жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
зј–еҶҷMRзЁӢеәҸпјҢи®©е…¶еҸҜд»ҘйҖӮеҗҲеӨ§йғЁеҲҶзҡ„HBaseиЎЁж•°жҚ®еҜје…ҘеҲ°HBaseиЎЁж•°жҚ®гҖӮе…¶дёӯеҢ…жӢ¬еҸҜд»Ҙи®ҫзҪ®зүҲжң¬ж•°гҖҒеҸҜд»Ҙи®ҫзҪ®иҫ“е…ҘиЎЁзҡ„еҲ—еҜје…Ҙи®ҫзҪ®(йҖүеҸ–е…¶дёӯжҹҗеҮ еҲ—)гҖҒеҸҜд»Ҙи®ҫзҪ®иҫ“еҮәиЎЁзҡ„еҲ—еҜјеҮәи®ҫзҪ®(йҖүеҸ–е…¶дёӯжҹҗеҮ еҲ—)гҖӮ
еҺҹе§ӢиЎЁtest1ж•°жҚ®еҰӮдёӢпјҡ
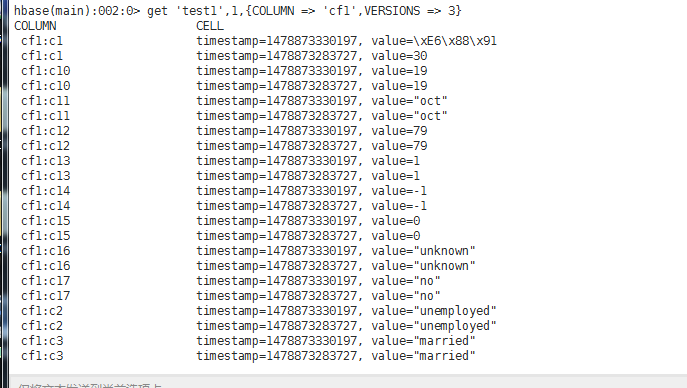
жҜҸдёӘrow keyйғҪжңүдёӨдёӘзүҲжң¬зҡ„ж•°жҚ®пјҢиҝҷйҮҢеҸӘжҳҫзӨәдәҶrow keyдёә1зҡ„ж•°жҚ®
еңЁhbase shell дёӯеҲӣе»әж•°жҚ®иЎЁпјҡ
create 'test2',{NAME => 'cf1',VERSIONS => 10} // дҝқеӯҳж— зүҲжң¬гҖҒж— еҲ—еҜје…Ҙи®ҫзҪ®гҖҒж— еҲ—еҜјеҮәи®ҫзҪ®зҡ„ж•°жҚ®
create 'test3',{NAME => 'cf1',VERSIONS => 10} // дҝқеӯҳж— зүҲжң¬гҖҒж— еҲ—еҜје…Ҙи®ҫзҪ®гҖҒжңүеҲ—еҜјеҮәи®ҫзҪ®зҡ„ж•°жҚ®
create 'test4',{NAME => 'cf1',VERSIONS => 10} // дҝқеӯҳж— зүҲжң¬гҖҒжңүеҲ—еҜје…Ҙи®ҫзҪ®гҖҒж— еҲ—еҜјеҮәи®ҫзҪ®зҡ„ж•°жҚ®
create 'test5',{NAME => 'cf1',VERSIONS => 10} // дҝқеӯҳжңүзүҲжң¬гҖҒж— еҲ—еҜје…Ҙи®ҫзҪ®гҖҒж— еҲ—еҜјеҮәи®ҫзҪ®зҡ„ж•°жҚ®
create 'test6',{NAME => 'cf1',VERSIONS => 10} // дҝқеӯҳжңүзүҲжң¬гҖҒж— еҲ—еҜје…Ҙи®ҫзҪ®гҖҒжңүеҲ—еҜјеҮәи®ҫзҪ®зҡ„ж•°жҚ®
create 'test7',{NAME => 'cf1',VERSIONS => 10} // дҝқеӯҳжңүзүҲжң¬гҖҒжңүеҲ—еҜје…Ҙи®ҫзҪ®гҖҒж— еҲ—еҜјеҮәи®ҫзҪ®зҡ„ж•°жҚ®
create 'test8',{NAME => 'cf1',VERSIONS => 10} // дҝқеӯҳжңүзүҲжң¬гҖҒжңүеҲ—еҜје…Ҙи®ҫзҪ®гҖҒжңүеҲ—еҜјеҮәи®ҫзҪ®зҡ„ж•°жҚ®
mainеҮҪж•°е…ҘеҸЈпјҡ
package GeneralHBaseToHBase;
import org.apache.hadoop.util.ToolRunner;
public class DriverTest {
public static void main(String[] args) throws Exception {
// ж— зүҲжң¬и®ҫзҪ®гҖҒж— еҲ—еҜје…Ҙи®ҫзҪ®пјҢж— еҲ—еҜјеҮәи®ҫзҪ®
String[] myArgs1= new String[]{
"test1", // иҫ“е…ҘиЎЁ
"test2", // иҫ“еҮәиЎЁ
"0", // зүҲжң¬еӨ§е°Ҹж•°пјҢеҰӮжһңеҖјдёә0пјҢеҲҷдёәй»ҳи®Өд»Һиҫ“е…ҘиЎЁеҜјеҮәжңҖж–°зҡ„ж•°жҚ®еҲ°иҫ“еҮәиЎЁ
"-1", // еҲ—еҜје…Ҙи®ҫзҪ®пјҢеҰӮжһңдёә-1 пјҢеҲҷжІЎжңүи®ҫзҪ®еҲ—еҜје…Ҙ
"-1" // еҲ—еҜјеҮәи®ҫзҪ®пјҢеҰӮжһңдёә-1пјҢеҲҷжІЎжңүи®ҫзҪ®еҲ—еҜјеҮә
};
ToolRunner.run(HBaseDriver.getConfiguration(),
new HBaseDriver(),
myArgs1);
