您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
1.1 pretty
http://50.1.1.111:9200/haoke/user/Bct_zXAB_G2CqNSl4VI9 #用浏览器访问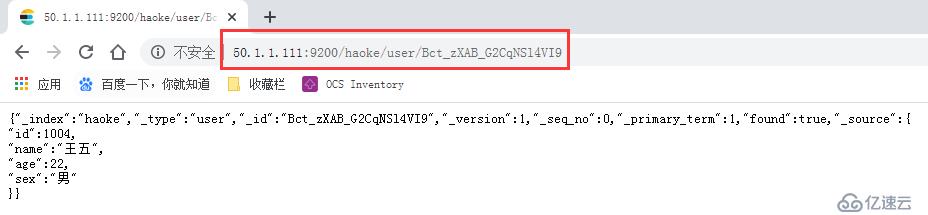
http://50.1.1.111:9200/haoke/user/Bct_zXAB_G2CqNSl4VI9?pretty #用浏览器访问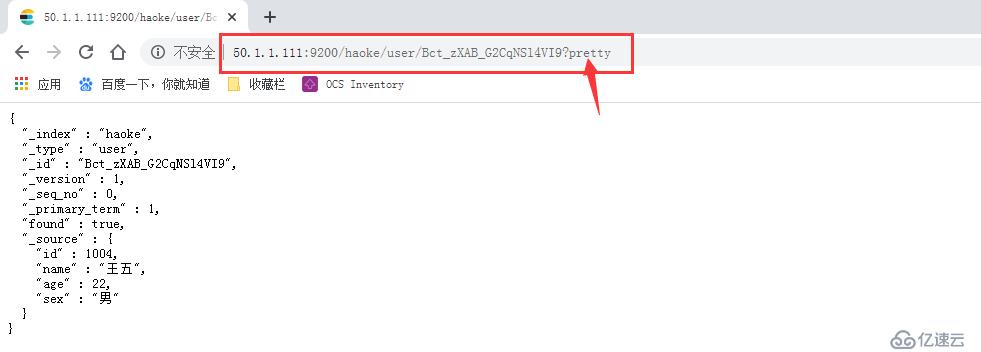
#能看到加了?pretty 就会以json格式返回结果
1.2指定响应字段
在响应的数据中,如果我们不需要全部的字段,可以指定某些需要的字段进行返回。
GET http://50.1.1.111:9200/haoke/user/Bct_zXAB_G2CqNSl4VI9?_source=id,name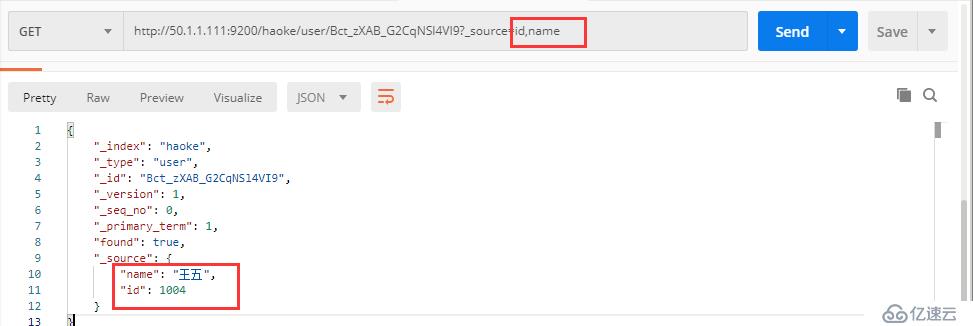
#只显示了两个字段,注意后面更的?号
1.3只返回原始数据,不需要元数据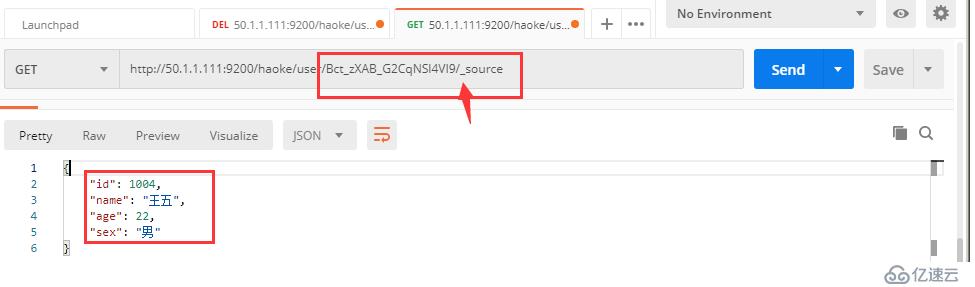
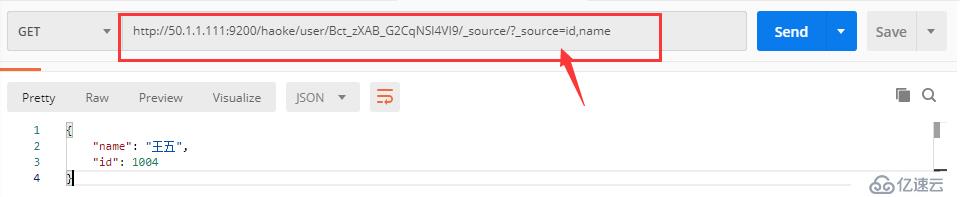
#还能,既不显示元数据,也能筛选字段
1.4 如果我们只需要判断文档是否存在,而不是查询文档内容
HEAD http://50.1.1.111:9200/haoke/user/Bct_zXAB_G2CqNSl4VI9
#返回状态码200 为存在。
#400 开头,为不存在
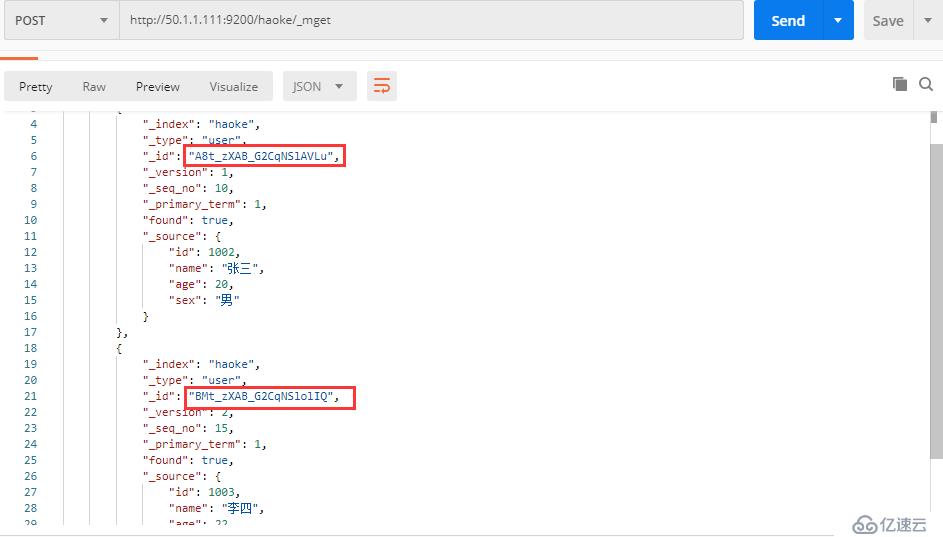
POST http://50.1.1.111:9200/haoke/_mget
{
"ids" : [ "A8t_zXAB_G2CqNSlAVLu", "BMt_zXAB_G2CqNSlolIQ" ] ##这里面是元数据的_id
