жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« е°ҶдёәеӨ§е®¶иҜҰз»Ҷи®Іи§Јжңүе…іApache Commons ConfigurationиҜ»еҸ–xmlй…ҚзҪ®зҡ„ж–№жі•пјҢе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еҒҡдёӘеҸӮиҖғпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
иҝ‘жңҹйЎ№зӣ®иҮӘе·ұжүӢеҶҷдёҖдёӘеӯ—з¬ҰдёІиҝһжҺҘжұ гҖӮеӣ дёәзҺҜеўғдёҚеҗҢжңүејҖеҸ‘зүҲжң¬гҖҒжөӢиҜ•зүҲжң¬гҖҒдёҠзәҝзүҲжң¬гҖҒжҜҸдёҖдёӘзүҲжң¬з”ЁеҲ°зҡ„ж•°жҚ®еә“д№ҹжҳҜдёҚдёҖж ·зҡ„гҖӮжүҖд»ҘйңҖиҰҒиғҪзҒөжҙ»зҡ„еҲҮжҚўж•°жҚ®еә“иҝһжҺҘгҖӮеҪ“然иҝҷдёӘз”Ёmavenе°ұи§ЈеҶідәҶгҖӮApache Commons Configuration жЎҶжһ¶з”Ёзҡ„дё»иҰҒжҳҜи§Јжһҗж•°жҚ®еә“иҝһжҺҘеӯ—з¬ҰдёІгҖӮ
дёӢйқўд»Ӣз»ҚApache Commons Configuration жЎҶжһ¶зҡ„еёёз”ЁйғЁеҲҶгҖӮ
**
дёӢиҪҪjarеҢ…http://www.php.cn/жҲ–иҖ…http://www.php.cn/ mavenдёӯжҗңзҙўдёӢиҪҪ
з ”з©¶apiзҡ„дҪҝз”ЁгҖӮ
В·еҪ“xmlз»“жһ„еӨ§еҸҳеҢ–зҡ„ж—¶еҖҷдёҚз”ЁиҝҮеӨҡзҡ„дҝ®ж”№и§Јжһҗxmlзҡ„д»Јз Ғ
з”ЁжҲ·еҸӘйңҖиҰҒдҝ®ж”№иҮӘе·ұзҡ„и§ЈжһҗиҜӯжі•ж ‘еҚіеҸҜгҖӮ
е®ўжҲ·еҸӘйңҖиҰҒдҝ®ж”№иҜӯжі•ж ‘жЎҶжһ¶еҺ»и§ЈжһҗпјҢжҖқиҖғзҡ„иө·зӮ№жҳҜдёҚжҳҜи·ҹи®ҫи®ЎжЁЎејҸдёӯзҡ„и§ЈйҮҠеҷЁжЁЎејҸзұ»дјјгҖӮжһ„е»әжҠҪиұЎиҜӯжі•ж ‘е№¶и§ЈйҮҠжү§иЎҢгҖӮ
з”ЁжҲ·еҸӘйңҖиҰҒе…іеҝғе’Ңдҝ®ж”№иҮӘе·ұзҡ„и§ЈжһҗиҜӯжі•ж ‘еҚіеҸҜгҖӮ
з”ЁжҲ·дёҚз”Ёе…ізі»еҰӮдҪ•и§ЈжһҗеҸӘйңҖиҰҒй…ҚзҪ®еҜ№еә”зҡ„и§ЈжһҗиҜӯ法规еҲҷеҚіеҸҜгҖӮ
з®ҖеҢ–зЁӢеәҸxmlй…ҚзҪ®з»“жһ„еҸҳеҢ–еҗҺеӨ§е№…еәҰзҡ„дҝ®ж”№д»Јз ҒгҖӮ
йҰ–е…Ҳе…Ҳй…ҚзҪ®дёҖдёӢMavenгҖӮ
<dependency>
<groupId>commons-configuration</groupId>
<artifactId>commons-configuration</artifactId>
<version>1.8</version>
</dependency>
<dependency>
<groupId>commons-beanutils</groupId>
<artifactId>commons-beanutils</artifactId>
<version>1.8.0</version>
</dependency>
<dependency>
<groupId>commons-jxpath</groupId>
<artifactId>commons-jxpath</artifactId>
<version>1.3</version>
</dependency>е®ҡд№үдёҖдёӘspringok1.xmlеҶ…е®№еҰӮдёӢ 
<?xml version="1.0" encoding="UTF-8"?><!-- springok1.xml --><config>
<database>
<url>127.0.0.1</url>
<port>3306</port>
<login>admin</login>
<password></password>
</database></config>public static void main(String[] args) throws Exception {
XMLConfiguration conf=new XMLConfiguration("springok1.xml");
System.out.println(conf.getString("database.url"));
System.out.println(conf.getString("database.port"));
System.out.println(conf.getString("database.login"));
System.out.println(conf.getString("database.password"));
}иҫ“еҮәеҰӮдёӢ:иҜҙжҳҺе·Із»ҸжҲҗеҠҹи§ЈжһҗxmlдәҶгҖӮ
127.0.0.1
3306
admin
иҺ·еҸ–зҡ„ж–№жі•жңүеҫҲеӨҡз§ҚжӣҙиҜҰз»Ҷзҡ„иҺ·еҸ–ж–№жі•еҸҜд»Ҙд»ҺAbstractConfigurationж–№жі•дёӯеҜ№еә”жүҫеҲ°гҖӮ
дёҠйқўй…ҚзҪ®зҡ„жҳҜдёҖдёӘж•°жҚ®еә“зҡ„иҝһжҺҘдҝЎжҒҜпјҢеҰӮжһңй…ҚзҪ®еҫҲеӨҡж•°жҚ®еә“зҡ„иҝһжҺҘдҝЎжҒҜпјҢжҖҺд№Ҳи§ЈжһҗиҝһжҺҘдҝЎжҒҜеҲҮжҚўе‘ўгҖӮдҝ®ж”№springok1.xmlзҡ„дҝЎжҒҜдёәеӨҡдёӘиҝһжҺҘй…ҚзҪ®еҰӮдёӢпјҡ
<?xml version="1.0" encoding="UTF-8"?><!-- springok1.xml --><config><databases>
<database>
<url>127.0.0.1</url>
<port>3306</port>
<login>admin</login>
<password></password>
</database>
<database>
<url>127.0.0.1</url>
<port>3302</port>
<login>admin</login>
<password>admin</password>
</database></databases></config>зҺ°еңЁеҒҮи®ҫжҲ‘们иҰҒиҺ·еҸ–дёӨдёӘзҡ„й…ҚзҪ®ж•°жҚ®еә“иҝһжҺҘдҝЎжҒҜпјҢзЁӢеәҸеҰӮдёӢпјҡ
