жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
дёҚзҹҘйҒ“еӨ§е®¶д№ӢеүҚеҜ№зұ»дјјд»Җд№ҲжҳҜMySQLзҙўеј•еҺҹзҗҶеҸҠдјҳеҢ–зҡ„еҹәжң¬жӯҘйӘӨзҡ„ж–Үз« жңүж— дәҶи§ЈпјҢд»ҠеӨ©жҲ‘еңЁиҝҷйҮҢз»ҷеӨ§е®¶еҶҚз®ҖеҚ•зҡ„и®Іи®ІгҖӮж„ҹе…ҙи¶Јзҡ„иҜқе°ұдёҖиө·жқҘзңӢзңӢжӯЈж–ҮйғЁеҲҶеҗ§пјҢзӣёдҝЎзңӢе®Ңд»Җд№ҲжҳҜMySQLзҙўеј•еҺҹзҗҶеҸҠдјҳеҢ–зҡ„еҹәжң¬жӯҘйӘӨдҪ дёҖе®ҡдјҡжңүжүҖ收иҺ·зҡ„гҖӮ 
жң¬ж–ҮжҳҜзҫҺеӣўдёҖдҪҚеӨ§дҪ¬еҶҷзҡ„пјҢиҝҳдёҚй”ҷжӢҝеҮәжқҘе’ҢеӨ§е®¶еҲҶдә«дёӢ,д»Јз ҒдёӯеөҢеҘ—еңЁhtmlдёӯsqlиҜӯеҸҘжҳҜjavaжЎҶжһ¶зҡ„еҶҷжі•пјҢзҗҶи§Је…¶sqlиҰҒжү§иЎҢзҡ„иҜӯеҸҘеҚіеҸҜгҖӮ
MySQLеҮӯеҖҹзқҖеҮәиүІзҡ„жҖ§иғҪгҖҒдҪҺе»үзҡ„жҲҗжң¬гҖҒдё°еҜҢзҡ„иө„жәҗпјҢе·Із»ҸжҲҗдёәз»қеӨ§еӨҡж•°дә’иҒ”зҪ‘е…¬еҸёзҡ„йҰ–йҖүе…ізі»еһӢж•°жҚ®еә“гҖӮиҷҪ然жҖ§иғҪеҮәиүІпјҢдҪҶжүҖи°“вҖңеҘҪ马й…ҚеҘҪйһҚвҖқпјҢеҰӮдҪ•иғҪеӨҹжӣҙеҘҪзҡ„дҪҝз”Ёе®ғпјҢе·Із»ҸжҲҗдёәејҖеҸ‘е·ҘзЁӢеёҲзҡ„еҝ…дҝ®иҜҫпјҢжҲ‘们з»Ҹеёёдјҡд»ҺиҒҢдҪҚжҸҸиҝ°дёҠзңӢеҲ°иҜёеҰӮвҖңзІҫйҖҡMySQLвҖқгҖҒвҖңSQLиҜӯеҸҘдјҳеҢ–вҖқгҖҒвҖңдәҶи§Јж•°жҚ®еә“еҺҹзҗҶвҖқзӯүиҰҒжұӮгҖӮжҲ‘们зҹҘйҒ“дёҖиҲ¬зҡ„еә”з”Ёзі»з»ҹпјҢиҜ»еҶҷжҜ”дҫӢеңЁ10:1е·ҰеҸіпјҢиҖҢдё”жҸ’е…Ҙж“ҚдҪңе’ҢдёҖиҲ¬зҡ„жӣҙж–°ж“ҚдҪңеҫҲе°‘еҮәзҺ°жҖ§иғҪй—®йўҳпјҢйҒҮеҲ°жңҖеӨҡзҡ„пјҢд№ҹжҳҜжңҖе®№жҳ“еҮәй—®йўҳзҡ„пјҢиҝҳжҳҜдёҖдәӣеӨҚжқӮзҡ„жҹҘиҜўж“ҚдҪңпјҢжүҖд»ҘжҹҘиҜўиҜӯеҸҘзҡ„дјҳеҢ–жҳҫ然жҳҜйҮҚдёӯд№ӢйҮҚгҖӮ
жң¬дәәд»Һ13е№ҙ7жңҲд»Ҫиө·пјҢдёҖзӣҙеңЁзҫҺеӣўж ёеҝғдёҡеҠЎзі»з»ҹйғЁеҒҡж…ўжҹҘиҜўзҡ„дјҳеҢ–е·ҘдҪңпјҢе…ұи®ЎеҚҒдҪҷдёӘзі»з»ҹпјҢзҙҜи®Ўи§ЈеҶіе’Ңз§ҜзҙҜдәҶдёҠзҷҫдёӘж…ўжҹҘиҜўжЎҲдҫӢгҖӮйҡҸзқҖдёҡеҠЎзҡ„еӨҚжқӮжҖ§жҸҗеҚҮпјҢйҒҮеҲ°зҡ„й—®йўҳеҚғеҘҮзҷҫжҖӘпјҢдә”иҠұе…«й—ЁпјҢеҢӘеӨ·жүҖжҖқгҖӮжң¬ж–Үж—ЁеңЁд»ҘејҖеҸ‘е·ҘзЁӢеёҲзҡ„и§’еәҰжқҘи§ЈйҮҠж•°жҚ®еә“зҙўеј•зҡ„еҺҹзҗҶе’ҢеҰӮдҪ•дјҳеҢ–ж…ўжҹҘиҜўгҖӮ
<span class="hljs-keyword">select</span>
<span class="hljs-keyword">count</span>(*) <span class="hljs-keyword">from</span>
task
<span class="hljs-keyword">where</span>
<span class="hljs-keyword">status</span>=<span class="hljs-number">2</span>
<span class="hljs-keyword">and</span> operator_id=<span class="hljs-number">20839</span>
<span class="hljs-keyword">and</span> operate_time><span class="hljs-number">1371169729</span>
<span class="hljs-keyword">and</span> operate_time<<span class="hljs-number">1371174603</span>
<span class="hljs-keyword">and</span> <span class="hljs-keyword">type</span>=<span class="hljs-number">2</span>;зі»з»ҹдҪҝз”ЁиҖ…еҸҚеә”жңүдёҖдёӘеҠҹиғҪи¶ҠжқҘи¶Ҡж…ўпјҢдәҺжҳҜе·ҘзЁӢеёҲжүҫеҲ°дәҶдёҠйқўзҡ„SQLгҖӮ
并且е…ҙиҮҙеҶІеҶІзҡ„жүҫеҲ°дәҶжҲ‘пјҢвҖңиҝҷдёӘSQLйңҖиҰҒдјҳеҢ–пјҢз»ҷжҲ‘жҠҠжҜҸдёӘеӯ—ж®өйғҪеҠ дёҠзҙўеј•вҖқгҖӮ
жҲ‘еҫҲжғҠ讶пјҢй—®йҒ“пјҡвҖңдёәд»Җд№ҲйңҖиҰҒжҜҸдёӘеӯ—ж®өйғҪеҠ дёҠзҙўеј•пјҹвҖқ
вҖңжҠҠжҹҘиҜўзҡ„еӯ—ж®өйғҪеҠ дёҠзҙўеј•дјҡжӣҙеҝ«вҖқпјҢе·ҘзЁӢеёҲдҝЎеҝғж»Ўж»ЎгҖӮ
вҖңиҝҷз§Қжғ…еҶөе®Ңе…ЁеҸҜд»Ҙе»әдёҖдёӘиҒ”еҗҲзҙўеј•пјҢеӣ дёәжҳҜжңҖе·ҰеүҚзјҖеҢ№й…ҚпјҢжүҖд»Ҙoperate_timeйңҖиҰҒж”ҫеҲ°жңҖеҗҺпјҢиҖҢдё”иҝҳйңҖиҰҒжҠҠе…¶д»–зӣёе…ізҡ„жҹҘиҜўйғҪжӢҝжқҘпјҢйңҖиҰҒеҒҡдёҖдёӘз»јеҗҲиҜ„дј°гҖӮвҖқ
вҖңиҒ”еҗҲзҙўеј•пјҹжңҖе·ҰеүҚзјҖеҢ№й…Қпјҹз»јеҗҲиҜ„дј°пјҹвҖқе·ҘзЁӢеёҲдёҚзҰҒйҷ·е…ҘдәҶжІүжҖқгҖӮ
еӨҡж•°жғ…еҶөдёӢпјҢжҲ‘们зҹҘйҒ“зҙўеј•иғҪеӨҹжҸҗй«ҳжҹҘиҜўж•ҲзҺҮпјҢдҪҶеә”иҜҘеҰӮдҪ•е»әз«Ӣзҙўеј•пјҹзҙўеј•зҡ„йЎәеәҸеҰӮдҪ•пјҹи®ёеӨҡдәәеҚҙеҸӘзҹҘйҒ“еӨ§жҰӮгҖӮе…¶е®һзҗҶи§ЈиҝҷдәӣжҰӮеҝө并дёҚйҡҫпјҢиҖҢдё”зҙўеј•зҡ„еҺҹзҗҶиҝңжІЎжңүжғіиұЎзҡ„йӮЈд№ҲеӨҚжқӮгҖӮ
зҙўеј•зҡ„зӣ®зҡ„еңЁдәҺжҸҗй«ҳжҹҘиҜўж•ҲзҺҮпјҢеҸҜд»Ҙзұ»жҜ”еӯ—е…ёпјҢеҰӮжһңиҰҒжҹҘвҖңmysqlвҖқиҝҷдёӘеҚ•иҜҚпјҢжҲ‘们иӮҜе®ҡйңҖиҰҒе®ҡдҪҚеҲ°mеӯ—жҜҚпјҢ然еҗҺд»ҺдёӢеҫҖдёӢжүҫеҲ°yеӯ—жҜҚпјҢеҶҚжүҫеҲ°еү©дёӢзҡ„sqlгҖӮеҰӮжһңжІЎжңүзҙўеј•пјҢйӮЈд№ҲдҪ еҸҜиғҪйңҖиҰҒжҠҠжүҖжңүеҚ•иҜҚзңӢдёҖйҒҚжүҚиғҪжүҫеҲ°дҪ жғіиҰҒзҡ„пјҢеҰӮжһңжҲ‘жғіжүҫеҲ°mејҖеӨҙзҡ„еҚ•иҜҚе‘ўпјҹжҲ–иҖ…zeејҖеӨҙзҡ„еҚ•иҜҚе‘ўпјҹжҳҜдёҚжҳҜи§үеҫ—еҰӮжһңжІЎжңүзҙўеј•пјҢиҝҷдёӘдәӢжғ…ж №жң¬ж— жі•е®ҢжҲҗпјҹ
йҷӨдәҶиҜҚе…ёпјҢз”ҹжҙ»дёӯйҡҸеӨ„еҸҜи§Ғзҙўеј•зҡ„дҫӢеӯҗпјҢеҰӮзҒ«иҪҰз«ҷзҡ„иҪҰж¬ЎиЎЁгҖҒеӣҫд№Ұзҡ„зӣ®еҪ•зӯүгҖӮе®ғ们зҡ„еҺҹзҗҶйғҪжҳҜдёҖж ·зҡ„пјҢйҖҡиҝҮдёҚж–ӯзҡ„зј©е°ҸжғіиҰҒиҺ·еҫ—ж•°жҚ®зҡ„иҢғеӣҙжқҘзӯӣйҖүеҮәжңҖз»ҲжғіиҰҒзҡ„з»“жһңпјҢеҗҢж—¶жҠҠйҡҸжңәзҡ„дәӢ件еҸҳжҲҗйЎәеәҸзҡ„дәӢ件пјҢд№ҹе°ұжҳҜжҲ‘们жҖ»жҳҜйҖҡиҝҮеҗҢдёҖз§ҚжҹҘжүҫж–№ејҸжқҘй”Ғе®ҡж•°жҚ®гҖӮ
