您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要讲解了Python正则表达式匹配中文的方法,内容清晰明了,对此有兴趣的小伙伴可以学习一下,相信大家阅读完之后会有帮助。
用 '[\u4e00-\u9fa5]‘ 匹配中文
在字符串中匹配中文
示例:
匹配字符串中的第一个中文字符
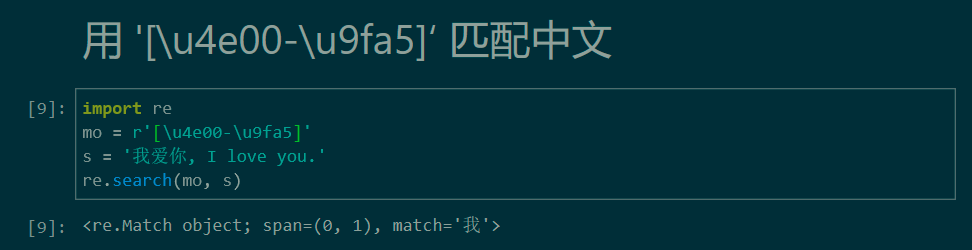
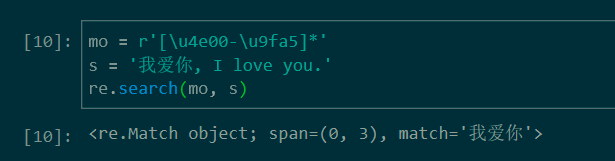
匹配字符串中的第一个连续的中文片段
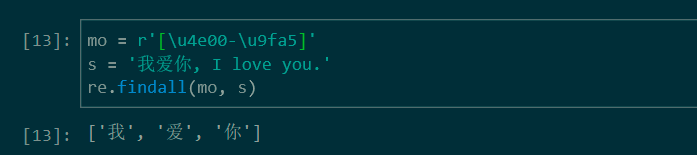
匹配字符串中的所有中文字符

注:要确保正则字符和匹配文本是 unicode 范围内的编码。
其他 扩充 范围
几个主要非英文语系字符范围: 2E80~33FFh:中日韩符号区。收容康熙字典部首、中日韩辅助部首、注音符号、日本假名、韩文音符,中日韩的符号、标点、带圈或带括符文数字、月份,以及日本的假名组合、单位、年号、月份、日期、时间等。 3400~4DFFh:中日韩认同表意文字扩充A区,总计收容6,582个中日韩汉字。 4E00~9FFFh:中日韩认同表意文字区,总计收容20,902个中日韩汉字。 A000~A4FFh:彝族文字区,收容中国南方彝族文字和字根。 AC00~D7FFh:韩文拼音组合字区,收容以韩文音符拼成的文字。 F900~FAFFh:中日韩兼容表意文字区,总计收容302个中日韩汉字。 FB00~FFFDh:文字表现形式区,收容组合拉丁文字、希伯来文、阿拉伯文、中日韩直式标点、小符号、半角符号、全角符号等。
看完上述内容,是不是对Python正则表达式匹配中文的方法有进一步的了解,如果还想学习更多内容,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。