}
在Elasticsearch中,支持批量的插入、修改、删除操作,都是通过_bulk的api完成的。
_bulk操作
在Elasticsearch中,支持批量的插入、修改、删除操作,都是通过_bulk的api完成的。
请求格式如下:(请求格式不同寻常)
{ action: { metadata }}\n
{ request body }\n
{ action: { metadata }}\n
{ request body }\n
\n{"create":{"_index":"haoke","_type":"user","_id":2001}}
{"id":2001,"name":"name1","age": 20,"sex": "男"}
{"create":{"_index":"haoke","_type":"user","_id":2002}}
{"id":2002,"name":"name2","age": 20,"sex": "男"}
{"create":{"_index":"haoke","_type":"user","_id":2003}}
{"id":2003,"name":"name3","age": 20,"sex": "男"}
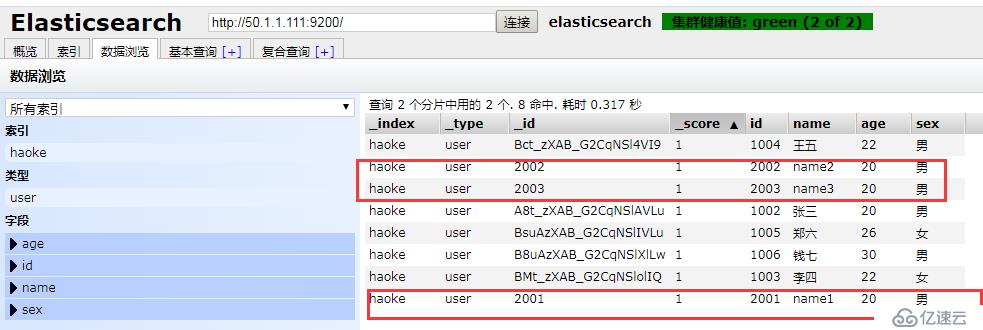
POST http://50.1.1.111:9200/haoke/user/_bulk
{"delete":{"_index":"haoke","_type":"user","_id":2001}}
{"delete":{"_index":"haoke","_type":"user","_id":2002}}
{"delete":{"_index":"haoke","_type":"user","_id":2003}}
#刚插入的数据,被删除了。
其他操作就类似了。
一次请求多少性能最高?
