жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚhiveдҪҝз”ЁиҝҮзЁӢдёӯжңүе“Әдәӣи°ғдјҳзӯ–з•ҘпјҢж–Үдёӯд»Ӣз»Қзҡ„йқһеёёиҜҰз»ҶпјҢе…·жңүдёҖе®ҡзҡ„еҸӮиҖғд»·еҖјпјҢж„ҹе…ҙи¶Јзҡ„е°Ҹдјҷдјҙ们дёҖе®ҡиҰҒзңӢе®ҢпјҒ
дёӢйқўжҳҜhiveдҪҝз”ЁиҝҮзЁӢдёӯдёҖдәӣи°ғдјҳзӯ–з•Ҙ
FetchжҠ“еҸ–жҳҜжҢҮпјҢHiveдёӯеҜ№жҹҗдәӣжғ…еҶөзҡ„жҹҘиҜўеҸҜд»ҘдёҚеҝ…дҪҝз”ЁMapReduceи®Ўз®—гҖӮдҫӢеҰӮпјҡSELECT * FROM employees;еңЁиҝҷз§Қжғ…еҶөдёӢпјҢHiveеҸҜд»Ҙз®ҖеҚ•ең°иҜ»еҸ–employeeеҜ№еә”зҡ„еӯҳеӮЁзӣ®еҪ•дёӢзҡ„ж–Ү件пјҢ然еҗҺиҫ“еҮәжҹҘиҜўз»“жһңеҲ°жҺ§еҲ¶еҸ°гҖӮ
еңЁhive-default.xml.templateж–Ү件дёӯhive.fetch.task.conversionй»ҳи®ӨжҳҜmoreпјҢиҖҒзүҲжң¬hiveй»ҳи®ӨжҳҜminimalпјҢиҜҘеұһжҖ§дҝ®ж”№дёәmoreд»ҘеҗҺпјҢеңЁе…ЁеұҖжҹҘжүҫгҖҒеӯ—ж®өжҹҘжүҫгҖҒlimitжҹҘжүҫзӯүйғҪдёҚиө°mapreduceгҖӮ
<property> <name>hive.fetch.task.conversion</name> <value>more</value> <description> Expects one of [none, minimal, more]. Some select queries can be converted to single FETCH task minimizing latency. Currently the query should be single sourced not having any subquery and should not have any aggregations or distincts (which incurs RS), lateral views and joins. 0. none : disable hive.fetch.task.conversion зҰҒз”ЁfetchжҠ“еҸ– 1. minimal : SELECT STAR, FILTER on partition columns, LIMIT еҸӘжңүselectеҲҶеҢәеӯ—ж®өпјҢд»ҘеҸҠlimitж—¶жүҚиғҪдҪҝз”ЁfetchпјҲдёҚиө°MapReduceпјү 2. more : SELECT, FILTER, LIMIT only (support TABLESAMPLE and virtual columns) еӯ—ж®өжҹҘжүҫпјҢlimitйғҪдёҚиө°MapReduce </description> </property>
д№ҹеҸҜд»ҘйҖҡиҝҮеңЁhiveе‘Ҫд»ӨиЎҢдёӢдёҙж—¶дҝ®ж”№иҜҘеҸӮж•°зҡ„еҖјпјҡ
hive (default)> set hive.fetch.task.conversion=more;
жңүж—¶Hiveзҡ„иҫ“е…Ҙж•°жҚ®йҮҸжҳҜйқһеёёе°Ҹзҡ„гҖӮеңЁиҝҷз§Қжғ…еҶөдёӢпјҢдёәжҹҘиҜўи§ҰеҸ‘жү§иЎҢд»»еҠЎж¶ҲиҖ—зҡ„ж—¶й—ҙеҸҜиғҪдјҡжҜ”е®һйҷ…jobзҡ„жү§иЎҢж—¶й—ҙиҰҒеӨҡзҡ„еӨҡгҖӮеҜ№дәҺеӨ§еӨҡж•°иҝҷз§Қжғ…еҶөпјҢHiveеҸҜд»ҘйҖҡиҝҮжң¬ең°жЁЎејҸеңЁеҚ•еҸ°жңәеҷЁдёҠеӨ„зҗҶжүҖжңүзҡ„д»»еҠЎгҖӮеҜ№дәҺе°Ҹж•°жҚ®йӣҶпјҢжү§иЎҢж—¶й—ҙеҸҜд»ҘжҳҺжҳҫиў«зј©зҹӯгҖӮеҚіеҸӘеҗҜеҠЁдёҖдёӘmapе’Ңreduceд»»еҠЎпјҢдё”еңЁеҚ•еҸ°дё»жңәдёҠжү§иЎҢгҖӮзӣёе…іеҸӮж•°и®ҫзҪ®еҰӮдёӢпјҡ
//ејҖеҗҜжң¬ең°mrпјҢиҮӘеҠЁж №жҚ®дёӢйқўзҡ„й…ҚзҪ®еҶіе®ҡжҳҜеҗҰдҪҝз”Ёжң¬ең°жЁЎејҸ set hive.exec.mode.local.auto=true; //и®ҫзҪ®local mrзҡ„жңҖеӨ§иҫ“е…Ҙж•°жҚ®йҮҸпјҢеҪ“иҫ“е…Ҙж•°жҚ®йҮҸе°ҸдәҺиҝҷдёӘеҖјж—¶йҮҮз”Ёlocal mrзҡ„ж–№ејҸпјҢй»ҳи®Өдёә134217728bytesпјҢеҚі128M set hive.exec.mode.local.auto.inputbytes.max=50000000; //и®ҫзҪ®local mrзҡ„жңҖеӨ§иҫ“е…Ҙж–Ү件дёӘж•°пјҢеҪ“иҫ“е…Ҙж–Ү件дёӘж•°е°ҸдәҺиҝҷдёӘеҖјж—¶йҮҮз”Ёlocal mrзҡ„ж–№ејҸпјҢй»ҳи®Өдёә4 set hive.exec.mode.local.auto.input.files.max=10;