public static void main(String[] args) throws Exception {
XMLConfiguration conf=new XMLConfiguration("springok1.xml");
System.out.println(conf.getString("databases.database(0).url"));
System.out.println(conf.getString("databases.database(0).port"));
System.out.println(conf.getString("databases.database(0).login"));
System.out.println(conf.getString("databases.database(0).password"));
System.out.println(conf.getString("databases.database(1).url"));
System.out.println(conf.getString("databases.database(1).port"));
System.out.println(conf.getString("databases.database(1).login"));
System.out.println(conf.getString("databases.database(1).password"));
}иҫ“еҮәпјҡ
127.0.0.1
3306
admin
127.0.0.1
3302
admin
admin
и§Јжһҗok,
з»“еҗҲеүҚйқўзҡ„й…ҚзҪ®ж–Ү件зҡ„дҫӢеӯҗи·ҹе®һжҲҳжҲ‘们еҸ‘зҺ°еӨҡдёӘзӣёеҗҢзҡ„ж Үзӯҫзҡ„иҜқзҙўеј•жҳҜд»Һ0ејҖе§Ӣзҡ„гҖӮ
зӮ№зҡ„и®ҝй—®ж–№ејҸдёҠйқўзҡ„йӮЈз§Қж–№ејҸжҳҜжІЎй—®йўҳпјҢеҜ№дәҺдёҖдәӣеӨҚжқӮзҡ„й…ҚзҪ®жқҘи®ІпјҢжҲ‘们еҸҜиғҪйңҖиҰҒдҪҝз”ЁXPathиЎЁиҫҫејҸиҜӯиЁҖгҖӮиҝҷйҮҢзҡ„дё»иҰҒдјҳзӮ№жҳҜпјҢдҪҝз”ЁдәҶXMLзҡ„й«ҳзә§жҹҘиҜўпјҢзЁӢеәҸзңӢиө·жқҘд»Қ然жҜ”иҫғз®ҖжҙҒжҳ“жҮӮгҖӮеҸҜзҗҶи§ЈжҖ§й«ҳгҖӮ 
иҝҳжҳҜи§ЈжһҗдёҠйқўзҡ„springok.xmlж–Ү件гҖӮд»Јз ҒеҰӮдёӢпјҡ
XMLConfiguration conf=new XMLConfiguration("springok1.xml");
conf.setExpressionEngine(new XPathExpressionEngine());
System.out.println(conf.getString("databases/database[port='3306']/url"));
System.out.println(conf.getString("databases/database[port='3302']/port"));иҫ“еҮәпјҡ
127.0.0.1
3302
жөӢиҜ•ok.
EnvironmentConfiguration conf=new EnvironmentConfiguration();
System.out.println(conf.getMap());жәҗз ҒеҲҶжһҗеҰӮдҪ•е®һзҺ°пјҡ
public EnvironmentConfiguration()
{ super(new HashMap<String, Object>(System.getenv()));
}иҒ”еҗҲдёҖе’Ң2дёӨз§Қж–№ејҸпјҢжҳҜдёҚжҳҜжҲ‘们еҸҜд»ҘеҶҚзі»з»ҹеҸҳйҮҸдёӯе®ҡд№үдёҖдёӘйңҖиҰҒиҝһжҺҘзҡ„ж•°жҚ®еә“еӯ—з¬ҰдёІkeyпјҢи§Јжһҗзҡ„ж—¶еҖҷиҺ·еҸ–еҠЁжҖҒеҠ иҪҪе‘ўпјҹ
public String getDbUrl() throws ConfigurationException {
EnvironmentConfiguration envConfig =new EnvironmentConfiguration(); String env = envConfig.getString("ENV_TYPE"); if("dev".equals(env) ||"production".equals(env)) {
XMLConfiguration xmlConfig =new XMLConfiguration("springok1.xml");
xmlConfig.setExpressionEngine(new XPathExpressionEngine()); String xpath ="databases/database[name = '"+ env +"']/url"; return xmlConfig.getString(xpath);
}else{ String msg ="ENV_TYPE environment variable is "+
"not properly set";
throw new IllegalStateException(msg);
}
}жөӢиҜ•okжІЎй—®йўҳгҖӮ
xmlй…ҚзҪ®еҰӮдёӢеӣҫпјҡ
public String getDbUrl()throws ConfigurationException {
DefaultConfigurationBuilder builder =
new DefaultConfigurationBuilder(вҖңconfig.xmlвҖқ);
boolean load =true;
CombinedConfiguration config = builder.getConfiguration(load);
config.setExpressionEngine(new XPathExpressionEngine());
String env = config.getString(вҖңENV_TYPEвҖқ);
if(вҖңdevвҖқ.equals(env) ||вҖқproductionвҖқ.equals(env)) {
String xpath =вҖқdatabases/database[name = вҖҳвҖқ+ env +вҖқвҖҷ]/urlвҖқ;
return config.getString(xpath);
}else{
String msg =вҖқENV_TYPE environment variable is вҖң+
вҖңnot properly setвҖқ;
throw new IllegalStateException(msg);
