жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮеҶ…е®№дё»иҰҒи®Іи§ЈвҖңPyTorchжҖҺд№ҲдҪҝз”Ёж Үзӯҫе№іж»‘жӯЈеҲҷеҢ–вҖқпјҢж„ҹе…ҙи¶Јзҡ„жңӢеҸӢдёҚеҰЁжқҘзңӢзңӢгҖӮжң¬ж–Үд»Ӣз»Қзҡ„ж–№жі•ж“ҚдҪңз®ҖеҚ•еҝ«жҚ·пјҢе®һз”ЁжҖ§ејәгҖӮдёӢйқўе°ұи®©е°Ҹзј–жқҘеёҰеӨ§е®¶еӯҰд№ вҖңPyTorchжҖҺд№ҲдҪҝз”Ёж Үзӯҫе№іж»‘жӯЈеҲҷеҢ–вҖқеҗ§!
д»Җд№ҲжҳҜж Үзӯҫе№іж»‘пјҹеңЁPyTorchдёӯеҰӮдҪ•еҺ»дҪҝз”Ёе®ғпјҹ
еңЁи®ӯз»ғж·ұеәҰеӯҰд№ жЁЎеһӢзҡ„иҝҮзЁӢдёӯпјҢиҝҮжӢҹеҗҲе’ҢжҰӮзҺҮж ЎеҮҶ(probability calibration)жҳҜдёӨдёӘеёёи§Ғзҡ„й—®йўҳгҖӮдёҖж–№йқўпјҢжӯЈеҲҷеҢ–жҠҖжңҜеҸҜд»Ҙи§ЈеҶіиҝҮжӢҹеҗҲй—®йўҳпјҢе…¶дёӯиҫғдёәеёёи§Ғзҡ„ж–№жі•жңүе°ҶжқғйҮҚи°ғе°ҸпјҢиҝӯд»ЈжҸҗеүҚеҒңжӯўд»ҘеҸҠдёўејғдёҖдәӣжқғйҮҚзӯүгҖӮеҸҰдёҖж–№йқўпјҢPlattж ҮеәҰжі•е’Ңisotonic regressionжі•иғҪеӨҹеҜ№жЁЎеһӢиҝӣиЎҢж ЎеҮҶгҖӮдҪҶжҳҜжңүжІЎжңүдёҖз§Қж–№жі•еҸҜд»ҘеҗҢж—¶и§ЈеҶіиҝҮжӢҹеҗҲе’ҢжЁЎеһӢиҝҮеәҰиҮӘдҝЎе‘ў?
ж Үзӯҫе№іж»‘д№ҹи®ёеҸҜд»ҘгҖӮе®ғжҳҜдёҖз§ҚеҺ»ж”№еҸҳзӣ®ж ҮеҸҳйҮҸзҡ„жӯЈеҲҷеҢ–жҠҖжңҜпјҢиғҪдҪҝжЁЎеһӢзҡ„йў„жөӢз»“жһңдёҚеҶҚд»…дёәдёҖдёӘзЎ®е®ҡеҖјгҖӮж Үзӯҫе№іж»‘д№ӢжүҖд»Ҙиў«зңӢдҪңжҳҜдёҖз§ҚжӯЈеҲҷеҢ–жҠҖжңҜпјҢжҳҜеӣ дёәе®ғеҸҜд»ҘйҳІжӯўиҫ“е…ҘеҲ°softmaxеҮҪж•°зҡ„жңҖеӨ§logitsеҖјеҸҳеҫ—зү№еҲ«еӨ§пјҢд»ҺиҖҢдҪҝеҫ—еҲҶзұ»жЁЎеһӢеҸҳеҫ—жӣҙеҠ еҮҶзЎ®гҖӮ
еңЁиҝҷзҜҮж–Үз« дёӯпјҢжҲ‘们е®ҡд№үдәҶж Үзӯҫе№іж»‘еҢ–пјҢеңЁжөӢиҜ•иҝҮзЁӢдёӯжҲ‘们е°Ҷе®ғеә”з”ЁеҲ°дәӨеҸүзҶөжҚҹеӨұеҮҪж•°дёӯгҖӮ