ж•°жҚ®еә“д№ҹжҳҜдёҖж ·пјҢдҪҶжҳҫ然иҰҒеӨҚжқӮи®ёеӨҡпјҢеӣ дёәдёҚд»…йқўдёҙзқҖзӯүеҖјжҹҘиҜўпјҢиҝҳжңүиҢғеӣҙжҹҘиҜў(>гҖҒ<гҖҒbetweenгҖҒin)гҖҒжЁЎзіҠжҹҘиҜў(like)гҖҒ并йӣҶжҹҘиҜў(or)зӯүзӯүгҖӮж•°жҚ®еә“еә”иҜҘйҖүжӢ©жҖҺд№Ҳж ·зҡ„ж–№ејҸжқҘеә”еҜ№жүҖжңүзҡ„й—®йўҳе‘ўпјҹжҲ‘们еӣһжғіеӯ—е…ёзҡ„дҫӢеӯҗпјҢиғҪдёҚиғҪжҠҠж•°жҚ®еҲҶжҲҗж®өпјҢ然еҗҺеҲҶж®өжҹҘиҜўе‘ўпјҹжңҖз®ҖеҚ•зҡ„еҰӮжһң1000жқЎж•°жҚ®пјҢ1еҲ°100еҲҶжҲҗ第дёҖж®өпјҢ101еҲ°200еҲҶжҲҗ第дәҢж®өпјҢ201еҲ°300еҲҶжҲҗ第дёүж®өвҖҰвҖҰиҝҷж ·жҹҘ第250жқЎж•°жҚ®пјҢеҸӘиҰҒжүҫ第дёүж®өе°ұеҸҜд»ҘдәҶпјҢдёҖдёӢеӯҗеҺ»йҷӨдәҶ90%зҡ„ж— ж•Ҳж•°жҚ®гҖӮдҪҶеҰӮжһңжҳҜ1еҚғдёҮзҡ„и®°еҪ•е‘ўпјҢеҲҶжҲҗеҮ ж®өжҜ”иҫғеҘҪпјҹзЁҚжңүз®—жі•еҹәзЎҖзҡ„еҗҢеӯҰдјҡжғіеҲ°жҗңзҙўж ‘пјҢе…¶е№іеқҮеӨҚжқӮеәҰжҳҜlgNпјҢе…·жңүдёҚй”ҷзҡ„жҹҘиҜўжҖ§иғҪгҖӮдҪҶиҝҷйҮҢжҲ‘们еҝҪз•ҘдәҶдёҖдёӘе…ій”®зҡ„й—®йўҳпјҢеӨҚжқӮеәҰжЁЎеһӢжҳҜеҹәдәҺжҜҸж¬ЎзӣёеҗҢзҡ„ж“ҚдҪңжҲҗжң¬жқҘиҖғиҷ‘зҡ„пјҢж•°жҚ®еә“е®һзҺ°жҜ”иҫғеӨҚжқӮпјҢж•°жҚ®дҝқеӯҳеңЁзЈҒзӣҳдёҠпјҢиҖҢдёәдәҶжҸҗй«ҳжҖ§иғҪпјҢжҜҸж¬ЎеҸҲеҸҜд»ҘжҠҠйғЁеҲҶж•°жҚ®иҜ»е…ҘеҶ…еӯҳжқҘи®Ўз®—пјҢеӣ дёәжҲ‘们зҹҘйҒ“и®ҝй—®зЈҒзӣҳзҡ„жҲҗжң¬еӨ§жҰӮжҳҜи®ҝй—®еҶ…еӯҳзҡ„еҚҒдёҮеҖҚе·ҰеҸіпјҢжүҖд»Ҙз®ҖеҚ•зҡ„жҗңзҙўж ‘йҡҫд»Ҙж»Ўи¶іеӨҚжқӮзҡ„еә”з”ЁеңәжҷҜгҖӮ
еүҚйқўжҸҗеҲ°дәҶи®ҝй—®зЈҒзӣҳпјҢйӮЈд№ҲиҝҷйҮҢе…Ҳз®ҖеҚ•д»Ӣз»ҚдёҖдёӢзЈҒзӣҳIOе’Ңйў„иҜ»пјҢзЈҒзӣҳиҜ»еҸ–ж•°жҚ®йқ зҡ„жҳҜжңәжў°иҝҗеҠЁпјҢжҜҸж¬ЎиҜ»еҸ–ж•°жҚ®иҠұиҙ№зҡ„ж—¶й—ҙеҸҜд»ҘеҲҶдёәеҜ»йҒ“ж—¶й—ҙгҖҒж—ӢиҪ¬е»¶иҝҹгҖҒдј иҫ“ж—¶й—ҙдёүдёӘйғЁеҲҶпјҢеҜ»йҒ“ж—¶й—ҙжҢҮзҡ„жҳҜзЈҒиҮӮ移еҠЁеҲ°жҢҮе®ҡзЈҒйҒ“жүҖйңҖиҰҒзҡ„ж—¶й—ҙпјҢдё»жөҒзЈҒзӣҳдёҖиҲ¬еңЁ5msд»ҘдёӢпјӣж—ӢиҪ¬е»¶иҝҹе°ұжҳҜжҲ‘们з»Ҹеёёеҗ¬иҜҙзҡ„зЈҒзӣҳиҪ¬йҖҹпјҢжҜ”еҰӮдёҖдёӘзЈҒзӣҳ7200иҪ¬пјҢиЎЁзӨәжҜҸеҲҶй’ҹиғҪиҪ¬7200ж¬ЎпјҢд№ҹе°ұжҳҜиҜҙ1з§’й’ҹиғҪиҪ¬120ж¬ЎпјҢж—ӢиҪ¬е»¶иҝҹе°ұжҳҜ1/120/2 = 4.17msпјӣдј иҫ“ж—¶й—ҙжҢҮзҡ„жҳҜд»ҺзЈҒзӣҳиҜ»еҮәжҲ–е°Ҷж•°жҚ®еҶҷе…ҘзЈҒзӣҳзҡ„ж—¶й—ҙпјҢдёҖиҲ¬еңЁйӣ¶зӮ№еҮ жҜ«з§’пјҢзӣёеҜ№дәҺеүҚдёӨдёӘж—¶й—ҙеҸҜд»ҘеҝҪз•ҘдёҚи®ЎгҖӮйӮЈд№Ҳи®ҝй—®дёҖж¬ЎзЈҒзӣҳзҡ„ж—¶й—ҙпјҢеҚідёҖж¬ЎзЈҒзӣҳIOзҡ„ж—¶й—ҙзәҰзӯүдәҺ5+4.17 = 9msе·ҰеҸіпјҢеҗ¬иө·жқҘиҝҳжҢәдёҚй”ҷзҡ„пјҢдҪҶиҰҒзҹҘйҒ“дёҖеҸ°500 -MIPSзҡ„жңәеҷЁжҜҸз§’еҸҜд»Ҙжү§иЎҢ5дәҝжқЎжҢҮд»ӨпјҢеӣ дёәжҢҮд»Өдҫқйқ зҡ„жҳҜз”өзҡ„жҖ§иҙЁпјҢжҚўеҸҘиҜқиҜҙжү§иЎҢдёҖж¬ЎIOзҡ„ж—¶й—ҙеҸҜд»Ҙжү§иЎҢ40дёҮжқЎжҢҮд»ӨпјҢж•°жҚ®еә“еҠЁиҫ„еҚҒдёҮзҷҫдёҮд№ғиҮіеҚғдёҮзә§ж•°жҚ®пјҢжҜҸж¬Ў9жҜ«з§’зҡ„ж—¶й—ҙпјҢжҳҫ然жҳҜдёӘзҒҫйҡҫгҖӮдёӢеӣҫжҳҜи®Ўз®—жңә硬件延иҝҹзҡ„еҜ№жҜ”еӣҫпјҢдҫӣеӨ§е®¶еҸӮиҖғпјҡ

various-system-software-hardware-latencies
иҖғиҷ‘еҲ°зЈҒзӣҳIOжҳҜйқһеёёй«ҳжҳӮзҡ„ж“ҚдҪңпјҢи®Ўз®—жңәж“ҚдҪңзі»з»ҹеҒҡдәҶдёҖдәӣдјҳеҢ–пјҢеҪ“дёҖж¬ЎIOж—¶пјҢдёҚе…үжҠҠеҪ“еүҚзЈҒзӣҳең°еқҖзҡ„ж•°жҚ®пјҢиҖҢжҳҜжҠҠзӣёйӮ»зҡ„ж•°жҚ®д№ҹйғҪиҜ»еҸ–еҲ°еҶ…еӯҳзј“еҶІеҢәеҶ…пјҢеӣ дёәеұҖйғЁйў„иҜ»жҖ§еҺҹзҗҶе‘ҠиҜүжҲ‘们пјҢеҪ“и®Ўз®—жңәи®ҝй—®дёҖдёӘең°еқҖзҡ„ж•°жҚ®зҡ„ж—¶еҖҷпјҢдёҺе…¶зӣёйӮ»зҡ„ж•°жҚ®д№ҹдјҡеҫҲеҝ«иў«и®ҝй—®еҲ°гҖӮжҜҸдёҖж¬ЎIOиҜ»еҸ–зҡ„ж•°жҚ®жҲ‘们称д№ӢдёәдёҖйЎө(page)гҖӮе…·дҪ“дёҖйЎөжңүеӨҡеӨ§ж•°жҚ®и·ҹж“ҚдҪңзі»з»ҹжңүе…іпјҢдёҖиҲ¬дёә4kжҲ–8kпјҢд№ҹе°ұжҳҜжҲ‘们иҜ»еҸ–дёҖйЎөеҶ…зҡ„ж•°жҚ®ж—¶еҖҷпјҢе®һйҷ…дёҠжүҚеҸ‘з”ҹдәҶдёҖж¬ЎIOпјҢиҝҷдёӘзҗҶи®әеҜ№дәҺзҙўеј•зҡ„ж•°жҚ®з»“жһ„и®ҫи®Ўйқһеёёжңүеё®еҠ©гҖӮ
еүҚйқўи®ІдәҶз”ҹжҙ»дёӯзҙўеј•зҡ„дҫӢеӯҗпјҢзҙўеј•зҡ„еҹәжң¬еҺҹзҗҶпјҢж•°жҚ®еә“зҡ„еӨҚжқӮжҖ§пјҢеҸҲи®ІдәҶж“ҚдҪңзі»з»ҹзҡ„зӣёе…ізҹҘиҜҶпјҢзӣ®зҡ„е°ұжҳҜи®©еӨ§е®¶дәҶи§ЈпјҢд»»дҪ•дёҖз§Қж•°жҚ®з»“жһ„йғҪдёҚжҳҜеҮӯз©әдә§з”ҹзҡ„пјҢдёҖе®ҡдјҡжңүе®ғзҡ„иғҢжҷҜе’ҢдҪҝз”ЁеңәжҷҜпјҢжҲ‘们зҺ°еңЁжҖ»з»“дёҖдёӢпјҢжҲ‘们йңҖиҰҒиҝҷз§Қж•°жҚ®з»“жһ„иғҪеӨҹеҒҡдәӣд»Җд№ҲпјҢе…¶е®һеҫҲз®ҖеҚ•пјҢйӮЈе°ұжҳҜпјҡжҜҸж¬ЎжҹҘжүҫж•°жҚ®ж—¶жҠҠзЈҒзӣҳIOж¬Ўж•°жҺ§еҲ¶еңЁдёҖдёӘеҫҲе°Ҹзҡ„ж•°йҮҸзә§пјҢжңҖеҘҪжҳҜеёёж•°ж•°йҮҸзә§гҖӮйӮЈд№ҲжҲ‘们е°ұжғіеҲ°еҰӮжһңдёҖдёӘй«ҳеәҰеҸҜжҺ§зҡ„еӨҡи·Ҝжҗңзҙўж ‘жҳҜеҗҰиғҪж»Ўи¶ійңҖжұӮе‘ўпјҹе°ұиҝҷж ·пјҢb+ж ‘еә”иҝҗиҖҢз”ҹгҖӮ
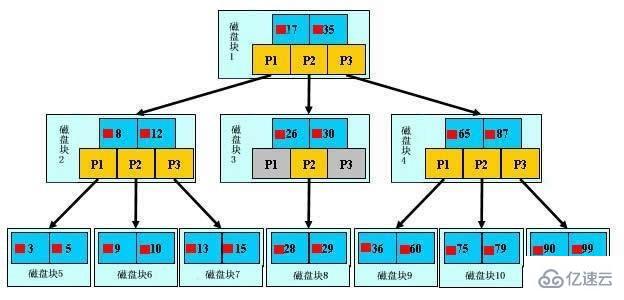
еҰӮдёҠеӣҫпјҢжҳҜдёҖйў—b+ж ‘пјҢе…ідәҺb+ж ‘зҡ„е®ҡд№үеҸҜд»ҘеҸӮи§ҒB+ж ‘пјҢиҝҷйҮҢеҸӘиҜҙдёҖдәӣйҮҚзӮ№пјҢжө…и“қиүІзҡ„еқ—жҲ‘们称д№ӢдёәдёҖдёӘзЈҒзӣҳеқ—пјҢеҸҜд»ҘзңӢеҲ°жҜҸдёӘзЈҒзӣҳеқ—еҢ…еҗ«еҮ дёӘж•°жҚ®йЎ№пјҲж·ұи“қиүІжүҖзӨәпјүе’ҢжҢҮй’ҲпјҲй»„иүІжүҖзӨәпјүпјҢеҰӮзЈҒзӣҳеқ—1еҢ…еҗ«ж•°жҚ®йЎ№17е’Ң35пјҢеҢ…еҗ«жҢҮй’ҲP1гҖҒP2гҖҒP3пјҢP1иЎЁзӨәе°ҸдәҺ17зҡ„зЈҒзӣҳеқ—пјҢP2иЎЁзӨәеңЁ17е’Ң35д№Ӣй—ҙзҡ„зЈҒзӣҳеқ—пјҢP3иЎЁзӨәеӨ§дәҺ35зҡ„зЈҒзӣҳеқ—гҖӮзңҹе®һзҡ„ж•°жҚ®еӯҳеңЁдәҺеҸ¶еӯҗиҠӮзӮ№еҚі3гҖҒ5гҖҒ9гҖҒ10гҖҒ13гҖҒ15гҖҒ28гҖҒ29гҖҒ36гҖҒ60гҖҒ75гҖҒ79гҖҒ90гҖҒ99гҖӮйқһеҸ¶еӯҗиҠӮзӮ№еҸӘдёҚеӯҳеӮЁзңҹе®һзҡ„ж•°жҚ®пјҢеҸӘеӯҳеӮЁжҢҮеј•жҗңзҙўж–№еҗ‘зҡ„ж•°жҚ®йЎ№пјҢеҰӮ17гҖҒ35并дёҚзңҹе®һеӯҳеңЁдәҺж•°жҚ®иЎЁдёӯгҖӮ
еҰӮеӣҫжүҖзӨәпјҢеҰӮжһңиҰҒжҹҘжүҫж•°жҚ®йЎ№29пјҢйӮЈд№ҲйҰ–е…ҲдјҡжҠҠзЈҒзӣҳеқ—1з”ұзЈҒзӣҳеҠ иҪҪеҲ°еҶ…еӯҳпјҢжӯӨж—¶еҸ‘з”ҹдёҖж¬ЎIOпјҢеңЁеҶ…еӯҳдёӯз”ЁдәҢеҲҶжҹҘжүҫзЎ®е®ҡ29еңЁ17е’Ң35д№Ӣй—ҙпјҢй”Ғе®ҡзЈҒзӣҳеқ—1зҡ„P2жҢҮй’ҲпјҢеҶ…еӯҳж—¶й—ҙеӣ дёәйқһеёёзҹӯпјҲзӣёжҜ”зЈҒзӣҳзҡ„IOпјүеҸҜд»ҘеҝҪз•ҘдёҚи®ЎпјҢйҖҡиҝҮзЈҒзӣҳеқ—1зҡ„P2жҢҮй’Ҳзҡ„зЈҒзӣҳең°еқҖжҠҠзЈҒзӣҳеқ—3з”ұзЈҒзӣҳеҠ иҪҪеҲ°еҶ…еӯҳпјҢеҸ‘з”ҹ第дәҢж¬ЎIOпјҢ29еңЁ26е’Ң30д№Ӣй—ҙпјҢй”Ғе®ҡзЈҒзӣҳеқ—3зҡ„P2жҢҮй’ҲпјҢйҖҡиҝҮжҢҮй’ҲеҠ иҪҪзЈҒзӣҳеқ—8еҲ°еҶ…еӯҳпјҢеҸ‘з”ҹ第дёүж¬ЎIOпјҢеҗҢж—¶еҶ…еӯҳдёӯеҒҡдәҢеҲҶжҹҘжүҫжүҫеҲ°29пјҢз»“жқҹжҹҘиҜўпјҢжҖ»и®Ўдёүж¬ЎIOгҖӮзңҹе®һзҡ„жғ…еҶөжҳҜпјҢ3еұӮзҡ„b+ж ‘еҸҜд»ҘиЎЁзӨәдёҠзҷҫдёҮзҡ„ж•°жҚ®пјҢеҰӮжһңдёҠзҷҫдёҮзҡ„ж•°жҚ®жҹҘжүҫеҸӘйңҖиҰҒдёүж¬ЎIOпјҢжҖ§иғҪжҸҗй«ҳе°ҶжҳҜе·ЁеӨ§зҡ„пјҢеҰӮжһңжІЎжңүзҙўеј•пјҢжҜҸдёӘж•°жҚ®йЎ№йғҪиҰҒеҸ‘з”ҹдёҖж¬ЎIOпјҢйӮЈд№ҲжҖ»е…ұйңҖиҰҒзҷҫдёҮж¬Ўзҡ„IOпјҢжҳҫ然жҲҗжң¬йқһеёёйқһеёёй«ҳгҖӮ