// ж— зүҲжң¬и®ҫзҪ®гҖҒжңүеҲ—еҜје…Ҙи®ҫзҪ®пјҢж— еҲ—еҜјеҮәи®ҫзҪ®
String[] myArgs2= new String[]{
"test1",
"test3",
"0",
"cf1:c1,cf1:c2,cf1:c10,cf1:c11,cf1:c14",
"-1"
};
ToolRunner.run(HBaseDriver.getConfiguration(),
new HBaseDriver(),
myArgs2);
// ж— зүҲжң¬и®ҫзҪ®пјҢж— еҲ—еҜје…Ҙи®ҫзҪ®пјҢжңүеҲ—еҜјеҮәи®ҫзҪ®
String[] myArgs3= new String[]{
"test1",
"test4",
"0",
"-1",
"cf1:c1,cf1:c10,cf1:c14"
};
ToolRunner.run(HBaseDriver.getConfiguration(),
new HBaseDriver(),
myArgs3);
// жңүзүҲжң¬и®ҫзҪ®пјҢж— еҲ—еҜје…Ҙи®ҫзҪ®пјҢж— еҲ—еҜјеҮәи®ҫзҪ®
String[] myArgs4= new String[]{
"test1",
"test5",
"2",
"-1",
"-1"
};
ToolRunner.run(HBaseDriver.getConfiguration(),
new HBaseDriver(),
myArgs4);
// жңүзүҲжң¬и®ҫзҪ®гҖҒжңүеҲ—еҜје…Ҙи®ҫзҪ®пјҢж— еҲ—еҜјеҮәи®ҫзҪ®
String[] myArgs5= new String[]{
"test1",
"test6",
"2",
"cf1:c1,cf1:c2,cf1:c10,cf1:c11,cf1:c14",
"-1"
};
ToolRunner.run(HBaseDriver.getConfiguration(),
new HBaseDriver(),
myArgs5);
// жңүзүҲжң¬и®ҫзҪ®гҖҒж— еҲ—еҜје…Ҙи®ҫзҪ®пјҢжңүеҲ—еҜјеҮәи®ҫзҪ®
String[] myArgs6= new String[]{
"test1",
"test7",
"2",
"-1",
"cf1:c1,cf1:c10,cf1:c14"
};
ToolRunner.run(HBaseDriver.getConfiguration(),
new HBaseDriver(),
myArgs6);
// жңүзүҲжң¬и®ҫзҪ®гҖҒжңүеҲ—еҜје…Ҙи®ҫзҪ®пјҢжңүеҲ—еҜјеҮәи®ҫзҪ®
String[] myArgs7= new String[]{
"test1",
"test8",
"2",
"cf1:c1,cf1:c2,cf1:c10,cf1:c11,cf1:c14",
"cf1:c1,cf1:c10,cf1:c14"
};
ToolRunner.run(HBaseDriver.getConfiguration(),
new HBaseDriver(),
myArgs7);
}
}
driverпјҡ
package GeneralHBaseToHBase;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.util.Tool;
import util.JarUtil;
public class HBaseDriver extends Configured implements Tool{
public static String FROMTABLE=""; //еҜје…ҘиЎЁ
public static String TOTABLE=""; //еҜјеҮәиЎЁ
public static String SETVERSION=""; //жҳҜеҗҰи®ҫзҪ®зүҲжң¬
// args => {FromTable,ToTable,SetVersion,ColumnFromTable,ColumnToTable}
@Override
public int run(String[] args) throws Exception {
if(args.length!=5){
System.err.println("Usage:\n demo.job.HBaseDriver <input> <inputTable> "
