您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
数据库完整性:是指数据库中数据在逻辑上的一致性、正确性、有效性和相容性
实体完整性(Entity Integrity 行完整性):实体完整性指表中行的完整性。主要用于保证操作的数据(记录)非空、唯一且不重复。即实体完整性要求每个关系(表)有且仅有一个主键,每一个主键值必须唯一,而且不允许为“空”(NULL)或重复。
域完整性(Domain Integrity 列完整性):是指数据库表中的列必须满足某种特定的数据类型或约束。其中约束又包括取值范围、精度等规定。表中的CHECK、FOREIGN KEY 约束和DEFAULT、 NOT NULL定义都属于域完整性的范畴。
参照完整性(Referential Integrity)属于表间规则:对于永久关系的相关表,在更新、插入或删除记录时,如果只改其一,就会影响数据的完整性。如删除父表的某记录后,子表的相应记录未删除,致使这些记录称为孤立记录。
参照完整性规则(Referential Integrity)要求:若属性组F是关系模式R1的主键,同时F也是关系模式R2的外键,则在R2的关系中,F的取值只允许两种可能:空值或等于R1关系中某个主键值。
Sql Server的存储结构,页、区、堆
页:用于数据存储的连续的磁盘空间块,SQL Server中数据存储的基本单位是页,磁盘I/O操作在页级执行,页的大小为8KB。每页的开头是96字节的页头,用于存储有关页的系统信息,包括页码、页类型、页的可用空间以及拥有该页的对象的分配单元ID;其他便是存储数据的数据行与剩下可用空间,结构图如下(个人绘制)
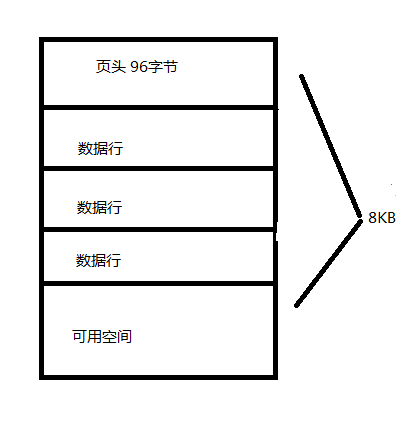
区间:区是管理空间的基本单位,一个区是8个物理上连续的页(即64KB)的集合,所有页都存储在区中。SQL Server有两种类型的区:统一区和混合区。
堆:堆是指不含聚集索引的表,它的数据不按任何顺序进行存储。
联系一个堆中的数据的唯一结构是被称为索引分配映射(IAM)的一个位图页,当扫描对象时,SQl server使用IAM页来遍历该对象的数据。
堆表内的数据页和行没有任何特定的顺序,也不链接在一起。数据页之间唯一的逻辑连接是记录在IAM页内的信息
假设某订单明细表中有100万条数据,需要查询某个订单的明细数据,如下:
select*fromT_EPZ_INOUT_ENTRY_DETAILwhereentry_apply_id='31227000034000090169'
如果在堆表中进行查询,SQLServer通过扫描IAM页对堆表进行全表扫描,对entry_apply_id比较100万次,如果以entry_apply_id字段建立索引,则因为索引键值数据都必定以B-Tree有顺序的摆放,所以可采用二分查找找数据。也就是2的N次方大于记录数,就可以找到该条数据。而2的20次方大于100万,因此最多找寻20次就可以找到该条记录。20次与100万次的比较,你可以轻松感受出性能的差异。
由此引出索引的概念
索引分为聚集索引与非聚集索引
聚集索引 :聚集索引是指数据库表行中数据的物理顺序与键值的逻辑(索引)顺序相同。一个表只能有一个聚集索引,因为一个表的物理顺序只有一种情况,所以,对应的聚集索引只能有一个。如果某索引不是聚集索引,则表中的行物理顺序与索引顺序不匹配,与非聚集索引相比,聚集索引有着更快的检索速度
非聚集索引:非聚集索引是一种索引,该索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同
聚集索引与非聚集索引的形象比喻
汉语字典的正文本身就是一个聚集索引。 比如,我们要查“安”字,就会很自然地翻开字典的前几页,因为“安”的拼音是“an”,而按照拼音排序汉字的字典是以英文字母“a”开头并以“z”结尾的,那么“安”字就自然地排在字典的前部。如果您翻完了所有以“a”开头的部分仍然找不到这个字,那么就说明您的字典中没有这个字;同样的,如果查“张”字,那您也会将您的字典翻到最后部分,因为“张”的拼音是“zhang”。也就是说,字典的正文部分本身就是一个目录,您不需要再去查其他目录来找到您需要找的内容。正文内容本身就是一种按照一定规则排列的目录称为“聚集索引”。每个表只能有一个聚集索引,因为目录只能按照一种方法进行排序