йҖҡиҝҮдёҠйқўзҡ„еҲҶжһҗпјҢжҲ‘们зҹҘйҒ“IOж¬Ўж•°еҸ–еҶідәҺb+ж•°зҡ„й«ҳеәҰhпјҢеҒҮи®ҫеҪ“еүҚж•°жҚ®иЎЁзҡ„ж•°жҚ®дёәNпјҢжҜҸдёӘзЈҒзӣҳеқ—зҡ„ж•°жҚ®йЎ№зҡ„ж•°йҮҸжҳҜmпјҢеҲҷжңүh=гҸ’(m+1)NпјҢеҪ“ж•°жҚ®йҮҸNдёҖе®ҡзҡ„жғ…еҶөдёӢпјҢmи¶ҠеӨ§пјҢhи¶Ҡе°ҸпјӣиҖҢm = зЈҒзӣҳеқ—зҡ„еӨ§е°Ҹ / ж•°жҚ®йЎ№зҡ„еӨ§е°ҸпјҢзЈҒзӣҳеқ—зҡ„еӨ§е°Ҹд№ҹе°ұжҳҜдёҖдёӘж•°жҚ®йЎөзҡ„еӨ§е°ҸпјҢжҳҜеӣәе®ҡзҡ„пјҢеҰӮжһңж•°жҚ®йЎ№еҚ зҡ„з©әй—ҙи¶Ҡе°ҸпјҢж•°жҚ®йЎ№зҡ„ж•°йҮҸи¶ҠеӨҡпјҢж ‘зҡ„й«ҳеәҰи¶ҠдҪҺгҖӮиҝҷе°ұжҳҜдёәд»Җд№ҲжҜҸдёӘж•°жҚ®йЎ№пјҢеҚізҙўеј•еӯ—ж®өиҰҒе°ҪйҮҸзҡ„е°ҸпјҢжҜ”еҰӮintеҚ 4еӯ—иҠӮпјҢиҰҒжҜ”bigint8еӯ—иҠӮе°‘дёҖеҚҠгҖӮиҝҷд№ҹжҳҜдёәд»Җд№Ҳb+ж ‘иҰҒжұӮжҠҠзңҹе®һзҡ„ж•°жҚ®ж”ҫеҲ°еҸ¶еӯҗиҠӮзӮ№иҖҢдёҚжҳҜеҶ…еұӮиҠӮзӮ№пјҢдёҖж—Ұж”ҫеҲ°еҶ…еұӮиҠӮзӮ№пјҢзЈҒзӣҳеқ—зҡ„ж•°жҚ®йЎ№дјҡеӨ§е№…еәҰдёӢйҷҚпјҢеҜјиҮҙж ‘еўһй«ҳгҖӮеҪ“ж•°жҚ®йЎ№зӯүдәҺ1ж—¶е°ҶдјҡйҖҖеҢ–жҲҗзәҝжҖ§иЎЁгҖӮ
еҪ“b+ж ‘зҡ„ж•°жҚ®йЎ№жҳҜеӨҚеҗҲзҡ„ж•°жҚ®з»“жһ„пјҢжҜ”еҰӮ(name,age,sex)зҡ„ж—¶еҖҷпјҢb+ж•°жҳҜжҢүз…§д»Һе·ҰеҲ°еҸізҡ„йЎәеәҸжқҘе»әз«Ӣжҗңзҙўж ‘зҡ„пјҢжҜ”еҰӮеҪ“(еј дёү,20,F)иҝҷж ·зҡ„ж•°жҚ®жқҘжЈҖзҙўзҡ„ж—¶еҖҷпјҢb+ж ‘дјҡдјҳе…ҲжҜ”иҫғnameжқҘзЎ®е®ҡдёӢдёҖжӯҘзҡ„жүҖжҗңж–№еҗ‘пјҢеҰӮжһңnameзӣёеҗҢеҶҚдҫқж¬ЎжҜ”иҫғageе’ҢsexпјҢжңҖеҗҺеҫ—еҲ°жЈҖзҙўзҡ„ж•°жҚ®пјӣдҪҶеҪ“(20,F)иҝҷж ·зҡ„жІЎжңүnameзҡ„ж•°жҚ®жқҘзҡ„ж—¶еҖҷпјҢb+ж ‘е°ұдёҚзҹҘйҒ“дёӢдёҖжӯҘиҜҘжҹҘе“ӘдёӘиҠӮзӮ№пјҢеӣ дёәе»әз«Ӣжҗңзҙўж ‘зҡ„ж—¶еҖҷnameе°ұжҳҜ第дёҖдёӘжҜ”иҫғеӣ еӯҗпјҢеҝ…йЎ»иҰҒе…Ҳж №жҚ®nameжқҘжҗңзҙўжүҚиғҪзҹҘйҒ“дёӢдёҖжӯҘеҺ»е“ӘйҮҢжҹҘиҜўгҖӮжҜ”еҰӮеҪ“(еј дёү,F)иҝҷж ·зҡ„ж•°жҚ®жқҘжЈҖзҙўж—¶пјҢb+ж ‘еҸҜд»Ҙз”ЁnameжқҘжҢҮе®ҡжҗңзҙўж–№еҗ‘пјҢдҪҶдёӢдёҖдёӘеӯ—ж®өageзҡ„зјәеӨұпјҢжүҖд»ҘеҸӘиғҪжҠҠеҗҚеӯ—зӯүдәҺеј дёүзҡ„ж•°жҚ®йғҪжүҫеҲ°пјҢ然еҗҺеҶҚеҢ№й…ҚжҖ§еҲ«жҳҜFзҡ„ж•°жҚ®дәҶпјҢ иҝҷдёӘжҳҜйқһеёёйҮҚиҰҒзҡ„жҖ§иҙЁпјҢеҚізҙўеј•зҡ„жңҖе·ҰеҢ№й…Қзү№жҖ§гҖӮ
е…ідәҺMySQLзҙўеј•еҺҹзҗҶжҳҜжҜ”иҫғжһҜзҮҘзҡ„дёңиҘҝпјҢеӨ§е®¶еҸӘйңҖиҰҒжңүдёҖдёӘж„ҹжҖ§зҡ„и®ӨиҜҶпјҢ并дёҚйңҖиҰҒзҗҶи§Јеҫ—йқһеёёйҖҸеҪ»е’Ңж·ұе…ҘгҖӮжҲ‘们еӣһеӨҙжқҘзңӢзңӢдёҖејҖе§ӢжҲ‘们иҜҙзҡ„ж…ўжҹҘиҜўпјҢдәҶи§Је®Ңзҙўеј•еҺҹзҗҶд№ӢеҗҺпјҢеӨ§е®¶жҳҜдёҚжҳҜжңүд»Җд№Ҳжғіжі•е‘ўпјҹе…ҲжҖ»з»“дёҖдёӢзҙўеј•зҡ„еҮ еӨ§еҹәжң¬еҺҹеҲҷпјҡ
ж №жҚ®жңҖе·ҰеҢ№й…ҚеҺҹеҲҷпјҢжңҖејҖе§Ӣзҡ„sqlиҜӯеҸҘзҡ„зҙўеј•еә”иҜҘжҳҜstatusгҖҒoperator_idгҖҒtypeгҖҒoperate_timeзҡ„иҒ”еҗҲзҙўеј•пјӣе…¶дёӯstatusгҖҒoperator_idгҖҒtypeзҡ„йЎәеәҸеҸҜд»Ҙйў еҖ’пјҢжүҖд»ҘжҲ‘жүҚдјҡиҜҙпјҢжҠҠиҝҷдёӘиЎЁзҡ„жүҖжңүзӣёе…іжҹҘиҜўйғҪжүҫеҲ°пјҢдјҡз»јеҗҲеҲҶжһҗпјӣ жҜ”еҰӮиҝҳжңүеҰӮдёӢжҹҘиҜўпјҡ
<span class="hljs-keyword">select</span> * <span class="hljs-keyword">from</span> task <span class="hljs-keyword">where</span> <span class="hljs-keyword">status</span> = <span class="hljs-number">0</span> <span class="hljs-keyword">and</span> <span class="hljs-keyword">type</span> = <span class="hljs-number">12</span> <span class="hljs-keyword">limit</span> <span class="hljs-number">10</span>;
<span class="hljs-keyword">select</span> <span class="hljs-keyword">count</span>(*) <span class="hljs-keyword">from</span> task <span class="hljs-keyword">where</span> <span class="hljs-keyword">status</span> = <span class="hljs-number">0</span> ;
йӮЈд№Ҳзҙўеј•е»әз«ӢжҲҗ(status,type,operator_id,operate_time)е°ұжҳҜйқһеёёжӯЈзЎ®зҡ„пјҢеӣ дёәеҸҜд»ҘиҰҶзӣ–еҲ°жүҖжңүжғ…еҶөгҖӮиҝҷдёӘе°ұжҳҜеҲ©з”ЁдәҶзҙўеј•зҡ„жңҖе·ҰеҢ№й…Қзҡ„еҺҹеҲҷ
е…ідәҺexplainе‘Ҫд»ӨзӣёдҝЎеӨ§е®¶е№¶дёҚйҷҢз”ҹпјҢе…·дҪ“з”Ёжі•е’Ңеӯ—ж®өеҗ«д№үеҸҜд»ҘеҸӮиҖғе®ҳзҪ‘explain-outputпјҢиҝҷйҮҢйңҖиҰҒејәи°ғrowsжҳҜж ёеҝғжҢҮж ҮпјҢз»қеӨ§йғЁеҲҶrowsе°Ҹзҡ„иҜӯеҸҘжү§иЎҢдёҖе®ҡеҫҲеҝ«пјҲжңүдҫӢеӨ–пјҢдёӢйқўдјҡи®ІеҲ°пјүгҖӮжүҖд»ҘдјҳеҢ–иҜӯеҸҘеҹәжң¬дёҠйғҪжҳҜеңЁдјҳеҢ–rowsгҖӮ
дёӢйқўеҮ дёӘдҫӢеӯҗиҜҰз»Ҷи§ЈйҮҠдәҶеҰӮдҪ•еҲҶжһҗе’ҢдјҳеҢ–ж…ўжҹҘиҜўгҖӮ
еҫҲеӨҡжғ…еҶөдёӢпјҢжҲ‘们еҶҷSQLеҸӘжҳҜдёәдәҶе®һзҺ°еҠҹиғҪпјҢиҝҷеҸӘжҳҜ第дёҖжӯҘпјҢдёҚеҗҢзҡ„иҜӯеҸҘд№ҰеҶҷж–№ејҸеҜ№дәҺж•ҲзҺҮеҫҖеҫҖжңүжң¬иҙЁзҡ„е·®еҲ«пјҢиҝҷиҰҒжұӮжҲ‘们еҜ№mysqlзҡ„жү§иЎҢи®ЎеҲ’е’Ңзҙўеј•еҺҹеҲҷжңүйқһеёёжё…жҘҡзҡ„и®ӨиҜҶпјҢиҜ·зңӢдёӢйқўзҡ„иҜӯеҸҘпјҡ
<span class="hljs-keyword">select</span>
<span class="hljs-keyword">distinct</span> cert.emp_id
<span class="hljs-keyword">from</span>
cm_log cl
<span class="hljs-keyword">inner</span> <span class="hljs-keyword">join</span>
(
<span class="hljs-keyword">select</span>
emp.id <span class="hljs-keyword">as</span> emp_id,
emp_cert.id <span class="hljs-keyword">as</span> cert_id
<span class="hljs-keyword">from</span>
employee emp
<span class="hljs-keyword">left</span> <span class="hljs-keyword">join</span>