}
}
еҪ“еҹәдәҺж–Ү件зҡ„й…ҚзҪ®еҸҳеҢ–зҡ„ж—¶еҖҷиҮӘеҠЁеҠ иҪҪпјҢеӣ дёәжҲ‘们еҸҜд»Ҙи®ҫзҪ®еҠ иҪҪзӯ–з•ҘгҖӮжЎҶжһ¶дјҡиҪ®иҜўй…ҚзҪ®ж–Ү件пјҢеҪ“ж–Ү件зҡ„еҶ…е®№еҸ‘з”ҹж”№еҸҳж—¶пјҢй…ҚзҪ®еҜ№иұЎд№ҹдјҡеҲ·ж–°гҖӮдҪ еҸҜд»Ҙз”ЁзЁӢеәҸжҺ§еҲ¶пјҡ
XMLConfiguration config =new XMLConfiguration("springok1.xml");
ReloadingStrategy strategy =new FileChangedReloadingStrategy();
((FileChangedReloadingStrategy) strategy).setRefreshDelay(5000);
config.setReloadingStrategy(strategy);жҲ–иҖ…й…ҚзҪ®зҡ„ж—¶еҖҷжҺ§еҲ¶пјҡ
<?xmlversion="1.0"encoding="UTF-8"?><!-- config.xml --><configuration>
<env/>
<xmlfileName="const.xml">
<reloadingStrategyrefreshDelay="5000" config-class="org.apache.commons.configuration.reloading.FileChangedReloadingStrategy"/>
</xml></configuration>дёӢйқўжҳҜdomе’Ңsaxж–№ејҸзҡ„жүӢеҠЁи§Јжһҗж–№ејҸеҸҜеҸӮиҖғдҪҝз”ЁгҖӮ
javaиҜӯиЁҖдёӯxmlи§ЈжһҗжңүеҫҲеӨҡз§Қж–№ејҸпјҢжңҖжөҒиЎҢзҡ„ж–№ејҸжңүsaxе’ҢdomдёӨз§ҚгҖӮ
1. domжҳҜжҠҠжүҖжңүзҡ„и§ЈжһҗеҶ…е®№дёҖж¬ЎжҖ§еҠ е…ҘеҶ…еӯҳжүҖд»ҘxmlеҶ…е®№еӨ§зҡ„иҜқжҖ§иғҪдёҚеҘҪгҖӮ
2. saxжҳҜй©ұеҠЁи§ЈжһҗгҖӮжүҖд»ҘеҶ…еӯҳдёҚдјҡеҚ з”ЁеӨӘеӨҡгҖӮ(springз”Ёзҡ„е°ұжҳҜsaxи§Јжһҗж–№ејҸ)
йңҖиҰҒд»Җд№ҲеҢ…иҮӘе·ұеҲ°зҪ‘дёҠжүҫдёӢеҗ§пјҹ
xmlж–Ү件еҰӮдёӢпјҡ
пјң?xml version="1.0" encoding="GB2312"?пјһ пјңRESULTпјһ пјңVALUEпјһ гҖҖгҖҖ пјңNOпјһspringok1пјң/NOпјһ гҖҖгҖҖ пјңADDRпјһspringokпјң/ADDRпјһ пјң/VALUEпјһ пјңVALUEпјһ гҖҖгҖҖ пјңNOпјһspringok2пјң/NOпјһ гҖҖ гҖҖпјңADDRпјһspringokпјң/ADDRпјһ пјң/VALUEпјһ пјң/RESULTпјһ
DOMжҳҜз”ЁдёҺе№іеҸ°е’ҢиҜӯиЁҖж— е…ізҡ„ж–№ејҸиЎЁзӨәXMLж–ҮжЎЈзҡ„е®ҳж–№W3Cж ҮеҮҶгҖӮDOMжҳҜд»ҘеұӮж¬Ўз»“жһ„з»„з»Үзҡ„иҠӮзӮ№жҲ–дҝЎжҒҜзүҮж–ӯзҡ„йӣҶеҗҲгҖӮиҝҷдёӘеұӮж¬Ўз»“жһ„е…Ғи®ёејҖеҸ‘дәәе‘ҳеңЁж ‘дёӯеҜ»жүҫзү№е®ҡдҝЎжҒҜгҖӮеҲҶжһҗиҜҘз»“жһ„йҖҡеёёйңҖиҰҒеҠ иҪҪж•ҙдёӘж–ҮжЎЈе’Ңжһ„йҖ еұӮж¬Ўз»“жһ„пјҢ然еҗҺжүҚиғҪеҒҡд»»дҪ•е·ҘдҪңгҖӮз”ұдәҺе®ғжҳҜеҹәдәҺдҝЎжҒҜеұӮж¬Ўзҡ„пјҢеӣ иҖҢDOMиў«и®ӨдёәжҳҜеҹәдәҺж ‘жҲ–еҹәдәҺеҜ№иұЎзҡ„гҖӮDOMд»ҘеҸҠе№ҝд№үзҡ„еҹәдәҺж ‘зҡ„еӨ„зҗҶе…·жңүеҮ дёӘдјҳзӮ№гҖӮйҰ–е…ҲпјҢз”ұдәҺж ‘еңЁеҶ…еӯҳдёӯжҳҜжҢҒд№…зҡ„пјҢеӣ жӯӨеҸҜд»Ҙдҝ®ж”№е®ғд»Ҙдҫҝеә”з”ЁзЁӢеәҸиғҪеҜ№ж•°жҚ®е’Ңз»“жһ„дҪңеҮәжӣҙж”№гҖӮе®ғиҝҳеҸҜд»ҘеңЁд»»дҪ•ж—¶еҖҷеңЁж ‘дёӯдёҠдёӢеҜјиҲӘпјҢиҖҢдёҚжҳҜеғҸSAXйӮЈж ·жҳҜдёҖж¬ЎжҖ§зҡ„еӨ„зҗҶгҖӮDOMдҪҝз”Ёиө·жқҘд№ҹиҰҒз®ҖеҚ•еҫ—еӨҡгҖӮ
import java.io.*; import java.util.*; import org.w3c.dom.*; import javax.xml.parsers.*; public class MyXMLReader{
гҖҖpublic static void main(String arge[]){
гҖҖгҖҖlong lasting =System.currentTimeMillis(); гҖҖгҖҖtry{
гҖҖгҖҖгҖҖFile f=new File("data_10k.xml"); гҖҖгҖҖгҖҖDocumentBuilderFactory factory=DocumentBuilderFactory.newInstance(); гҖҖгҖҖгҖҖDocumentBuilder builder=factory.newDocumentBuilder(); гҖҖгҖҖгҖҖDocument doc = builder.parse(f); гҖҖгҖҖгҖҖNodeList nl = doc.getElementsByTagName("VALUE"); гҖҖгҖҖгҖҖfor (int i=0;iпјңnl.getLength();i++){ гҖҖгҖҖгҖҖгҖҖSystem.out.print("иҪҰзүҢеҸ·з Ғ:" + doc.getElementsByTagName("NO").item(i).getFirstChild().getNodeValue()); гҖҖгҖҖгҖҖгҖҖSystem.out.println("иҪҰдё»ең°еқҖ:" + doc.getElementsByTagName("ADDR").item(i).getFirstChild().getNodeValue()); гҖҖ гҖҖ}
гҖҖгҖҖ}catch(Exception e){
