жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬ж–Үдё»иҰҒз»ҷеӨ§е®¶д»Ӣз»ҚMySQLзҙўеј•е’ҢжҹҘиҜўдјҳеҢ–иҜҰжһҗпјҢж–Үз« еҶ…е®№йғҪжҳҜ笔иҖ…з”Ёеҝғж‘ҳйҖүе’Ңзј–иҫ‘зҡ„пјҢе…·жңүдёҖе®ҡзҡ„й’ҲеҜ№жҖ§пјҢеҜ№еӨ§е®¶зҡ„еҸӮиҖғж„Ҹд№үиҝҳжҳҜжҜ”иҫғеӨ§зҡ„пјҢдёӢйқўи·ҹ笔иҖ…дёҖиө·дәҶи§ЈдёӢдё»йўҳеҶ…е®№еҗ§гҖӮ
дёҖдёӘз®ҖеҚ•зҡ„еҜ№жҜ”жөӢиҜ•
еүҚйқўзҡ„жЎҲдҫӢдёӯпјҢc2c_zwdb.t_file_countиЎЁеҸӘжңүдёҖдёӘиҮӘеўһidпјҢFFileNameеӯ—ж®өжңӘеҠ зҙўеј•зҡ„sqlжү§иЎҢжғ…еҶөеҰӮдёӢпјҡ

еңЁдёҠеӣҫдёӯпјҢtype=allпјҢkey=nullпјҢrows=33777гҖӮиҜҘsqlжңӘдҪҝз”Ёзҙўеј•пјҢжҳҜдёҖдёӘж•ҲзҺҮйқһеёёдҪҺзҡ„е…ЁиЎЁжү«жҸҸгҖӮеҰӮжһңеҠ дёҠиҒ”еҗҲжҹҘиҜўе’Ңе…¶д»–дёҖдәӣзәҰжқҹжқЎд»¶пјҢж•°жҚ®еә“дјҡз–ҜзӢӮзҡ„ж¶ҲиҖ—еҶ…еӯҳпјҢ并且дјҡеҪұе“ҚеүҚз«ҜзЁӢеәҸзҡ„жү§иЎҢгҖӮ
иҝҷж—¶з»ҷFFileNameеӯ—ж®өж·»еҠ дёҖдёӘзҙўеј•пјҡ
alter table c2c_zwdb.t_file_count add index index_title(FFileName);
еҶҚж¬Ўжү§иЎҢдёҠиҝ°жҹҘиҜўиҜӯеҸҘпјҢе…¶еҜ№жҜ”еҫҲжҳҺжҳҫпјҡ

еңЁиҜҘеӣҫдёӯпјҢtype=refпјҢkey=зҙўеј•еҗҚпјҲindex_titleпјүпјҢrows=1гҖӮиҜҘsqlдҪҝз”ЁдәҶзҙўеј•index_titleпјҢдё”жҳҜдёҖдёӘеёёж•°жү«жҸҸпјҢж №жҚ®зҙўеј•еҸӘжү«жҸҸдәҶдёҖиЎҢгҖӮ
жҜ”иө·жңӘеҠ зҙўеј•зҡ„жғ…еҶөпјҢеҠ дәҶзҙўеј•еҗҺпјҢжҹҘиҜўж•ҲзҺҮеҜ№жҜ”йқһеёёжҳҺжҳҫгҖӮ
йҖҡиҝҮдёҠйқўзҡ„еҜ№жҜ”жөӢиҜ•еҸҜд»ҘзңӢеҮәпјҢзҙўеј•жҳҜеҝ«йҖҹжҗңзҙўзҡ„е…ій”®гҖӮMySQLзҙўеј•зҡ„е»әз«ӢеҜ№дәҺMySQLзҡ„й«ҳж•ҲиҝҗиЎҢжҳҜеҫҲйҮҚиҰҒзҡ„гҖӮеҜ№дәҺе°‘йҮҸзҡ„ж•°жҚ®пјҢжІЎжңүеҗҲйҖӮзҡ„зҙўеј•еҪұе“ҚдёҚжҳҜеҫҲеӨ§пјҢдҪҶжҳҜпјҢеҪ“йҡҸзқҖж•°жҚ®йҮҸзҡ„еўһеҠ пјҢжҖ§иғҪдјҡжҖҘеү§дёӢйҷҚгҖӮеҰӮжһңеҜ№еӨҡеҲ—иҝӣиЎҢзҙўеј•(з»„еҗҲзҙўеј•)пјҢеҲ—зҡ„йЎәеәҸйқһеёёйҮҚиҰҒпјҢMySQLд»…иғҪеҜ№зҙўеј•жңҖе·Ұиҫ№зҡ„еүҚзјҖиҝӣиЎҢжңүж•Ҳзҡ„жҹҘжүҫгҖӮ
дёӢйқўд»Ӣз»ҚеҮ з§Қеёёи§Ғзҡ„MySQLзҙўеј•зұ»еһӢгҖӮ
зҙўеј•еҲҶеҚ•еҲ—зҙўеј•е’Ңз»„еҗҲзҙўеј•гҖӮеҚ•еҲ—зҙўеј•пјҢеҚідёҖдёӘзҙўеј•еҸӘеҢ…еҗ«еҚ•дёӘеҲ—пјҢдёҖдёӘиЎЁеҸҜд»ҘжңүеӨҡдёӘеҚ•еҲ—зҙўеј•пјҢдҪҶиҝҷдёҚжҳҜз»„еҗҲзҙўеј•гҖӮз»„еҗҲзҙўеј•пјҢеҚідёҖдёӘзҙўеј•еҢ…еҗ«еӨҡдёӘеҲ—гҖӮ