+ "<output> <outputTable>"
+"< versions >"
+ " <set columns from inputTable> like <cf1:c1,cf1:c2,cf1:c10,cf1:c11,cf1:c14> or <-1> "
+ "<set columns from outputTable> like <cf1:c1,cf1:c10,cf1:c14> or <-1>");
return -1;
}
Configuration conf = getConf();
FROMTABLE = args[0];
TOTABLE = args[1];
SETVERSION = args[2];
conf.set("SETVERSION", SETVERSION);
if(!args[3].equals("-1")){
conf.set("COLUMNFROMTABLE", args[3]);
}
if(!args[4].equals("-1")){
conf.set("COLUMNTOTABLE", args[4]);
}
String jobName ="From table "+FROMTABLE+ " ,Import to "+ TOTABLE;
Job job = Job.getInstance(conf, jobName);
job.setJarByClass(HBaseDriver.class);
Scan scan = new Scan();
// еҲӨж–ӯжҳҜеҗҰйңҖиҰҒи®ҫзҪ®зүҲжң¬
if(SETVERSION != "0" || SETVERSION != "1"){
scan.setMaxVersions(Integer.parseInt(SETVERSION));
}
// и®ҫзҪ®HBaseиЎЁиҫ“е…ҘпјҡиЎЁеҗҚгҖҒscanгҖҒMapperзұ»гҖҒmapperиҫ“еҮәй”®зұ»еһӢгҖҒmapperиҫ“еҮәеҖјзұ»еһӢ
TableMapReduceUtil.initTableMapperJob(
FROMTABLE,
scan,
HBaseToHBaseMapper.class,
ImmutableBytesWritable.class,
Put.class,
job);
// и®ҫзҪ®HBaseиЎЁиҫ“еҮәпјҡиЎЁеҗҚпјҢreducerзұ»
TableMapReduceUtil.initTableReducerJob(TOTABLE, null, job);
// жІЎжңү reducersпјҢ зӣҙжҺҘеҶҷе…ҘеҲ° иҫ“еҮәж–Ү件
job.setNumReduceTasks(0);
return job.waitForCompletion(true) ? 0 : 1;
}
private static Configuration configuration;
public static Configuration getConfiguration(){
if(configuration==null){
/**
* TODO дәҶи§ЈеҰӮдҪ•зӣҙжҺҘд»ҺWindowsжҸҗдәӨд»Јз ҒеҲ°HadoopйӣҶзҫӨ
* 并дҝ®ж”№е…¶дёӯзҡ„й…ҚзҪ®дёәе®һйҷ…й…ҚзҪ®
*/
configuration = new Configuration();
configuration.setBoolean("mapreduce.app-submission.cross-platform", true);// й…ҚзҪ®дҪҝз”Ёи·Ёе№іеҸ°жҸҗдәӨд»»еҠЎ
configuration.set("fs.defaultFS", "hdfs://master:8020");// жҢҮе®ҡnamenode
configuration.set("mapreduce.framework.name", "yarn"); // жҢҮе®ҡдҪҝз”ЁyarnжЎҶжһ¶
configuration.set("yarn.resourcemanager.address", "master:8032"); // жҢҮе®ҡresourcemanager
configuration.set("yarn.resourcemanager.scheduler.address", "master:8030");// жҢҮе®ҡиө„жәҗеҲҶй…ҚеҷЁ
