您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
导语:宜信于2019年3月29日正式开源nextsystem4(以下简称“NS4”)系列模块。此次开源的NS4系列模块是围绕当前支付系统笨重、代码耦合度高、维护成本高而产生的分布式业务系统解决方案。NS4系列框架允许创建复杂的流程/业务流,对于业务服务节点的实现可串联,可分布式。其精简、轻量,实现了“脱容器”(不依赖tomcat、jetty等容器)独立运行。NS4系列框架的设计理念是将业务和逻辑进行分离,开发人员只需通过简单的配置和业务实现就可以实现逻辑复杂、性能高效、功能稳定的业务系统。点击查看框架整体介绍
NS4系列包括4个开源模块,分别是:ns4_frame 分布式服务框架(详情点击查看:开源|ns4_frame分布式服务框架开发指南)、ns4_gear_idgen ID生成器组件(NS4框架Demo示例)、ns4_gear_watchdog 监控系统组件(服务守护、应用性能监控、数据采集、自动化报警系统)和ns4_chatbot通讯组件。
其中,ns4_gear_idgen(ID生成器)是基于ns4_frame框架实现的,它支持分布式部署,生成全局唯一的 ID,其中长度、前缀、后缀、步长、进制也可根据自己的业务自由配置,还可以通过ns4_gear_idgen对NS4.0框架进行测试。本文重点介绍ns4_gear_idgen (ID生成器)方案具备哪些优点。
项目开源地址:https://github.com/newsettle/ns4_gear_idgen
在复杂的系统中,往往需要使用一个有意义且有序的序列号来作为全局唯一的ID,来对大量的数据(如订单账户)进行标识。
取当前毫秒数/微秒作为ID ,如System.currentTimeMillis()
优点
缺点
UUID(Universally Unique Identifier)的标准型式包含32个16进制数字,以连字号分为五段,形式为8-4-4-4-12的36个字符。示例:550e8400-e29b-41d4-a716- 446655440000,到目前为止业界一共有 5 种方式生成UUID,详情见IETF发布的UUID规范 A Universally Unique IDentifier (UUID) URN Namespace。
优点
缺点
ID作为主键时在特定的环境会存在一些问题,比如做DB主键的场景下,UUID就非常不适用:
All indexes other than the clustered index are known as secondary indexes. In InnoDB, each record in a secondary index contains the primary key columns for the row, as well as the columns specified for the secondary index. InnoDB uses this primary key value to search for the row in the clustered index. If the primary key is long, the secondary indexes use more space, so it is advantageous to have a short primary key.