(1) дё»й”®зҙўеј• PRIMARY KEY
е®ғжҳҜдёҖз§Қзү№ж®Ҡзҡ„е”ҜдёҖзҙўеј•пјҢдёҚе…Ғи®ёжңүз©әеҖјгҖӮдёҖиҲ¬жҳҜеңЁе»әиЎЁзҡ„ж—¶еҖҷеҗҢж—¶еҲӣе»әдё»й”®зҙўеј•гҖӮ
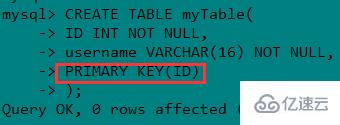
еҪ“然д№ҹеҸҜд»Ҙз”Ё ALTER е‘Ҫд»ӨгҖӮи®°дҪҸпјҡдёҖдёӘиЎЁеҸӘиғҪжңүдёҖдёӘдё»й”®гҖӮ
(2) е”ҜдёҖзҙўеј• UNIQUE
е”ҜдёҖзҙўеј•еҲ—зҡ„еҖјеҝ…йЎ»е”ҜдёҖпјҢдҪҶе…Ғи®ёжңүз©әеҖјгҖӮеҰӮжһңжҳҜз»„еҗҲзҙўеј•пјҢеҲҷеҲ—еҖјзҡ„з»„еҗҲеҝ…йЎ»е”ҜдёҖгҖӮеҸҜд»ҘеңЁеҲӣе»әиЎЁзҡ„ж—¶еҖҷжҢҮе®ҡпјҢд№ҹеҸҜд»Ҙдҝ®ж”№иЎЁз»“жһ„пјҢеҰӮпјҡ
ALTER TABLE table_name ADD UNIQUE (column)
(3) жҷ®йҖҡзҙўеј• INDEX
иҝҷжҳҜжңҖеҹәжң¬зҡ„зҙўеј•пјҢе®ғжІЎжңүд»»дҪ•йҷҗеҲ¶гҖӮеҸҜд»ҘеңЁеҲӣе»әиЎЁзҡ„ж—¶еҖҷжҢҮе®ҡпјҢд№ҹеҸҜд»Ҙдҝ®ж”№иЎЁз»“жһ„пјҢеҰӮпјҡ
ALTER TABLE table_name ADD INDEX index_name (column)
(4) з»„еҗҲзҙўеј• INDEX
з»„еҗҲзҙўеј•пјҢеҚідёҖдёӘзҙўеј•еҢ…еҗ«еӨҡдёӘеҲ—гҖӮеҸҜд»ҘеңЁеҲӣе»әиЎЁзҡ„ж—¶еҖҷжҢҮе®ҡпјҢд№ҹеҸҜд»Ҙдҝ®ж”№иЎЁз»“жһ„пјҢеҰӮпјҡ
ALTER TABLE table_name ADD INDEX index_name(column1, column2, column3)
(5) е…Ёж–Үзҙўеј• FULLTEXT
е…Ёж–Үзҙўеј•пјҲд№ҹз§°е…Ёж–ҮжЈҖзҙўпјүжҳҜзӣ®еүҚжҗңзҙўеј•ж“ҺдҪҝз”Ёзҡ„дёҖз§Қе…ій”®жҠҖжңҜгҖӮе®ғиғҪеӨҹеҲ©з”ЁеҲҶиҜҚжҠҖжңҜзӯүеӨҡз§Қз®—жі•жҷәиғҪеҲҶжһҗеҮәж–Үжң¬ж–Үеӯ—дёӯе…ій”®еӯ—иҜҚзҡ„йў‘зҺҮеҸҠйҮҚиҰҒжҖ§пјҢ然еҗҺжҢүз…§дёҖе®ҡзҡ„算法规еҲҷжҷәиғҪең°зӯӣйҖүеҮәжҲ‘们жғіиҰҒзҡ„жҗңзҙўз»“жһңгҖӮ
еҸҜд»ҘеңЁеҲӣе»әиЎЁзҡ„ж—¶еҖҷжҢҮе®ҡпјҢд№ҹеҸҜд»Ҙдҝ®ж”№иЎЁз»“жһ„пјҢеҰӮпјҡ
ALTER TABLE table_name ADD FULLTEXT (column)
mysqlдёӯжҷ®йҒҚдҪҝз”ЁB+TreeеҒҡзҙўеј•пјҢдҪҶеңЁе®һзҺ°дёҠеҸҲж №жҚ®иҒҡз°Үзҙўеј•е’ҢйқһиҒҡз°Үзҙўеј•иҖҢдёҚеҗҢпјҢжң¬ж–ҮжҡӮдёҚи®Ёи®әиҝҷзӮ№гҖӮ
b+ж ‘д»Ӣз»Қ
дёӢйқўиҝҷеј b+ж ‘зҡ„еӣҫзүҮеңЁеҫҲеӨҡең°ж–№еҸҜд»ҘзңӢеҲ°пјҢд№ӢжүҖд»ҘеңЁиҝҷйҮҢд№ҹйҖүеҸ–иҝҷеј пјҢжҳҜеӣ дёәи§үеҫ—иҝҷеј еӣҫзүҮеҸҜд»ҘеҫҲеҘҪзҡ„иҜ йҮҠзҙўеј•зҡ„жҹҘжүҫиҝҮзЁӢгҖӮ