emp_certificate emp_cert
<span class="hljs-keyword">on</span> emp.id = emp_cert.emp_id
<span class="hljs-keyword">where</span>
emp.is_deleted=<span class="hljs-number">0</span>
) cert
<span class="hljs-keyword">on</span> (
cl.ref_table=<span class="hljs-string">'Employee'</span>
<span class="hljs-keyword">and</span> cl.ref_oid= cert.emp_id
)
<span class="hljs-keyword">or</span> (
cl.ref_table=<span class="hljs-string">'EmpCertificate'</span>
<span class="hljs-keyword">and</span> cl.ref_oid= cert.cert_id
)
<span class="hljs-keyword">where</span>
cl.last_upd_date >=<span class="hljs-string">'2013-11-07 15:03:00'</span>
<span class="hljs-keyword">and</span> cl.last_upd_date<=<span class="hljs-string">'2013-11-08 16:00:00'</span>;53 rows in <span class="hljs-keyword">set</span> (<span class="hljs-number">1.87</span> sec)
+<span class="hljs-comment">----+-------------+------------+-------+---------------------------------+-----------------------+---------+-------------------+-------+--------------------------------+</span> | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +<span class="hljs-comment">----+-------------+------------+-------+---------------------------------+-----------------------+---------+-------------------+-------+--------------------------------+</span> | 1 | PRIMARY | cl | range | cm_log_cls_id,idx_last_upd_date | idx_last_upd_date | 8 | NULL | 379 | Using where; Using temporary | | 1 | PRIMARY | <derived2> | ALL | NULL | NULL | NULL | NULL | 63727 | Using where; Using join buffer | | 2 | DERIVED | emp | ALL | NULL | NULL | NULL | NULL | 13317 | Using where | | 2 | DERIVED | emp_cert | ref | emp_certificate_empid | emp_certificate_empid | 4 | meituanorg.emp.id | 1 | Using index | +<span class="hljs-comment">----+-------------+------------+-------+---------------------------------+-----------------------+---------+-------------------+-------+--------------------------------+</span>
з®Җиҝ°дёҖдёӢжү§иЎҢи®ЎеҲ’пјҢйҰ–е…Ҳmysqlж №жҚ®idx_last_upd_dateзҙўеј•жү«жҸҸcm_logиЎЁиҺ·еҫ—379жқЎи®°еҪ•пјӣ然еҗҺжҹҘиЎЁжү«жҸҸдәҶ63727жқЎи®°еҪ•пјҢеҲҶдёәдёӨйғЁеҲҶпјҢderivedиЎЁзӨәжһ„йҖ иЎЁпјҢд№ҹе°ұжҳҜдёҚеӯҳеңЁзҡ„иЎЁпјҢеҸҜд»Ҙз®ҖеҚ•зҗҶи§ЈжҲҗжҳҜдёҖдёӘиҜӯеҸҘеҪўжҲҗзҡ„з»“жһңйӣҶпјҢеҗҺйқўзҡ„ж•°еӯ—иЎЁзӨәиҜӯеҸҘзҡ„IDгҖӮderived2иЎЁзӨәзҡ„жҳҜID = 2зҡ„жҹҘиҜўжһ„йҖ дәҶиҷҡжӢҹиЎЁпјҢ并且иҝ”еӣһдәҶ63727жқЎи®°еҪ•гҖӮжҲ‘们еҶҚжқҘзңӢзңӢID = 2зҡ„иҜӯеҸҘ究з«ҹеҒҡдәҶеҶҷд»Җд№Ҳиҝ”еӣһдәҶиҝҷд№ҲеӨ§йҮҸзҡ„ж•°жҚ®пјҢйҰ–е…Ҳе…ЁиЎЁжү«жҸҸemployeeиЎЁ13317жқЎи®°еҪ•пјҢ然еҗҺж №жҚ®зҙўеј•emp_certificate_empidе…іиҒ”emp_certificateиЎЁпјҢrows = 1иЎЁзӨәпјҢжҜҸдёӘе…іиҒ”йғҪеҸӘй”Ғе®ҡдәҶдёҖжқЎи®°еҪ•пјҢж•ҲзҺҮжҜ”иҫғй«ҳгҖӮиҺ·еҫ—еҗҺпјҢеҶҚе’Ңcm_logзҡ„379жқЎи®°еҪ•ж №жҚ®и§„еҲҷе…іиҒ”гҖӮд»Һжү§иЎҢиҝҮзЁӢдёҠеҸҜд»ҘзңӢеҮәиҝ”еӣһдәҶеӨӘеӨҡзҡ„ж•°жҚ®пјҢиҝ”еӣһзҡ„ж•°жҚ®з»қеӨ§йғЁеҲҶcm_logйғҪз”ЁдёҚеҲ°пјҢеӣ дёәcm_logеҸӘй”Ғе®ҡдәҶ379жқЎи®°еҪ•гҖӮ
еҰӮдҪ•дјҳеҢ–е‘ўпјҹеҸҜд»ҘзңӢеҲ°жҲ‘们еңЁиҝҗиЎҢе®ҢеҗҺиҝҳжҳҜиҰҒе’Ңcm_logеҒҡjoin,йӮЈд№ҲжҲ‘们иғҪдёҚиғҪд№ӢеүҚе’Ңcm_logеҒҡjoinе‘ўпјҹд»”з»ҶеҲҶжһҗиҜӯеҸҘдёҚйҡҫеҸ‘зҺ°пјҢе…¶еҹәжң¬жҖқжғіжҳҜеҰӮжһңcm_logзҡ„ref_tableжҳҜEmpCertificateе°ұе…іиҒ”emp_certificateиЎЁпјҢеҰӮжһңref_tableжҳҜEmployeeе°ұе…іиҒ”employeeиЎЁпјҢжҲ‘们е®Ңе…ЁеҸҜд»ҘжӢҶжҲҗдёӨйғЁеҲҶпјҢ并用unionиҝһжҺҘиө·жқҘпјҢжіЁж„ҸиҝҷйҮҢз”ЁunionпјҢиҖҢдёҚз”Ёunion allжҳҜеӣ дёәеҺҹиҜӯеҸҘжңүвҖңdistinctвҖқжқҘеҫ—еҲ°е”ҜдёҖзҡ„и®°еҪ•пјҢиҖҢunionжҒ°еҘҪе…·еӨҮдәҶиҝҷз§ҚеҠҹиғҪгҖӮеҰӮжһңеҺҹиҜӯеҸҘдёӯжІЎжңүdistinctдёҚйңҖиҰҒеҺ»йҮҚпјҢжҲ‘们е°ұеҸҜд»ҘзӣҙжҺҘдҪҝз”Ёunion allдәҶпјҢеӣ дёәдҪҝз”ЁunionйңҖиҰҒеҺ»йҮҚзҡ„еҠЁдҪңпјҢдјҡеҪұе“ҚSQLжҖ§иғҪгҖӮ
дјҳеҢ–иҝҮзҡ„иҜӯеҸҘеҰӮдёӢпјҡ
<span class="hljs-keyword">select</span>
emp.id
<span class="hljs-keyword">from</span>
cm_log cl
<span class="hljs-keyword">inner</span> <span class="hljs-keyword">join</span>
employee emp
<span class="hljs-keyword">on</span> cl.ref_table = <span class="hljs-string">'Employee'</span>
<span class="hljs-keyword">and</span> cl.ref_oid = emp.id
<span class="hljs-keyword">where</span>
cl.last_upd_date >=<span class="hljs-string">'2013-11-07 15:03:00'</span>
<span class="hljs-keyword">and</span> cl.last_upd_date<=<span class="hljs-string">'2013-11-08 16:00:00'</span>
<span class="hljs-keyword">and</span> emp.is_deleted = <span class="hljs-number">0</span>
<span class="hljs-keyword">union</span>
<span class="hljs-keyword">select</span>
emp.id
<span class="hljs-keyword">from</span>
cm_log cl