configuration.set("mapreduce.jobhistory.address", "master:10020");// жҢҮе®ҡhistoryserver
configuration.set("hbase.master", "master:16000");
configuration.set("hbase.rootdir", "hdfs://master:8020/hbase");
configuration.set("hbase.zookeeper.quorum", "slave1,slave2,slave3");
configuration.set("hbase.zookeeper.property.clientPort", "2181");
//TODO йңҖexport->jar file ; и®ҫзҪ®жӯЈзЎ®зҡ„jarеҢ…жүҖеңЁдҪҚзҪ®
configuration.set("mapreduce.job.jar",JarUtil.jar(HBaseDriver.class));// и®ҫзҪ®jarеҢ…и·Ҝеҫ„
}
return configuration;
}
}
mapperпјҡ
package GeneralHBaseToHBase;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map.Entry;
import java.util.NavigableMap;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.util.Bytes;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class HBaseToHBaseMapper extends TableMapper<ImmutableBytesWritable, Put> {
Logger log = LoggerFactory.getLogger(HBaseToHBaseMapper.class);
private static int versionNum = 0;
private static String[] columnFromTable = null;
private static String[] columnToTable = null;
private static String column1 = null;
private static String column2 = null;
@Override
protected void setup(Context context)
throws IOException, InterruptedException {
Configuration conf = context.getConfiguration();
versionNum = Integer.parseInt(conf.get("SETVERSION", "0"));
column1 = conf.get("COLUMNFROMTABLE",null);
if(!(column1 == null)){
columnFromTable = column1.split(",");
}
column2 = conf.get("COLUMNTOTABLE",null);
if(!(column2 == null)){
columnToTable = column2.split(",");
}
}
@Override
protected void map(ImmutableBytesWritable key, Result value,
Context context)
throws IOException, InterruptedException {
context.write(key, resultToPut(key,value));
}
/***
* жҠҠkeyпјҢvalueиҪ¬жҚўдёәPut
* @param key
* @param value
* @return
* @throws IOException
*/
private Put resultToPut(ImmutableBytesWritable key, Result value) throws IOException {