еҰӮдёҠеӣҫпјҢжҳҜдёҖйў—b+ж ‘гҖӮжө…и“қиүІзҡ„еқ—жҲ‘们称д№ӢдёәдёҖдёӘзЈҒзӣҳеқ—пјҢеҸҜд»ҘзңӢеҲ°жҜҸдёӘзЈҒзӣҳеқ—еҢ…еҗ«еҮ дёӘж•°жҚ®йЎ№пјҲж·ұи“қиүІжүҖзӨәпјүе’ҢжҢҮй’ҲпјҲй»„иүІжүҖзӨәпјүпјҢеҰӮзЈҒзӣҳеқ—1еҢ…еҗ«ж•°жҚ®йЎ№17е’Ң35пјҢеҢ…еҗ«жҢҮй’ҲP1гҖҒP2гҖҒP3пјҢP1иЎЁзӨәе°ҸдәҺ17зҡ„зЈҒзӣҳеқ—пјҢP2иЎЁзӨәеңЁ17е’Ң35д№Ӣй—ҙзҡ„зЈҒзӣҳеқ—пјҢP3иЎЁзӨәеӨ§дәҺ35зҡ„зЈҒзӣҳеқ—гҖӮ
зңҹе®һзҡ„ж•°жҚ®еӯҳеңЁдәҺеҸ¶еӯҗиҠӮзӮ№пјҢеҚі3гҖҒ5гҖҒ9гҖҒ10гҖҒ13гҖҒ15гҖҒ28гҖҒ29гҖҒ36гҖҒ60гҖҒ75гҖҒ79гҖҒ90гҖҒ99гҖӮйқһеҸ¶еӯҗиҠӮзӮ№дёҚеӯҳеӮЁзңҹе®һзҡ„ж•°жҚ®пјҢеҸӘеӯҳеӮЁжҢҮеј•жҗңзҙўж–№еҗ‘зҡ„ж•°жҚ®йЎ№пјҢеҰӮ17гҖҒ35并дёҚзңҹе®һеӯҳеңЁдәҺж•°жҚ®иЎЁдёӯгҖӮ
жҹҘжүҫиҝҮзЁӢ
еңЁдёҠеӣҫдёӯпјҢеҰӮжһңиҰҒжҹҘжүҫж•°жҚ®йЎ№29пјҢйӮЈд№ҲйҰ–е…ҲдјҡжҠҠзЈҒзӣҳеқ—1з”ұзЈҒзӣҳеҠ иҪҪеҲ°еҶ…еӯҳпјҢжӯӨж—¶еҸ‘з”ҹдёҖж¬ЎIOпјҢеңЁеҶ…еӯҳдёӯз”ЁдәҢеҲҶжҹҘжүҫзЎ®е®ҡ29еңЁ17е’Ң35д№Ӣй—ҙпјҢй”Ғе®ҡзЈҒзӣҳеқ—1зҡ„P2жҢҮй’ҲпјҢеҶ…еӯҳж—¶й—ҙеӣ дёәйқһеёёзҹӯпјҲзӣёжҜ”зЈҒзӣҳзҡ„IOпјүеҸҜд»ҘеҝҪз•ҘдёҚи®ЎпјҢйҖҡиҝҮзЈҒзӣҳеқ—1зҡ„P2жҢҮй’Ҳзҡ„зЈҒзӣҳең°еқҖжҠҠзЈҒзӣҳеқ—3з”ұзЈҒзӣҳеҠ иҪҪеҲ°еҶ…еӯҳпјҢеҸ‘з”ҹ第дәҢж¬ЎIOпјҢ29еңЁ26е’Ң30д№Ӣй—ҙпјҢй”Ғе®ҡзЈҒзӣҳеқ—3зҡ„P2жҢҮй’ҲпјҢйҖҡиҝҮжҢҮй’ҲеҠ иҪҪзЈҒзӣҳеқ—8еҲ°еҶ…еӯҳпјҢеҸ‘з”ҹ第дёүж¬ЎIOпјҢеҗҢж—¶еҶ…еӯҳдёӯеҒҡдәҢеҲҶжҹҘжүҫжүҫеҲ°29пјҢз»“жқҹжҹҘиҜўпјҢжҖ»и®Ўдёүж¬ЎIOгҖӮзңҹе®һзҡ„жғ…еҶөжҳҜпјҢ3еұӮзҡ„b+ж ‘еҸҜд»ҘиЎЁзӨәдёҠзҷҫдёҮзҡ„ж•°жҚ®пјҢеҰӮжһңдёҠзҷҫдёҮзҡ„ж•°жҚ®жҹҘжүҫеҸӘйңҖиҰҒдёүж¬ЎIOпјҢжҖ§иғҪжҸҗй«ҳе°ҶжҳҜе·ЁеӨ§зҡ„пјҢеҰӮжһңжІЎжңүзҙўеј•пјҢжҜҸдёӘж•°жҚ®йЎ№йғҪиҰҒеҸ‘з”ҹдёҖж¬ЎIOпјҢйӮЈд№ҲжҖ»е…ұйңҖиҰҒзҷҫдёҮж¬Ўзҡ„IOпјҢжҳҫ然жҲҗжң¬йқһеёёйқһеёёй«ҳгҖӮ
жҖ§иҙЁ
(1) зҙўеј•еӯ—ж®өиҰҒе°ҪйҮҸзҡ„е°ҸгҖӮ
йҖҡиҝҮдёҠйқўb+ж ‘зҡ„жҹҘжүҫиҝҮзЁӢпјҢжҲ–иҖ…йҖҡиҝҮзңҹе®һзҡ„ж•°жҚ®еӯҳеңЁдәҺеҸ¶еӯҗиҠӮзӮ№иҝҷдёӘдәӢе®һеҸҜзҹҘпјҢIOж¬Ўж•°еҸ–еҶідәҺb+ж•°зҡ„й«ҳеәҰhгҖӮ