гҖҖгҖҖгҖҖe.printStackTrace(); }SAXеӨ„зҗҶзҡ„дјҳзӮ№йқһеёёзұ»дјјдәҺжөҒеӘ’дҪ“зҡ„дјҳзӮ№гҖӮеҲҶжһҗиғҪеӨҹз«ӢеҚіејҖе§ӢпјҢиҖҢдёҚжҳҜзӯүеҫ…жүҖжңүзҡ„ж•°жҚ®иў«еӨ„зҗҶгҖӮиҖҢдё”пјҢз”ұдәҺеә”з”ЁзЁӢеәҸеҸӘжҳҜеңЁиҜ»еҸ–ж•°жҚ®ж—¶жЈҖжҹҘж•°жҚ®пјҢеӣ жӯӨдёҚйңҖиҰҒе°Ҷж•°жҚ®еӯҳеӮЁеңЁеҶ…еӯҳдёӯгҖӮиҝҷеҜ№дәҺеӨ§еһӢж–ҮжЎЈжқҘиҜҙжҳҜдёӘе·ЁеӨ§зҡ„дјҳзӮ№гҖӮдәӢе®һдёҠпјҢеә”з”ЁзЁӢеәҸз”ҡиҮідёҚеҝ…и§Јжһҗж•ҙдёӘж–ҮжЎЈпјӣе®ғеҸҜд»ҘеңЁжҹҗдёӘжқЎд»¶еҫ—еҲ°ж»Ўи¶іж—¶еҒңжӯўи§ЈжһҗгҖӮдёҖиҲ¬жқҘиҜҙпјҢSAXиҝҳжҜ”е®ғзҡ„жӣҝд»ЈиҖ…DOMеҝ«и®ёеӨҡгҖӮ йҖүжӢ©DOMиҝҳжҳҜйҖүжӢ©SAXпјҹ еҜ№дәҺйңҖиҰҒиҮӘе·ұзј–еҶҷд»Јз ҒжқҘеӨ„зҗҶXMLж–ҮжЎЈзҡ„ејҖеҸ‘дәәе‘ҳжқҘиҜҙпјҢ йҖүжӢ©DOMиҝҳжҳҜSAXи§ЈжһҗжЁЎеһӢжҳҜдёҖдёӘйқһеёёйҮҚиҰҒзҡ„и®ҫи®ЎеҶізӯ–гҖӮ DOMйҮҮз”Ёе»әз«Ӣж ‘еҪўз»“жһ„зҡ„ж–№ејҸи®ҝй—®XMLж–ҮжЎЈпјҢиҖҢSAXйҮҮз”Ёзҡ„дәӢ件模еһӢгҖӮ DOMи§ЈжһҗеҷЁжҠҠXMLж–ҮжЎЈиҪ¬еҢ–дёәдёҖдёӘеҢ…еҗ«е…¶еҶ…е®№зҡ„ж ‘пјҢ并еҸҜд»ҘеҜ№ж ‘иҝӣиЎҢйҒҚеҺҶгҖӮз”ЁDOMи§ЈжһҗжЁЎеһӢзҡ„дјҳзӮ№жҳҜзј–зЁӢе®№жҳ“пјҢејҖеҸ‘дәәе‘ҳеҸӘйңҖиҰҒи°ғз”Ёе»әж ‘зҡ„жҢҮд»ӨпјҢ然еҗҺеҲ©з”Ёnavigation APIsи®ҝй—®жүҖйңҖзҡ„ж ‘иҠӮзӮ№жқҘе®ҢжҲҗд»»еҠЎгҖӮеҸҜд»ҘеҫҲе®№жҳ“зҡ„ж·»еҠ е’Ңдҝ®ж”№ж ‘дёӯзҡ„е…ғзҙ гҖӮ然иҖҢз”ұдәҺдҪҝз”ЁDOMи§ЈжһҗеҷЁзҡ„ж—¶еҖҷйңҖиҰҒеӨ„зҗҶж•ҙдёӘXMLж–ҮжЎЈпјҢжүҖд»ҘеҜ№жҖ§иғҪе’ҢеҶ…еӯҳзҡ„иҰҒжұӮжҜ”иҫғй«ҳпјҢе°Өе…¶жҳҜйҒҮеҲ°еҫҲеӨ§зҡ„XMLж–Ү件зҡ„ж—¶еҖҷгҖӮз”ұдәҺе®ғзҡ„йҒҚеҺҶиғҪеҠӣпјҢDOMи§ЈжһҗеҷЁеёёз”ЁдәҺXMLж–ҮжЎЈйңҖиҰҒйў‘з№Ғзҡ„ж”№еҸҳзҡ„жңҚеҠЎдёӯгҖӮ SAXи§ЈжһҗеҷЁйҮҮз”ЁдәҶеҹәдәҺдәӢ件зҡ„жЁЎеһӢпјҢе®ғеңЁи§ЈжһҗXMLж–ҮжЎЈзҡ„ж—¶еҖҷеҸҜд»Ҙи§ҰеҸ‘дёҖзі»еҲ—зҡ„дәӢ件пјҢеҪ“еҸ‘зҺ°з»ҷе®ҡзҡ„tagзҡ„ж—¶еҖҷпјҢе®ғеҸҜд»ҘжҝҖжҙ»дёҖдёӘеӣһи°ғж–№жі•пјҢе‘ҠиҜүиҜҘж–№жі•еҲ¶е®ҡзҡ„ж Үзӯҫе·Із»ҸжүҫеҲ°гҖӮSAXеҜ№еҶ…еӯҳзҡ„иҰҒжұӮйҖҡеёёдјҡжҜ”иҫғдҪҺпјҢеӣ дёәе®ғи®©ејҖеҸ‘дәәе‘ҳиҮӘе·ұжқҘеҶіе®ҡжүҖиҰҒеӨ„зҗҶзҡ„tag.зү№еҲ«жҳҜеҪ“ејҖеҸ‘дәәе‘ҳеҸӘйңҖиҰҒеӨ„зҗҶж–ҮжЎЈдёӯжүҖеҢ…еҗ«зҡ„йғЁеҲҶж•°жҚ®ж—¶пјҢSAXиҝҷз§Қжү©еұ•иғҪеҠӣеҫ—еҲ°дәҶжӣҙеҘҪзҡ„дҪ“зҺ°гҖӮдҪҶз”ЁSAXи§ЈжһҗеҷЁзҡ„ж—¶еҖҷзј–з Ғе·ҘдҪңдјҡжҜ”иҫғеӣ°йҡҫпјҢиҖҢдё”еҫҲйҡҫеҗҢж—¶и®ҝй—®еҗҢдёҖдёӘж–ҮжЎЈдёӯзҡ„еӨҡеӨ„дёҚеҗҢж•°жҚ®гҖӮ
import org.xml.sax.*;
import org.xml.sax.helpers.*;
import javax.xml.parsers.*;
public class MyXMLReader extends DefaultHandler { гҖҖjava.util.Stack tags = new java.util.Stack();
гҖҖpublic MyXMLReader() {
гҖҖгҖҖsuper();
}
гҖҖpublic static void main(String args[]) {
гҖҖгҖҖlong lasting = System.currentTimeMillis();
гҖҖгҖҖtry {
гҖҖгҖҖгҖҖSAXParserFactory sf = SAXParserFactory.newInstance();
гҖҖгҖҖгҖҖSAXParser sp = sf.newSAXParser();
гҖҖгҖҖгҖҖMyXMLReader reader = new MyXMLReader();
гҖҖгҖҖгҖҖsp.parse(new InputSource("data_10k.xml"), reader);
гҖҖгҖҖ} catch (Exception e) {
гҖҖгҖҖгҖҖe.printStackTrace();
гҖҖгҖҖ}
гҖҖгҖҖSystem.out.println("иҝҗиЎҢж—¶й—ҙпјҡ" + (System.currentTimeMillis() - lasting) + "жҜ«з§’");}
гҖҖгҖҖpublic void characters(char ch[], int start, int length) throws SAXException {
гҖҖгҖҖString tag = (String) tags.peek();
гҖҖгҖҖif (tag.equals("NO")) {
гҖҖгҖҖгҖҖSystem.out.print("иҪҰзүҢеҸ·з Ғпјҡ" + new String(ch, start, length));
}
if (tag.equals("ADDR")) {
гҖҖгҖҖSystem.out.println("ең°еқҖ:" + new String(ch, start, length));
}
}
гҖҖгҖҖpublic void startElement(String uri,String localName,String qName,Attributes attrs) {
гҖҖгҖҖtags.push(qName);}
}**
жҖ»з»“пјҡдёӘдәәе–ңж¬ўиҝҷдёӘжЎҶжһ¶пјҢж”ҜжҢҒе®ҡж—¶еҲ·ж–°гҖҒxpathгҖҒimportж–№ејҸгҖӮ