<span class="hljs-keyword">inner</span> <span class="hljs-keyword">join</span>
emp_certificate ec
<span class="hljs-keyword">on</span> cl.ref_table = <span class="hljs-string">'EmpCertificate'</span>
<span class="hljs-keyword">and</span> cl.ref_oid = ec.id
<span class="hljs-keyword">inner</span> <span class="hljs-keyword">join</span>
employee emp
<span class="hljs-keyword">on</span> emp.id = ec.emp_id
<span class="hljs-keyword">where</span>
cl.last_upd_date >=<span class="hljs-string">'2013-11-07 15:03:00'</span>
<span class="hljs-keyword">and</span> cl.last_upd_date<=<span class="hljs-string">'2013-11-08 16:00:00'</span>
<span class="hljs-keyword">and</span> emp.is_deleted = <span class="hljs-number">0</span>дёҚйңҖиҰҒдәҶи§ЈдёҡеҠЎеңәжҷҜпјҢеҸӘйңҖиҰҒж”№йҖ зҡ„иҜӯеҸҘе’Ңж”№йҖ д№ӢеүҚзҡ„иҜӯеҸҘдҝқжҢҒз»“жһңдёҖиҮҙ
зҺ°жңүзҙўеј•еҸҜд»Ҙж»Ўи¶іпјҢдёҚйңҖиҰҒе»әзҙўеј•
з”Ёж”№йҖ еҗҺзҡ„иҜӯеҸҘе®һйӘҢдёҖдёӢпјҢеҸӘйңҖиҰҒ10ms йҷҚдҪҺдәҶиҝ‘200еҖҚпјҒ
+<span class="hljs-comment">----+--------------+------------+--------+---------------------------------+-------------------+---------+-----------------------+------+-------------+</span> | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +<span class="hljs-comment">----+--------------+------------+--------+---------------------------------+-------------------+---------+-----------------------+------+-------------+</span> | 1 | PRIMARY | cl | range | cm_log_cls_id,idx_last_upd_date | idx_last_upd_date | 8 | NULL | 379 | Using where | | 1 | PRIMARY | emp | eq_ref | PRIMARY | PRIMARY | 4 | meituanorg.cl.ref_oid | 1 | Using where | | 2 | UNION | cl | range | cm_log_cls_id,idx_last_upd_date | idx_last_upd_date | 8 | NULL | 379 | Using where | | 2 | UNION | ec | eq_ref | PRIMARY,emp_certificate_empid | PRIMARY | 4 | meituanorg.cl.ref_oid | 1 | | | 2 | UNION | emp | eq_ref | PRIMARY | PRIMARY | 4 | meituanorg.ec.emp_id | 1 | Using where | | NULL | UNION RESULT | <union1,2> | ALL | NULL | NULL | NULL | NULL | NULL | | +<span class="hljs-comment">----+--------------+------------+--------+---------------------------------+-------------------+---------+-----------------------+------+-------------+</span> 53 rows in <span class="hljs-keyword">set</span> (<span class="hljs-number">0.01</span> sec)
дёҫиҝҷдёӘдҫӢеӯҗзҡ„зӣ®зҡ„еңЁдәҺйў иҰҶжҲ‘们еҜ№еҲ—зҡ„еҢәеҲҶеәҰзҡ„и®ӨзҹҘпјҢдёҖиҲ¬дёҠжҲ‘们и®ӨдёәеҢәеҲҶеәҰи¶Ҡй«ҳзҡ„еҲ—пјҢи¶Ҡе®№жҳ“й”Ғе®ҡжӣҙе°‘зҡ„и®°еҪ•пјҢдҪҶеңЁдёҖдәӣзү№ж®Ҡзҡ„жғ…еҶөдёӢпјҢиҝҷз§ҚзҗҶи®әжҳҜжңүеұҖйҷҗжҖ§зҡ„гҖӮ
<span class="hljs-keyword">select</span>
*
<span class="hljs-keyword">from</span>
stage_poi sp
<span class="hljs-keyword">where</span>
sp.accurate_result=<span class="hljs-number">1</span>
<span class="hljs-keyword">and</span> (
sp.sync_status=<span class="hljs-number">0</span>
<span class="hljs-keyword">or</span> sp.sync_status=<span class="hljs-number">2</span>
<span class="hljs-keyword">or</span> sp.sync_status=<span class="hljs-number">4</span>
);е…ҲзңӢзңӢиҝҗиЎҢеӨҡй•ҝж—¶й—ҙ,951жқЎж•°жҚ®6.22з§’пјҢзңҹзҡ„еҫҲж…ўгҖӮ
951 rows in <span class="hljs-keyword">set</span> (<span class="hljs-number">6.22</span> sec)
е…ҲexplainпјҢrowsиҫҫеҲ°дәҶ361дёҮпјҢtype = ALLиЎЁжҳҺжҳҜе…ЁиЎЁжү«жҸҸгҖӮ
+<span class="hljs-comment">----+-------------+-------+------+---------------+------+---------+------+---------+-------------+</span> | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +<span class="hljs-comment">----+-------------+-------+------+---------------+------+---------+------+---------+-------------+</span> | 1 | SIMPLE | sp | ALL | NULL | NULL | NULL | NULL | 3613155 | Using where | +<span class="hljs-comment">----+-------------+-------+------+---------------+------+---------+------+---------+-------------+</span>
жүҖжңүеӯ—ж®өйғҪеә”з”ЁжҹҘиҜўиҝ”еӣһи®°еҪ•ж•°пјҢеӣ дёәжҳҜеҚ•иЎЁжҹҘиҜў 0е·Із»ҸеҒҡиҝҮдәҶ951жқЎгҖӮ
и®©explainзҡ„rows е°ҪйҮҸйҖјиҝ‘951гҖӮ
зңӢдёҖдёӢaccurate_result = 1зҡ„и®°еҪ•ж•°пјҡ
<span class="hljs-keyword">select</span> <span class="hljs-keyword">count</span>(*),accurate_result <span class="hljs-keyword">from</span> stage_poi <span class="hljs-keyword">group</span> <span class="hljs-keyword">by</span> accurate_result; +<span class="hljs-comment">----------+-----------------+</span> | count(*) | accurate_result | +<span class="hljs-comment">----------+-----------------+</span> | 1023 | -1 | | 2114655 | 0 | | 972815 | 1 | +<span class="hljs-comment">----------+-----------------+</span>