еҒҮи®ҫеҪ“еүҚж•°жҚ®иЎЁзҡ„ж•°жҚ®йҮҸдёәNпјҢжҜҸдёӘзЈҒзӣҳеқ—зҡ„ж•°жҚ®йЎ№зҡ„ж•°йҮҸжҳҜmпјҢеҲҷж ‘й«ҳh=гҸ’(m+1)NпјҢеҪ“ж•°жҚ®йҮҸNдёҖе®ҡзҡ„жғ…еҶөдёӢпјҢmи¶ҠеӨ§пјҢhи¶Ҡе°Ҹпјӣ
иҖҢm = зЈҒзӣҳеқ—зҡ„еӨ§е°Ҹ/ж•°жҚ®йЎ№зҡ„еӨ§е°ҸпјҢзЈҒзӣҳеқ—зҡ„еӨ§е°Ҹд№ҹе°ұжҳҜдёҖдёӘж•°жҚ®йЎөзҡ„еӨ§е°ҸпјҢжҳҜеӣәе®ҡзҡ„пјӣеҰӮжһңж•°жҚ®йЎ№еҚ зҡ„з©әй—ҙи¶Ҡе°ҸпјҢж•°жҚ®йЎ№зҡ„ж•°йҮҸmи¶ҠеӨҡпјҢж ‘зҡ„й«ҳеәҰhи¶ҠдҪҺгҖӮиҝҷе°ұжҳҜдёәд»Җд№ҲжҜҸдёӘж•°жҚ®йЎ№пјҢеҚізҙўеј•еӯ—ж®өиҰҒе°ҪйҮҸзҡ„е°ҸпјҢжҜ”еҰӮintеҚ 4еӯ—иҠӮпјҢиҰҒжҜ”bigint8еӯ—иҠӮе°‘дёҖеҚҠгҖӮ
(2) зҙўеј•зҡ„жңҖе·ҰеҢ№й…Қзү№жҖ§гҖӮ
еҪ“b+ж ‘зҡ„ж•°жҚ®йЎ№жҳҜеӨҚеҗҲзҡ„ж•°жҚ®з»“жһ„пјҢжҜ”еҰӮ(name,age,sex)зҡ„ж—¶еҖҷпјҢb+ж•°жҳҜжҢүз…§д»Һе·ҰеҲ°еҸізҡ„йЎәеәҸжқҘе»әз«Ӣжҗңзҙўж ‘зҡ„пјҢжҜ”еҰӮеҪ“(еј дёү,20,F)иҝҷж ·зҡ„ж•°жҚ®жқҘжЈҖзҙўзҡ„ж—¶еҖҷпјҢb+ж ‘дјҡдјҳе…ҲжҜ”иҫғnameжқҘзЎ®е®ҡдёӢдёҖжӯҘзҡ„жүҖжҗңж–№еҗ‘пјҢеҰӮжһңnameзӣёеҗҢеҶҚдҫқж¬ЎжҜ”иҫғageе’ҢsexпјҢжңҖеҗҺеҫ—еҲ°жЈҖзҙўзҡ„ж•°жҚ®пјӣдҪҶеҪ“(20,F)иҝҷж ·зҡ„жІЎжңүnameзҡ„ж•°жҚ®жқҘзҡ„ж—¶еҖҷпјҢb+ж ‘е°ұдёҚзҹҘйҒ“дёӢдёҖжӯҘиҜҘжҹҘе“ӘдёӘиҠӮзӮ№пјҢеӣ дёәе»әз«Ӣжҗңзҙўж ‘зҡ„ж—¶еҖҷnameе°ұжҳҜ第дёҖдёӘжҜ”иҫғеӣ еӯҗпјҢеҝ…йЎ»иҰҒе…Ҳж №жҚ®nameжқҘжҗңзҙўжүҚиғҪзҹҘйҒ“дёӢдёҖжӯҘеҺ»е“ӘйҮҢжҹҘиҜўгҖӮжҜ”еҰӮеҪ“(еј дёү,F)иҝҷж ·зҡ„ж•°жҚ®жқҘжЈҖзҙўж—¶пјҢb+ж ‘еҸҜд»Ҙз”ЁnameжқҘжҢҮе®ҡжҗңзҙўж–№еҗ‘пјҢдҪҶдёӢдёҖдёӘеӯ—ж®өageзҡ„зјәеӨұпјҢжүҖд»ҘеҸӘиғҪжҠҠеҗҚеӯ—зӯүдәҺеј дёүзҡ„ж•°жҚ®йғҪжүҫеҲ°пјҢ然еҗҺеҶҚеҢ№й…ҚжҖ§еҲ«жҳҜFзҡ„ж•°жҚ®дәҶпјҢ иҝҷдёӘжҳҜйқһеёёйҮҚиҰҒзҡ„жҖ§иҙЁпјҢеҚізҙўеј•зҡ„жңҖе·ҰеҢ№й…Қзү№жҖ§гҖӮ
е»әзҙўеј•зҡ„еҮ еӨ§еҺҹеҲҷ
(1) жңҖе·ҰеүҚзјҖеҢ№й…ҚеҺҹеҲҷ
еҜ№дәҺеӨҡеҲ—зҙўеј•пјҢжҖ»жҳҜд»Һзҙўеј•зҡ„жңҖеүҚйқўеӯ—ж®өејҖе§ӢпјҢжҺҘзқҖеҫҖеҗҺпјҢдёӯй—ҙдёҚиғҪи·іиҝҮгҖӮжҜ”еҰӮеҲӣе»әдәҶеӨҡеҲ—зҙўеј•(name,age,sex)пјҢдјҡе…ҲеҢ№й…Қnameеӯ—ж®өпјҢеҶҚеҢ№й…Қageеӯ—ж®өпјҢеҶҚеҢ№й…Қsexеӯ—ж®өзҡ„пјҢдёӯй—ҙдёҚиғҪи·іиҝҮгҖӮmysqlдјҡдёҖзӣҙеҗ‘еҸіеҢ№й…ҚзӣҙеҲ°йҒҮеҲ°иҢғеӣҙжҹҘиҜў(>гҖҒ<гҖҒbetweenгҖҒlike)е°ұеҒңжӯўеҢ№й…ҚгҖӮ
