您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
一、服务器设备类型:
HP DL380服务器
300G SAS盘 数量三块
二、服务器故障描述:
硬盘磁盘故障导致整个RAID组瘫痪,具体显示为其中一块硬盘状态灯为红色。由于数据库存储在D分区,备份存储在E分区。存储故障,造成D分区不可识别,E分区可识别,但是拷贝备份文件报错,通过重启服务器,导致先离线的硬盘上线,并同步了一段时间,在没有同步完成就直接强制关机,之后未对服务器做任何操作。
三、服务器数据恢复操作流程:
1、为了确保现存磁盘中数据的安全,先对磁盘做只读镜像备份,三块硬盘可以正常读取,没有发现坏道。只读镜像备份日志如下图所示: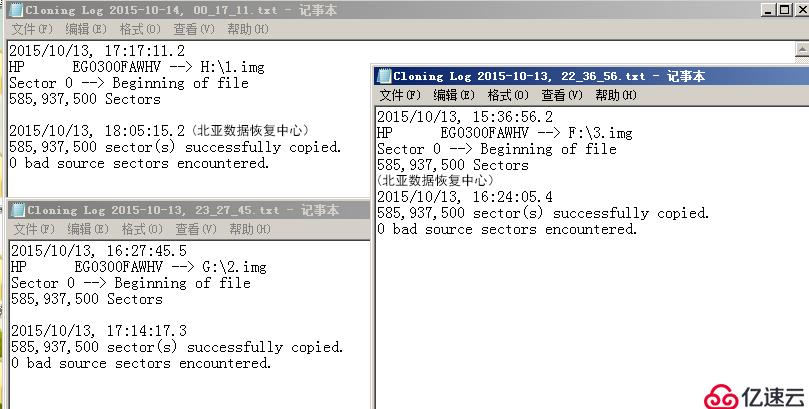
2、对备份的镜像文件进行详细分析,重组raid结构,并进行异或校验,部分校验通过。由于离线硬盘上线之后进行同步操作,会损坏数据,所以如下图所示表示数据有损坏的情况。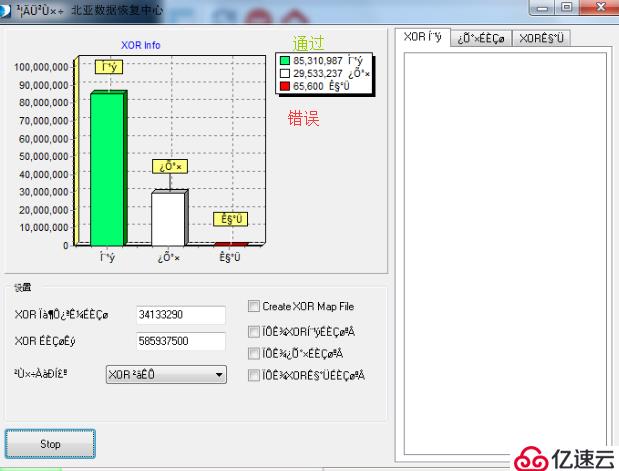
3、RAID分析过程,尝试多种硬盘离线状态下提取数据,每块盘离线所提取的数据都是一样的。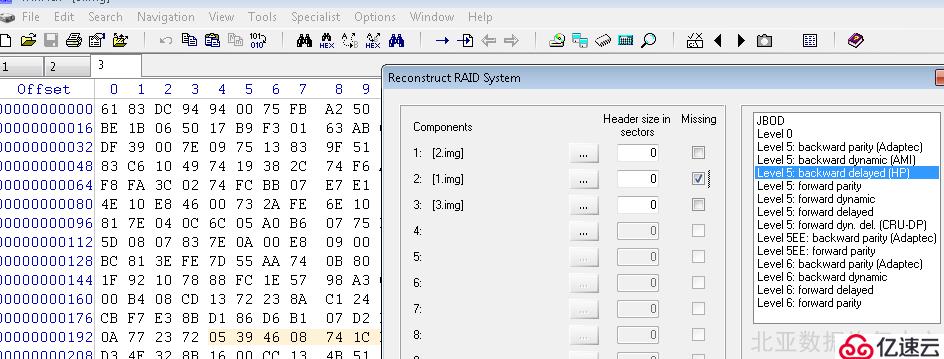
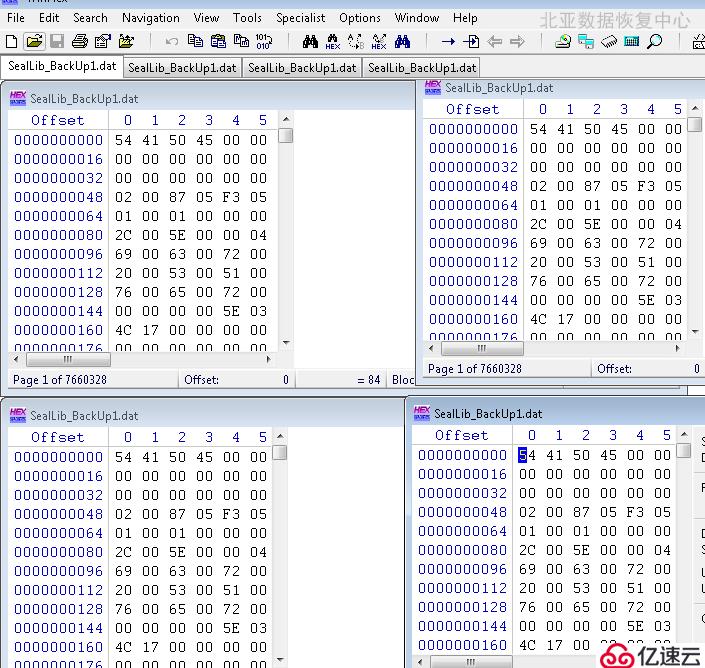