HashMap<String, String> fTableMap = new HashMap<>();
HashMap<String, String> tTableMap = new HashMap<>();
Put put = new Put(key.get());
if(! (columnFromTable == null || columnFromTable.length == 0)){
fTableMap = getFamilyAndColumn(columnFromTable);
}
if(! (columnToTable == null || columnToTable.length == 0)){
tTableMap = getFamilyAndColumn(columnToTable);
}
if(versionNum==0){
if(fTableMap.size() == 0){
if(tTableMap.size() == 0){
for (Cell kv : value.rawCells()) {
put.add(kv); // жІЎжңүи®ҫзҪ®зүҲжң¬пјҢжІЎжңүи®ҫзҪ®еҲ—еҜје…ҘпјҢжІЎжңүи®ҫзҪ®еҲ—еҜјеҮә
}
return put;
} else{
return getPut(put, value, tTableMap); // ж— зүҲжң¬гҖҒж— еҲ—еҜје…ҘгҖҒжңүеҲ—еҜјеҮә
}
} else {
if(tTableMap.size() == 0){
return getPut(put, value, fTableMap);// ж— зүҲжң¬гҖҒжңүеҲ—еҜје…ҘгҖҒж— еҲ—еҜјеҮә
} else {
return getPut(put, value, tTableMap);// ж— зүҲжң¬гҖҒжңүеҲ—еҜје…ҘгҖҒжңүеҲ—еҜјеҮә
}
}
} else{
if(fTableMap.size() == 0){
if(tTableMap.size() == 0){
return getPut1(put, value); // жңүзүҲжң¬пјҢж— еҲ—еҜје…ҘпјҢж— еҲ—еҜјеҮә
}else{
return getPut2(put, value, tTableMap); //жңүзүҲжң¬пјҢж— еҲ—еҜје…ҘпјҢжңүеҲ—еҜјеҮә
}
}else{
if(tTableMap.size() == 0){
return getPut2(put,value,fTableMap);// жңүзүҲжң¬пјҢжңүеҲ—еҜје…ҘпјҢж— еҲ—еҜјеҮә
}else{
return getPut2(put,value,tTableMap); // жңүзүҲжң¬пјҢжңүеҲ—еҜје…ҘпјҢжңүеҲ—еҜјеҮә
}
}
}
}
/***
* ж— зүҲжң¬и®ҫзҪ®зҡ„жғ…еҶөдёӢпјҢеҜ№дәҺжңүеҲ—еҜје…ҘжҲ–иҖ…еҲ—еҜјеҮә
* @param put
* @param value
* @param tableMap
* @return
* @throws IOException
*/
private Put getPut(Put put,Result value,HashMap<String, String> tableMap) throws IOException{
for(Cell kv : value.rawCells()){
byte[] family = kv.getFamily();
if(tableMap.containsKey(new String(family))){
String columnStr = tableMap.get(new String(family));
ArrayList<String> columnBy = toByte(columnStr);
if(columnBy.contains(new String(kv.getQualifier()))){
put.add(kv); //жІЎжңүи®ҫзҪ®зүҲжң¬пјҢжІЎжңүи®ҫзҪ®еҲ—еҜје…ҘпјҢжңүи®ҫзҪ®еҲ—еҜјеҮә
}
}
}
return put;
}
/***
* (жңүзүҲжң¬пјҢж— еҲ—еҜје…ҘпјҢжңүеҲ—еҜјеҮә)жҲ–иҖ…(жңүзүҲжң¬пјҢжңүеҲ—еҜје…ҘпјҢж— еҲ—еҜјеҮә)