иҝ‘жңҹйЎ№зӣ®иҮӘе·ұжүӢеҶҷдёҖдёӘеӯ—з¬ҰдёІиҝһжҺҘжұ гҖӮеӣ дёәзҺҜеўғдёҚеҗҢжңүејҖеҸ‘зүҲжң¬гҖҒжөӢиҜ•зүҲжң¬гҖҒдёҠзәҝзүҲжң¬гҖҒжҜҸдёҖдёӘзүҲжң¬з”ЁеҲ°зҡ„ж•°жҚ®еә“д№ҹжҳҜдёҚдёҖж ·зҡ„гҖӮжүҖд»ҘйңҖиҰҒиғҪзҒөжҙ»зҡ„еҲҮжҚўж•°жҚ®еә“иҝһжҺҘгҖӮеҪ“然иҝҷдёӘз”Ёmavenе°ұи§ЈеҶідәҶгҖӮApache Commons Configuration жЎҶжһ¶з”Ёзҡ„дё»иҰҒжҳҜи§Јжһҗж•°жҚ®еә“иҝһжҺҘеӯ—з¬ҰдёІгҖӮ
дёӢйқўд»Ӣз»ҚApache Commons Configuration жЎҶжһ¶зҡ„еёёз”ЁйғЁеҲҶгҖӮ
**
дёӢиҪҪjarеҢ…http://www.php.cn/жҲ–иҖ…http://www.php.cn/ mavenдёӯжҗңзҙўдёӢиҪҪ
з ”з©¶apiзҡ„дҪҝз”ЁгҖӮ
В·еҪ“xmlз»“жһ„еӨ§еҸҳеҢ–зҡ„ж—¶еҖҷдёҚз”ЁиҝҮеӨҡзҡ„дҝ®ж”№и§Јжһҗxmlзҡ„д»Јз Ғ
з”ЁжҲ·еҸӘйңҖиҰҒдҝ®ж”№иҮӘе·ұзҡ„и§ЈжһҗиҜӯжі•ж ‘еҚіеҸҜгҖӮ
е®ўжҲ·еҸӘйңҖиҰҒдҝ®ж”№иҜӯжі•ж ‘жЎҶжһ¶еҺ»и§ЈжһҗпјҢжҖқиҖғзҡ„иө·зӮ№жҳҜдёҚжҳҜи·ҹи®ҫи®ЎжЁЎејҸдёӯзҡ„и§ЈйҮҠеҷЁжЁЎејҸзұ»дјјгҖӮжһ„е»әжҠҪиұЎиҜӯжі•ж ‘е№¶и§ЈйҮҠжү§иЎҢгҖӮ
з”ЁжҲ·еҸӘйңҖиҰҒе…іеҝғе’Ңдҝ®ж”№иҮӘе·ұзҡ„и§ЈжһҗиҜӯжі•ж ‘еҚіеҸҜгҖӮ
з”ЁжҲ·дёҚз”Ёе…ізі»еҰӮдҪ•и§ЈжһҗеҸӘйңҖиҰҒй…ҚзҪ®еҜ№еә”зҡ„и§ЈжһҗиҜӯ法规еҲҷеҚіеҸҜгҖӮ
з®ҖеҢ–зЁӢеәҸxmlй…ҚзҪ®з»“жһ„еҸҳеҢ–еҗҺеӨ§е№…еәҰзҡ„дҝ®ж”№д»Јз ҒгҖӮ
йҰ–е…Ҳе…Ҳй…ҚзҪ®дёҖдёӢMavenгҖӮ
<dependency>
<groupId>commons-configuration</groupId>
<artifactId>commons-configuration</artifactId>
<version>1.8</version>
</dependency>
<dependency>
<groupId>commons-beanutils</groupId>
<artifactId>commons-beanutils</artifactId>
<version>1.8.0</version>
</dependency>
<dependency>
<groupId>commons-jxpath</groupId>
<artifactId>commons-jxpath</artifactId>
<version>1.3</version>
</dependency>е®ҡд№үдёҖдёӘspringok1.xmlеҶ…е®№еҰӮдёӢ
<?xml version="1.0" encoding="UTF-8"?><!-- springok1.xml --><config>
<database>
<url>127.0.0.1</url>
<port>3306</port>
<login>admin</login>
<password></password>
</database></config>public static void main(String[] args) throws Exception {
XMLConfiguration conf=new XMLConfiguration("springok1.xml");
System.out.println(conf.getString("database.url"));
System.out.println(conf.getString("database.port"));
System.out.println(conf.getString("database.login"));
System.out.println(conf.getString("database.password"));
}иҫ“еҮәеҰӮдёӢ:иҜҙжҳҺе·Із»ҸжҲҗеҠҹи§ЈжһҗxmlдәҶгҖӮ
127.0.0.1
3306
admin
иҺ·еҸ–зҡ„ж–№жі•жңүеҫҲеӨҡз§ҚжӣҙиҜҰз»Ҷзҡ„иҺ·еҸ–ж–№жі•еҸҜд»Ҙд»ҺAbstractConfigurationж–№жі•дёӯеҜ№еә”жүҫеҲ°гҖӮ
дёҠйқўй…ҚзҪ®зҡ„жҳҜдёҖдёӘж•°жҚ®еә“зҡ„иҝһжҺҘдҝЎжҒҜпјҢеҰӮжһңй…ҚзҪ®еҫҲеӨҡж•°жҚ®еә“зҡ„иҝһжҺҘдҝЎжҒҜпјҢжҖҺд№Ҳи§ЈжһҗиҝһжҺҘдҝЎжҒҜеҲҮжҚўе‘ўгҖӮдҝ®ж”№springok1.xmlзҡ„дҝЎжҒҜдёәеӨҡдёӘиҝһжҺҘй…ҚзҪ®еҰӮдёӢпјҡ
<?xml version="1.0" encoding="UTF-8"?><!-- springok1.xml --><config><databases>
<database>
<url>127.0.0.1</url>
<port>3306</port>
<login>admin</login>
<password></password>
</database>
<database>
<url>127.0.0.1</url>
<port>3302</port>
<login>admin</login>
<password>admin</password>
</database></databases></config>зҺ°еңЁеҒҮи®ҫжҲ‘们иҰҒиҺ·еҸ–дёӨдёӘзҡ„й…ҚзҪ®ж•°жҚ®еә“иҝһжҺҘдҝЎжҒҜпјҢзЁӢеәҸеҰӮдёӢпјҡ
public static void main(String[] args) throws Exception {
XMLConfiguration conf=new XMLConfiguration("springok1.xml");
System.out.println(conf.getString("databases.database(0).url"));
System.out.println(conf.getString("databases.database(0).port"));
