жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
jmeterи„ҡжң¬еҢ…еҗ«еҫҲеӨҡиҜ·жұӮпјҢиҖҢиҜ·жұӮд№Ӣй—ҙеҫҲеҸҜиғҪеӯҳеңЁжҹҗз§Қе…іиҒ”гҖӮе…іиҒ”еҚідёәдёҠдёӢж–Үд№Ӣй—ҙзҡ„иҝһжҺҘпјҢйҖҡиҝҮеүҚйқўиҜ·жұӮеҫ—еҲ°зҡ„е“Қеә”пјҢдҪңдёәеҗҺж–Үзҡ„иҫ“е…ҘпјҢд»ҘжӯӨж №жҚ®еүҚж–ҮдёҚеҗҢзҡ„е“Қеә”пјҢеҒҡеҮәдёҚеҗҢзҡ„еӨ„зҗҶгҖӮ
жҜ”еҰӮзҷ»еҪ•пјҢзҷ»еҪ•ж—¶иҺ·еҸ–зҡ„tokenпјҢеҸҜйҖҡиҝҮе…іиҒ”иҺ·еҸ–еҫ—еҲ°пјҢеҗҺйқўзҡ„еҗ„з§ҚиҜ·жұӮйғҪйңҖиҰҒд»ҘиҜҘtokenдҪңдёәеҸӮж•°дј йҖҒпјҢжүҚиғҪжӯЈеёёи®ҝй—®йЎөйқўиө„жәҗгҖӮ
jmeterе…іиҒ”зҡ„ж–№ејҸжңүдёүз§ҚпјҢеҲҶеҲ«жҳҜжӯЈеҲҷиЎЁиҫҫејҸжҸҗеҸ–еҷЁпјҢXpath Extractorе’ҢJSON ExtractorгҖӮ
еңЁеҸ–ж ·еҷЁпјҲеҰӮHTTPиҜ·жұӮпјүпјҢйҖүжӢ©еҗҺзҪ®еӨ„зҗҶеҷЁвҖ”вҖ”жӯЈеҲҷиЎЁиҫҫејҸжҸҗеҸ–еҷЁпјҢеҚіеҸҜдҪҝз”ЁгҖӮ
дёӢйқўд»ҘжҸҗеҸ–еҲқе§ӢtokenдёәдҫӢпјҢи®Іиҝ°дёӢеҰӮдҪ•жҸҗеҸ–жүҖйңҖдҝЎжҒҜгҖӮ
е…Ҳж·»еҠ дёҖдёӘHTTPиҜ·жұӮ
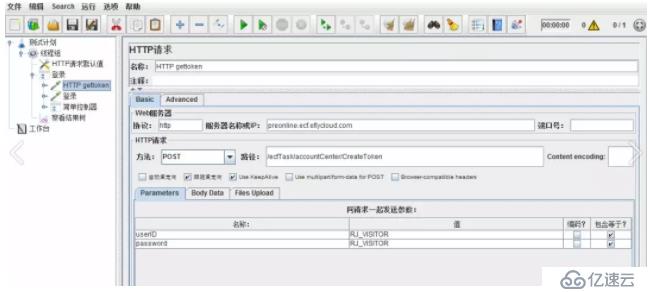
зӮ№еҮ»иҝҗиЎҢпјҢеңЁз»“жһңж ‘дёӯжҹҘзңӢе“Қеә”дҝЎжҒҜгҖӮжң¬дҫӢпјҢжҲ‘们йңҖиҰҒжҸҗеҸ–зҡ„жҳҜdataзҡ„еҖјпјҢдҪңдёәtoken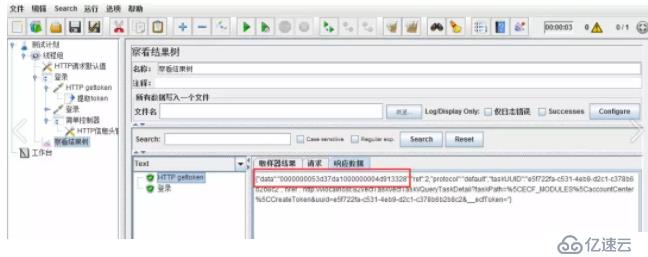