е°ҶkeyзӣёеҜ№еҲҶж•ЈпјҢ并且数жҚ®йҮҸе°Ҹзҡ„иЎЁж”ҫеңЁjoinзҡ„е·Ұиҫ№пјҢиҝҷж ·еҸҜд»Ҙжңүж•ҲеҮҸе°‘еҶ…еӯҳжәўеҮәй”ҷиҜҜеҸ‘з”ҹзҡ„еҮ зҺҮпјҢеӣ дёәжҳҜе°Ҷе·Ұиҫ№зҡ„иЎЁе…ҲиҜ»еҸ–зҡ„пјӣеҶҚиҝӣдёҖжӯҘпјҢеҸҜд»ҘдҪҝз”ЁGroupеҸҳе°Ҹзҡ„з»ҙеәҰиЎЁпјҲ1000жқЎд»ҘдёӢзҡ„и®°еҪ•жқЎж•°пјүе…ҲиҝӣеҶ…еӯҳгҖӮеңЁmapз«Ҝе®ҢжҲҗreduceгҖӮ
е®һйҷ…жөӢиҜ•еҸ‘зҺ°пјҡж–°зүҲзҡ„hiveе·Із»ҸеҜ№е°ҸиЎЁJOINеӨ§иЎЁе’ҢеӨ§иЎЁJOINе°ҸиЎЁиҝӣиЎҢдәҶдјҳеҢ–гҖӮе°ҸиЎЁж”ҫеңЁе·Ұиҫ№е’ҢеҸіиҫ№е·Із»ҸжІЎжңүжҳҺжҳҫеҢәеҲ«гҖӮ
иҝҷдёӘе®һйӘҢиҝҮзЁӢдёӯеҸҜд»Ҙжү“ејҖhadoopзҡ„jobhistory serverжқҘжҹҘзңӢjobзҡ„жү§иЎҢжғ…еҶөпјҢеҢ…жӢ¬жү§иЎҢзҡ„ж—¶й—ҙзӯүгҖӮ
й…ҚзҪ® mapred-site.xml <property> <name>mapreduce.jobhistory.address</name> <value>bigdata111:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>bigdata111:19888</value> </property> еҗҜеҠЁеҺҶеҸІжңҚеҠЎеҷЁпјҡ mr-jobhistory-daemon.sh start historyserver иҝӣе…Ҙhistoryserver зҡ„webйЎөйқўпјҡ http://192.168.1.102:19888
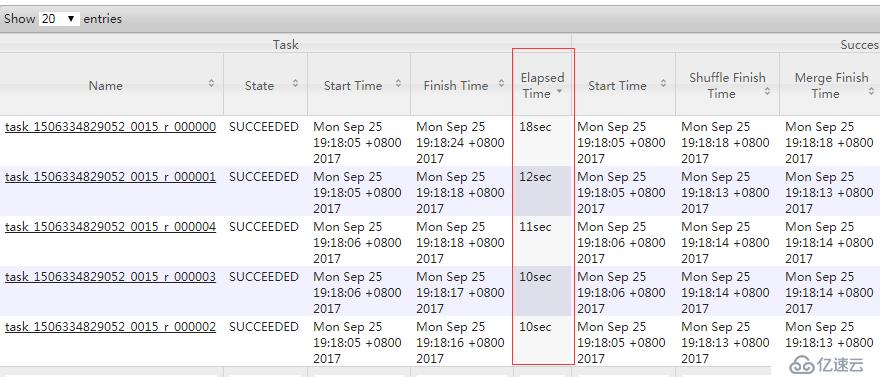
еӣҫ 3.1 hiveеӨ§иЎЁjoinз»“жһңеӣҫ
еҸҜд»ҘзңӢеҲ°jobз»“жһңжңүеҫҲеӨҡжү§иЎҢз»“жһңзҠ¶жҖҒеҸӮж•°пјҢжҜ”еҰӮжү§иЎҢж—¶й—ҙзӯүгҖӮ
жңүж—¶joinи¶…ж—¶жҳҜеӣ дёәжҹҗдәӣkeyеҜ№еә”зҡ„ж•°жҚ®еӨӘеӨҡпјҢиҖҢзӣёеҗҢkeyеҜ№еә”зҡ„ж•°жҚ®йғҪдјҡеҸ‘йҖҒеҲ°зӣёеҗҢзҡ„reducerдёҠпјҢд»ҺиҖҢеҜјиҮҙеҶ…еӯҳдёҚеӨҹгҖӮжӯӨж—¶жҲ‘们еә”иҜҘд»”з»ҶеҲҶжһҗиҝҷдәӣејӮеёёзҡ„keyпјҢеҫҲеӨҡжғ…еҶөдёӢпјҢиҝҷдәӣkeyеҜ№еә”зҡ„ж•°жҚ®жҳҜејӮеёёж•°жҚ®пјҢжҲ‘们йңҖиҰҒеңЁSQLиҜӯеҸҘдёӯиҝӣиЎҢиҝҮж»ӨгҖӮжҜ”еҰӮиҜҙkeyжҳҜnullпјҢеҰӮжһңжҳҜејӮеёёж•°жҚ®зҡ„иҜқпјҢе°ұеә”иҜҘиҝҮж»ӨжҺүгҖӮдҫӢеҰӮпјҡ
insert overwrite table jointable select n.* from (select * from nullidtable where id is not null ) n left join ori o on n.id = o.id; иҝҷйҮҢе°ұдәӢе…ҲеҜ№ nullidtable иЎЁдёӯ id дёәnull зҡ„иЎҢиҝҮж»ӨжҺүгҖӮ дҪҶжҳҜиҰҒжіЁж„ҸпјҢзЎ®е®ҡkeyжҳҜnullзҡ„ж•°жҚ®жҳҜж— ж•Ҳж•°жҚ®ж—¶жүҚиҝҮж»ӨпјҢеҰӮжһңжҳҜжңүж•Ҳж•°жҚ®е°ұдёҚиғҪйҮҮз”Ёиҝҷз§Қж–№ејҸдәҶ
жңүж—¶иҷҪ然жҹҗдёӘkeyдёәз©әеҜ№еә”зҡ„ж•°жҚ®еҫҲеӨҡпјҢдҪҶжҳҜзӣёеә”зҡ„ж•°жҚ®дёҚжҳҜејӮеёёж•°жҚ®пјҢеҝ…йЎ»иҰҒеҢ…еҗ«еңЁjoinзҡ„з»“жһңдёӯпјҢжӯӨж—¶жҲ‘们еҸҜд»ҘиЎЁaдёӯkeyдёәз©әзҡ„еӯ—ж®өиөӢдёҖдёӘйҡҸжңәзҡ„еҖјпјҢдҪҝеҫ—ж•°жҚ®йҡҸжңәеқҮеҢҖең°еҲҶдёҚеҲ°дёҚеҗҢзҡ„reducerдёҠгҖӮдҫӢеҰӮпјҡ