System.out.println(conf.getString("databases.database(0).login"));
System.out.println(conf.getString("databases.database(0).password"));
System.out.println(conf.getString("databases.database(1).url"));
System.out.println(conf.getString("databases.database(1).port"));
System.out.println(conf.getString("databases.database(1).login"));
System.out.println(conf.getString("databases.database(1).password"));
}иҫ“еҮәпјҡ
127.0.0.1
3306
admin
127.0.0.1
3302
admin
admin
и§Јжһҗok,
з»“еҗҲеүҚйқўзҡ„й…ҚзҪ®ж–Ү件зҡ„дҫӢеӯҗи·ҹе®һжҲҳжҲ‘们еҸ‘зҺ°еӨҡдёӘзӣёеҗҢзҡ„ж Үзӯҫзҡ„иҜқзҙўеј•жҳҜд»Һ0ејҖе§Ӣзҡ„гҖӮ
зӮ№зҡ„и®ҝй—®ж–№ејҸдёҠйқўзҡ„йӮЈз§Қж–№ејҸжҳҜжІЎй—®йўҳпјҢеҜ№дәҺдёҖдәӣеӨҚжқӮзҡ„й…ҚзҪ®жқҘи®ІпјҢжҲ‘们еҸҜиғҪйңҖиҰҒдҪҝз”ЁXPathиЎЁиҫҫејҸиҜӯиЁҖгҖӮиҝҷйҮҢзҡ„дё»иҰҒдјҳзӮ№жҳҜпјҢдҪҝз”ЁдәҶXMLзҡ„й«ҳзә§жҹҘиҜўпјҢзЁӢеәҸзңӢиө·жқҘд»Қ然жҜ”иҫғз®ҖжҙҒжҳ“жҮӮгҖӮеҸҜзҗҶи§ЈжҖ§й«ҳгҖӮ
иҝҳжҳҜи§ЈжһҗдёҠйқўзҡ„springok.xmlж–Ү件гҖӮд»Јз ҒеҰӮдёӢпјҡ
XMLConfiguration conf=new XMLConfiguration("springok1.xml");
conf.setExpressionEngine(new XPathExpressionEngine());
System.out.println(conf.getString("databases/database[port='3306']/url"));
System.out.println(conf.getString("databases/database[port='3302']/port"));иҫ“еҮәпјҡ
127.0.0.1
3302
жөӢиҜ•ok.
EnvironmentConfiguration conf=new EnvironmentConfiguration();
System.out.println(conf.getMap());жәҗз ҒеҲҶжһҗеҰӮдҪ•е®һзҺ°пјҡ
public EnvironmentConfiguration()
{ super(new HashMap<String, Object>(System.getenv()));
}иҒ”еҗҲдёҖе’Ң2дёӨз§Қж–№ејҸпјҢжҳҜдёҚжҳҜжҲ‘们еҸҜд»ҘеҶҚзі»з»ҹеҸҳйҮҸдёӯе®ҡд№үдёҖдёӘйңҖиҰҒиҝһжҺҘзҡ„ж•°жҚ®еә“еӯ—з¬ҰдёІkeyпјҢи§Јжһҗзҡ„ж—¶еҖҷиҺ·еҸ–еҠЁжҖҒеҠ иҪҪе‘ўпјҹ
public String getDbUrl() throws ConfigurationException {
EnvironmentConfiguration envConfig =new EnvironmentConfiguration(); String env = envConfig.getString("ENV_TYPE"); if("dev".equals(env) ||"production".equals(env)) {
XMLConfiguration xmlConfig =new XMLConfiguration("springok1.xml");
xmlConfig.setExpressionEngine(new XPathExpressionEngine()); String xpath ="databases/database[name = '"+ env +"']/url"; return xmlConfig.getString(xpath);
}else{ String msg ="ENV_TYPE environment variable is "+
"not properly set";
throw new IllegalStateException(msg);
}
}жөӢиҜ•okжІЎй—®йўҳгҖӮ
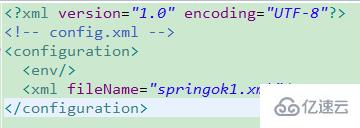
xmlй…ҚзҪ®еҰӮдёӢеӣҫпјҡ
public String getDbUrl()throws ConfigurationException {
DefaultConfigurationBuilder builder =
new DefaultConfigurationBuilder(вҖңconfig.xmlвҖқ);
boolean load =true;
CombinedConfiguration config = builder.getConfiguration(load);
config.setExpressionEngine(new XPathExpressionEngine());
String env = config.getString(вҖңENV_TYPEвҖқ);
if(вҖңdevвҖқ.equals(env) ||вҖқproductionвҖқ.equals(env)) {
String xpath =вҖқdatabases/database[name = вҖҳвҖқ+ env +вҖқвҖҷ]/urlвҖқ;
return config.getString(xpath);
}else{
String msg =вҖқENV_TYPE environment variable is вҖң+
вҖңnot properly setвҖқ;
throw new IllegalStateException(msg);
}
}
еҪ“еҹәдәҺж–Ү件зҡ„й…ҚзҪ®еҸҳеҢ–зҡ„ж—¶еҖҷиҮӘеҠЁеҠ иҪҪпјҢеӣ дёәжҲ‘们еҸҜд»Ҙи®ҫзҪ®еҠ иҪҪзӯ–з•ҘгҖӮжЎҶжһ¶дјҡиҪ®иҜўй…ҚзҪ®ж–Ү件пјҢеҪ“ж–Ү件зҡ„еҶ…е®№еҸ‘з”ҹж”№еҸҳж—¶пјҢй…ҚзҪ®еҜ№иұЎд№ҹдјҡеҲ·ж–°гҖӮдҪ еҸҜд»Ҙз”ЁзЁӢеәҸжҺ§еҲ¶пјҡ