еңЁHTTP gettokenзҡ„иҜ·жұӮдёӯпјҢж·»еҠ жӯЈеҲҷиЎЁиҫҫејҸжҸҗеҸ–еҷЁпјҢеЎ«е…ҘеҰӮдёӢдҝЎжҒҜгҖӮ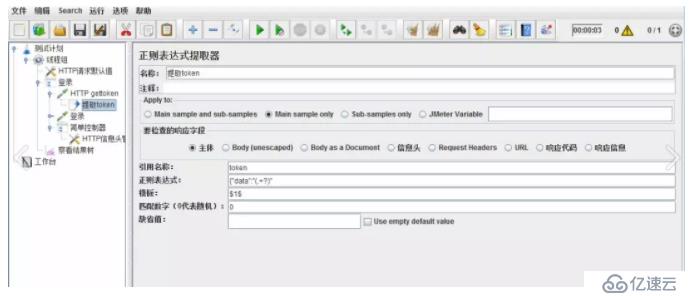
и§ЈйҮҠпјҡ
пјҲ1пјүеј•з”ЁеҗҚз§°пјҡдёӢдёҖдёӘиҜ·жұӮиҰҒеј•з”Ёзҡ„еҸӮж•°еҗҚз§°пјҢеҰӮеЎ«еҶҷtokenпјҢеҲҷеҸҜз”Ё${token}еј•з”Ёе®ғгҖӮ
пјҲ2пјүжӯЈеҲҷиЎЁиҫҫејҸпјҡ()жӢ¬иө·жқҘзҡ„йғЁеҲҶе°ұжҳҜиҰҒжҸҗеҸ–зҡ„гҖӮжӯӨйғЁеҲҶйңҖдәҶи§ЈжӯЈеҲҷиЎЁиҫҫејҸзҡ„ж–№жі•пјҢеңЁжӯӨдёҚз»ҶиҜҙгҖӮ
пјҲ3пјүжЁЎжқҝпјҡз”Ё$$еј•з”Ёиө·жқҘпјҢеҰӮжһңеңЁжӯЈеҲҷиЎЁиҫҫејҸдёӯжңүеӨҡдёӘжӯЈеҲҷиЎЁиҫҫејҸпјҲз”ұеӨҡдёӘжӢ¬еҸ·жҸҗеҸ–пјүпјҢеҰӮ$2$пјҢиЎЁзӨәи§ЈжһҗеҲ°зҡ„第2дёӘеҖјпјҢ$1$иЎЁзӨәи§ЈжһҗеҲ°зҡ„第1дёӘеҖјгҖӮ
пјҲ4пјүеҢ№й…Қж•°еӯ—пјҡ0д»ЈиЎЁйҡҸжңәеҸ–еҖјпјҢ1д»ЈиЎЁе…ЁйғЁеҸ–еҖјпјҢйҖҡеёёжғ…еҶөдёӢеЎ«0гҖӮ
пјҲ5пјүзјәзңҒеҖјпјҡеҰӮжһңеҸӮж•°жІЎжңүеҸ–еҫ—еҲ°еҖјпјҢйӮЈй»ҳи®Өз»ҷдёҖдёӘеҖји®©е®ғеҸ–гҖӮ
ж·»еҠ дёҖдёӘж–°зҡ„иҜ·жұӮпјҢиҜҘиҜ·жұӮеҸҜиҺ·еҸ–дёҠйқўзҡ„еҖјдҪңдёәtokenгҖӮеј•з”Ёж јејҸдёә{token_g1}гҖӮg1иЎЁзӨәжҸҗеҸ–зҡ„第дёҖдёӘеҖјпјҲеҰӮжңүеӨҡдёӘtokenпјҢg2иЎЁзӨә第дәҢдёӘпјүгҖӮ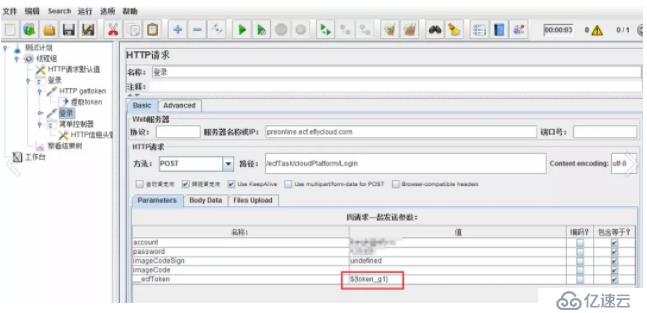