дёҖиҲ¬пјҢеңЁеҲӣе»әеӨҡеҲ—зҙўеј•ж—¶пјҢwhereеӯҗеҸҘдёӯдҪҝз”ЁжңҖйў‘з№Ғзҡ„дёҖеҲ—ж”ҫеңЁжңҖе·Ұиҫ№гҖӮ
зңӢдёҖдёӘиЎҘз¬ҰеҗҲжңҖе·ҰеүҚзјҖеҢ№й…ҚеҺҹеҲҷе’Ңз¬ҰеҗҲиҜҘеҺҹеҲҷзҡ„еҜ№жҜ”дҫӢеӯҗгҖӮ
е®һдҫӢпјҡиЎЁc2c_db.t_credit_detailе»әжңүзҙўеј•(Flistid,Fbank_listid)
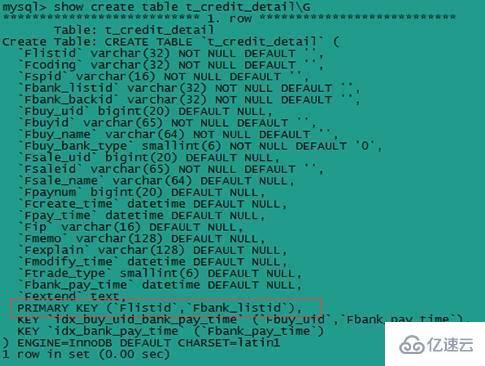
дёҚз¬ҰеҗҲжңҖе·ҰеүҚзјҖеҢ№й…ҚеҺҹеҲҷзҡ„sqlиҜӯеҸҘпјҡ
select * from t_credit_detail where Fbank_listid='201108010000199'G
иҜҘsqlзӣҙжҺҘз”ЁдәҶ第дәҢдёӘзҙўеј•еӯ—ж®өFbank_listidпјҢи·іиҝҮдәҶ第дёҖдёӘзҙўеј•еӯ—ж®өFlistidпјҢдёҚз¬ҰеҗҲжңҖе·ҰеүҚзјҖеҢ№й…ҚеҺҹеҲҷгҖӮз”Ёexplainе‘Ҫд»ӨжҹҘзңӢsqlиҜӯеҸҘзҡ„жү§иЎҢи®ЎеҲ’пјҢеҰӮдёӢеӣҫпјҡ
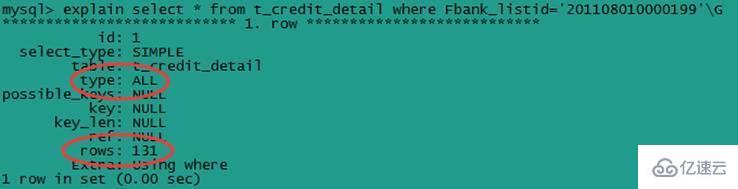
д»ҺдёҠеӣҫеҸҜд»ҘзңӢеҮәпјҢиҜҘsqlжңӘдҪҝз”Ёзҙўеј•пјҢжҳҜдёҖдёӘдҪҺж•Ҳзҡ„е…ЁиЎЁжү«жҸҸгҖӮ
з¬ҰеҗҲжңҖе·ҰеүҚзјҖеҢ№й…ҚеҺҹеҲҷзҡ„sqlиҜӯеҸҘпјҡ
select * from t_credit_detail where Flistid='2000000608201108010831508721' and Fbank_listid='201108010000199'G
иҜҘsqlе…ҲдҪҝз”ЁдәҶзҙўеј•зҡ„第дёҖдёӘеӯ—ж®өFlistidпјҢеҶҚдҪҝз”Ёзҙўеј•зҡ„第дәҢдёӘеӯ—ж®өFbank_listidпјҢдёӯй—ҙжІЎжңүи·іиҝҮпјҢз¬ҰеҗҲжңҖе·ҰеүҚзјҖеҢ№й…ҚеҺҹеҲҷгҖӮз”Ёexplainе‘Ҫд»ӨжҹҘзңӢsqlиҜӯеҸҘзҡ„жү§иЎҢи®ЎеҲ’пјҢеҰӮдёӢеӣҫпјҡ

д»ҺдёҠеӣҫеҸҜд»ҘзңӢеҮәпјҢиҜҘsqlдҪҝз”ЁдәҶзҙўеј•пјҢд»…жү«жҸҸдәҶдёҖиЎҢгҖӮ
еҜ№жҜ”еҸҜзҹҘпјҢз¬ҰеҗҲжңҖе·ҰеүҚзјҖеҢ№й…ҚеҺҹеҲҷзҡ„sqlиҜӯеҸҘжҜ”дёҚз¬ҰеҗҲиҜҘеҺҹеҲҷзҡ„sqlиҜӯеҸҘж•ҲзҺҮжңүжһҒеӨ§жҸҗй«ҳпјҢд»Һе…ЁиЎЁжү«жҸҸдёҠеҚҮеҲ°дәҶеёёж•°жү«жҸҸгҖӮ
(2) е°ҪйҮҸйҖүжӢ©еҢәеҲҶеәҰй«ҳзҡ„еҲ—дҪңдёәзҙўеј•гҖӮ
жҜ”еҰӮпјҢжҲ‘们дјҡйҖүжӢ©еӯҰеҸ·еҒҡзҙўеј•пјҢиҖҢдёҚдјҡйҖүжӢ©жҖ§еҲ«жқҘеҒҡзҙўеј•гҖӮ
(3) =е’ҢinеҸҜд»Ҙд№ұеәҸ
жҜ”еҰӮa = 1 and b = 2 and c = 3пјҢе»әз«Ӣ(a,b,c)зҙўеј•еҸҜд»Ҙд»»ж„ҸйЎәеәҸпјҢmysqlзҡ„жҹҘиҜўдјҳеҢ–еҷЁдјҡеё®дҪ дјҳеҢ–жҲҗзҙўеј•еҸҜд»ҘиҜҶеҲ«зҡ„еҪўејҸгҖӮ
(4) зҙўеј•еҲ—дёҚиғҪеҸӮдёҺи®Ўз®—пјҢдҝқжҢҒеҲ—вҖңе№ІеҮҖвҖқ