整个批量请求需要被加载到接受我们请求节点的内存里,所以请求越大,给其它请求可用的内存就越小。有一个最佳的bulk请求大小。超过这个大小,性能不再提升而且可能降低。
最佳大小,当然并不是一个固定的数字。它完全取决于你的硬件、你文档的大小和复杂度以及索引和搜索的负载。
幸运的是,这个最佳点(sweetspot)还是容易找到的:试着批量索引标准的文档,随着大小的增长,当性能开始降低,说明你每个批次的大小太大了。开始的数量可以在1000~5000个文档之间,如果你的文档非常大,可以使用较小的批次。
通常着眼于你请求批次的物理大小是非常有用的。一千个1kB的文档和一千个1MB的文档大不相同。一个好的
批次最好保持在5-15MB大小间。
和SQL使用LIMIT 关键字返回只有一页的结果一样,Elasticsearch接受from 和size 参数:
size: 结果数,默认10
from: 跳过开始的结果数,默认0POST http://50.1.1.111:9200/haoke/user/_search?size=1&from=2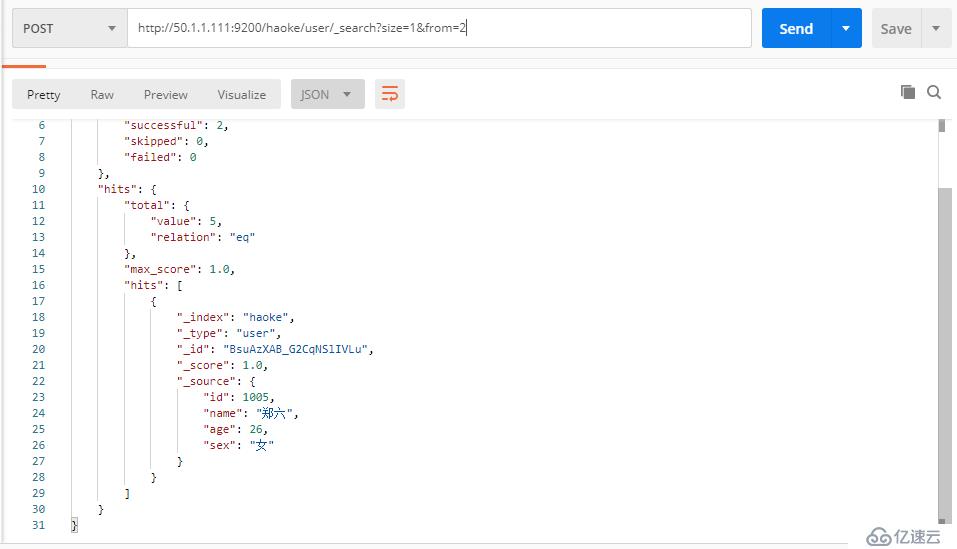
#表示跳过两个,显示1个,就表示只显示第三个
5.映射
前面我们创建的索引以及插入数据,都是由Elasticsearch进行自动判断类型,有些时候我们是需要进行明确字段类型
的,否则,自动判断的类型和实际需求是不相符的。
自动判断的规则如下:
Elasticsearch中支持的类型如下: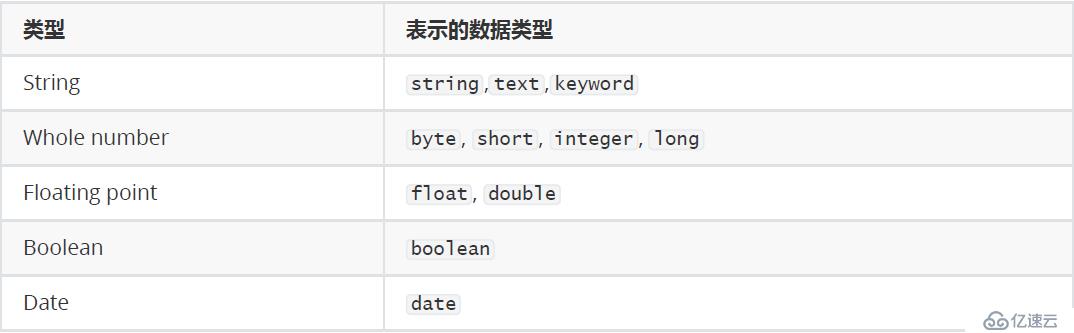
string类型在ElasticSearch 旧版本中使用较多,从ElasticSearch 5.x开始不再支持string,由text和keyword类型替代。
text 类型,当一个字段是要被全文搜索的,比如Email内容、产品描述,应该text类型。设置text类型以后,字段内容会被分析,在生成倒排索引以前,字符串会被分析器分成一个一个词项。text类型的字段不用于排序,很少用于聚合。
keyword类型适用于索引结构化的字段,比如email地址、主机名、状态码和标签。如果字段需要进行过滤(比如查找已发布博客中status属性为published的文章)、排序、聚合。keyword类型的字段只能通过精确值搜索到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。