* @param put
* @param value
* @param tTableMap
* @return
*/
private Put getPut2(Put put,Result value,HashMap<String, String> tableMap){
NavigableMap<byte[], NavigableMap<byte[], NavigableMap<Long, byte[]>>> map=value.getMap();
for(byte[] family:map.keySet()){
if(tableMap.containsKey(new String(family))){
String columnStr = tableMap.get(new String(family));
log.info("@@@@@@@@@@@"+new String(family)+" "+columnStr);
ArrayList<String> columnBy = toByte(columnStr);
NavigableMap<byte[], NavigableMap<Long, byte[]>> familyMap = map.get(family);//еҲ—з°ҮдҪңдёәkeyиҺ·еҸ–е…¶дёӯзҡ„еҲ—зӣёе…іж•°жҚ®
for(byte[] column:familyMap.keySet()){ //ж №жҚ®еҲ—еҗҚеҫӘеқҸ
log.info("!!!!!!!!!!!"+new String(column));
if(columnBy.contains(new String(column))){
NavigableMap<Long, byte[]> valuesMap = familyMap.get(column);
for(Entry<Long, byte[]> s:valuesMap.entrySet()){//иҺ·еҸ–еҲ—еҜ№еә”зҡ„дёҚеҗҢзүҲжң¬ж•°жҚ®пјҢй»ҳи®ӨжңҖж–°зҡ„дёҖдёӘ
System.out.println("***:"+new String(family)+" "+new String(column)+" "+s.getKey()+" "+new String(s.getValue()));
put.addColumn(family, column, s.getKey(),s.getValue());
}
}
}
}
}
return put;
}
/***
* жңүзүҲжң¬гҖҒж— еҲ—еҜје…ҘгҖҒж— еҲ—еҜјеҮә
* @param put
* @param value
* @return
*/
private Put getPut1(Put put,Result value){
NavigableMap<byte[], NavigableMap<byte[], NavigableMap<Long, byte[]>>> map=value.getMap();
for(byte[] family:map.keySet()){
NavigableMap<byte[], NavigableMap<Long, byte[]>> familyMap = map.get(family);//еҲ—з°ҮдҪңдёәkeyиҺ·еҸ–е…¶дёӯзҡ„еҲ—зӣёе…іж•°жҚ®
for(byte[] column:familyMap.keySet()){ //ж №жҚ®еҲ—еҗҚеҫӘеқҸ
NavigableMap<Long, byte[]> valuesMap = familyMap.get(column);
for(Entry<Long, byte[]> s:valuesMap.entrySet()){ //иҺ·еҸ–еҲ—еҜ№еә”зҡ„дёҚеҗҢзүҲжң¬ж•°жҚ®пјҢй»ҳи®ӨжңҖж–°зҡ„дёҖдёӘ
put.addColumn(family, column, s.getKey(),s.getValue());
}
}
}
return put;
}
// str => {"cf1:c1","cf1:c2","cf1:c10","cf1:c11","cf1:c14"}
/***
* еҫ—еҲ°еҲ—з°ҮеҗҚдёҺеҲ—еҗҚзҡ„k,vеҪўејҸзҡ„map