insert overwrite table jointable
select n.* from nullidtable n full join ori o on
case when n.id is null then concat('hive', rand()) else n.id end = o.id;
дҪҝз”Ё case when xxx then value1 else id end иҜӯеҸҘеҲӨж–ӯidжҳҜеҗҰдёәз©әпјҢдёәз©әеҲҷз”ЁйҡҸжңәж•°жӣҝд»ЈпјҢеҗҰеҲҷзӣҙжҺҘеҰӮжһңдёҚжҢҮе®ҡMapJoinжҲ–иҖ…дёҚз¬ҰеҗҲMapJoinзҡ„жқЎд»¶пјҢйӮЈд№ҲHiveи§ЈжһҗеҷЁдјҡе°ҶJoinж“ҚдҪңиҪ¬жҚўжҲҗCommon JoinпјҢеҚіпјҡеңЁReduceйҳ¶ж®өе®ҢжҲҗjoinгҖӮе®№жҳ“еҸ‘з”ҹж•°жҚ®еҖҫж–ңгҖӮеҸҜд»Ҙз”ЁMapJoinжҠҠе°ҸиЎЁе…ЁйғЁеҠ иҪҪеҲ°еҶ…еӯҳеңЁmapз«ҜиҝӣиЎҢjoinпјҢйҒҝе…ҚreducerеӨ„зҗҶгҖӮ
жҲ‘们еҸҜд»ҘжҢҮе®ҡеҪ“е°ҸиЎЁи¶…иҝҮеӨҡе°‘ж—¶йҮҮз”Ёreduce joinпјҢе°ҸдәҺе°ұйҮҮз”Ёmap join
пјҲ1пјүи®ҫзҪ®иҮӘеҠЁйҖүжӢ©Mapjoin set hive.auto.convert.join = true; й»ҳи®Өдёәtrue пјҲ2пјүеӨ§иЎЁе°ҸиЎЁзҡ„йҳҲеҖји®ҫзҪ®пјҲй»ҳи®Ө25MдёҖдёӢи®ӨдёәжҳҜе°ҸиЎЁпјүпјҡ set hive.mapjoin.smalltable.filesize=25000000;
йҮҮеҸ–reduceиҒҡеҗҲй»ҳи®Өжғ…еҶөдёӢпјҢMapйҳ¶ж®өеҗҢдёҖKeyж•°жҚ®еҲҶеҸ‘з»ҷдёҖдёӘreduceпјҢеҪ“дёҖдёӘkeyж•°жҚ®иҝҮеӨ§ж—¶е°ұеҖҫж–ңдәҶгҖӮ并дёҚжҳҜжүҖжңүзҡ„иҒҡеҗҲж“ҚдҪңйғҪйңҖиҰҒеңЁReduceз«Ҝе®ҢжҲҗпјҢеҫҲеӨҡиҒҡеҗҲж“ҚдҪңйғҪеҸҜд»Ҙе…ҲеңЁMapз«ҜиҝӣиЎҢйғЁеҲҶиҒҡеҗҲпјҢжңҖеҗҺеңЁReduceз«Ҝеҫ—еҮәжңҖз»Ҳз»“жһңгҖӮ
пјҲ1пјүжҳҜеҗҰеңЁMapз«ҜиҝӣиЎҢиҒҡеҗҲпјҢй»ҳи®ӨдёәTrue hive.map.aggr = true пјҲ2пјүеңЁMapз«ҜиҝӣиЎҢиҒҡеҗҲж“ҚдҪңзҡ„жқЎзӣ®ж•°зӣ® hive.groupby.mapaggr.checkinterval = 100000 пјҲ3пјүжңүж•°жҚ®еҖҫж–ңзҡ„ж—¶еҖҷиҝӣиЎҢиҙҹиҪҪеқҮиЎЎпјҲй»ҳи®ӨжҳҜfalseпјү hive.groupby.skewindata = true еҪ“иҝҷдёҖйЎ№и®ҫзҪ®дёәtrueж—¶пјҢз”ҹжҲҗзҡ„жҹҘиҜўи®ЎеҲ’дјҡжңүдёӨдёӘMR JobгҖӮ第дёҖдёӘMR JobдёӯпјҢMapзҡ„иҫ“еҮәз»“жһңдјҡйҡҸжңәеҲҶеёғеҲ°ReduceдёӯпјҢжҜҸдёӘReduceеҒҡйғЁеҲҶиҒҡеҗҲж“ҚдҪңпјҢ并иҫ“еҮәз»“жһңпјҢиҝҷж ·еӨ„зҗҶзҡ„з»“жһңжҳҜзӣёеҗҢзҡ„Group By KeyжңүеҸҜиғҪиў«еҲҶеҸ‘еҲ°дёҚеҗҢзҡ„ReduceдёӯпјҢд»ҺиҖҢиҫҫеҲ°иҙҹиҪҪеқҮиЎЎзҡ„зӣ®зҡ„пјӣ第дәҢдёӘMR JobеҶҚж №жҚ®йў„еӨ„зҗҶзҡ„ж•°жҚ®з»“жһңжҢүз…§Group By KeyеҲҶеёғеҲ°ReduceдёӯпјҲиҝҷдёӘиҝҮзЁӢеҸҜд»ҘдҝқиҜҒзӣёеҗҢзҡ„Group By Keyиў«еҲҶеёғеҲ°еҗҢдёҖдёӘReduceдёӯпјүпјҢжңҖеҗҺе®ҢжҲҗжңҖз»Ҳзҡ„иҒҡеҗҲж“ҚдҪңгҖӮ
жҷ®йҖҡжғ…еҶөйҖүпјҢжҲ‘们з»ҹи®ЎеҺ»йҮҚеҗҺзҡ„ж•°жҚ®иЎҢж•°ж—¶пјҢжҳҜиҝҷж ·зҡ„з»ҹи®Ўзҡ„пјҡ
select count(distinct id) from bigtable;
иҝҷз§Қж–№ејҸжңүдёҖдёӘе·ЁеӨ§зҡ„зјәйҷ·пјҢеӣ дёәжҳҜж•ҙдҪ“еҺ»йҮҚзҡ„пјҢжүҖд»ҘMapReduceж—¶пјҢж— жі•дҪҝз”ЁеӨҡдёӘreducerд»»еҠЎпјҢеҰӮжһңдҪҝз”ЁдәҶпјҢе°ұеҸҳжҲҗеұҖйғЁеҺ»йҮҚпјҢдҪҶж•ҙдҪ“дёҚиғҪдҝқиҜҒеҺ»йҮҚгҖӮиҝҷж ·зҡ„иҜқдёҖдёӘreducer зҡ„иҙҹиҪҪе…¶е®һжҳҜеҫҲеӨ§зҡ„пјҢеҸҜд»ҘйҮҮз”ЁдёӢйқўзҡ„ж–№ејҸдјҳеҢ–пјҡ
