您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
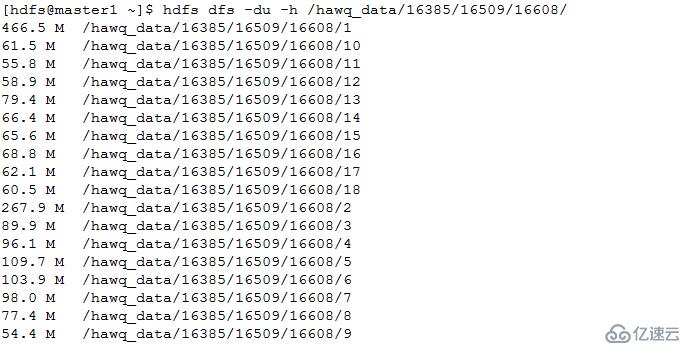
数据表采用随机分布: bucketnum=9
1.设置用于查询的virtual segment数量
语句级别:
SET hawq_rm_stmt_nvseg=10;
SET hawq_rm_stmt_vseg_memory='256mb';SET hawq_rm_stmt_nvseg=0;set hawq_rm_nvseg_perquery_perseg_limit=10;
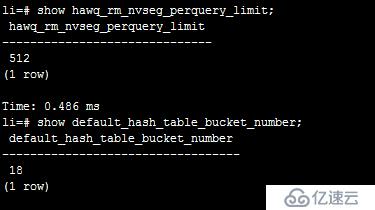
set hawq_rm_nvseg_perquery_limit=512;通过hawq_rm_nvseg_perquery_limit和hawq_rm_nvseg_perquery_perseg_limit参数可以调整查询执行时使用的virtual segments的数量
2.哈希分布表的相关参数:
default_hash_table_bucket_number
hawq_rm_nvseg_perquery_limit
hawq_rm_nvseg_perquery_perseg_limit
3.可以使用pg_partitions视图查找有关分区设计的信息。例如,查看销售表的分区设计:
SELECT partitionboundary, partitiontablename, partitionname, partitionlevel, partitionrank
FROM pg_partitions
WHERE tablename='ins_wifi_dates';下表和视图显示有关分区表的信息。
4.查看表的segment file分布
SELECT gpr.tablespace_oid,
gpr.database_oid,
gpf.relfilenode_oid,
gpf.segment_file_num,
'/hawq_data/'||gpr.tablespace_oid||'/'||gpr.database_oid||'/'||gpf.relfilenode_oid ||'/'||gpf.segment_file_num as path,
pg_class.relname,
gpr.persistent_state,
gpf.persistent_state
FROM gp_persistent_relfile_node gpf,pg_class, gp_persistent_relation_node gpr
WHERE gpf.relfilenode_oid = pg_class.relfilenode
AND gpr.relfilenode_oid = pg_class.relfilenode
AND pg_class.relname='person';SELECT distinct gpr.tablespace_oid,
gpr.database_oid,
gpf.relfilenode_oid,
pg_class.relname,
gpr.persistent_state,
gpf.persistent_state
FROM gp_persistent_relfile_node gpf,pg_class, gp_persistent_relation_node gpr
WHERE gpf.relfilenode_oid = pg_class.relfilenode
AND gpr.relfilenode_oid = pg_class.relfilenode
AND pg_class.relname like 'person_%' order by pg_class.relname ;#schema
SELECT gpr.tablespace_oid,
gpr.database_oid,
gpf.relfilenode_oid,
gpf.segment_file_num,
'/hawq_data/'||gpr.tablespace_oid||'/'||gpr.database_oid||'/'||gpf.relfilenode_oid ||'/'||gpf.segment_file_num as path,
pgn.nspname AS schemaname,
pg_class.relname AS tablename,
gpr.persistent_state,
gpf.persistent_state
FROM gp_persistent_relfile_node gpf,pg_class, gp_persistent_relation_node gpr, pg_namespace pgn
WHERE gpf.relfilenode_oid = pg_class.relfilenode
AND gpr.relfilenode_oid = pg_class.relfilenode
AND pgn.oid = pg_class.relnamespace
AND pg_class.relname='t_wifi_terminal_chrs_1_prt_1';经过测试发现:
数据在hdfs中的存储位置为: tablespace/database/table/segfile
分区表A目录中有默认哈希桶数目的segfile,但大小都为0,而其字表(如a1)目录中有默认哈希桶数目的segfile,且有文件。
查看表大小:
select sotdsize from hawq_toolkit.hawq_size_of_table_disk where sotdtablename='t_net_access_log';5.使用explain 或者 explain analyze 查看查询计划时,指定
set gp_log_dynamic_partition_pruning=on;可以显示扫描的分区名称。
Explain analyze和explain语句不同,explain analyze会真正执行查询,并得到查询执行过程中的统计数据。explain analyze的结果对了解查询执行的具体情况以及了解查询性能问题产生的原因有很大帮助。
SELECT * FROM pg_stats WHERE tablename = 'inventory';#查询会话信息
select * from pg_stat_activity;select application_name, datname, procpid, sess_id, usename, waiting, client_addr, client_port, waiting_resource, query_start, backend_start, xact_start from pg_stat_activity;select application_name, datname, procpid, sess_id, usename, waiting, client_addr, client_port, waiting_resource, current_query, query_start, backend_start, xact_start from pg_stat_activity;select application_name, datname, procpid, sess_id, usename, waiting, client_addr, client_port, waiting_resource, query_start, backend_start, xact_start from pg_stat_activity where application_name='psql' and current_query<>'<IDLE>';datname表示数据库名
