您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
服务端程序除了应用本身性能外,依赖与服务器本身的性能,今天学习了如何监测服务器性能。包括:CPU、内存、网络IO和磁盘使用率。 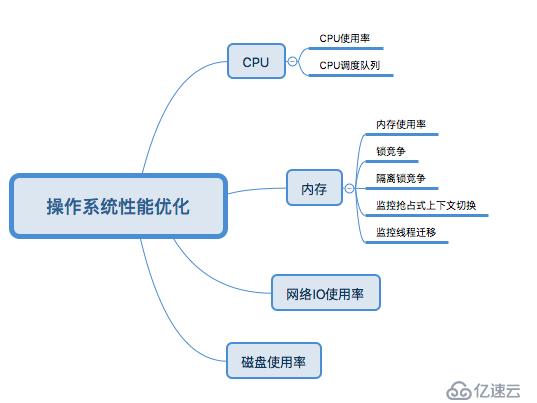
今天先看看如何监测CPU。
oot@SSP001:[/root]vmstat
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 79484 90085784 591052 79229448 0 0 0 6 0 0 1 1 97 0 0其中CPU部分代表cpu的监测数据。
具体含义如下:
| 名称 | 含义 | 英文 |
|---|---|---|
| us | 用户态CPU时间(百分比) | user time |
| sy | 系统态CPU时间(百分比) | system time |
| id | 空闲CPU时间(百分比) | Time spent idle |
| wa | 等待IO的CPU时间 | Time spent waiting for IO |
| st | 不知道什么鬼,忽略 | Time stolen from a virtual machine. Prior to Linux 2.6.11, unknown. |
参数中需要注意的是如果wa很高,代表IO等待时间很高,有可能是磁盘IO出现瓶颈。
[root@Hwseeker-Adx02 ~]# mpstat -P ALL 10 1
Linux 2.6.32-573.3.1.el6.x86_64 (Hwseeker-Adx02) 2018年01月23日 _x86_64_ (24 CPU)
16时45分03秒 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle
16时45分13秒 all 1.96 0.00 0.68 0.00 0.00 0.15 0.00 0.00 97.21
16时45分13秒 0 8.32 0.00 1.83 0.00 0.00 0.20 0.00 0.00 89.64
16时45分13秒 1 2.21 0.00 0.60 0.00 0.00 0.20 0.00 0.00 96.98
16时45分13秒 2 2.23 0.00 0.61 0.00 0.00 0.30 0.00 0.00 96.86
16时45分13秒 3 3.25 0.00 1.32 0.00 0.00 0.61 0.00 0.00 94.82
16时45分13秒 4 0.20 0.00 0.20 0.00 0.00 0.00 0.00 0.00 99.60
16时45分13秒 5 6.38 0.00 2.13 0.00 0.00 1.01 0.00 0.00 90.49
16时45分13秒 6 1.20 0.00 0.40 0.00 0.00 0.00 0.00 0.00 98.40
16时45分13秒 7 0.60 0.00 0.60 0.00 0.00 0.10 0.00 0.00 98.69
16时45分13秒 8 0.60 0.00 0.40 0.00 0.00 0.00 0.00 0.00 98.99
16时45分13秒 9 0.20 0.00 0.10 0.00 0.00 0.00 0.00 0.00 99.70
16时45分13秒 10 1.10 0.00 0.20 0.00 0.00 0.00 0.00 0.00 98.70
16时45分13秒 11 0.50 0.00 0.40 0.00 0.00 0.00 0.00 0.00 99.10
16时45分13秒 12 2.92 0.00 0.70 0.00 0.00 0.10 0.00 0.00 96.27
16时45分13秒 13 0.50 0.00 0.50 0.00 0.00 0.10 0.00 0.00 98.90
16时45分13秒 14 6.90 0.00 1.93 0.00 0.00 0.61 0.00 0.00 90.57
16时45分13秒 15 5.99 0.00 1.42 0.00 0.00 0.61 0.00 0.00 91.98
16时45分13秒 16 0.10 0.00 0.10 0.00 0.00 0.00 0.00 0.00 99.80
16时45分13秒 17 0.71 0.00 0.81 0.00 0.00 0.10 0.00 0.00 98.38
16时45分13秒 18 0.40 0.00 0.30 0.00 0.00 0.00 0.00 0.00 99.30
16时45分13秒 19 0.60 0.00 0.50 0.00 0.00 0.00 0.00 0.00 98.89
16时45分13秒 20 0.30 0.00 0.40 0.00 0.00 0.00 0.00 0.00 99.30
16时45分13秒 21 0.20 0.00 0.30 0.00 0.00 0.00 0.00 0.00 99.50
16时45分13秒 22 0.30 0.00 0.30 0.00 0.00 0.00 0.00 0.00 99.40
16时45分13秒 23 1.31 0.00 0.40 0.00 0.00 0.00 0.00 0.00 98.29mpstat可以查看每个cpu的状态,可以发现应用中一些线程比其他线程消耗了更多CPU周期,还是所有线程基本平分CPU周期。如果是所有线程平分CPU周期,代表应用扩展性很好。
mpstat命令具体使用方法可以自行百度。这里我们需要关注的还是%usr/%sys/%iowait这几个字段。
[root@Hwseeker-Adx02 ~]# top
top - 16:51:46 up 762 days, 16:33, 1 user, load average: 0.65, 0.40, 0.29
Tasks: 598 total, 1 running, 596 sleeping, 0 stopped, 1 zombie
Cpu(s): 1.6%us, 0.7%sy, 0.0%ni, 97.5%id, 0.0%wa, 0.0%hi, 0.1%si, 0.0%st
Mem: 132119192k total, 130669000k used, 1450192k free, 1157188k buffers
Swap: 131071996k total, 4017704k used, 127054292k free, 88117860k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
36660 root 20 0 24.3g 4.7g 13m S 16.8 3.7 4401:08 java
36888 root 20 0 24.4g 4.7g 13m S 14.8 3.8 4332:33 java
52318 root 20 0 2353m 1.0g 39m S 5.9 0.8 67399:27 firefox
5631 root 20 0 1252m 29m 1924 S 2.0 0.0 22434:02 main
21114 root 20 0 150m 13m 1364 S 2.0 0.0 664:08.76 redis-servertop命令不仅能监控用户态CPU、系统态cpu、空闲率,而且还会按照cpu使用率把进程列出来,使用起来很方便。
运行队列中是哪些正在等待可用CPU的轻量级进程。对于判断CPU是否满负荷运转很有帮助。
对于调度队列长度,该如何处理呢?
oot@SSP001:[/root]vmstat
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 79484 90085784 591052 79229448 0 0 0 6 0 0 1 1 97 0 0其中r列就是队列长度。
本博文内容为《Java性能优化权威指南》的读书笔记整理而来
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。