жҜ”еҰӮпјҡFlistid+1>вҖҳ2000000608201108010831508721вҖҳгҖӮеҺҹеӣ еҫҲз®ҖеҚ•пјҢеҒҮеҰӮзҙўеј•еҲ—еҸӮдёҺи®Ўз®—зҡ„иҜқпјҢйӮЈжҜҸж¬ЎжЈҖзҙўж—¶пјҢйғҪдјҡе…Ҳе°Ҷзҙўеј•и®Ўз®—дёҖж¬ЎпјҢеҶҚеҒҡжҜ”иҫғпјҢжҳҫ然жҲҗжң¬еӨӘеӨ§гҖӮ
(5) е°ҪйҮҸзҡ„жү©еұ•зҙўеј•пјҢдёҚиҰҒж–°е»әзҙўеј•гҖӮ
жҜ”еҰӮиЎЁдёӯе·Із»Ҹжңүaзҡ„зҙўеј•пјҢзҺ°еңЁиҰҒеҠ (a,b)зҡ„зҙўеј•пјҢйӮЈд№ҲеҸӘйңҖиҰҒдҝ®ж”№еҺҹжқҘзҡ„зҙўеј•еҚіеҸҜгҖӮ
зҙўеј•зҡ„дёҚи¶і
иҷҪ然зҙўеј•еҸҜд»ҘжҸҗй«ҳжҹҘиҜўж•ҲзҺҮпјҢдҪҶзҙўеј•д№ҹжңүиҮӘе·ұзҡ„дёҚи¶ід№ӢеӨ„гҖӮ
зҙўеј•зҡ„йўқеӨ–ејҖй”Җпјҡ
(1) з©әй—ҙпјҡзҙўеј•йңҖиҰҒеҚ з”Ёз©әй—ҙпјӣ
(2) ж—¶й—ҙпјҡжҹҘиҜўзҙўеј•йңҖиҰҒж—¶й—ҙпјӣ
(3) з»ҙжҠӨпјҡзҙўеј•йЎ»иҰҒз»ҙжҠӨпјҲж•°жҚ®еҸҳжӣҙж—¶пјүпјӣ
дёҚе»әи®®дҪҝз”Ёзҙўеј•зҡ„жғ…еҶөпјҡ
(1) ж•°жҚ®йҮҸеҫҲе°Ҹзҡ„иЎЁ
(2) з©әй—ҙзҙ§еј
дјҳеҢ–иҜӯеҸҘеҫҲеӨҡпјҢйңҖиҰҒжіЁж„Ҹзҡ„д№ҹеҫҲеӨҡпјҢй’ҲеҜ№е№іж—¶зҡ„жғ…еҶөжҖ»з»“дёҖдёӢеҮ зӮ№пјҡ
(1) Likeзҡ„еҸӮж•°д»ҘйҖҡй…Қз¬ҰејҖеӨҙж—¶
е°ҪйҮҸйҒҝе…ҚLikeзҡ„еҸӮж•°д»ҘйҖҡй…Қз¬ҰејҖеӨҙпјҢеҗҰеҲҷж•°жҚ®еә“еј•ж“Һдјҡж”ҫејғдҪҝз”Ёзҙўеј•иҖҢиҝӣиЎҢе…ЁиЎЁжү«жҸҸгҖӮ
д»ҘйҖҡй…Қз¬ҰејҖеӨҙзҡ„sqlиҜӯеҸҘпјҢдҫӢеҰӮпјҡselect * from t_credit_detail where Flistid like '%0'G
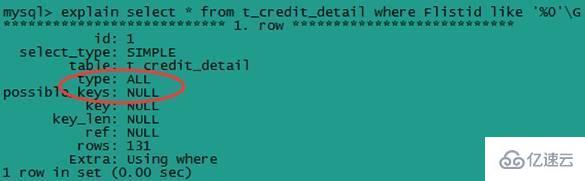
иҝҷжҳҜе…ЁиЎЁжү«жҸҸпјҢжІЎжңүдҪҝз”ЁеҲ°зҙўеј•пјҢдёҚе»әи®®дҪҝз”ЁгҖӮ
дёҚд»ҘйҖҡй…Қз¬ҰејҖеӨҙзҡ„sqlиҜӯеҸҘпјҢдҫӢеҰӮпјҡselect * from t_credit_detail where Flistid like '2%'G
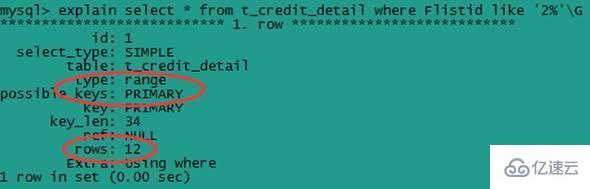
еҫҲжҳҺжҳҫпјҢиҝҷдҪҝз”ЁеҲ°дәҶзҙўеј•пјҢжҳҜжңүиҢғеӣҙзҡ„жҹҘжүҫдәҶпјҢжҜ”д»ҘйҖҡй…Қз¬ҰејҖеӨҙзҡ„sqlиҜӯеҸҘж•ҲзҺҮжҸҗй«ҳдёҚе°‘гҖӮ
(2) whereжқЎд»¶дёҚз¬ҰеҗҲжңҖе·ҰеүҚзјҖеҺҹеҲҷж—¶
дҫӢеӯҗе·ІеңЁжңҖе·ҰеүҚзјҖеҢ№й…ҚеҺҹеҲҷзҡ„еҶ…е®№дёӯжңүдёҫдҫӢгҖӮ
(3) дҪҝз”ЁпјҒ= жҲ– <> ж“ҚдҪңз¬Ұж—¶
е°ҪйҮҸйҒҝе…ҚдҪҝз”ЁпјҒ= жҲ– <>ж“ҚдҪңз¬ҰпјҢеҗҰеҲҷж•°жҚ®еә“еј•ж“Һдјҡж”ҫејғдҪҝз”Ёзҙўеј•иҖҢиҝӣиЎҢе…ЁиЎЁжү«жҸҸгҖӮдҪҝз”Ё>жҲ–<дјҡжҜ”иҫғй«ҳж•ҲгҖӮ
