参数之间用“&”作为分隔符。客户端发送一个HTTP请求到服务器的请求消息包括以下格式:
请求行(request line)、请求头部(header)、空行和请求数据四个部分组成。
下图给出了请求报文的一般格式。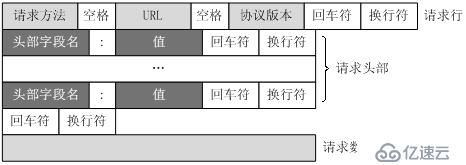
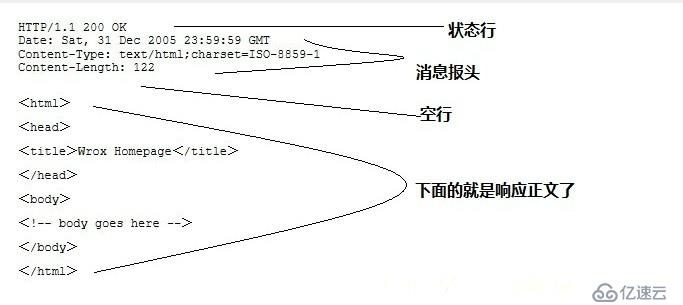
实例-----使用GET来传递数据
客户端请求:
GET /hello.txt HTTP/1.1
User-Agent: curl/7.16.3 libcurl/7.16.3 OpenSSL/0.9.7l zlib/1.2.3
Host: www.example.com
Accept-Language: en, mi
服务端响应:
HTTP/1.1 200 OK
Date: Mon, 27 Jul 2009 12:28:53 GMT
Server: Apache
Last-Modified: Wed, 22 Jul 2009 19:15:56 GMT
ETag: "34aa387-d-1568eb00"
Accept-Ranges: bytes
Content-Length: 51
Vary: Accept-Encoding
Content-Type: text/plain
输出结果:
Hello World! My payload includes a trailing CRLF.
HTTP请求方法
GET 请求指定的页面信息,并返回实体主体。
HEAD 类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头
POST 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。
PUT 从客户端向服务器传送的数据取代指定的文档的内容。
DELETE 请求服务器删除指定的页面。
CONNECT HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。
OPTIONS 允许客户端查看服务器的性能。
TRACE 回显服务器收到的请求,主要用于测试或诊断。
HTTP 响应头信息
Allow 服务器支持哪些请求方法(如GET、POST等)。
Content-Encoding 文档的编码(Encode)方法。只有在解码之后才可以得到Content-Type头指定的内容类型。利用gzip压缩文档能够显著地减少HTML文档的下载时间。Servlet应该通过查看Accept-Encoding头(即request.getHeader("Accept-Encoding"))检查浏览器是否支持gzip,为支持gzip的浏览器返回经gzip压缩的HTML页面,为其他浏览器返回普通页面。
Content-Length 表示内容长度
Content-Type 表示后面的文档属于什么MIME类型。
Date 当前的GMT时间(零时区时间)
Expires 应该在什么时候认为文档已经过期,从而不再缓存它
Last-Modified 文档的最后改动时间。客户可以通过If-Modified-Since请求头提供一个日期,该请求将被视为一个条件GET,只有改动时间迟于指定时间的文档才会返回,否则返回一个304(Not Modified)状态。
Location 表示客户应当到哪里去提取文档。Location通常不是直接设置的,而是通过HttpServletResponse的sendRedirect方法,该方法同时设置状态代码为302。
Server 服务器名字。Servlet一般不设置这个值,而是由Web服务器自己设置。
Set-Cookie 设置和页面关联的Cookie。
WWW-Authenticate 客户应该在Authorization头中提供什么类型的授权信息
Host 头域指定请求资源的Intenet主机和端口号,必须表示请求url的原始服务器或网关的位置
Referer 主要用来让服务器判断来源页面, 即用户是从哪个页面来的
用来统计用户来源,是从搜索页面来的,还是从其他网站链接过来,或是从书签等访问,以便网站合理定位.
用作防盗链, 即下载时判断来源地址是不是在网站域名之内, 否则就不能下载或显示.
对于某些恶意用户,也可能伪造Referer来获得某些权限,在设计网站时要考虑到这个问题.
还可用做电子商务网站的安全,在提交信用卡等重要信息的页面用referer来判断上一页是不是自己的网站,如果不是,可能是***用自己写的一个表单,来提交,为了能跳过你上一页里的javascript的验证等目的。
但是注意不要把Rerferer用在身份验证或者其他非常重要的检查上,因为Rerferer非常容易在客户端被改变。
User-Agent 头域的内容包含发出请求的用户信息。
Cache-Control 指定请求和响应遵循的缓存机制。
connection 是表示当client和server通信时对于长链接如何进行处理。
在http1.1中,client和server都是默认对方支持长链接的, 如果client使用http1.1协议,但又不希望使用长链接,则需要在header中指明connection的值为close;
如果server方也不想支持长链接,则在response中也需要明确说明connection的值为close。不论request还是response的header中包含了值为close的connection,都表明当前正在使用的tcp链接在当天请求处理完毕后会被断掉。以后client再进行新的请求时就必须创建新的tcp链接了。
常见的HTTP状态码:
200 - 请求成功
301 - 资源(网页等)被永久转移到其它URL
400 - Bad Request //客户端请求有语法错误,不能被服务器所理解
401 - Unauthorized //请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用
403 - Forbidden //服务器收到请求,但是拒绝提供服务
404 - 请求的资源(网页等)不存在
500 - Internal Server Error //服务器发生不可预期的错误
503 - Server Unavailable //服务器当前不能处理客户端的请求,一段时间后可能恢复正常
HTTP状态码由三个十进制数字组成,第一个十进制数字定义了状态码的类型,后两个数字没有分类的作用。 HTTP状态码共分为5种类型:
1 信息,服务器收到请求,需要请求者继续执行操作
2 成功,操作被成功接收并处理
3 重定向,需要进一步的操作以完成请求
4 客户端错误,请求包含语法错误或无法完成请求
5** 服务器错误,服务器在处理请求的过程中发生了错误
更多状态码http://www.runoob.com/http/http-status-codes.html
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。