ж Үзӯҫе№іж»‘пјҹ
еҒҮи®ҫиҝҷйҮҢжңүдёҖдёӘеӨҡеҲҶзұ»й—®йўҳпјҢеңЁиҝҷдёӘй—®йўҳдёӯпјҢзӣ®ж ҮеҸҳйҮҸйҖҡеёёжҳҜдёҖдёӘone-hotеҗ‘йҮҸпјҢеҚіеҪ“еӨ„дәҺжӯЈзЎ®еҲҶзұ»ж—¶з»“жһңдёә1пјҢеҗҰеҲҷз»“жһңжҳҜ0гҖӮ
ж Үзӯҫе№іж»‘ж”№еҸҳдәҶзӣ®ж Үеҗ‘йҮҸзҡ„жңҖе°ҸеҖјпјҢдҪҝе®ғдёәОөгҖӮеӣ жӯӨпјҢеҪ“жЁЎеһӢиҝӣиЎҢеҲҶзұ»ж—¶пјҢе…¶з»“жһңдёҚеҶҚд»…жҳҜ1жҲ–0пјҢиҖҢжҳҜжҲ‘们жүҖиҰҒжұӮзҡ„1-Оөе’ҢОөпјҢд»ҺиҖҢеёҰж Үзӯҫе№іж»‘зҡ„дәӨеҸүзҶөжҚҹеӨұеҮҪж•°дёәеҰӮдёӢе…¬ејҸгҖӮ

еңЁиҝҷдёӘе…¬ејҸдёӯпјҢce(x)иЎЁзӨәxзҡ„ж ҮеҮҶдәӨеҸүзҶөжҚҹеӨұеҮҪж•°пјҢдҫӢеҰӮпјҡ-log(p(x))пјҢОөжҳҜдёҖдёӘйқһеёёе°Ҹзҡ„жӯЈж•°пјҢiиЎЁзӨәеҜ№еә”зҡ„жӯЈзЎ®еҲҶзұ»пјҢNдёәжүҖжңүеҲҶзұ»зҡ„ж•°йҮҸгҖӮ
зӣҙи§ӮдёҠзңӢпјҢж Үи®°е№іж»‘йҷҗеҲ¶дәҶжӯЈзЎ®зұ»зҡ„logitеҖјпјҢ并дҪҝеҫ—е®ғжӣҙжҺҘиҝ‘дәҺе…¶д»–зұ»зҡ„logitеҖјгҖӮд»ҺиҖҢеңЁдёҖе®ҡзЁӢеәҰдёҠпјҢе®ғиў«еҪ“дҪңдёәдёҖз§ҚжӯЈеҲҷеҢ–жҠҖжңҜе’ҢдёҖз§ҚеҜ№жҠ—жЁЎеһӢиҝҮеәҰиҮӘдҝЎзҡ„ж–№жі•гҖӮ
PyTorchдёӯзҡ„дҪҝз”Ё
еңЁPyTorchдёӯпјҢеёҰж Үзӯҫе№іж»‘зҡ„дәӨеҸүзҶөжҚҹеӨұеҮҪж•°е®һзҺ°иө·жқҘйқһеёёз®ҖеҚ•гҖӮйҰ–е…ҲпјҢи®©жҲ‘们дҪҝз”ЁдёҖдёӘиҫ…еҠ©еҮҪж•°жқҘи®Ўз®—дёӨдёӘеҖјд№Ӣй—ҙзҡ„зәҝжҖ§з»„еҗҲгҖӮ
deflinear_combination(x, y, epsilon):return epsilon*x + (1-epsilon)*y
дёӢдёҖжӯҘпјҢжҲ‘们дҪҝз”ЁPyTorchдёӯдёҖдёӘе…Ёж–°зҡ„жҚҹеӨұеҮҪж•°пјҡnn.Module.