procpid表示当前的SQL对应的PID
query_start表示SQL执行开始时间
current_query表示当前执行的SQL语句
waiting表示是否正在执行,t表示正在执行,f表示已经执行完成
client_addr表示客户端IP地址
284933
kill有两种方式,第一种是:
SELECT pg_cancel_backend(PID);这种方式只能kill select查询,对update、delete 及DML不生效)
第二种是:
SELECT pg_terminate_backend(PID);这种可以kill掉各种操作(select、update、delete、drop等)操作
在pg_cancel_backend()下,session还在,事物回退;
在pg_terminate_backend()操作后,session消失,事物回退。
如果在某些时候pg_terminate_backend()不能杀死session,那么可以在os层面,直接kill -9 pid
select * from pg_resqueue_status;--资源队列
SELECT * FROM dump_resource_manager_status(2);--Segment
SELECT * FROM dump_resource_manager_status(3);SELECT relname, relkind, reltuples, relpages FROM pg_class WHERE relname = 'ins_wifi_dates';
SELECT * FROM pg_stats WHERE tablename = 'ins_wifi_dates';SELECT gp_segment_id, COUNT(*)
FROM ins_wifi_dates
GROUP BY gp_segment_id
ORDER BY gp_segment_idset gp_select_invisible=true;
select count(*) from pg_class;
set gp_select_invisible=false;
select count(*) from pg_class;
vacuum pg_class;
reindex table pg_class;日志:
set
表重分布:
ALTER TABLE sales SET WITH (REORGANIZE=TRUE);检查未analyze的表:
select * from hawq_toolkit.hawq_stats_missing;http://hawq.incubator.apache.org/docs/userguide/2.2.0.0-incubating/reference/toolkit/hawq_toolkit.html#topic46
HAWQ查看表大小: //不包含分区表
SELECT relname AS name, sotdsize AS size, sotdtoastsize AS
toast, sotdadditionalsize AS other
FROM hawq_toolkit.hawq_size_of_table_disk AS sotd, pg_catalog.pg_class
WHERE sotd.sotdoid=pg_class.oid and pg_class.relname='t_wifi_terminal_chrs'
ORDER BY relname;hawq_size_of_partition_and_indexes_disk
select relname AS name, sopaidpartitionoid, sopaidpartitiontablename, sopaidpartitiontablesize as size, sotailtablesizeuncompressed as uncompressed from hawq_toolkit.hawq_size_of_partition_and_indexes_disk sopi,pg_catalog.pg_class WHERE sopi.sopaidparentoid=pg_class.oid and pg_class.relname='t_wifi_terminal_chrs'
ORDER BY sopaidpartitionoid;select relname AS name,sum(sopaidpartitiontablesize) as size from hawq_toolkit.hawq_size_of_partition_and_indexes_disk sopi,pg_catalog.pg_class WHERE sopi.sopaidparentoid=pg_class.oid and pg_class.relname='t_wifi_terminal_chrs'
group by relname ;内存/vore比值
[root@master2 pg_log]# cat hawq-2017-10-17_224829.csv
2017-10-17 18:21:57.319620 CST,,,p237647,th317192736,,,,0,con4,,seg-10000,,,,,"LOG","00000","Resource manager chooses ratio 5120 MB per core as cluster level memory to core ratio, there are 2304 MB memory 6 CORE resource unable to be utilized.",,,,,,,0,,"resourcepool.c",4641,
2017-10-17 18:21:57.319668 CST,,,p237647,th317192736,,,,0,con4,,seg-10000,,,,,"LOG","00000","Resource manager adjusts segment hd4.bigdata original global resource manager resource capacity from (154368 MB, 32 CORE) to (153600 MB, 30 CORE)",,,,,,,0,,"resourcepool.c",4787,
2017-10-17 18:21:57.319716 CST,,,p237647,th317192736,,,,0,con4,,seg-10000,,,,,"LOG","00000","Resource manager adjusts segment hd1.bigdata original global resource manager resource capacity from (154368 MB, 32 CORE) to (153600 MB, 30 CORE)",,,,,,,0,,"resourcepool.c",4787,
2017-10-17 18:21:57.319762 CST,,,p237647,th317192736,,,,0,con4,,seg-10000,,,,,"LOG","00000","Resource manager adjusts segment hd2.bigdata original global resource manager resource capacity from (154368 MB, 32 CORE) to (153600 MB, 30 CORE)",,,,,,,0,,"resourcepool.c",4787,免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。