select * from t_credit_detail where Flistid != '2000000608201108010831508721'G
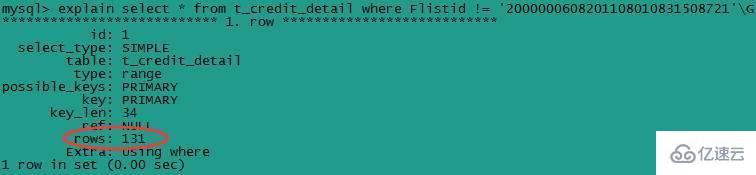
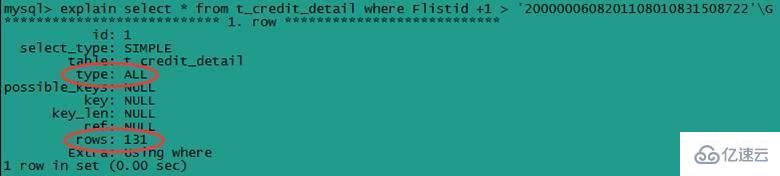
(4) зҙўеј•еҲ—еҸӮдёҺи®Ўз®—
еә”е°ҪйҮҸйҒҝе…ҚеңЁ where еӯҗеҸҘдёӯеҜ№еӯ—ж®өиҝӣиЎҢиЎЁиҫҫејҸж“ҚдҪңпјҢиҝҷе°ҶеҜјиҮҙеј•ж“Һж”ҫејғдҪҝз”Ёзҙўеј•иҖҢиҝӣиЎҢе…ЁиЎЁжү«жҸҸгҖӮ
select * from t_credit_detail where Flistid +1 > '2000000608201108010831508722'G
(5) еҜ№еӯ—ж®өиҝӣиЎҢnullеҖјеҲӨж–ӯ
еә”е°ҪйҮҸйҒҝе…ҚеңЁwhereеӯҗеҸҘдёӯеҜ№еӯ—ж®өиҝӣиЎҢnullеҖјеҲӨж–ӯпјҢеҗҰеҲҷе°ҶеҜјиҮҙеј•ж“Һж”ҫејғдҪҝз”Ёзҙўеј•иҖҢиҝӣиЎҢе…ЁиЎЁжү«жҸҸпјҢеҰӮпјҡ дҪҺж•Ҳпјҡselect * from t_credit_detail where Flistid is null ;
еҸҜд»ҘеңЁFlistidдёҠи®ҫзҪ®й»ҳи®ӨеҖј0пјҢзЎ®дҝқиЎЁдёӯFlistidеҲ—жІЎжңүnullеҖјпјҢ然еҗҺиҝҷж ·жҹҘиҜўпјҡ й«ҳж•Ҳпјҡselect * from t_credit_detail where Flistid =0;
(6) дҪҝз”ЁorжқҘиҝһжҺҘжқЎд»¶
еә”е°ҪйҮҸйҒҝе…ҚеңЁwhereеӯҗеҸҘдёӯдҪҝз”ЁorжқҘиҝһжҺҘжқЎд»¶пјҢеҗҰеҲҷе°ҶеҜјиҮҙеј•ж“Һж”ҫејғдҪҝз”Ёзҙўеј•иҖҢиҝӣиЎҢе…ЁиЎЁжү«жҸҸпјҢеҰӮпјҡ дҪҺж•Ҳпјҡselect * from t_credit_detail where Flistid = '2000000608201108010831508721' or Flistid = '10000200001';
еҸҜд»Ҙз”ЁдёӢйқўиҝҷж ·зҡ„жҹҘиҜўд»ЈжӣҝдёҠйқўзҡ„ or жҹҘиҜўпјҡ й«ҳж•Ҳпјҡselect from t_credit_detail where Flistid = '2000000608201108010831508721' union all select from t_credit_detail where Flistid = '10000200001';

еңЁи§Јжһҗзҡ„иҝҮзЁӢдёӯпјҢдјҡе°Ҷ'*' дҫқж¬ЎиҪ¬жҚўжҲҗжүҖжңүзҡ„еҲ—еҗҚпјҢиҝҷдёӘе·ҘдҪңжҳҜйҖҡиҝҮжҹҘиҜўж•°жҚ®еӯ—е…ёе®ҢжҲҗзҡ„пјҢиҝҷж„Ҹе‘ізқҖе°ҶиҖ—иҙ№жӣҙеӨҡзҡ„ж—¶й—ҙгҖӮ
жүҖд»ҘпјҢеә”иҜҘе…»жҲҗдёҖдёӘйңҖиҰҒд»Җд№Ҳе°ұеҸ–д»Җд№Ҳзҡ„еҘҪд№ жғҜгҖӮ
д»»дҪ•еңЁOrder byиҜӯеҸҘзҡ„йқһзҙўеј•йЎ№жҲ–иҖ…жңүи®Ўз®—иЎЁиҫҫејҸйғҪе°ҶйҷҚдҪҺжҹҘиҜўйҖҹеәҰгҖӮ
ж–№жі•пјҡ1.йҮҚеҶҷorder byиҜӯеҸҘд»ҘдҪҝз”Ёзҙўеј•пјӣ
2.дёәжүҖдҪҝз”Ёзҡ„еҲ—е»әз«ӢеҸҰеӨ–дёҖдёӘзҙўеј• 3.з»қеҜ№йҒҝе…ҚеңЁorder byеӯҗеҸҘдёӯдҪҝз”ЁиЎЁиҫҫејҸгҖӮ