如果您认识某个字,您可以快速地从自动中查到这个字。但您也可能会遇到您不认识的字,不知道它的发音,这时候,您就不能按照刚才的方法找到您要查的字,而需要去根据“偏旁部首”查到您要找的字,然后根据这个字后的页码直接翻到某页来找到您要找的字。但您结合“部首目录”和“检字表”而查到的字的排序并不是真正的正文的排序方法,比如您查“张”字,我们可以看到在查部首之后的检字表中“张”的页码是672页,检字表中“张”的上面是“驰”字,但页码却是63页,“张”的下面是“弩”字,页面是390页。很显然,这些字并不是真正的分别位于“张”字的上下方,现在您看到的连续的“驰、张、弩”三字实际上就是他们在非聚集索引中的排序,是字典正文中的字在非聚集索引中的映射。我们可以通过这种方式来找到您所需要的字,但它需要两个过程,先找到目录中的结果,然后再翻到您所需要的页码。我们把这种目录纯粹是目录,正文纯粹是正文的排序方式称为“非聚集索引”。
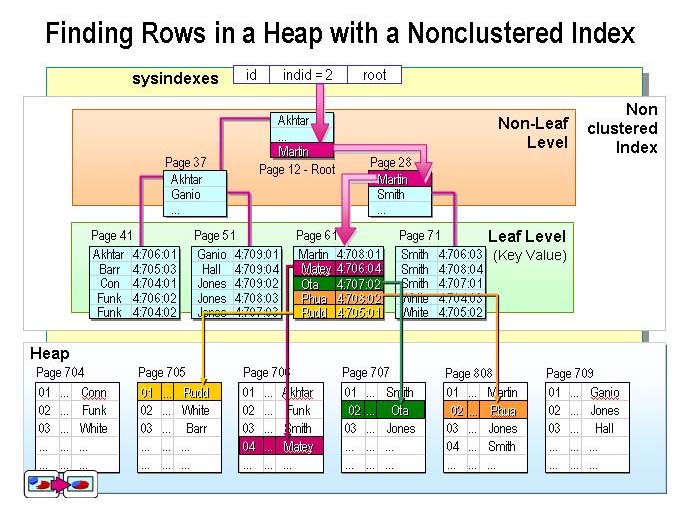
如图,表中存放的数据是杂乱无章的,没有按照姓名进行排序。我们将数据的姓名提取出来按照姓名创建一个非聚集索引。索引中姓名是排好序的,且索引所占用的空间远远小于表中数据所占用的空间,当我们查询表中某条数据时候,将不再进行全表扫描,而对索引进行扫描,得到想要的数据再定位到表中具体的数据。 但是 在非聚集索引上,要扫描某个具体的姓名也得耗费一定的时间,进一步优化,在其上面在加一个Non-leaf level (非叶节点)可以B树算法快速的定位。极大的提高了查询速度
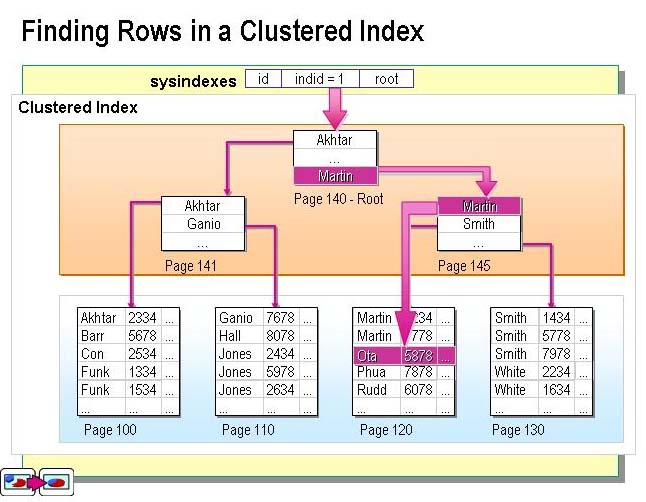
聚集索引的查询就是按B树查询
如何查询表中的索引?
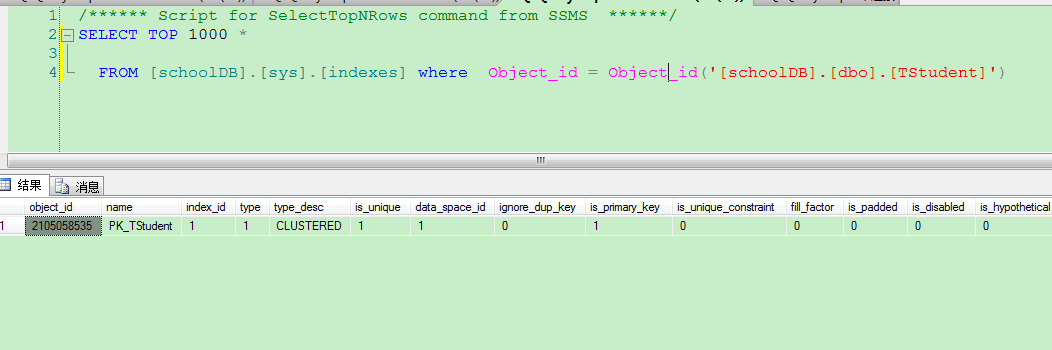
inidex_id = 0 说明表中无索引 inidex_id = 1 表中为聚集索引, inidex_id = 2或者3.。。。。为非聚集索引。
运用索引遇到的问题以及技术
页分裂、填充因子、碎片整理、索引统计
页分裂:因为在非聚集索引中或者有序的数据中 如 在a b e f中要插入新的数据 c ,那么c在物理顺序中将放入f的后面,成为 a b e f c这样变造成了页分裂。
可以用索引整理、或者在建表时定义填充因子(就是页创建之初,让每个页存储的数据占页的比列)解决页分裂的情况
dbcc showcontig(Tstudent,non_sname) --Tstudent表明,PK_TStudent索引名 ,查询页分裂情况 dbcc indexdefrag(schoolDB,Tstudent,non_sname)--索引整理 create nonclustered index non_sname on TStudent(sname) with drop_existing,fillfactor = 50--重建索引,并且制定填充因子 dbcc show_statistics(tstudent,non_sname)--查看索引统计 update statistics schooldb.dbo.tstudent --人工更新表中所有索引的统计 update statistics schooldb.dbo.tstudent non_sname --人工更新表中non_sname索引统计
在实际情况中,有时候不同索引会比用索引的速度更快,在运用索引查询的时候,但是sql server工具会自动帮你判断
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对亿速云的支持。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。