您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
redis集群怎么解决脑裂问题?针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
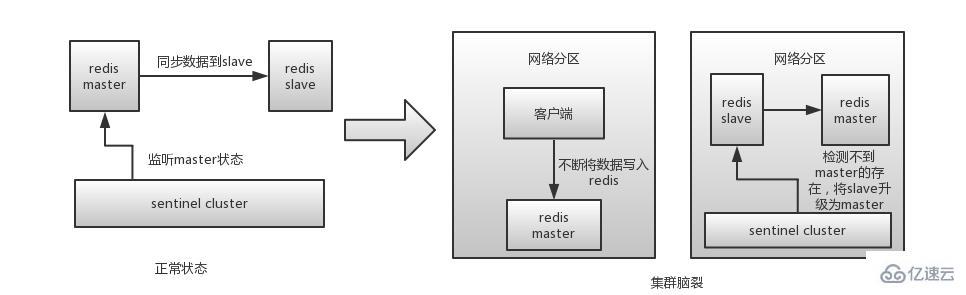
什么是redis的集群脑裂?
redis的集群脑裂是指因为网络问题,导致redis master节点跟redis slave节点和sentinel集群处于不同的网络分区,此时因为sentinel集群无法感知到master的存在,所以将slave节点提升为master节点。
此时存在两个不同的master节点,就像一个大脑分裂成了两个。
集群脑裂问题中,如果客户端还在基于原来的master节点继续写入数据,那么新的master节点将无法同步这些数据,当网络问题解决之后,sentinel集群将原先的master节点降为slave节点,此时再从新的master中同步数据,将会造成大量的数据丢失。
 解决方案
解决方案
redis的配置文件中,存在两个参数
min-slaves-to-write 3 min-slaves-max-lag 10
第一个参数表示连接到master的最少slave数量
第二个参数表示slave连接到master的最大延迟时间
如果连接到master的slave数量小于第一个参数,且ping的延迟时间小于等于第二个参数,那么master就会拒绝写请求,配置了这两个参数之后,如果发生集群脑裂,原先的master节点接收到客户端的写入请求会拒绝,就可以减少数据同步之后的数据丢失。
注意:较新版本的redis.conf文件中的参数变成了
min-replicas-to-write 3 min-replicas-max-lag 10
关于redis集群怎么解决脑裂问题问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注亿速云行业资讯频道了解更多相关知识。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。