жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚдәҶpythonзҲ¬иҷ«ж¶үеҸҠзҡ„зӣёе…іеә“жңүе“ӘдәӣпјҢе…·жңүдёҖе®ҡеҖҹйүҙд»·еҖјпјҢйңҖиҰҒзҡ„жңӢеҸӢеҸҜд»ҘеҸӮиҖғдёӢгҖӮеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеӨ§жңү收иҺ·гҖӮдёӢйқўи®©е°Ҹзј–еёҰзқҖеӨ§е®¶дёҖиө·дәҶи§ЈдёҖдёӢгҖӮ
д»ҘдёӢжҳҜPythonзҲ¬иҷ«ж¶үеҸҠзҡ„зӣёе…іеә“
иҜ·жұӮеә“пјҢи§Јжһҗеә“пјҢеӯҳеӮЁеә“пјҢе·Ҙе…·еә“
1гҖҒиҜ·жұӮеә“пјҡurllib/re/requests
пјҲ1пјү urllib/reжҳҜpythonй»ҳи®ӨиҮӘеёҰзҡ„еә“пјҢеҸҜд»ҘйҖҡиҝҮд»ҘдёӢе‘Ҫд»ӨиҝӣиЎҢйӘҢиҜҒпјҡ
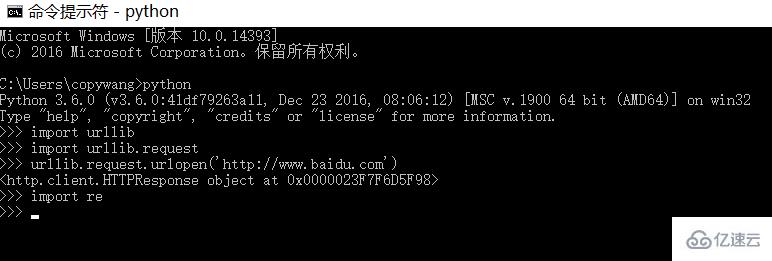
жІЎжңүжҠҘй”ҷдҝЎжҒҜиҫ“еҮәпјҢиҜҙжҳҺзҺҜеўғжӯЈеёё
пјҲ2пјү requestsе®үиЈ…
2.1 жү“ејҖCMDпјҢиҫ“е…Ҙ pip3 install requests
2.2 зӯүеҫ…е®үиЈ…еҗҺпјҢйӘҢиҜҒ

пјҲ3пјү seleniumе®үиЈ…пјҲй©ұеҠЁжөҸи§ҲеҷЁиҝӣиЎҢзҪ‘з«ҷи®ҝй—®иЎҢдёәпјү
3.1 жү“ејҖCMDпјҢиҫ“е…Ҙ pip3 install selenium
3.2 е®үиЈ…chromedriver
зҪ‘еқҖпјҡhttps://npm.taobao.org/
жҠҠдёӢиҪҪе®ҢжҲҗеҗҺзҡ„еҺӢзј©еҢ…и§ЈеҺӢпјҢжҠҠexeж”ҫеҲ°D:\Python3.6.0\Scripts\
иҝҷдёӘи·Ҝеҫ„еҸӘиҰҒеңЁPATHеҸҳйҮҸдёӯе°ұеҸҜд»Ҙ
3.3 зӯүеҫ…е®үиЈ…е®ҢжҲҗеҗҺпјҢйӘҢиҜҒ