XMLConfiguration config =new XMLConfiguration("springok1.xml");
ReloadingStrategy strategy =new FileChangedReloadingStrategy();
((FileChangedReloadingStrategy) strategy).setRefreshDelay(5000);
config.setReloadingStrategy(strategy);жҲ–иҖ…й…ҚзҪ®зҡ„ж—¶еҖҷжҺ§еҲ¶пјҡ
<?xmlversion="1.0"encoding="UTF-8"?><!-- config.xml --><configuration>
<env/>
<xmlfileName="const.xml">
<reloadingStrategyrefreshDelay="5000" config-class="org.apache.commons.configuration.reloading.FileChangedReloadingStrategy"/>
</xml></configuration>дёӢйқўжҳҜdomе’Ңsaxж–№ејҸзҡ„жүӢеҠЁи§Јжһҗж–№ејҸеҸҜеҸӮиҖғдҪҝз”ЁгҖӮ
javaиҜӯиЁҖдёӯxmlи§ЈжһҗжңүеҫҲеӨҡз§Қж–№ејҸпјҢжңҖжөҒиЎҢзҡ„ж–№ејҸжңүsaxе’ҢdomдёӨз§ҚгҖӮ
1. domжҳҜжҠҠжүҖжңүзҡ„и§ЈжһҗеҶ…е®№дёҖж¬ЎжҖ§еҠ е…ҘеҶ…еӯҳжүҖд»ҘxmlеҶ…е®№еӨ§зҡ„иҜқжҖ§иғҪдёҚеҘҪгҖӮ
2. saxжҳҜй©ұеҠЁи§ЈжһҗгҖӮжүҖд»ҘеҶ…еӯҳдёҚдјҡеҚ з”ЁеӨӘеӨҡгҖӮ(springз”Ёзҡ„е°ұжҳҜsaxи§Јжһҗж–№ејҸ)
йңҖиҰҒд»Җд№ҲеҢ…иҮӘе·ұеҲ°зҪ‘дёҠжүҫдёӢеҗ§пјҹ
xmlж–Ү件еҰӮдёӢпјҡ
пјң?xml version="1.0" encoding="GB2312"?пјһ пјңRESULTпјһ пјңVALUEпјһ гҖҖгҖҖ пјңNOпјһspringok1пјң/NOпјһ гҖҖгҖҖ пјңADDRпјһspringokпјң/ADDRпјһ пјң/VALUEпјһ пјңVALUEпјһ гҖҖгҖҖ пјңNOпјһspringok2пјң/NOпјһ гҖҖ гҖҖпјңADDRпјһspringokпјң/ADDRпјһ пјң/VALUEпјһ пјң/RESULTпјһ
DOMжҳҜз”ЁдёҺе№іеҸ°е’ҢиҜӯиЁҖж— е…ізҡ„ж–№ејҸиЎЁзӨәXMLж–ҮжЎЈзҡ„е®ҳж–№W3Cж ҮеҮҶгҖӮDOMжҳҜд»ҘеұӮж¬Ўз»“жһ„з»„з»Үзҡ„иҠӮзӮ№жҲ–дҝЎжҒҜзүҮж–ӯзҡ„йӣҶеҗҲгҖӮиҝҷдёӘеұӮж¬Ўз»“жһ„е…Ғи®ёејҖеҸ‘дәәе‘ҳеңЁж ‘дёӯеҜ»жүҫзү№е®ҡдҝЎжҒҜгҖӮеҲҶжһҗиҜҘз»“жһ„йҖҡеёёйңҖиҰҒеҠ иҪҪж•ҙдёӘж–ҮжЎЈе’Ңжһ„йҖ еұӮж¬Ўз»“жһ„пјҢ然еҗҺжүҚиғҪеҒҡд»»дҪ•е·ҘдҪңгҖӮз”ұдәҺе®ғжҳҜеҹәдәҺдҝЎжҒҜеұӮж¬Ўзҡ„пјҢеӣ иҖҢDOMиў«и®ӨдёәжҳҜеҹәдәҺж ‘жҲ–еҹәдәҺеҜ№иұЎзҡ„гҖӮDOMд»ҘеҸҠе№ҝд№үзҡ„еҹәдәҺж ‘зҡ„еӨ„зҗҶе…·жңүеҮ дёӘдјҳзӮ№гҖӮйҰ–е…ҲпјҢз”ұдәҺж ‘еңЁеҶ…еӯҳдёӯжҳҜжҢҒд№…зҡ„пјҢеӣ жӯӨеҸҜд»Ҙдҝ®ж”№е®ғд»Ҙдҫҝеә”з”ЁзЁӢеәҸиғҪеҜ№ж•°жҚ®е’Ңз»“жһ„дҪңеҮәжӣҙж”№гҖӮе®ғиҝҳеҸҜд»ҘеңЁд»»дҪ•ж—¶еҖҷеңЁж ‘дёӯдёҠдёӢеҜјиҲӘпјҢиҖҢдёҚжҳҜеғҸSAXйӮЈж ·жҳҜдёҖж¬ЎжҖ§зҡ„еӨ„зҗҶгҖӮDOMдҪҝз”Ёиө·жқҘд№ҹиҰҒз®ҖеҚ•еҫ—еӨҡгҖӮ
import java.io.*; import java.util.*; import org.w3c.dom.*; import javax.xml.parsers.*; public class MyXMLReader{
гҖҖpublic static void main(String arge[]){
гҖҖгҖҖlong lasting =System.currentTimeMillis(); гҖҖгҖҖtry{
гҖҖгҖҖгҖҖFile f=new File("data_10k.xml"); гҖҖгҖҖгҖҖDocumentBuilderFactory factory=DocumentBuilderFactory.newInstance(); гҖҖгҖҖгҖҖDocumentBuilder builder=factory.newDocumentBuilder(); гҖҖгҖҖгҖҖDocument doc = builder.parse(f); гҖҖгҖҖгҖҖNodeList nl = doc.getElementsByTagName("VALUE"); гҖҖгҖҖгҖҖfor (int i=0;iпјңnl.getLength();i++){ гҖҖгҖҖгҖҖгҖҖSystem.out.print("иҪҰзүҢеҸ·з Ғ:" + doc.getElementsByTagName("NO").item(i).getFirstChild().getNodeValue()); гҖҖгҖҖгҖҖгҖҖSystem.out.println("иҪҰдё»ең°еқҖ:" + doc.getElementsByTagName("ADDR").item(i).getFirstChild().getNodeValue()); гҖҖ гҖҖ}
гҖҖгҖҖ}catch(Exception e){