然еҗҺзӮ№еҮ»иҝҗиЎҢпјҢеңЁз»“жһңж ‘еҸҜзңӢеҲ°пјҢж–°иҜ·жұӮдёӯзҡ„tokenеҸӮж•°еҖјдёҺеүҚж–ҮиҺ·еҸ–зҡ„dataеҖјдёҖиҮҙпјҢиЎЁзӨәжҸҗеҸ–жҲҗеҠҹгҖӮ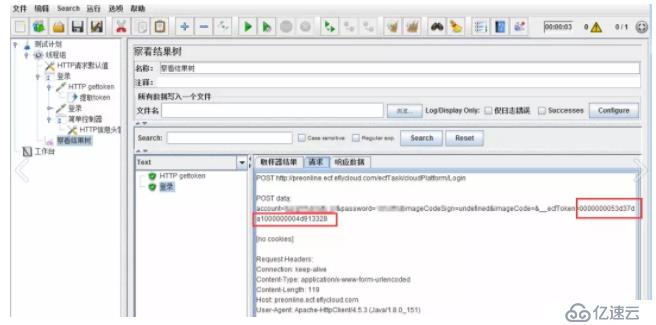
XPath ExtractorжҳҜеҸҰдёҖдёӘеҸҜиў«з”ЁжқҘжҸҗеҸ–йЎөйқўз»ҷе®ҡеҶ…е®№зҡ„Post ProcessorпјҲеҗҺзҪ®еӨ„зҗҶеҷЁпјүпјҢXPath Extractorзҡ„дҪҝз”Ёж–№ејҸдёҺжӯЈеҲҷиЎЁиҫҫејҸеӨ„зҗҶеҷЁзұ»дјјпјҢеҸӘдёҚиҝҮйңҖиҰҒеңЁиҜҘExtractorдёӯжҢҮе®ҡзҡ„дёҚжҳҜжӯЈеҲҷиЎЁиҫҫејҸпјҢиҖҢжҳҜз»ҷе®ҡзҡ„XPathи·Ҝеҫ„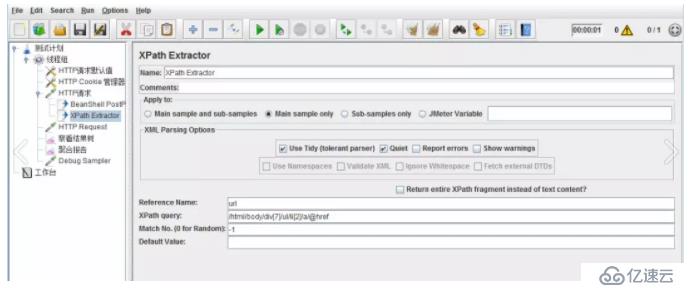
еҪ“жҸҗеҸ–зҡ„ж–Үжң¬ж—¶йЎөйқўдёҠзҡ„е…ғзҙ ж—¶пјҢXpath ExtractorжҜ”иҫғж–№дҫҝеҘҪз”ЁгҖӮXpathеҸҜеңЁжөҸи§ҲеҷЁйҖҡиҝҮF12пјҢиҺ·еҸ–жүҖйңҖе…ғзҙ зҡ„иЎЁиҫҫејҸгҖӮ
JSON ExtractorдёҺXpath ExtractorеҫҲзӣёдјјпјҢе…үеҗ¬еҗҚеӯ—е°ұзҹҘйҒ“гҖӮеҜ№дәҺе“Қеә”з»“жһңдёәJSONж јејҸзҡ„ж•°жҚ®пјҢз”ЁJSON ExtractorиҝӣиЎҢжҸҗеҸ–дјҡжӣҙдёәж–№дҫҝе’Ңдјҳйӣ…гҖӮдёҠдёҖдёӘдҫӢеӯҗиҜҙжҳҺдёӢеҰӮдҪ•дҪҝз”Ёпјҡ
еҒҮеҰӮйңҖиҰҒд»ҺдёӢйқўзҡ„urlдёӯжҸҗеҸ–userTypeзҡ„еҖјпјҢе“Қеә”з»“жһңд»Ҙjsonж јејҸжҳҫзӨәпјҢеҸҜжё…жҷ°зҡ„зңӢеҲ°еұӮзә§е…ізі»гҖӮ
