您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本文介绍了Django实现whoosh搜索引擎使用jieba分词,分享给大家,具体如下:
Django版本:3.0.4
python包准备:
pip install django-haystack pip install jieba
使用jieba分词
1.cd到site-packages内的haystack包,创建并编辑ChineseAnalyzer.py文件
# (注意:pip安装的是django-haystack,但是实际包的文件夹名字为haystack) cd /usr/local/lib/python3.8/site-packages/haystack/backends/ # 创建并编辑ChineseAnalyzer.py文件 vim ChineseAnalyzer.py
2.修改ChineseAnalyzer.py文件内容
import jieba
from whoosh.analysis import Tokenizer, Token
class ChineseTokenizer(Tokenizer):
def __call__(self,
value,
positions=False,
chars=False,
keeporiginal=False,
removestops=True,
start_pos=0,
start_char=0,
mode='',
**kwargs):
t = Token(positions, chars, removestops=removestops, mode=mode,**kwargs)
seglist = jieba.cut(value, cut_all=True)
for w in seglist:
t.original = t.text = w
t.boost = 1.0
if positions:
t.pos = start_pos + value.find(w)
if chars:
t.startchar = start_char + value.find(w)
t.endchar = start_char + value.find(w) + len(w)
yield t
def ChineseAnalyzer():
return ChineseTokenizer()
3.替换分词器
cp whoosh_backend.py whoosh_cn_backend.py vim whoosh_cn_backend.py
# 导入ChineseAnalyzer,并将原有的StemmingAnalyser替换为ChineseAnalyzer from .ChineseAnalyzer import ChineseAnalyzer # from whoosh.analysis import StemmingAnalyzer
vim替换命令: %s/StemmingAnalyzer/ChineseAnalyzer/g
4.修改setting.py文件
# 全文搜索框架配置
HAYSTACK_CONNECTIONS = {
'default': {
# 使用whoosh引擎
# 'ENGINE': 'haystack.backends.whoosh_backend.WhooshEngine',
# 使用jieba分词
'ENGINE': 'haystack.backends.whoosh_cn_backend.WhooshEngine',
# 索引文件路径
'PATH': os.path.join(BASE_DIR, 'whoosh_index'),
},
}
5.重新建立索引
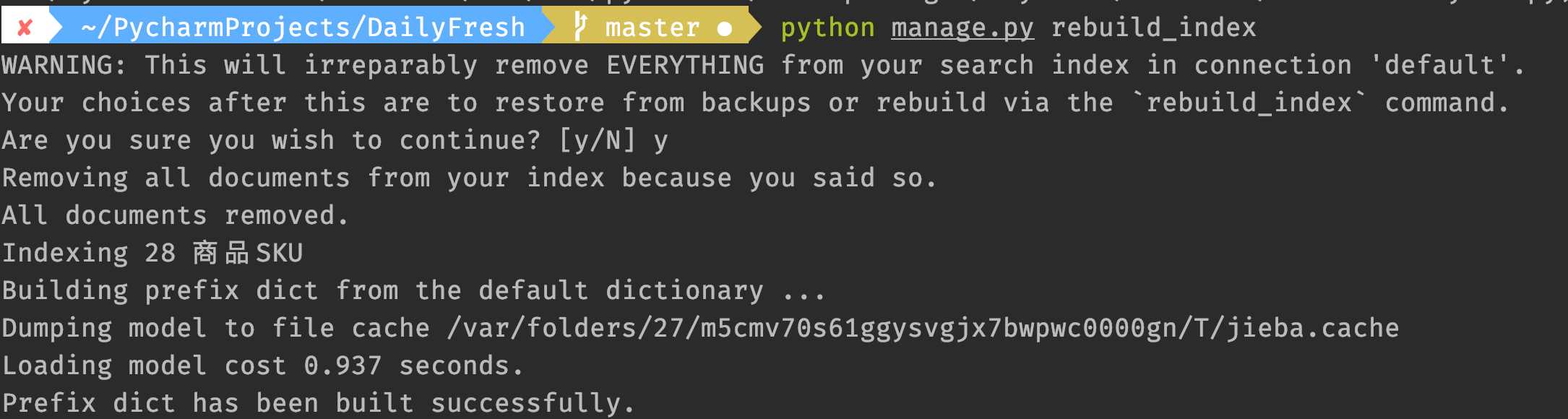
python manage.py rebuild_index
可以看到,已经使用了jieba分词。
到此这篇关于Django实现whoosh搜索引擎使用jieba分词的文章就介绍到这了,更多相关Django jieba分词内容请搜索亿速云以前的文章或继续浏览下面的相关文章希望大家以后多多支持亿速云!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。