жҲ‘们зңӢеҲ°accurate_resultиҝҷдёӘеӯ—ж®өзҡ„еҢәеҲҶеәҰйқһеёёдҪҺпјҢж•ҙдёӘиЎЁеҸӘжңү-1,0,1дёүдёӘеҖјпјҢеҠ дёҠзҙўеј•д№ҹж— жі•й”Ғе®ҡзү№еҲ«е°‘йҮҸзҡ„ж•°жҚ®гҖӮ
еҶҚзңӢдёҖдёӢsync_statusеӯ—ж®өзҡ„жғ…еҶөпјҡ
<span class="hljs-keyword">select</span> <span class="hljs-keyword">count</span>(*),sync_status <span class="hljs-keyword">from</span> stage_poi <span class="hljs-keyword">group</span> <span class="hljs-keyword">by</span> sync_status; +<span class="hljs-comment">----------+-------------+</span> | count(*) | sync_status | +<span class="hljs-comment">----------+-------------+</span> | 3080 | 0 | | 3085413 | 3 | +<span class="hljs-comment">----------+-------------+</span>
еҗҢж ·зҡ„еҢәеҲҶеәҰд№ҹеҫҲдҪҺпјҢж №жҚ®зҗҶи®әпјҢд№ҹдёҚйҖӮеҗҲе»әз«Ӣзҙўеј•гҖӮ
й—®йўҳеҲҶжһҗеҲ°иҝҷпјҢеҘҪеғҸеҫ—еҮәдәҶиҝҷдёӘиЎЁж— жі•дјҳеҢ–зҡ„з»“и®әпјҢдёӨдёӘеҲ—зҡ„еҢәеҲҶеәҰйғҪеҫҲдҪҺпјҢеҚідҫҝеҠ дёҠзҙўеј•д№ҹеҸӘиғҪйҖӮеә”иҝҷз§Қжғ…еҶөпјҢеҫҲйҡҫеҒҡжҷ®йҒҚжҖ§зҡ„дјҳеҢ–пјҢжҜ”еҰӮеҪ“sync_status 0гҖҒ3еҲҶеёғзҡ„еҫҲе№іеқҮпјҢйӮЈд№Ҳй”Ғе®ҡи®°еҪ•д№ҹжҳҜзҷҫдёҮзә§еҲ«зҡ„гҖӮ
жүҫдёҡеҠЎж–№еҺ»жІҹйҖҡпјҢзңӢзңӢдҪҝз”ЁеңәжҷҜгҖӮдёҡеҠЎж–№жҳҜиҝҷд№ҲжқҘдҪҝз”ЁиҝҷдёӘSQLиҜӯеҸҘзҡ„пјҢжҜҸйҡ”дә”еҲҶй’ҹдјҡжү«жҸҸз¬ҰеҗҲжқЎд»¶зҡ„ж•°жҚ®пјҢеӨ„зҗҶе®ҢжҲҗеҗҺжҠҠsync_statusиҝҷдёӘеӯ—ж®өеҸҳжҲҗ1,дә”еҲҶй’ҹз¬ҰеҗҲжқЎд»¶зҡ„и®°еҪ•ж•°е№¶дёҚдјҡеӨӘеӨҡпјҢ1000дёӘе·ҰеҸігҖӮдәҶи§ЈдәҶдёҡеҠЎж–№зҡ„дҪҝз”ЁеңәжҷҜеҗҺпјҢдјҳеҢ–иҝҷдёӘSQLе°ұеҸҳеҫ—з®ҖеҚ•дәҶпјҢеӣ дёәдёҡеҠЎж–№дҝқиҜҒдәҶж•°жҚ®зҡ„дёҚе№іиЎЎпјҢеҰӮжһңеҠ дёҠзҙўеј•еҸҜд»ҘиҝҮж»ӨжҺүз»қеӨ§йғЁеҲҶдёҚйңҖиҰҒзҡ„ж•°жҚ®гҖӮ
ж №жҚ®е»әз«Ӣзҙўеј•и§„еҲҷпјҢдҪҝз”ЁеҰӮдёӢиҜӯеҸҘе»әз«Ӣзҙўеј•
<span class="hljs-keyword">alter</span> <span class="hljs-keyword">table</span> stage_poi <span class="hljs-keyword">add</span> <span class="hljs-keyword">index</span> idx_acc_status(accurate_result,sync_status);
и§ӮеҜҹйў„жңҹз»“жһң,еҸ‘зҺ°еҸӘйңҖиҰҒ200msпјҢеҝ«дәҶ30еӨҡеҖҚгҖӮ
952 rows in <span class="hljs-keyword">set</span> (<span class="hljs-number">0.20</span> sec)
жҲ‘们еҶҚжқҘеӣһйЎҫдёҖдёӢеҲҶжһҗй—®йўҳзҡ„иҝҮзЁӢпјҢеҚ•иЎЁжҹҘиҜўзӣёеҜ№жқҘиҜҙжҜ”иҫғеҘҪдјҳеҢ–пјҢеӨ§йғЁеҲҶж—¶еҖҷеҸӘйңҖиҰҒжҠҠwhereжқЎд»¶йҮҢйқўзҡ„еӯ—ж®өдҫқ照规еҲҷеҠ дёҠзҙўеј•е°ұеҘҪпјҢеҰӮжһңеҸӘжҳҜиҝҷз§ҚвҖңж— и„‘вҖқдјҳеҢ–зҡ„иҜқпјҢжҳҫ然дёҖдәӣеҢәеҲҶеәҰйқһеёёдҪҺзҡ„еҲ—пјҢдёҚеә”иҜҘеҠ зҙўеј•зҡ„еҲ—д№ҹдјҡиў«еҠ дёҠзҙўеј•пјҢиҝҷж ·дјҡеҜ№жҸ’е…ҘгҖҒжӣҙж–°жҖ§иғҪйҖ жҲҗдёҘйҮҚзҡ„еҪұе“ҚпјҢеҗҢж—¶д№ҹжңүеҸҜиғҪеҪұе“Қе…¶е®ғзҡ„жҹҘиҜўиҜӯеҸҘгҖӮжүҖд»ҘжҲ‘们第4жӯҘи°ғе·®SQLзҡ„дҪҝз”ЁеңәжҷҜйқһеёёе…ій”®пјҢжҲ‘们еҸӘжңүзҹҘйҒ“иҝҷдёӘдёҡеҠЎеңәжҷҜпјҢжүҚиғҪжӣҙеҘҪең°иҫ…еҠ©жҲ‘们жӣҙеҘҪзҡ„еҲҶжһҗе’ҢдјҳеҢ–жҹҘиҜўиҜӯеҸҘгҖӮ
<span class="hljs-keyword">select</span>
c.id,
c.name,
c.position,
c.sex,
c.phone,
c.office_phone,
c.feature_info,
c.birthday,
c.creator_id,
c.is_keyperson,
c.giveup_reason,
c.status,
c.data_source,
from_unixtime(c.created_time) <span class="hljs-keyword">as</span> created_time,
from_unixtime(c.last_modified) <span class="hljs-keyword">as</span> last_modified,
c.last_modified_user_id
<span class="hljs-keyword">from</span>
contact c
<span class="hljs-keyword">inner</span> <span class="hljs-keyword">join</span>
contact_branch cb
<span class="hljs-keyword">on</span> c.id = cb.contact_id
<span class="hljs-keyword">inner</span> <span class="hljs-keyword">join</span>
branch_user bu
<span class="hljs-keyword">on</span> cb.branch_id = bu.branch_id
<span class="hljs-keyword">and</span> bu.status <span class="hljs-keyword">in</span> (
<span class="hljs-number">1</span>,
<span class="hljs-number">2</span>)
<span class="hljs-keyword">inner</span> <span class="hljs-keyword">join</span>
org_emp_info oei
<span class="hljs-keyword">on</span> oei.data_id = bu.user_id
<span class="hljs-keyword">and</span> oei.node_left >= <span class="hljs-number">2875</span>
<span class="hljs-keyword">and&llt;/span> oei.node_right <= <span class="hljs-number">10802</span>
<span class="hljs-keyword">and</span> oei.org_category = - <span class="hljs-number">1</span>
<span class="hljs-keyword">order</span> <span class="hljs-keyword">by</span>
c.created_time <span class="hljs-keyword">desc</span> <span class="hljs-keyword">limit</span> <span class="hljs-number">0</span> ,
<span class="hljs-number">10</span>;иҝҳжҳҜеҮ дёӘжӯҘйӘӨгҖӮ
10 rows in <span class="hljs-keyword">set</span> (<span class="hljs-number">13.06</span> sec)