гҖҖгҖҖгҖҖe.printStackTrace(); }SAXеӨ„зҗҶзҡ„дјҳзӮ№йқһеёёзұ»дјјдәҺжөҒеӘ’дҪ“зҡ„дјҳзӮ№гҖӮеҲҶжһҗиғҪеӨҹз«ӢеҚіејҖе§ӢпјҢиҖҢдёҚжҳҜзӯүеҫ…жүҖжңүзҡ„ж•°жҚ®иў«еӨ„зҗҶгҖӮиҖҢдё”пјҢз”ұдәҺеә”з”ЁзЁӢеәҸеҸӘжҳҜеңЁиҜ»еҸ–ж•°жҚ®ж—¶жЈҖжҹҘж•°жҚ®пјҢеӣ жӯӨдёҚйңҖиҰҒе°Ҷж•°жҚ®еӯҳеӮЁеңЁеҶ…еӯҳдёӯгҖӮиҝҷеҜ№дәҺеӨ§еһӢж–ҮжЎЈжқҘиҜҙжҳҜдёӘе·ЁеӨ§зҡ„дјҳзӮ№гҖӮдәӢе®һдёҠпјҢеә”з”ЁзЁӢеәҸз”ҡиҮідёҚеҝ…и§Јжһҗж•ҙдёӘж–ҮжЎЈпјӣе®ғеҸҜд»ҘеңЁжҹҗдёӘжқЎд»¶еҫ—еҲ°ж»Ўи¶іж—¶еҒңжӯўи§ЈжһҗгҖӮдёҖиҲ¬жқҘиҜҙпјҢSAXиҝҳжҜ”е®ғзҡ„жӣҝд»ЈиҖ…DOMеҝ«и®ёеӨҡгҖӮ йҖүжӢ©DOMиҝҳжҳҜйҖүжӢ©SAXпјҹ еҜ№дәҺйңҖиҰҒиҮӘе·ұзј–еҶҷд»Јз ҒжқҘеӨ„зҗҶXMLж–ҮжЎЈзҡ„ејҖеҸ‘дәәе‘ҳжқҘиҜҙпјҢ йҖүжӢ©DOMиҝҳжҳҜSAXи§ЈжһҗжЁЎеһӢжҳҜдёҖдёӘйқһеёёйҮҚиҰҒзҡ„и®ҫи®ЎеҶізӯ–гҖӮ DOMйҮҮз”Ёе»әз«Ӣж ‘еҪўз»“жһ„зҡ„ж–№ејҸи®ҝй—®XMLж–ҮжЎЈпјҢиҖҢSAXйҮҮз”Ёзҡ„дәӢ件模еһӢгҖӮ DOMи§ЈжһҗеҷЁжҠҠXMLж–ҮжЎЈиҪ¬еҢ–дёәдёҖдёӘеҢ…еҗ«е…¶еҶ…е®№зҡ„ж ‘пјҢ并еҸҜд»ҘеҜ№ж ‘иҝӣиЎҢйҒҚеҺҶгҖӮз”ЁDOMи§ЈжһҗжЁЎеһӢзҡ„дјҳзӮ№жҳҜзј–зЁӢе®№жҳ“пјҢејҖеҸ‘дәәе‘ҳеҸӘйңҖиҰҒи°ғз”Ёе»әж ‘зҡ„жҢҮд»ӨпјҢ然еҗҺеҲ©з”Ёnavigation APIsи®ҝй—®жүҖйңҖзҡ„ж ‘иҠӮзӮ№жқҘе®ҢжҲҗд»»еҠЎгҖӮеҸҜд»ҘеҫҲе®№жҳ“зҡ„ж·»еҠ е’Ңдҝ®ж”№ж ‘дёӯзҡ„е…ғзҙ гҖӮ然иҖҢз”ұдәҺдҪҝз”ЁDOMи§ЈжһҗеҷЁзҡ„ж—¶еҖҷйңҖиҰҒеӨ„зҗҶж•ҙдёӘXMLж–ҮжЎЈпјҢжүҖд»ҘеҜ№жҖ§иғҪе’ҢеҶ…еӯҳзҡ„иҰҒжұӮжҜ”иҫғй«ҳпјҢе°Өе…¶жҳҜйҒҮеҲ°еҫҲеӨ§зҡ„XMLж–Ү件зҡ„ж—¶еҖҷгҖӮз”ұдәҺе®ғзҡ„йҒҚеҺҶиғҪеҠӣпјҢDOMи§ЈжһҗеҷЁеёёз”ЁдәҺXMLж–ҮжЎЈйңҖиҰҒйў‘з№Ғзҡ„ж”№еҸҳзҡ„жңҚеҠЎдёӯгҖӮ SAXи§ЈжһҗеҷЁйҮҮз”ЁдәҶеҹәдәҺдәӢ件зҡ„жЁЎеһӢпјҢе®ғеңЁи§ЈжһҗXMLж–ҮжЎЈзҡ„ж—¶еҖҷеҸҜд»Ҙи§ҰеҸ‘дёҖзі»еҲ—зҡ„дәӢ件пјҢеҪ“еҸ‘зҺ°з»ҷе®ҡзҡ„tagзҡ„ж—¶еҖҷпјҢе®ғеҸҜд»ҘжҝҖжҙ»дёҖдёӘеӣһи°ғж–№жі•пјҢе‘ҠиҜүиҜҘж–№жі•еҲ¶е®ҡзҡ„ж Үзӯҫе·Із»ҸжүҫеҲ°гҖӮSAXеҜ№еҶ…еӯҳзҡ„иҰҒжұӮйҖҡеёёдјҡжҜ”иҫғдҪҺпјҢеӣ дёәе®ғи®©ејҖеҸ‘дәәе‘ҳиҮӘе·ұжқҘеҶіе®ҡжүҖиҰҒеӨ„зҗҶзҡ„tag.зү№еҲ«жҳҜеҪ“ејҖеҸ‘дәәе‘ҳеҸӘйңҖиҰҒеӨ„зҗҶж–ҮжЎЈдёӯжүҖеҢ…еҗ«зҡ„йғЁеҲҶж•°жҚ®ж—¶пјҢSAXиҝҷз§Қжү©еұ•иғҪеҠӣеҫ—еҲ°дәҶжӣҙеҘҪзҡ„дҪ“зҺ°гҖӮдҪҶз”ЁSAXи§ЈжһҗеҷЁзҡ„ж—¶еҖҷзј–з Ғе·ҘдҪңдјҡжҜ”иҫғеӣ°йҡҫпјҢиҖҢдё”еҫҲйҡҫеҗҢж—¶и®ҝй—®еҗҢдёҖдёӘж–ҮжЎЈдёӯзҡ„еӨҡеӨ„дёҚеҗҢж•°жҚ®гҖӮ
import org.xml.sax.*;
import org.xml.sax.helpers.*;
import javax.xml.parsers.*;
public class MyXMLReader extends DefaultHandler { гҖҖjava.util.Stack tags = new java.util.Stack();
гҖҖpublic MyXMLReader() {
гҖҖгҖҖsuper();
}
гҖҖpublic static void main(String args[]) {
гҖҖгҖҖlong lasting = System.currentTimeMillis();
гҖҖгҖҖtry {
гҖҖгҖҖгҖҖSAXParserFactory sf = SAXParserFactory.newInstance();
гҖҖгҖҖгҖҖSAXParser sp = sf.newSAXParser();
гҖҖгҖҖгҖҖMyXMLReader reader = new MyXMLReader();
гҖҖгҖҖгҖҖsp.parse(new InputSource("data_10k.xml"), reader);
гҖҖгҖҖ} catch (Exception e) {
гҖҖгҖҖгҖҖe.printStackTrace();
гҖҖгҖҖ}
гҖҖгҖҖSystem.out.println("иҝҗиЎҢж—¶й—ҙпјҡ" + (System.currentTimeMillis() - lasting) + "жҜ«з§’");}
гҖҖгҖҖpublic void characters(char ch[], int start, int length) throws SAXException {
гҖҖгҖҖString tag = (String) tags.peek();
гҖҖгҖҖif (tag.equals("NO")) {
гҖҖгҖҖгҖҖSystem.out.print("иҪҰзүҢеҸ·з Ғпјҡ" + new String(ch, start, length));
}
if (tag.equals("ADDR")) {
гҖҖгҖҖSystem.out.println("ең°еқҖ:" + new String(ch, start, length));
}
}
гҖҖгҖҖpublic void startElement(String uri,String localName,String qName,Attributes attrs) {
гҖҖгҖҖtags.push(qName);}
}е…ідәҺApache Commons ConfigurationиҜ»еҸ–xmlй…ҚзҪ®зҡ„ж–№жі•е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢеҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶгҖӮеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢеҸҜд»ҘжҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