select count(id) from (select id from bigtable group by id) a;
е…ҲеҗҜеҠЁMapReduceж №жҚ®idиҝӣиЎҢgroup byпјҢиҝҷдёӘиҝҮзЁӢдёӯе…¶е®һе·Із»ҸеҺ»йҮҚдәҶпјҢиҖҢдё”group byдёӯжҳҜеҸҜд»Ҙз”ЁеӨҡдёӘreducerд»»еҠЎпјҢиҝҷж ·зҡ„е°ұеҸҜд»ҘеҮҸиҪ»еҚ•дёӘreducer зҡ„еҺӢеҠӣгҖӮжҺҘзқҖеҶҚеҗҜеҠЁеҸҰеӨ–дёҖдёӘMapReduceпјҢз”ЁдәҺcountз»ҹи®Ўgroup byд№ӢеҗҺзҡ„ж•°жҚ®зҡ„иЎҢж•°гҖӮжүҖд»ҘиҝҷйҮҢжҳҜеҸҳжҲҗдёӨдёӘMapReduce jobжү§иЎҢзҡ„д»»еҠЎпјҢжүҖд»ҘиҰҒжіЁж„Ҹд»…еҪ“ж•°жҚ®йҮҸеӨ§ж—¶йҮҮз”Ёиҝҷз§Қж–№ејҸпјҢеҗҰеҲҷеӨҡд»»еҠЎзҡ„и°ғеәҰеҸҚиҖҢеҚ з”ЁжӣҙеӨҡиө„жәҗпјҢ并且ж•ҲзҺҮд№ҹдёҚеҘҪгҖӮ
еҲ—иҝҮж»Өпјҡе°ҪйҮҸдёҚдҪҝз”Ёselect * иҖҢжҳҜжҢҮе®ҡиҰҒжҹҘиҜўзҡ„еӯ—ж®ө
иЎҢиҝҮж»ӨпјҡеңЁжҲ‘们иҝӣиЎҢеӨ–йғЁjoinж—¶пјҢеҰӮжһңжҹҗдёӘиЎЁиҰҒиҝҮж»ӨеҲ°жҹҗдәӣиЎҢгҖӮиҰҒе…ҲеңЁjoinд№ӢеүҚиҝӣиЎҢиҝҮж»ӨпјҢдёҚиҰҒдёӨиЎЁjoinд№ӢеҗҺеҶҚиҝҮж»ӨпјҢеӣ дёәjoinд№ӢеҗҺж•°жҚ®йҮҸжҜ”еҺҹжқҘеўһеӨ§дәҶпјҢиҝҮж»ӨиҰҒжӣҙд№…гҖӮ
joinд№ӢеҗҺиҝҮж»Өпјҡ
select o.id from bigtable b join ori o on o.id = b.id where o.id <= 10; жүҖд»ҘwhereиҜӯеҸҘдёҚиҰҒж”ҫеңЁjoinд№ӢеҗҺпјҢиҝҷжҳҜдёҚеҘҪзҡ„пјҢеӨ§ж•°жҚ®йҮҸзҡ„ж—¶еҖҷиҖ—ж—¶еҫҲй•ҝ
joinд№ӢеүҚиҝҮж»Өпјҡ
select b.id from bigtable b join (select id from ori where id <= 10 ) o on b.id = o.id; иҝҷйҮҢе°ұжҳҜе…ҲеҜ№oriиЎЁиҝӣиЎҢidеҲ—зҡ„иҝҮж»ӨпјҢиҝҮж»ӨеҗҺзҡ„ж•°жҚ®еҶҚе’ҢbigtableиЎЁjoin
еҰӮжһңhiveиЎЁжҳҜдёҖеј еҲҶеҢәиЎЁпјҢдёҖиҲ¬жғ…еҶөдёӢпјҢжҲ‘们иҝӣиЎҢinsertжҸ’е…Ҙж—¶й—ҙж—¶пјҢйңҖиҰҒжҳҺжҳҫжҢҮе®ҡжҸ’е…ҘеҲ°е“ӘдёӘеҲҶеҢәдёӯгҖӮиҖҢеҰӮжһңејҖеҗҜдәҶеҠЁжҖҒеҲҶеҢәпјҢйӮЈд№Ҳе°ұдјҡж №жҚ®еҜје…Ҙж•°жҚ®зҡ„еҲҶеҢәеӯ—ж®өпјҢиҮӘеҠЁеҜје…ҘеҲ°жҢҮе®ҡеҲҶеҢәпјҢеҰӮжһңеҲҶеҢәдёҚеӯҳеңЁпјҢе°ұиҮӘеҠЁеҲӣе»әгҖӮ
пјҲ1пјүејҖеҗҜеҠЁжҖҒеҲҶеҢәеҠҹиғҪпјҲй»ҳи®ӨtrueпјҢејҖеҗҜпјү hive.exec.dynamic.partition=true пјҲ2пјүи®ҫзҪ®дёәйқһдёҘж јжЁЎејҸпјҲеҠЁжҖҒеҲҶеҢәзҡ„жЁЎејҸпјҢй»ҳи®ӨstrictпјҢиЎЁзӨәеҝ…йЎ»жҢҮе®ҡиҮіе°‘дёҖдёӘеҲҶеҢәдёәйқҷжҖҒеҲҶеҢәпјҢnonstrictжЁЎејҸиЎЁзӨәе…Ғи®ёжүҖжңүзҡ„еҲҶеҢәеӯ—ж®өйғҪеҸҜд»ҘдҪҝз”ЁеҠЁжҖҒеҲҶеҢәгҖӮпјү hive.exec.dynamic.partition.mode=nonstrict пјҲ3пјүеңЁжүҖжңүжү§иЎҢMRзҡ„иҠӮзӮ№дёҠпјҢжңҖеӨ§дёҖе…ұеҸҜд»ҘеҲӣе»әеӨҡе°‘дёӘеҠЁжҖҒеҲҶеҢәгҖӮ hive.exec.max.dynamic.partitions=1000 пјҲ4пјүеңЁжҜҸдёӘжү§иЎҢMRзҡ„иҠӮзӮ№дёҠпјҢжңҖеӨ§еҸҜд»ҘеҲӣе»әеӨҡе°‘дёӘеҠЁжҖҒеҲҶеҢәгҖӮиҜҘеҸӮж•°йңҖиҰҒж №жҚ®е®һйҷ…зҡ„ж•°жҚ®жқҘи®ҫе®ҡгҖӮжҜ”еҰӮпјҡжәҗж•°жҚ®дёӯеҢ…еҗ«дәҶдёҖе№ҙзҡ„ж•°жҚ®пјҢеҚіdayеӯ—ж®өжңү365дёӘеҖјпјҢйӮЈд№ҲиҜҘеҸӮж•°е°ұйңҖиҰҒи®ҫзҪ®жҲҗеӨ§дәҺ365пјҢеҰӮжһңдҪҝз”Ёй»ҳи®ӨеҖј100пјҢеҲҷдјҡжҠҘй”ҷгҖӮ hive.exec.max.dynamic.partitions.pernode=100 пјҲ5пјүж•ҙдёӘMR JobдёӯпјҢжңҖеӨ§еҸҜд»ҘеҲӣе»әеӨҡе°‘дёӘHDFSж–Ү件гҖӮ hive.exec.max.created.files=100000 пјҲ6пјүеҪ“жңүз©әеҲҶеҢәз”ҹжҲҗж—¶пјҢжҳҜеҗҰжҠӣеҮәејӮеёёгҖӮдёҖиҲ¬дёҚйңҖиҰҒи®ҫзҪ®гҖӮ hive.error.on.empty.partition=false
дҫӢеӯҗпјҡ
йңҖжұӮпјҡе°Ҷoriдёӯзҡ„ж•°жҚ®жҢүз…§ж—¶й—ҙ(еҰӮпјҡ20111230000008)пјҢжҸ’е…ҘеҲ°зӣ®ж ҮиЎЁori_partitioned_targetзҡ„зӣёеә”еҲҶеҢәдёӯ
пјҲ1пјүеҲӣе»әеҲҶеҢәиЎЁ create table ori_partitioned(id bigint, time bigint, uid string, keyword string, url_rank int, click_num int, click_url string) partitioned by (p_time bigint) row format delimited fields terminated by '\t'; пјҲ2пјүеҠ иҪҪж•°жҚ®еҲ°еҲҶеҢәиЎЁдёӯ hive (default)> load data local inpath '/opt/module/datas/ds1' into table ori_partitioned partition(p_time='20111230000010') ; hive (default)> load data local inpath '/opt/module/datas/ds2' into table ori_partitioned partition(p_time='20111230000011') ; пјҲ3пјүеҲӣе»әзӣ®ж ҮеҲҶеҢәиЎЁ create table ori_partitioned_target(id bigint, time bigint, uid string, keyword string, url_rank int, click_num int, click_url string) PARTITIONED BY (p_time STRING) row format delimited fields terminated by '\t'; пјҲ4пјүи®ҫзҪ®еҠЁжҖҒеҲҶеҢә set hive.exec.dynamic.partition = true; set hive.exec.dynamic.partition.mode = nonstrict; set hive.exec.max.dynamic.partitions = 1000; set hive.exec.max.dynamic.partitions.pernode = 100; set hive.exec.max.created.files = 100000; set hive.error.on.empty.partition = false; hive (default)> insert overwrite table ori_partitioned_target partition (p_time) select id, time, uid, keyword, url_rank, click_num, click_url, p_time from ori_partitioned;
иҝҷдёӘй—®йўҳеңЁMapReduceдёӯиҜҙиҝҮдәҶпјҢй»ҳи®ӨжҳҜжҢүжҜҸдёӘж–Ү件дёҖдёӘж•ҙдҪ“еҺ»еҲҮзүҮзҡ„пјҢдёҖдёӘж–Ү件иҮіе°‘жҳҜдёҖдёӘеҲҮзүҮпјҢеӨ§йҮҸе°Ҹж–Ү件时пјҢеҠҝеҝ…дә§з”ҹеҫҲеӨҡmapд»»еҠЎгҖӮиҝҷдёӘй—®йўҳеңЁhiveдёӯд№ҹжҳҜдёҖж ·зҡ„гҖӮ
и§ЈеҶіж–№жЎҲпјҡ
еңЁmapжү§иЎҢеүҚеҗҲ并е°Ҹж–Ү件пјҢеҮҸе°‘mapж•°пјҡCombineHiveInputFormatе…·жңүеҜ№е°Ҹж–Ү件иҝӣиЎҢеҗҲ并зҡ„еҠҹиғҪпјҲзі»з»ҹй»ҳи®Өзҡ„ж јејҸпјүгҖӮHiveInputFormatжІЎжңүеҜ№е°Ҹж–Ү件еҗҲ并еҠҹиғҪгҖӮ
set hive.input.format= org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