* @param str => {"cf1:c1","cf1:c2","cf1:c10","cf1:c11","cf1:c14"}
* @return map => {"cf1" => "c1,c2,c10,c11,c14"}
*/
private static HashMap<String, String> getFamilyAndColumn(String[] str){
HashMap<String, String> map = new HashMap<>();
HashSet<String> set = new HashSet<>();
for(String s : str){
set.add(s.split(":")[0]);
}
Object[] ob = set.toArray();
for(int i=0; i<ob.length;i++){
String family = String.valueOf(ob[i]);
String columns = "";
for(int j=0;j < str.length;j++){
if(family.equals(str[j].split(":")[0])){
columns += str[j].split(":")[1]+",";
}
}
map.put(family, columns.substring(0, columns.length()-1));
}
return map;
}
private static ArrayList<String> toByte(String s){
ArrayList<String> b = new ArrayList<>();
String[] sarr = s.split(",");
for(int i=0;i<sarr.length;i++){
b.add(sarr[i]);
}
return b;
}
}
зЁӢеәҸиҝҗиЎҢе®Ңд№ӢеҗҺпјҢеңЁhbase shellдёӯжҹҘзңӢжҜҸдёӘиЎЁпјҢзңӢжҳҜеҗҰж•°жҚ®еҜје…ҘжӯЈзЎ®пјҡ
test2пјҡ(ж— зүҲжң¬гҖҒж— еҲ—еҜје…Ҙи®ҫзҪ®гҖҒж— еҲ—еҜјеҮәи®ҫзҪ®)
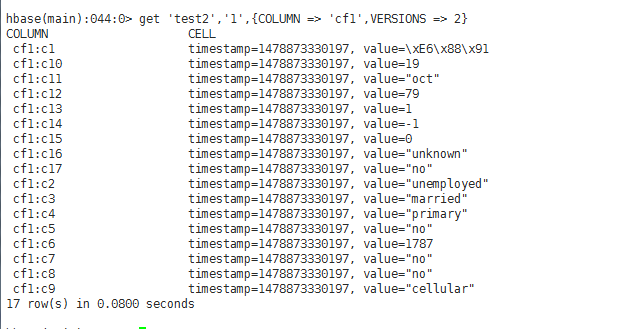
test3 (ж— зүҲжң¬гҖҒжңүеҲ—еҜје…Ҙи®ҫзҪ®("cf1:c1,cf1:c2,cf1:c10,cf1:c11,cf1:c14")гҖҒж— еҲ—еҜјеҮәи®ҫзҪ®)
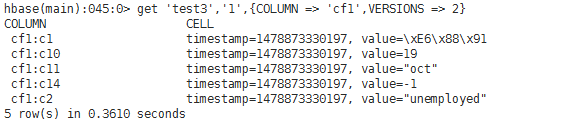
test4(ж— зүҲжң¬гҖҒж— еҲ—еҜје…Ҙи®ҫзҪ®гҖҒжңүеҲ—еҜјеҮәи®ҫзҪ®("cf1:c1,cf1:c10,cf1:c14"))
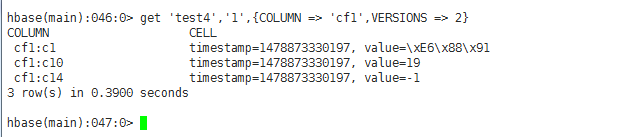
test5(жңүзүҲжң¬гҖҒж— еҲ—еҜје…Ҙи®ҫзҪ®гҖҒж— еҲ—еҜјеҮәи®ҫзҪ®)
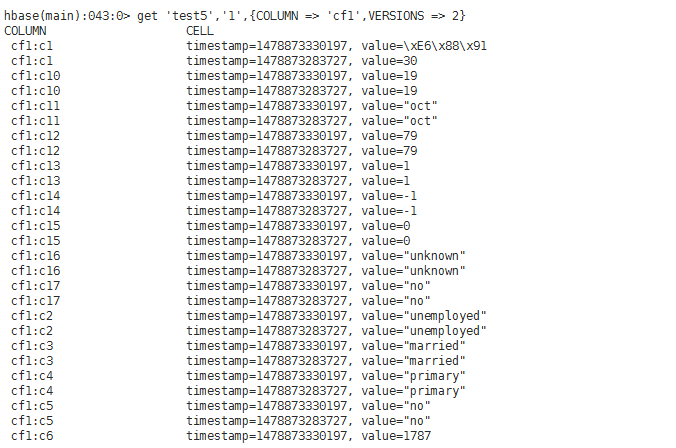
test6(жңүзүҲжң¬гҖҒжңүеҲ—еҜје…Ҙи®ҫзҪ®("cf1:c1,cf1:c2,cf1:c10,cf1:c11,cf1:c14")гҖҒж— еҲ—еҜјеҮәи®ҫзҪ®)
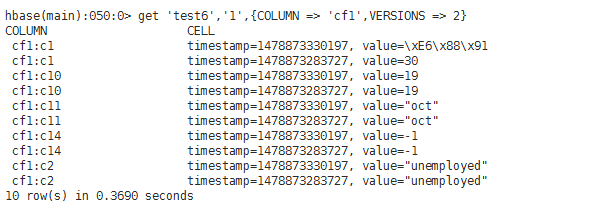
test7(жңүзүҲжң¬гҖҒж— еҲ—еҜје…Ҙи®ҫзҪ®гҖҒжңүеҲ—еҜјеҮәи®ҫзҪ®("cf1:c1,cf1:c10,cf1:c14"))
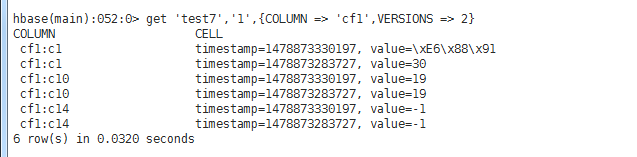
test8(жңүзүҲжң¬гҖҒжңүеҲ—еҜје…Ҙи®ҫзҪ®("cf1:c1,cf1:c2,cf1:c10,cf1:c11,cf1:c14")гҖҒжңүеҲ—еҜјеҮәи®ҫзҪ®("cf1:c1,cf1:c10,cf1:c14"))
д»ҘдёҠе°ұжҳҜжң¬ж–Үзҡ„е…ЁйғЁеҶ…е®№пјҢеёҢжңӣеҜ№еӨ§е®¶зҡ„еӯҰд№ жңүжүҖеё®еҠ©пјҢд№ҹеёҢжңӣеӨ§е®¶еӨҡеӨҡж”ҜжҢҒдәҝйҖҹдә‘гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