这种方案大致来说是一种以划分命名空间(UUID也算,由于比较常见,所以单独分析)来生成ID的一种算法,这种方案把64-bit分别划分成多段,分开来标示机器、时间等,比如在snowflake中的64-bit分别表示。如下图(图片来自网络)所示:

41-bit的时间可以表示(1L<<41)/(1000L*3600*24*365)=69年的时间,10-bit机器可以分别表示1024台机器。如果我们对IDC划分有需求,还可以将10-bit分5-bit给IDC,分5-bit给工作机器。这样就可以表示32个IDC,每个IDC下可以有32台机器,可以根据自身需求定义。
12 个自增序列号可以表示2^12个ID,理论上snowflake方案的QPS约为409.6w/s,这种分配方式可以保证在任何一个IDC的任何一台机器在任意毫秒内生成的ID都是不同的。
优点
缺点
以MySQL举例,利用给字段设置auto_increment_increment和 auto_increment_offset来保证ID自增,每次业务使用下列SQL读写MySQL得到ID号。
begin;
REPLACE INTO Tickets64 (stub) VALUES ('a');
SELECT LAST_INSERT_ID();
commit;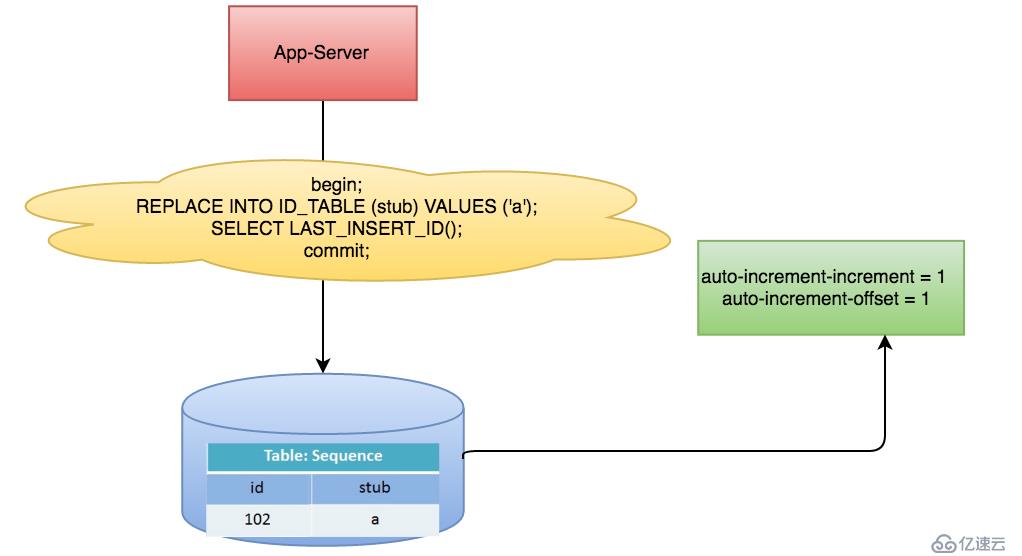
优点
缺点
Redis的所有命令操作都是单线程的,本身提供像incr和increby这样的自增原子命令,所以能保证生成的ID肯定是唯一有序的。
考虑到单节点的性能瓶颈,可以使用Redis集群来获取更高的吞吐量。假如一个集群中有5台Redis。可以初始化每台Redis的值分别是1, 2, 3, 4, 5,然后步长都是5。各个Redis生成的ID为:
A:1, 6, 11, 16, 21
B:2, 7, 12, 17, 22
C:3, 8, 13, 18, 23
D:4, 9, 14, 19, 24
E:5, 10, 15, 20, 25
优点
缺点
先看下数据库表设计:
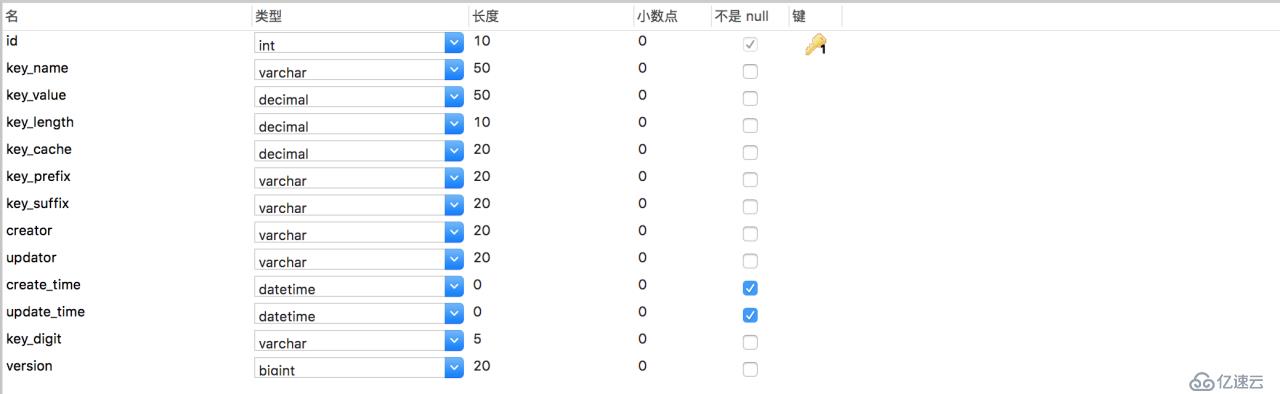
字段说明:
key_prefix:生成ID的前缀,可配置自定义前缀+日期部分 如: ${date14}/TEST${date14}
ID前缀日期部分支持以下几种日期格式: 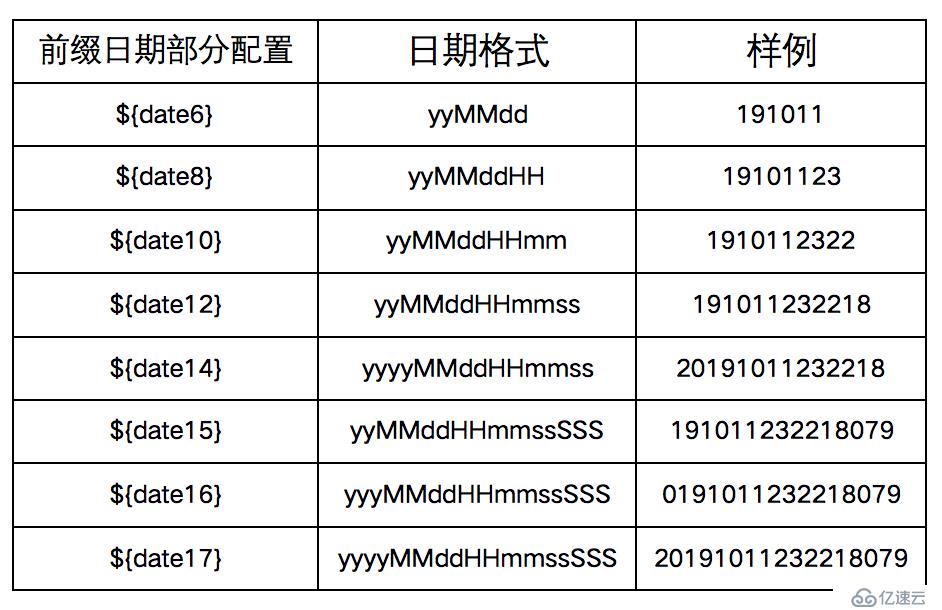
优点
该ID生成器是基于NS4框架实现的,支持分布式部署,同时生成的ID长度、前缀、后缀、步长,进制也可根据自己的业务自由的配置。
其功能可分为以下几个部分:

见 ns4_gear_idgen 源码下 gear_key.sql
内容来源:宜信技术学院
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。