+<span class="hljs-comment">----+-------------+-------+--------+-------------------------------------+-------------------------+---------+--------------------------+------+----------------------------------------------+</span> | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +<span class="hljs-comment">----+-------------+-------+--------+-------------------------------------+-------------------------+---------+--------------------------+------+----------------------------------------------+</span> | 1 | SIMPLE | oei | ref | idx_category_left_right,idx_data_id | idx_category_left_right | 5 | const | 8849 | Using where; Using temporary; Using filesort | | 1 | SIMPLE | bu | ref | PRIMARY,idx_userid_status | idx_userid_status | 4 | meituancrm.oei.data_id | 76 | Using where; Using index | | 1 | SIMPLE | cb | ref | idx_branch_id,idx_contact_branch_id | idx_branch_id | 4 | meituancrm.bu.branch_id | 1 | | | 1 | SIMPLE | c | eq_ref | PRIMARY | PRIMARY | 108 | meituancrm.cb.contact_id | 1 | | +<span class="hljs-comment">----+-------------+-------+--------+-------------------------------------+-------------------------+---------+--------------------------+------+----------------------------------------------+</span>
д»Һжү§иЎҢи®ЎеҲ’дёҠзңӢпјҢmysqlе…ҲжҹҘorg_emp_infoиЎЁжү«жҸҸ8849и®°еҪ•пјҢеҶҚз”Ёзҙўеј•idx_userid_statusе…іиҒ”branch_userиЎЁпјҢеҶҚз”Ёзҙўеј•idx_branch_idе…іиҒ”contact_branchиЎЁпјҢжңҖеҗҺдё»й”®е…іиҒ”contactиЎЁгҖӮ
rowsиҝ”еӣһзҡ„йғҪйқһеёёе°‘пјҢзңӢдёҚеҲ°жңүд»Җд№ҲејӮеёёжғ…еҶөгҖӮжҲ‘们еңЁзңӢдёҖдёӢиҜӯеҸҘпјҢеҸ‘зҺ°еҗҺйқўжңүorder by + limitз»„еҗҲпјҢдјҡдёҚдјҡжҳҜжҺ’еәҸйҮҸеӨӘеӨ§жҗһзҡ„пјҹдәҺжҳҜжҲ‘们з®ҖеҢ–SQLпјҢеҺ»жҺүеҗҺйқўзҡ„order by е’Ң limitпјҢзңӢзңӢеҲ°еә•з”ЁдәҶеӨҡе°‘и®°еҪ•жқҘжҺ’еәҸгҖӮ
<span class="hljs-keyword">select</span>
<span class="hljs-keyword">count</span>(*)
<span class="hljs-keyword">from</span>
contact c
<span class="hljs-keyword">inner</span> <span class="hljs-keyword">join</span>
contact_branch cb
<span class="hljs-keyword">on</span> c.id = cb.contact_id
<span class="hljs-keyword">inner</span> <span class="hljs-keyword">join</span>
branch_user bu
<span class="hljs-keyword">on</span> cb.branch_id = bu.branch_id
<span class="hljs-keyword">and</span> bu.status <span class="hljs-keyword">in</span> (
<span class="hljs-number">1</span>,
<span class="hljs-number">2</span>)
<span class="hljs-keyword">inner</span> <span class="hljs-keyword">join</span>
org_emp_info oei
<span class="hljs-keyword">on</span> oei.data_id = bu.user_id
<span class="hljs-keyword">and</span> oei.node_left >= <span class="hljs-number">2875</span>
<span class="hljs-keyword">and</span> oei.node_right <= <span class="hljs-number">10802</span>
<span class="hljs-keyword">and</span> oei.org_category = - <span class="hljs-number">1</span>
+<span class="hljs-comment">----------+</span>
| <span class="hljs-keyword">count</span>(*) |
+<span class="hljs-comment">----------+</span>
| <span class="hljs-number">778878</span> |
+<span class="hljs-comment">----------+</span>
<span class="hljs-number">1</span> <span class="hljs-keyword">row</span> <span class="hljs-keyword">in</span> <span class="hljs-keyword">set</span> (<span class="hljs-number">5.19</span> sec)еҸ‘зҺ°жҺ’еәҸд№ӢеүҚеұ…然й”Ғе®ҡдәҶ778878жқЎи®°еҪ•пјҢеҰӮжһңй’ҲеҜ№70дёҮзҡ„з»“жһңйӣҶжҺ’еәҸпјҢе°ҶжҳҜзҒҫйҡҫжҖ§зҡ„пјҢжҖӘдёҚеҫ—иҝҷд№Ҳж…ўпјҢйӮЈжҲ‘们иғҪдёҚиғҪжҚўдёӘжҖқи·ҜпјҢе…Ҳж №жҚ®contactзҡ„created_timeжҺ’еәҸпјҢеҶҚжқҘjoinдјҡдёҚдјҡжҜ”иҫғеҝ«е‘ўпјҹ
дәҺжҳҜж”№йҖ жҲҗдёӢйқўзҡ„иҜӯеҸҘпјҢд№ҹеҸҜд»Ҙз”Ёstraight_joinжқҘдјҳеҢ–пјҡ
select c.id, c.name, c.position, c.sex, c.phone, c.office_phone, c.feature_info, c.birthday, c.creator_id, c.is_keyperson, c.giveup_reason, c.status, c.data_source, from_unixtime(c.created_time) as created_time, from_unixtime(c.last_modified) as last_modified, c.last_modified_user_id from contact c where exists ( select 1 from contact_branch cb inner join branch_user bu on cb.branch_id = bu.branch_id and bu.status in ( 1, 2) inner join org_emp_info oei on oei.data_id = bu.user_id and oei.node_left >= 2875 and oei.node_right <= 10802 and oei.org_category = вҖ“ 1 where c.id = cb.contact_id ) order by c.created_time desc limit 0 , 10;
йӘҢиҜҒдёҖдёӢж•Ҳжһң йў„и®ЎеңЁ
<span class="hljs-number">1</span>msеҶ…пјҢжҸҗеҚҮдәҶ<span class="hljs-number">13000</span>еӨҡеҖҚпјҒ sql <span class="hljs-number">10</span> rows <span class="hljs-keyword">in</span> <span class="hljs-keyword">set</span> (<span class="hljs-number">0.00</span> sec)
