您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
JDBC执行数据库操作语句,首先需要将sql语句打包成为网络字节流,传递给数据库,数据库经过解包,然后编译sql语句,最后执行,然后将结果通过字节流的形式返回给JDBC API
简单的来说大致分为以下几点:
JDBC打包sql语句
发送字节流至数据库
数据库解包
检查sql语法,编译sql
执行sql语句
<br/>
注册驱动 (Driver)
建立连接(创建Connection)
创建执行sql语句(通常是创建Statement或者其子类)
执行语句
处理执行结果(在非查询语句中,该步骤是可以省略的)
案例
@Test
public void wholeExample(){
try {
//1.注册驱动
Class.forName("com.mysql.jdbc.Driver");
//2.获取数据库连接
Connection conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/test", "root","123456");
//3.创建执行句柄
Statement stmt = conn.createStatement();
//4.执行sql语句
ResultSet rs = stmt.executeQuery("select * from user");
//5.处理执行结果
while(rs.next()){
System.out.println("id:"+rs.getInt(1)+"\tname:"+rs.getString(2)+"\tbirthday:"+rs.getDate(3)+"\tmoney:"+rs.getFloat(4));
}
//6.释放资源
rs.close();
stmt.close();
conn.close();
} catch (SQLException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
<br/>
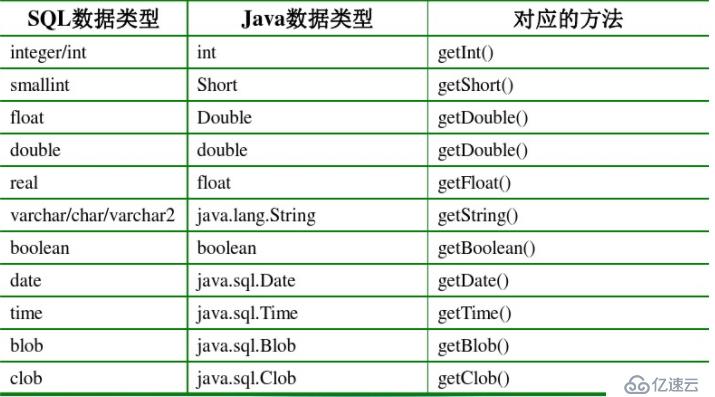
当我们存放大量的文本信息时,数据库中的varchar或者varchar2肯定是不能满足的,varchar2好像最多只能有4000个长度,存放一篇很长的文章或者一个文本信息,我们采用CLOB类型
针对二进制文件进行的存取,比如图片,音频等信息
//stream文件流
PreparedStatement.setBlob(index, stream)<br/>
数据库的事务是保证数据完整性的一种机制,简而言之,就是怎样确保数据的执行过程要么都成功,要么都失败
<br/>
原子性(atomicity):组成事务处理的语句形成了一个逻辑单元,不能只执行其中的一部分
一致性(consistency):在事务处理执行前后,数据库是一致的(两个账户要么都变,或者都不变)
隔离性(isolcation):一个事务处理对另一个事务处理没有影响
Jdbc的事务默认是打开的,也就是说执行每一步操作的话,事务都会隐式的进行提交,在抛出异常之前,我们的更改操作已经同步到了数据库中去
//提交事务
//回滚事务
通常所说的跨库事务,要求几个数据库的事务在一个应用中保持一致,JTA就是为了解决这个问题而诞生的
在数据库操作中PreparedStatement会带来很大的方便,减少拼写sql字符串带来的麻烦,防止SQL注入的发生.
PreparedStatement是Statement的子类
在数据库操作中调用数据库中的存储过程
案例:执行有参数有返回值的存储过程
create or replace procedure test1(in id integer,in name varchar(20),in money float,out counter integer)
as
begin
insert into user values(id,name,now(),money);
select count(1) into counter from user;
commit;
end test1; @Test
public void callProcedureWithParamWithResult() throws SQLException{
Connection conn = null;
CallableStatement stmt = null;
ResultSet rs = null;
try {
conn = ConnCreate.getConnection("jdbc:mysql://localhost:3306/test",
"root", "123456");
String sql = "{call test1(?,?,?,?)}";
stmt = conn.prepareCall(sql);
stmt.setInt(1, 17);
stmt.setString(2, "test");
stmt.setFloat(3, 6000);
stmt.registerOutParameter(1, Types.INTEGER);
stmt.executeUpdate();
int counter = stmt.getInt(4);
System.out.println(counter);
} finally {
ConnCreate.close(conn, stmt, rs);
}
}<br/>
//添加一条条的sql
// 执行批处理
利用sql语句进行分页(eg: mysql的limit ? ?, 一个offsize偏移量,另一个pagesize页面数量)
@Test
public void page() throws SQLException{
page(100,20);
}
static void page(int start,int total) throws SQLException{
Connection conn = null;
PreparedStatement stmt = null;
ResultSet rs = null;
try {
conn = ConnCreate.getConnection("jdbc:mysql://localhost:3306/test",
"root", "123456");
String sql = "select * from user limit ?,?";
stmt = conn.prepareStatement(sql);
stmt.setInt(1, start);
stmt.setInt(2, total);
rs = stmt.executeQuery();
while(rs.next()) //向下滚动
{
System.out.println("name:"+rs.getString(2)+"id:"+rs.getInt(1));
}
} finally {
ConnCreate.close(conn, stmt, null);
}
}使用jdbc最大的开销之一就是创建数据库,当我们频繁的创建数据库时,势必影响应用的效率,或者在数据库关闭出现问题时,我们不能马上释放,时间长一些,整个数据库的 资源将会被我们的应用耗尽
C3P0
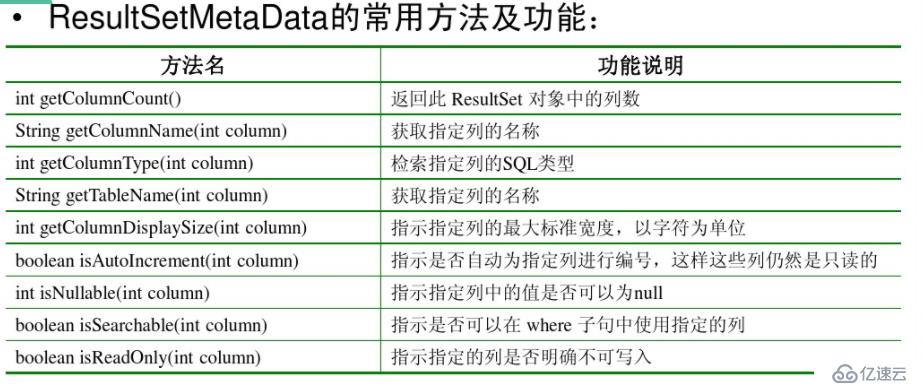
如果我们不知道我们的一个sql语句查询了几列结果集,并且每列的列名,类型等信息,这个时候我们应该使用ResultSetMetaData
<br/>
@Test
public void resultMeta() throws SQLException{
String sql="select * from user";
Connection conn = null;
PreparedStatement stmt = null;
ResultSet rs = null;
try {
conn = ConnFactory.getConnection();
stmt = conn.prepareStatement(sql);
rs = stmt.executeQuery();
ResultSetMetaData rsmd = rs.getMetaData();
int count = rsmd.getColumnCount();
for(int i=1;i<=count;++i){
System.out.println("Type:"+rsmd.getColumnType(i));
System.out.println("ColumnName:"+rsmd.getColumnName(i));
System.out.println("ColumnLable:"+rsmd.getColumnLabel(i));
}
} finally{
ConnFactory.close(conn, stmt, rs);
}
}免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。