4、首先针对E分区中的dat文件进行分析修复。发现两个备份文件都有损坏,如下图: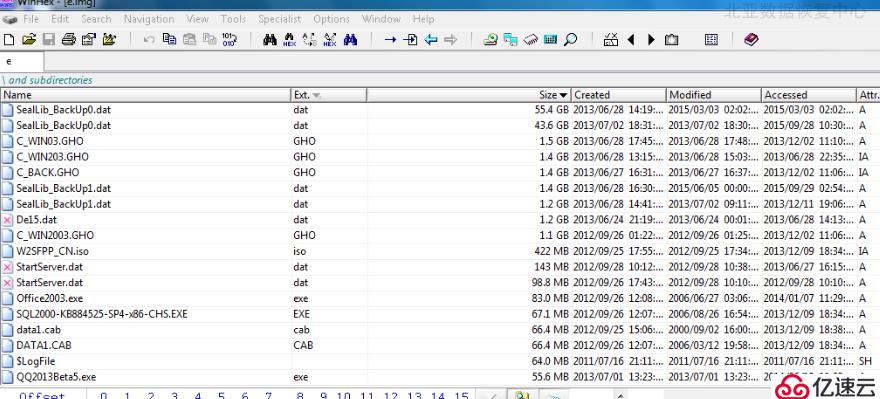
5、分析聚合dat碎片,验证dat数据完整性,底层结构显示有损坏。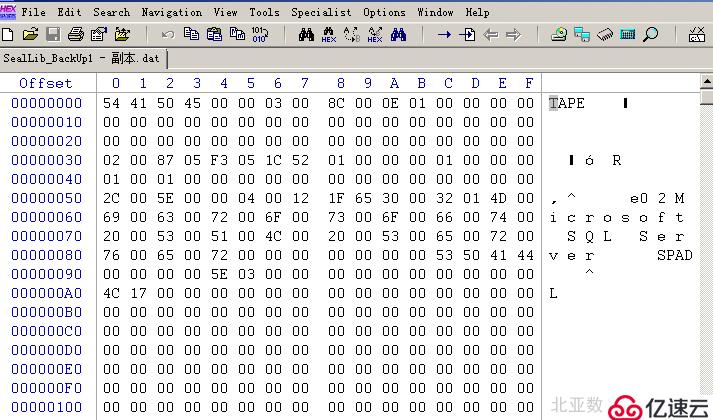
6、同时进行D分区的数据文件的分析扫描,由于存储同步,数据文件目录不可见。
7、对D分区自由空间数据页扫描,并对文件碎片进行分析和聚合。
8、验证数据文件碎片的完整性和有效性。
9、提取备份文件中的数据记录到新建的数据库中。
10、通过上层应用连接数据库,验证数据可用性,数据库文件可以正常加载,上层应用软件中用户账号正常,可以进行正常数据查询。
四、 服务器数据恢复结果
对重组的raid结构进行异或检测,发现数据部分被同步损坏,但是还有部分数据正常
在恢复过程中,在E盘发现2个SealLib数据库的备份文件。但是备份文件数据中页结构有小部分损坏,
在D分区扫描的结果中数据碎片发现较连续的数据片段,碎片可用。通过对D分区碎片和E分区备份文件进行整合拼接。
五、服务器数据恢复结论:
通过工程师解析处理,最终修复解析出的数据可以支撑整个应用的正常使用,上层应用可以正常查询数据库内容,至此数据恢复工作结束。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。