жң¬д»ҘдёәиҮіжӯӨеӨ§е·Ҙе‘ҠжҲҗпјҢдҪҶжҲ‘们еңЁеүҚйқўзҡ„еҲҶжһҗдёӯжјҸдәҶдёҖдёӘз»ҶиҠӮпјҢе…ҲжҺ’еәҸеҶҚjoinе’Ңе…ҲjoinеҶҚжҺ’еәҸзҗҶи®әдёҠејҖй”ҖжҳҜдёҖж ·зҡ„пјҢдёәдҪ•жҸҗеҚҮиҝҷд№ҲеӨҡжҳҜеӣ дёәжңүдёҖдёӘlimitпјҒеӨ§иҮҙжү§иЎҢиҝҮзЁӢжҳҜпјҡmysqlе…ҲжҢүзҙўеј•жҺ’еәҸеҫ—еҲ°еүҚ10жқЎи®°еҪ•пјҢ然еҗҺеҶҚеҺ»joinиҝҮж»ӨпјҢеҪ“еҸ‘зҺ°дёҚеӨҹ10жқЎзҡ„ж—¶еҖҷпјҢеҶҚж¬ЎеҺ»10жқЎпјҢеҶҚж¬ЎjoinпјҢиҝҷжҳҫ然еңЁеҶ…еұӮjoinиҝҮж»Өзҡ„ж•°жҚ®йқһеёёеӨҡзҡ„ж—¶еҖҷпјҢе°ҶжҳҜзҒҫйҡҫзҡ„пјҢжһҒз«Ҝжғ…еҶөпјҢеҶ…еұӮдёҖжқЎж•°жҚ®йғҪжүҫдёҚеҲ°пјҢmysqlиҝҳеӮ»д№Һд№Һзҡ„жҜҸж¬ЎеҸ–10жқЎпјҢеҮ д№ҺйҒҚеҺҶдәҶиҝҷдёӘж•°жҚ®иЎЁпјҒ
з”ЁдёҚеҗҢеҸӮж•°зҡ„SQLиҜ•йӘҢдёӢпјҡ
<span class="hljs-keyword">select</span>
sql_no_cache c.id,
c.name,
c.position,
c.sex,
c.phone,
c.office_phone,
c.feature_info,
c.birthday,
c.creator_id,
c.is_keyperson,
c.giveup_reason,
c.status,
c.data_source,
from_unixtime(c.created_time) <span class="hljs-keyword">as</span> created_time,
from_unixtime(c.last_modified) <span class="hljs-keyword">as</span> last_modified,
c.last_modified_user_id
<span class="hljs-keyword">from</span>
contact c
<span class="hljs-keyword">where</span>
<span class="hljs-keyword">exists</span> (
<span class="hljs-keyword">select</span>
<span class="hljs-number">1</span>
<span class="hljs-keyword">from</span>
contact_branch cb
<span class="hljs-keyword">inner</span> <span class="hljs-keyword">join</span>
branch_user bu
<span class="hljs-keyword">on</span> cb.branch_id = bu.branch_id
<span class="hljs-keyword">and</span> bu.status <span class="hljs-keyword">in</span> (
<span class="hljs-number">1</span>,
<span class="hljs-number">2</span>)
<span class="hljs-keyword">inner</span> <span class="hljs-keyword">join</span>
org_emp_info oei
<span class="hljs-keyword">on</span> oei.data_id = bu.user_id
<span class="hljs-keyword">and</span> oei.node_left >= <span class="hljs-number">2875</span>
<span class="hljs-keyword">and</span> oei.node_right <= <span class="hljs-number">2875</span>
<span class="hljs-keyword">and</span> oei.org_category = - <span class="hljs-number">1</span>
<span class="hljs-keyword">where</span>
c.id = cb.contact_id
)
<span class="hljs-keyword">order</span> <span class="hljs-keyword">by</span>
c.created_time <span class="hljs-keyword">desc</span> <span class="hljs-keyword">limit</span> <span class="hljs-number">0</span> ,
<span class="hljs-number">10</span>;
Empty <span class="hljs-keyword">set</span> (<span class="hljs-number">2</span> <span class="hljs-keyword">min</span> <span class="hljs-number">18.99</span> sec)2 min 18.99 secпјҒжҜ”д№ӢеүҚзҡ„жғ…еҶөиҝҳзіҹзі•еҫҲеӨҡгҖӮз”ұдәҺmysqlзҡ„nested loopжңәеҲ¶пјҢйҒҮеҲ°иҝҷз§Қжғ…еҶөпјҢеҹәжң¬жҳҜж— жі•дјҳеҢ–зҡ„гҖӮиҝҷжқЎиҜӯеҸҘжңҖз»Ҳд№ҹеҸӘиғҪдәӨз»ҷеә”з”Ёзі»з»ҹеҺ»дјҳеҢ–иҮӘе·ұзҡ„йҖ»иҫ‘дәҶгҖӮ йҖҡиҝҮиҝҷдёӘдҫӢеӯҗжҲ‘们еҸҜд»ҘзңӢеҲ°пјҢ并дёҚжҳҜжүҖжңүиҜӯеҸҘйғҪиғҪдјҳеҢ–пјҢиҖҢеҫҖеҫҖжҲ‘们дјҳеҢ–ж—¶пјҢз”ұдәҺSQLз”ЁдҫӢеӣһеҪ’ж—¶иҗҪжҺүдёҖдәӣжһҒз«Ҝжғ…еҶөпјҢдјҡйҖ жҲҗжҜ”еҺҹжқҘиҝҳдёҘйҮҚзҡ„еҗҺжһңгҖӮжүҖд»ҘпјҢ第дёҖпјҡдёҚиҰҒжҢҮжңӣжүҖжңүиҜӯеҸҘйғҪиғҪйҖҡиҝҮSQLдјҳеҢ–пјҢ第дәҢпјҡдёҚиҰҒиҝҮдәҺиҮӘдҝЎпјҢеҸӘй’ҲеҜ№е…·дҪ“caseжқҘдјҳеҢ–пјҢиҖҢеҝҪз•ҘдәҶжӣҙеӨҚжқӮзҡ„жғ…еҶөгҖӮ
ж…ўжҹҘиҜўзҡ„жЎҲдҫӢе°ұеҲҶжһҗеҲ°иҝҷе„ҝпјҢд»ҘдёҠеҸӘжҳҜдёҖдәӣжҜ”иҫғе…ёеһӢзҡ„жЎҲдҫӢгҖӮжҲ‘们еңЁдјҳеҢ–иҝҮзЁӢдёӯйҒҮеҲ°иҝҮи¶…иҝҮ1000иЎҢпјҢж¶үеҸҠеҲ°16дёӘиЎЁjoinзҡ„вҖңеһғеңҫSQLвҖқпјҢд№ҹйҒҮеҲ°иҝҮзәҝдёҠзәҝдёӢж•°жҚ®еә“е·®ејӮеҜјиҮҙеә”з”ЁзӣҙжҺҘиў«ж…ўжҹҘиҜўжӢ–жӯ»пјҢд№ҹйҒҮеҲ°иҝҮvarcharзӯүеҖјжҜ”иҫғжІЎжңүеҶҷеҚ•еј•еҸ·пјҢиҝҳйҒҮеҲ°иҝҮз¬ӣеҚЎе°”з§ҜжҹҘиҜўзӣҙжҺҘжҠҠд»Һеә“жҗһжӯ»гҖӮеҶҚеӨҡзҡ„жЎҲдҫӢе…¶е®һд№ҹеҸӘжҳҜдёҖдәӣз»ҸйӘҢзҡ„з§ҜзҙҜпјҢеҰӮжһңжҲ‘们зҶҹжӮүжҹҘиҜўдјҳеҢ–еҷЁгҖҒзҙўеј•зҡ„еҶ…йғЁеҺҹзҗҶпјҢйӮЈд№ҲеҲҶжһҗиҝҷдәӣжЎҲдҫӢе°ұеҸҳеҫ—зү№еҲ«з®ҖеҚ•дәҶгҖӮ
жң¬ж–Үд»ҘдёҖдёӘж…ўжҹҘиҜўжЎҲдҫӢеј•е…ҘдәҶMySQLзҙўеј•еҺҹзҗҶгҖҒдјҳеҢ–ж…ўжҹҘиҜўзҡ„дёҖдәӣж–№жі•и®ә;并й’ҲеҜ№йҒҮеҲ°зҡ„е…ёеһӢжЎҲдҫӢеҒҡдәҶиҜҰз»Ҷзҡ„еҲҶжһҗгҖӮе…¶е®һеҒҡдәҶиҝҷд№Ҳй•ҝж—¶й—ҙзҡ„иҜӯеҸҘдјҳеҢ–еҗҺжүҚеҸ‘зҺ°пјҢд»»дҪ•ж•°жҚ®еә“еұӮйқўзҡ„дјҳеҢ–йғҪжҠөдёҚдёҠеә”з”Ёзі»з»ҹзҡ„дјҳеҢ–пјҢеҗҢж ·жҳҜMySQLпјҢеҸҜд»Ҙз”ЁжқҘж”Ҝж’‘Google/FaceBook/Taobaoеә”з”ЁпјҢдҪҶеҸҜиғҪиҝһдҪ зҡ„дёӘдәәзҪ‘з«ҷйғҪж’‘дёҚдҪҸгҖӮеҘ—з”ЁжңҖиҝ‘жҜ”иҫғжөҒиЎҢзҡ„иҜқпјҡвҖңжҹҘиҜўе®№жҳ“пјҢдјҳеҢ–дёҚжҳ“пјҢдё”еҶҷдё”зҸҚжғңпјҒвҖқ
зңӢе®Ңд»Җд№ҲжҳҜMySQLзҙўеј•еҺҹзҗҶеҸҠдјҳеҢ–зҡ„еҹәжң¬жӯҘйӘӨиҝҷзҜҮж–Үз« пјҢеӨ§е®¶и§үеҫ—жҖҺд№Ҳж ·пјҹеҰӮжһңжғіиҰҒдәҶи§ЈжӣҙеӨҡзӣёе…іпјҢеҸҜд»Ҙ继з»ӯе…іжіЁжҲ‘们зҡ„иЎҢдёҡиө„и®Ҝжқҝеқ—гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