еңЁзҷ»еҪ•зҡ„иҜ·жұӮдёҠж·»еҠ JSON ExtractorпјҢVariable namesз»ҷжҸҗеҸ–зҡ„еҸҳйҮҸи®ҫеҗҚз§°пјҢJSON Path expresstionsж јејҸеҰӮдёӢ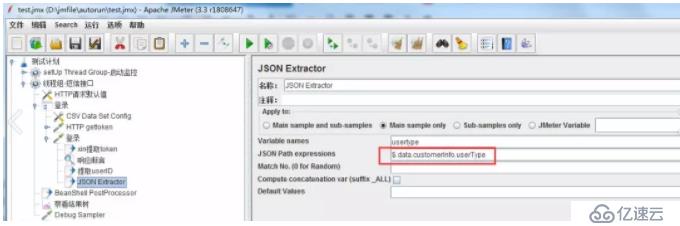
еҰӮжһңиҜҘurlзҡ„е“Қеә”еҢ…еҗ«еӨҡдёӘcustomerinfoпјҢиҰҒжҸҗеҸ–第дәҢдёӘcustomerinfoйҮҢйқўзҡ„userTypeпјҢеҸҜз”Ё$.data.customerInfo[1].userTypeзҡ„ж•°з»„еҪўејҸжҸҗеҸ–гҖӮ
жіЁпјҡеҰӮйңҖж ёеҜ№жҳҜеҗҰжҲҗеҠҹжҸҗеҸ–жүҖйңҖеҸҳйҮҸпјҢеҸҜеңЁзәҝзЁӢз»„ж·»еҠ дёҖдёӘdebug samplerпјҢжү§иЎҢи„ҡжң¬еҗҺпјҢжҹҘзңӢз»“жһңж ‘еҚіеҸҜзҹҘжҷ“
дёүз§Қе…іиҒ”ж–№ејҸеҗ„жңүе…¶йҖӮз”ЁиҢғеӣҙпјҢйғҪжҺҢжҸЎиҝҷдәӣдҪҝз”Ёж–№жі•дјҡеңЁзј–еҶҷжөӢиҜ•и„ҡжң¬ж—¶еҰӮйұјеҫ—ж°ҙгҖӮ
еҰӮиҺ·еҸ–HTMLзӯүиө„жәҗж—¶пјҢйҖүжӢ©Xpath ExtractorжӣҙдҫҝжҚ·пјҢеҸҜеҝ«йҖҹжҸҗеҸ–е…·дҪ“е…ғзҙ зҡ„еұһжҖ§еҖјпјӣ
еҰӮе“Қеә”ж јејҸдёәJSONпјҢйҖүжӢ©JSON Extractorж— з–‘жӣҙж–№дҫҝпјӣ
иӢҘиҝӣиЎҢжҺҘеҸЈжөӢиҜ•пјҢиҜ·жұӮзҡ„е“Қеә”дёҚжҳҜйЎөйқўе…ғзҙ зҡ„еҪўејҸпјҢеҲҷеә”з”ЁжӯЈеҲҷиЎЁиҫҫејҸиҝӣиЎҢжҸҗеҸ–гҖӮзқҝжұҹдә‘е®ҳзҪ‘й“ҫжҺҘпјҡhttps://www.eflycloud.com/home?from=RJ0035
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