еҪ“жҜҸдёӘmapжү§иЎҢйғҪйқһеёёзј“ж…ўж—¶пјҢеҸҜиғҪжҳҜеӣ дёәеӨ„зҗҶйҖ»иҫ‘еӨҚжқӮпјҢиҝҷж—¶еҖҷеҸҜд»ҘиҖғиҷ‘е°ҶеҲҮзүҮеӨ§е°Ҹи®ҫзҪ®зҡ„е°ҸзӮ№пјҢеўһеҠ mapж•°зӣ®пјҢеҮҸиҪ»жҜҸдёӘmapе·ҘдҪңйҮҸгҖӮ
еўһеҠ mapзҡ„ж–№жі•дёәпјҡж №жҚ®computeSliteSize(Math.max(minSize,Math.min(maxSize,blocksize)))=blocksize=128Mе…¬ејҸпјҢи°ғж•ҙmaxSizeжңҖеӨ§еҖјгҖӮи®©maxSizeжңҖеӨ§еҖјдҪҺдәҺblocksizeе°ұеҸҜд»ҘеўһеҠ mapзҡ„дёӘж•°гҖӮ
и®ҫзҪ®жңҖеӨ§еҲҮзүҮеҖјдёә100дёӘеӯ—иҠӮ hive (default)> set mapreduce.input.fileinputformat.split.maxsize=100; иҝҷйҮҢеҸӘжҳҜдҫӢеӯҗпјҢе…·дҪ“и®ҫзҪ®дёәеӨҡеӨ§пјҢж №жҚ®е…·дҪ“жғ…еҶөеҶіе®ҡ
и°ғж•ҙж–№ејҸпјҡ
пјҲ1пјүжҜҸдёӘReduceеӨ„зҗҶзҡ„ж•°жҚ®йҮҸй»ҳи®ӨжҳҜ256MB hive.exec.reducers.bytes.per.reducer=256000000 пјҲ2пјүжҜҸдёӘд»»еҠЎжңҖеӨ§зҡ„reduceж•°пјҢй»ҳи®Өдёә1009 hive.exec.reducers.max=1009 пјҲ3пјүи®Ўз®—reducerж•°зҡ„е…¬ејҸ N=min(еҸӮж•°2пјҢжҖ»иҫ“е…Ҙж•°жҚ®йҮҸ/еҸӮж•°1)
иҰҒжіЁж„Ҹпјҡ
1пјүиҝҮеӨҡзҡ„еҗҜеҠЁе’ҢеҲқе§ӢеҢ–reduceд№ҹдјҡж¶ҲиҖ—ж—¶й—ҙе’Ңиө„жәҗпјӣ
2пјүеҸҰеӨ–пјҢжңүеӨҡе°‘дёӘreduceпјҢе°ұдјҡжңүеӨҡе°‘дёӘиҫ“еҮәж–Ү件пјҢеҰӮжһңз”ҹжҲҗдәҶеҫҲеӨҡдёӘе°Ҹж–Ү件пјҢйӮЈд№ҲеҰӮжһңиҝҷдәӣе°Ҹж–Ү件дҪңдёәдёӢдёҖдёӘд»»еҠЎзҡ„иҫ“е…ҘпјҢеҲҷд№ҹдјҡеҮәзҺ°е°Ҹж–Ү件иҝҮеӨҡзҡ„й—®йўҳпјӣ
еңЁи®ҫзҪ®reduceдёӘж•°зҡ„ж—¶еҖҷд№ҹйңҖиҰҒиҖғиҷ‘иҝҷдёӨдёӘеҺҹеҲҷпјҡеӨ„зҗҶеӨ§ж•°жҚ®йҮҸеҲ©з”ЁеҗҲйҖӮзҡ„reduceж•°пјӣдҪҝеҚ•дёӘreduceд»»еҠЎеӨ„зҗҶж•°жҚ®йҮҸеӨ§е°ҸиҰҒеҗҲйҖӮпјӣ
Hiveдјҡе°ҶдёҖдёӘжҹҘиҜўиҪ¬еҢ–жҲҗдёҖдёӘжҲ–иҖ…еӨҡдёӘйҳ¶ж®өгҖӮиҝҷж ·зҡ„йҳ¶ж®өеҸҜд»ҘжҳҜMapReduceйҳ¶ж®өгҖҒжҠҪж ·йҳ¶ж®өгҖҒеҗҲ并йҳ¶ж®өгҖҒlimitйҳ¶ж®өгҖӮжҲ–иҖ…Hiveжү§иЎҢиҝҮзЁӢдёӯеҸҜиғҪйңҖиҰҒзҡ„е…¶д»–йҳ¶ж®өгҖӮй»ҳи®Өжғ…еҶөдёӢпјҢHiveдёҖж¬ЎеҸӘдјҡжү§иЎҢдёҖдёӘйҳ¶ж®өгҖӮдёҚиҝҮпјҢжҹҗдёӘзү№е®ҡзҡ„jobеҸҜиғҪеҢ…еҗ«дј—еӨҡзҡ„йҳ¶ж®өпјҢиҖҢиҝҷдәӣйҳ¶ж®өеҸҜиғҪ并йқһе®Ңе…Ёдә’зӣёдҫқиө–зҡ„пјҢд№ҹе°ұжҳҜиҜҙжңүдәӣйҳ¶ж®өжҳҜеҸҜд»Ҙ并иЎҢжү§иЎҢзҡ„пјҢиҝҷж ·еҸҜиғҪдҪҝеҫ—ж•ҙдёӘjobзҡ„жү§иЎҢж—¶й—ҙзј©зҹӯгҖӮдёҚиҝҮпјҢеҰӮжһңжңүжӣҙеӨҡзҡ„йҳ¶ж®өеҸҜд»Ҙ并иЎҢжү§иЎҢпјҢйӮЈд№ҲjobеҸҜиғҪе°ұи¶Ҡеҝ«е®ҢжҲҗгҖӮ
йҖҡиҝҮи®ҫзҪ®еҸӮж•°hive.exec.parallelеҖјдёәtrueпјҢе°ұеҸҜд»ҘејҖеҗҜ并еҸ‘жү§иЎҢгҖӮдёҚиҝҮпјҢеңЁе…ұдә«йӣҶзҫӨдёӯпјҢйңҖиҰҒжіЁж„ҸдёӢпјҢеҰӮжһңjobдёӯ并иЎҢйҳ¶ж®өеўһеӨҡпјҢйӮЈд№ҲйӣҶзҫӨеҲ©з”ЁзҺҮе°ұдјҡеўһеҠ гҖӮ
set hive.exec.parallel=true; //жү“ејҖд»»еҠЎе№¶иЎҢжү§иЎҢ set hive.exec.parallel.thread.number=16; //еҗҢдёҖдёӘsqlе…Ғи®ёжңҖеӨ§е№¶иЎҢеәҰпјҢй»ҳи®Өдёә8гҖӮ