жҸҗй«ҳGROUP BY иҜӯеҸҘзҡ„ж•ҲзҺҮ, еҸҜд»ҘйҖҡиҝҮе°ҶдёҚйңҖиҰҒзҡ„и®°еҪ•еңЁGROUP BY д№ӢеүҚиҝҮж»ӨжҺү
дҪҺж•Ҳ:
SELECT JOB , AVG(SAL)
FROM EMP
GROUP by JOB
HAVING JOB = вҖҳPRESIDENT'
OR JOB = вҖҳMANAGER'
й«ҳж•Ҳ:
SELECT JOB , AVG(SAL)
FROM EMP
WHERE JOB = вҖҳPRESIDENT'
OR JOB = вҖҳMANAGER'
GROUP by JOB
еҫҲеӨҡж—¶еҖҷз”Ё exists д»Јжӣҝ in жҳҜдёҖдёӘеҘҪзҡ„йҖүжӢ©пјҡ select num from a where num in(select num from b) з”ЁдёӢйқўзҡ„иҜӯеҸҘжӣҝжҚўпјҡ select num from a where exists(select 1 from b where num=a.num)
е°ҪеҸҜиғҪзҡ„дҪҝз”Ё varchar/nvarchar д»Јжӣҝ char/nchar пјҢеӣ дёәйҰ–е…ҲеҸҳй•ҝеӯ—ж®өеӯҳеӮЁз©әй—ҙе°ҸпјҢеҸҜд»ҘиҠӮзңҒеӯҳеӮЁз©әй—ҙпјҢе…¶ж¬ЎеҜ№дәҺжҹҘиҜўжқҘиҜҙпјҢеңЁдёҖдёӘзӣёеҜ№иҫғе°Ҹзҡ„еӯ—ж®өеҶ…жҗңзҙўж•ҲзҺҮжҳҫ然иҰҒй«ҳдәӣгҖӮ
SELECT OrderID FROM Details WHERE UnitPrice > 10 GROUP BY OrderID
еҸҜж”№дёәпјҡ
SELECT DISTINCT OrderID FROM Details WHERE UnitPrice > 10
UNION ALLдёҚжү§иЎҢSELECT DISTINCTеҮҪж•°пјҢиҝҷж ·е°ұдјҡеҮҸе°‘еҫҲеӨҡдёҚеҝ…иҰҒзҡ„иө„жәҗгҖӮ
еҰӮжһңеә”з”ЁзЁӢеәҸжңүеҫҲеӨҡJOIN жҹҘиҜўпјҢдҪ еә”иҜҘзЎ®и®ӨдёӨдёӘиЎЁдёӯJoinзҡ„еӯ—ж®өжҳҜиў«е»әиҝҮзҙўеј•зҡ„гҖӮиҝҷж ·пјҢMySQLеҶ…йғЁдјҡеҗҜеҠЁдёәдҪ дјҳеҢ–Joinзҡ„SQLиҜӯеҸҘзҡ„жңәеҲ¶гҖӮ
иҖҢдё”пјҢиҝҷдәӣиў«з”ЁжқҘJoinзҡ„еӯ—ж®өпјҢеә”иҜҘжҳҜзӣёеҗҢзҡ„зұ»еһӢзҡ„гҖӮдҫӢеҰӮпјҡеҰӮжһңдҪ иҰҒжҠҠ DECIMAL еӯ—ж®өе’ҢдёҖдёӘ INT еӯ—ж®өJoinеңЁдёҖиө·пјҢMySQLе°ұж— жі•дҪҝз”Ёе®ғ们зҡ„зҙўеј•гҖӮеҜ№дәҺйӮЈдәӣSTRINGзұ»еһӢпјҢиҝҳйңҖиҰҒжңүзӣёеҗҢзҡ„еӯ—з¬ҰйӣҶжүҚиЎҢгҖӮпјҲдёӨдёӘиЎЁзҡ„еӯ—з¬ҰйӣҶжңүеҸҜиғҪдёҚдёҖж ·пјү
зңӢе®Ңд»ҘдёҠе…ідәҺMySQLзҙўеј•е’ҢжҹҘиҜўдјҳеҢ–иҜҰжһҗпјҢеҫҲеӨҡиҜ»иҖ…жңӢеҸӢиӮҜе®ҡеӨҡе°‘жңүдёҖе®ҡзҡ„дәҶи§ЈпјҢеҰӮйңҖиҺ·еҸ–жӣҙеӨҡзҡ„иЎҢдёҡзҹҘиҜҶдҝЎжҒҜ пјҢеҸҜд»ҘжҢҒз»ӯе…іжіЁжҲ‘们зҡ„иЎҢдёҡиө„и®Ҝж Ҹзӣ®зҡ„гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