import torch.nn.functional as F defreduce_loss(loss, reduction='mean'):return loss.mean() if reduction=='mean'else loss.sum() if reduction=='sum'else loss classLabelSmoothingCrossEntropy(nn.Module):def__init__(self, epsilon:float=0.1, reduction='mean'): super().__init__() self.epsilon = epsilon self.reduction = reduction defforward(self, preds, target): n = preds.size()[-1] log_preds = F.log_softmax(preds, dim=-1) loss = reduce_loss(-log_preds.sum(dim=-1), self.reduction) nll = F.nll_loss(log_preds, target, reduction=self.reduction) return linear_combination(loss/n, nll, self.epsilon)
жҲ‘们зҺ°еңЁеҸҜд»ҘеңЁд»Јз ҒдёӯеҲ йҷӨиҝҷдёӘзұ»гҖӮеҜ№дәҺиҝҷдёӘдҫӢеӯҗпјҢжҲ‘们дҪҝз”Ёж ҮеҮҶзҡ„fast.ai pets example.
from fastai.vision import * from fastai.metrics import error_rate # prepare the data path = untar_data(URLs.PETS) path_img = path/'images' fnames = get_image_files(path_img) bs = 64 np.random.seed(2) pat = r'/([^/]+)_\d+.jpg$' data = ImageDataBunch.from_name_re(path_img, fnames, pat, ds_tfms=get_transforms(), size=224, bs=bs) \ .normalize(imagenet_stats) # train the model learn = cnn_learner(data, models.resnet34, metrics=error_rate) learn.loss_func = LabelSmoothingCrossEntropy() learn.fit_one_cycle(4)
жңҖеҗҺе°Ҷж•°жҚ®иҪ¬жҚўжҲҗжЁЎеһӢеҸҜд»ҘдҪҝз”Ёзҡ„ж јејҸпјҢйҖүжӢ©ResNetжһ¶жһ„并д»ҘеёҰж Үзӯҫе№іж»‘зҡ„дәӨеҸүзҶөжҚҹеӨұеҮҪж•°дҪңдёәдјҳеҢ–зӣ®ж ҮгҖӮз»ҸиҝҮеӣӣиҪ®еҫӘзҺҜеҗҺпјҢе…¶з»“жһңеҰӮдёӢ