HiveжҸҗдҫӣдәҶдёҖдёӘдёҘж јжЁЎејҸпјҢеҸҜд»ҘйҳІжӯўз”ЁжҲ·жү§иЎҢйӮЈдәӣеҸҜиғҪж„Ҹеҗ‘дёҚеҲ°зҡ„дёҚеҘҪзҡ„еҪұе“Қзҡ„жҹҘиҜўгҖӮйҖҡиҝҮи®ҫзҪ®еұһжҖ§hive.mapred.modeеҖјдёәй»ҳи®ӨжҳҜйқһдёҘж јжЁЎејҸnonstrict гҖӮејҖеҗҜдёҘж јжЁЎејҸйңҖиҰҒдҝ®ж”№hive.mapred.modeеҖјдёәstrictпјҢејҖеҗҜдёҘж јжЁЎејҸеҸҜд»ҘзҰҒжӯў3з§Қзұ»еһӢзҡ„жҹҘиҜўгҖӮ
<property> <name>hive.mapred.mode</name> <value>strict</value> <description> The mode in which the Hive operations are being performed. In strict mode, some risky queries are not allowed to run. They include: Cartesian Product. No partition being picked up for a query. Comparing bigints and strings. Comparing bigints and doubles. Orderby without limit. </description> </property>
йҷҗеҲ¶д»ҘдёӢдёүз§Қжғ…еҶөзҡ„sqlиҜӯеҸҘзҡ„жү§иЎҢпјҡ
1пјүеҜ№дәҺеҲҶеҢәиЎЁпјҢйҷӨйқһwhereиҜӯеҸҘдёӯеҗ«жңүеҲҶеҢәеӯ—ж®өиҝҮж»ӨжқЎд»¶жқҘйҷҗеҲ¶иҢғеӣҙпјҢеҗҰеҲҷдёҚе…Ғи®ёжү§иЎҢгҖӮжҚўеҸҘиҜқиҜҙпјҢе°ұжҳҜз”ЁжҲ·дёҚе…Ғи®ёжү«жҸҸжүҖжңүеҲҶеҢәгҖӮиҝӣиЎҢиҝҷдёӘйҷҗеҲ¶зҡ„еҺҹеӣ жҳҜпјҢйҖҡеёёеҲҶеҢәиЎЁйғҪжӢҘжңүйқһеёёеӨ§зҡ„ж•°жҚ®йӣҶпјҢиҖҢдё”ж•°жҚ®еўһеҠ иҝ…йҖҹгҖӮжІЎжңүиҝӣиЎҢеҲҶеҢәйҷҗеҲ¶зҡ„жҹҘиҜўеҸҜиғҪдјҡж¶ҲиҖ—д»ӨдәәдёҚеҸҜжҺҘеҸ—зҡ„е·ЁеӨ§иө„жәҗжқҘеӨ„зҗҶиҝҷдёӘиЎЁгҖӮ
2пјүеҜ№дәҺдҪҝз”ЁдәҶorder byиҜӯеҸҘзҡ„жҹҘиҜўпјҢиҰҒжұӮеҝ…йЎ»дҪҝз”ЁlimitиҜӯеҸҘгҖӮеӣ дёәorder byдёәдәҶжү§иЎҢжҺ’еәҸиҝҮзЁӢдјҡе°ҶжүҖжңүзҡ„з»“жһңж•°жҚ®еҲҶеҸ‘еҲ°еҗҢдёҖдёӘReducerдёӯиҝӣиЎҢеӨ„зҗҶпјҢејәеҲ¶иҰҒжұӮз”ЁжҲ·еўһеҠ иҝҷдёӘLIMITиҜӯеҸҘеҸҜд»ҘйҳІжӯўReducerйўқеӨ–жү§иЎҢеҫҲй•ҝдёҖж®өж—¶й—ҙгҖӮ
3пјүйҷҗеҲ¶з¬ӣеҚЎе°”з§Ҝзҡ„жҹҘиҜўгҖӮеҜ№е…ізі»еһӢж•°жҚ®еә“йқһеёёдәҶи§Јзҡ„з”ЁжҲ·еҸҜиғҪжңҹжңӣеңЁжү§иЎҢJOINжҹҘиҜўзҡ„ж—¶еҖҷдёҚдҪҝз”ЁONиҜӯеҸҘиҖҢжҳҜдҪҝз”ЁwhereиҜӯеҸҘпјҢиҝҷж ·е…ізі»ж•°жҚ®еә“зҡ„жү§иЎҢдјҳеҢ–еҷЁе°ұеҸҜд»Ҙй«ҳж•Ҳең°е°ҶWHEREиҜӯеҸҘиҪ¬еҢ–жҲҗйӮЈдёӘONиҜӯеҸҘгҖӮдёҚе№ёзҡ„жҳҜпјҢHive并дёҚдјҡжү§иЎҢиҝҷз§ҚдјҳеҢ–пјҢеӣ жӯӨпјҢеҰӮжһңиЎЁи¶іеӨҹеӨ§пјҢйӮЈд№ҲиҝҷдёӘжҹҘиҜўе°ұдјҡеҮәзҺ°дёҚеҸҜжҺ§зҡ„жғ…еҶөгҖӮ
JVMйҮҚз”ЁжҳҜHadoopи°ғдјҳеҸӮж•°зҡ„еҶ…е®№пјҢе…¶еҜ№Hiveзҡ„жҖ§иғҪе…·жңүйқһеёёеӨ§зҡ„еҪұе“ҚпјҢзү№еҲ«жҳҜеҜ№дәҺеҫҲйҡҫйҒҝе…Қе°Ҹж–Ү件зҡ„еңәжҷҜжҲ–taskзү№еҲ«еӨҡзҡ„еңәжҷҜпјҢиҝҷзұ»еңәжҷҜеӨ§еӨҡж•°жү§иЎҢж—¶й—ҙйғҪеҫҲзҹӯгҖӮ
Hadoopзҡ„й»ҳи®Өй…ҚзҪ®йҖҡеёёжҳҜдҪҝз”Ёжҙҫз”ҹJVMжқҘжү§иЎҢmapе’ҢReduceд»»еҠЎзҡ„гҖӮиҝҷж—¶JVMзҡ„еҗҜеҠЁиҝҮзЁӢеҸҜиғҪдјҡйҖ жҲҗзӣёеҪ“еӨ§зҡ„ејҖй”ҖпјҢе°Өе…¶жҳҜжү§иЎҢзҡ„jobеҢ…еҗ«жңүжҲҗзҷҫдёҠеҚғtaskд»»еҠЎзҡ„жғ…еҶөгҖӮJVMйҮҚз”ЁеҸҜд»ҘдҪҝеҫ—JVMе®һдҫӢеңЁеҗҢдёҖдёӘjobдёӯйҮҚж–°дҪҝз”ЁNж¬ЎгҖӮNзҡ„еҖјеҸҜд»ҘеңЁHadoopзҡ„mapred-site.xmlж–Ү件дёӯиҝӣиЎҢй…ҚзҪ®гҖӮйҖҡеёёеңЁ10-20д№Ӣй—ҙпјҢе…·дҪ“еӨҡе°‘йңҖиҰҒж №жҚ®е…·дҪ“дёҡеҠЎеңәжҷҜжөӢиҜ•еҫ—еҮәгҖӮ