еӣһиҪҰеҗҺеј№еҮәchromeжөҸи§ҲеҷЁз•Ңйқў
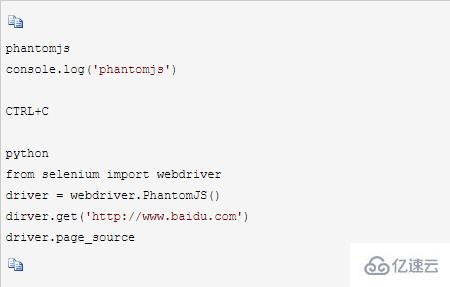
3.4 е®үиЈ…е…¶д»–жөҸи§ҲеҷЁ
ж— з•ҢйқўжөҸи§ҲеҷЁphantomjs
дёӢиҪҪзҪ‘еқҖпјҡhttp://phantomjs.org/
дёӢиҪҪе®ҢжҲҗеҗҺи§ЈеҺӢпјҢжҠҠж•ҙдёӘзӣ®еҪ•ж”ҫеҲ°D:\Python3.6.0\Scripts\пјҢжҠҠbinзӣ®еҪ•зҡ„и·Ҝеҫ„ж·»еҠ еҲ°PATHеҸҳйҮҸ
йӘҢиҜҒпјҡ
жү“ејҖCMD
2. и§Јжһҗеә“пјҡ
2.1 lxml (XPATH)
жү“ејҖCMDиҫ“е…Ҙpip3 install lxmlжҲ–иҖ…д»Һhttps://pypi.python.orgдёӢиҪҪпјҢдҫӢеҰӮпјҢlxml-4.1.1-cp36-cp36m-win_amd64.whl (md5) ,е…ҲдёӢиҪҪwhlж–Ү件пјҢе‘Ҫд»ӨиЎҢжү§иЎҢpip3 install ж–Ү件еҗҚ.whl
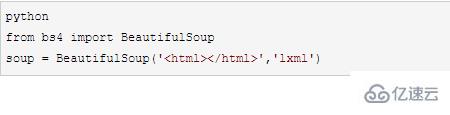
2.2 beautifulsoup
жү“ејҖCMDпјҢйңҖиҰҒе…Ҳе®үиЈ…еҘҪlxml
pip3 install beautifulsoup4
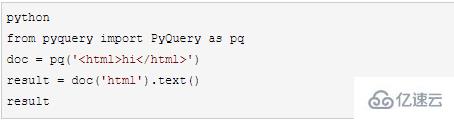
2.3 pyqueryпјҲзұ»дјјjqueryиҜӯжі•пјү
жү“ејҖCMDпјҢpip3 install pyquery
йӘҢиҜҒе®үиЈ…з»“жһң
3. еӯҳеӮЁеә“
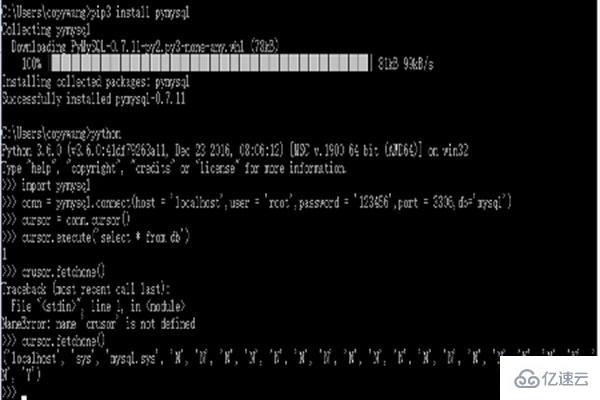
3.1 pymysqlпјҲж“ҚдҪңMySQLпјҢе…ізі»еһӢж•°жҚ®еә“пјү
е®үиЈ…пјҡpip3 install pymysqlпјҢе®үиЈ…еҗҺжөӢиҜ•пјҡ
3.2 pymongoпјҲж“ҚдҪңMongoDBпјҢkey-valueпјү
е®үиЈ… pip3 install pymongo
йӘҢиҜҒ

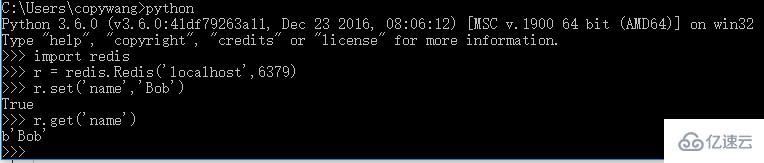
3.3 redisпјҲеҲҶеёғејҸзҲ¬иҷ«пјҢз»ҙжҠӨзҲ¬еҸ–йҳҹеҲ—пјү е®үиЈ…пјҡpip3 install redis
йӘҢиҜҒпјҡ
4.1DjangoпјҲеҲҶеёғејҸзҲ¬иҷ«з»ҙжҠӨзі»з»ҹпјүpip3 install django
4.2jupyterпјҲиҝҗиЎҢеңЁзҪ‘йЎөз«Ҝзҡ„и®°дәӢжң¬пјҢж”ҜжҢҒmarkdownпјҢеҸҜд»ҘеңЁзҪ‘йЎөдёҠиҝҗиЎҢд»Јз Ғпјүе®үиЈ… pip3 install jupyter
йӘҢиҜҒпјҡжү“ејҖCMDпјҢjupyter notebook
д№ӢеҗҺе°ұеҸҜд»ҘеңЁзҪ‘йЎөзӣҙжҺҘеҲӣе»әи®°дәӢжң¬пјҢд»Јз Ғеқ—е’ҢMarkdownеқ—пјҢж”ҜжҢҒжү“еҚ°
ж„ҹи°ўдҪ иғҪеӨҹи®Өзңҹйҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« пјҢеёҢжңӣе°Ҹзј–еҲҶдә«pythonзҲ¬иҷ«ж¶үеҸҠзҡ„зӣёе…іеә“жңүе“ӘдәӣеҶ…е®№еҜ№еӨ§е®¶жңүеё®еҠ©пјҢеҗҢж—¶д№ҹеёҢжңӣеӨ§е®¶еӨҡеӨҡж”ҜжҢҒдәҝйҖҹдә‘пјҢе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢйҒҮеҲ°й—®йўҳе°ұжүҫдәҝйҖҹдә‘пјҢиҜҰз»Ҷзҡ„и§ЈеҶіж–№жі•зӯүзқҖдҪ жқҘеӯҰд№ !
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