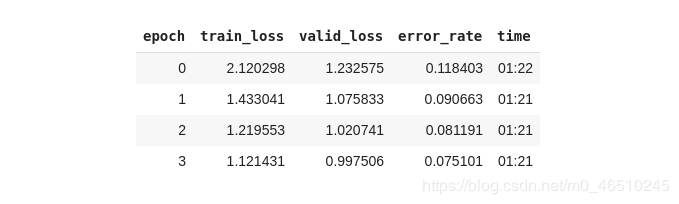
жҲ‘们жүҖеҫ—з»“жһңзҡ„й”ҷиҜҜзҺҮд»…дёә7.5%пјҢиҝҷеҜ№дәҺ10иЎҢе·ҰеҸізҡ„д»Јз ҒжқҘиҜҙжҳҜе®Ңе…ЁеҸҜд»ҘжҺҘеҸ—зҡ„пјҢ并且еңЁжЁЎеһӢдёӯеӨ§еӨҡж•°еҸӮж•°иҝҳйғҪйҖүжӢ©зҡ„жҳҜй»ҳи®Өи®ҫзҪ®гҖӮ
еӣ жӯӨпјҢеңЁжЁЎеһӢдёӯиҝҳжңүи®ёеӨҡеҸӮж•°еҸҜд»ҘиҝӣиЎҢи°ғж•ҙпјҢд»ҺиҖҢдҪҝеҫ—жЁЎеһӢзҡ„иЎЁзҺ°жҖ§иғҪжӣҙеҘҪпјҢдҫӢеҰӮпјҡеҸҜд»ҘдҪҝз”ЁдёҚеҗҢзҡ„дјҳеҢ–еҷЁгҖҒи¶…еҸӮж•°гҖҒжЁЎеһӢжһ¶жһ„зӯүгҖӮ
з»“и®ә
еңЁиҝҷзҜҮж–Үз« дёӯпјҢжҲ‘们дәҶи§ЈдәҶд»Җд№ҲжҳҜж Үзӯҫе№іж»‘д»ҘеҸҠд»Җд№Ҳж—¶еҖҷеҺ»дҪҝз”Ёе®ғпјҢ并且жҲ‘们иҝҳзҹҘйҒ“дәҶеҰӮдҪ•еңЁPyTorchдёӯе®һзҺ°е®ғгҖӮд№ӢеҗҺпјҢжҲ‘们и®ӯз»ғдәҶдёҖдёӘе…Ҳиҝӣзҡ„и®Ўз®—жңәи§Ҷи§үжЁЎеһӢпјҢд»…дҪҝз”ЁеҚҒиЎҢд»Јз Ғе°ұиҜҶеҲ«еҮәдәҶдёҚеҗҢе“Ғз§Қзҡ„зҢ«е’ҢзӢ—гҖӮ
жЁЎеһӢжӯЈеҲҷеҢ–е’ҢжЁЎеһӢж ЎеҮҶжҳҜдёӨдёӘйҮҚиҰҒзҡ„жҰӮеҝөгҖӮиӢҘжғіжҲҗдёәдёҖдёӘж·ұеәҰеӯҰд№ зҡ„иө„ж·ұзҺ©е®¶пјҢе°ұеә”иҜҘеҘҪеҘҪең°еҺ»зҗҶи§ЈиҝҷдәӣиғҪеӨҹеҜ№жҠ—иҝҮжӢҹеҗҲе’ҢжЁЎеһӢиҝҮеәҰиҮӘдҝЎзҡ„е·Ҙе…·гҖӮ
дҪңиҖ…з®Җд»Ӣпјҡ Dimitris PoulopoulosпјҢжҳҜBigDataStackзҡ„дёҖеҗҚжңәеҷЁеӯҰд№ з ”з©¶е‘ҳпјҢеҗҢж—¶д№ҹжҳҜеёҢи…ҠPiraeusеӨ§еӯҰзҡ„еҚҡеЈ«гҖӮжӣҫдёә欧зӣҹ委е‘ҳдјҡгҖҒ欧зӣҹз»ҹи®ЎеұҖгҖҒеӣҪйҷ…иҙ§еёҒеҹәйҮ‘з»„з»ҮгҖҒ欧жҙІеӨ®иЎҢзӯүе®ўжҲ·и®ҫи®ЎиҝҮдёҺAIзӣёе…ізҡ„иҪҜ件гҖӮ
жҖ»з»“
еҲ°жӯӨпјҢзӣёдҝЎеӨ§е®¶еҜ№вҖңPyTorchжҖҺд№ҲдҪҝз”Ёж Үзӯҫе№іж»‘жӯЈеҲҷеҢ–вҖқжңүдәҶжӣҙж·ұзҡ„дәҶи§ЈпјҢдёҚеҰЁжқҘе®һйҷ…ж“ҚдҪңдёҖз•Әеҗ§пјҒиҝҷйҮҢжҳҜдәҝйҖҹдә‘зҪ‘з«ҷпјҢжӣҙеӨҡзӣёе…іеҶ…е®№еҸҜд»Ҙиҝӣе…Ҙзӣёе…ійў‘йҒ“иҝӣиЎҢжҹҘиҜўпјҢе…іжіЁжҲ‘们пјҢ继з»ӯеӯҰд№ пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