<property> <name>mapreduce.job.jvm.numtasks</name> <value>10</value> <description>How many tasks to run per jvm. If set to -1, there is no limit. </description> </property>
еҪ“еүҚиҝҷдёӘд№ҹжңүзјәзӮ№пјҢиҝҷдёӘеҠҹиғҪзҡ„зјәзӮ№жҳҜпјҢејҖеҗҜJVMйҮҚз”Ёе°ҶдёҖзӣҙеҚ з”ЁдҪҝз”ЁеҲ°зҡ„taskжҸ’ж§ҪпјҢд»ҘдҫҝиҝӣиЎҢйҮҚз”ЁпјҢзӣҙеҲ°д»»еҠЎе®ҢжҲҗеҗҺжүҚиғҪйҮҠж”ҫпјҢд№ҹе°ұиҜҙзӯүж•ҙдёӘjobжү§иЎҢе®ҢжҜ•еҗҺпјҢеҚ з”Ёзҡ„жүҖжңүjvmжүҚдјҡйҮҠж”ҫгҖӮеҰӮжһңжҹҗдёӘвҖңдёҚе№іиЎЎзҡ„вҖқjobдёӯжңүжҹҗеҮ дёӘreduce taskжү§иЎҢзҡ„ж—¶й—ҙиҰҒжҜ”е…¶д»–Reduce taskж¶ҲиҖ—зҡ„ж—¶й—ҙеӨҡзҡ„еӨҡзҡ„иҜқпјҢйӮЈд№Ҳж•ҙдёӘjobдҝқз•ҷзҡ„жҸ’ж§Ҫе°ұдјҡдёҖзӣҙз©әй—ІзқҖеҚҙж— жі•иў«е…¶д»–зҡ„jobдҪҝз”ЁпјҢзӣҙеҲ°жүҖжңүзҡ„taskйғҪз»“жқҹдәҶжүҚдјҡйҮҠж”ҫгҖӮ
е…ідәҺMapReduceзҡ„жҺЁжөӢжү§иЎҢи§ҒMapReduceйғЁеҲҶзҡ„жҺЁжөӢжү§иЎҢзӣёе…ізҡ„еҶ…е®№пјҢиҝҷйҮҢдёҚйҮҚеӨҚгҖӮ
иҖҢhiveиҮӘе·ұд№ҹжңүжҸҗдҫӣдәҶй…ҚзҪ®йЎ№жқҘжҺ§еҲ¶reduce-sideзҡ„жҺЁжөӢжү§иЎҢпјҡ
<property> <name>hive.mapred.reduce.tasks.lative.execution</name> <value>true</value> <description>Whether speculative execution for reducers should be turned on. </description> </property>
е…ідәҺи°ғдјҳиҝҷдәӣжҺЁжөӢжү§иЎҢеҸҳйҮҸпјҢиҝҳеҫҲйҡҫз»ҷдёҖдёӘе…·дҪ“зҡ„е»әи®®гҖӮеҰӮжһңз”ЁжҲ·еҜ№дәҺиҝҗиЎҢж—¶зҡ„еҒҸе·®йқһеёёж•Ҹж„ҹзҡ„иҜқпјҢйӮЈд№ҲеҸҜд»Ҙе°ҶиҝҷдәӣеҠҹиғҪе…ій—ӯжҺүгҖӮеҰӮжһңз”ЁжҲ·еӣ дёәиҫ“е…Ҙж•°жҚ®йҮҸеҫҲеӨ§иҖҢйңҖиҰҒжү§иЎҢй•ҝж—¶й—ҙзҡ„mapжҲ–иҖ…Reduce taskзҡ„иҜқпјҢйӮЈд№ҲеҗҜеҠЁжҺЁжөӢжү§иЎҢйҖ жҲҗзҡ„жөӘиҙ№жҳҜйқһеёёе·ЁеӨ§еӨ§гҖӮ
иҝҷдёӘеҸҜд»ҘзңӢвҖңhive--еҹәжң¬еҺҹзҗҶвҖқдёӯеҺӢзј©зӣёе…іеҶ…е®№гҖӮдё»иҰҒе°ұжҳҜд»ҺеҮҸе°‘mapе’Ңreduceдј йҖ’зҡ„ж•°жҚ®йҮҸпјҢд»ҘеҸҠеҮҸе°‘reduceиҫ“еҮәж–Ү件зҡ„еӨ§е°ҸиҝӣиЎҢдјҳеҢ–гҖӮ
жү§иЎҢsqlд»»еҠЎж—¶пјҢеҸҜд»ҘдҪҝз”Ё explainжҹҘзңӢжү§иЎҢзҡ„йў„и®ЎиҝҮзЁӢпјҢзңӢзңӢжңүжІЎжңүеҸҜдјҳеҢ–зҡ„зӮ№гҖӮ
пјҲ1пјүжҹҘзңӢдёӢйқўиҝҷжқЎиҜӯеҸҘзҡ„жү§иЎҢи®ЎеҲ’ hive (default)> explain select * from emp; пјҲ2пјүжҹҘзңӢиҜҰз»Ҷжү§иЎҢи®ЎеҲ’ hive (default)> explain extended select * from emp;
д»ҘдёҠжҳҜвҖңhiveдҪҝз”ЁиҝҮзЁӢдёӯжңүе“Әдәӣи°ғдјҳзӯ–з•ҘвҖқиҝҷзҜҮж–Үз« зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒеёҢжңӣеҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүеё®еҠ©пјҢжӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