您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
随着人工智能的兴起,Python这门曾经小众的编程语言可谓是焕发了第二春。

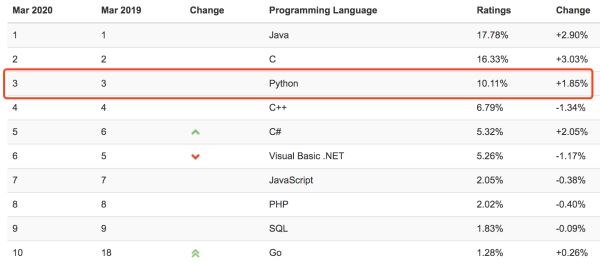
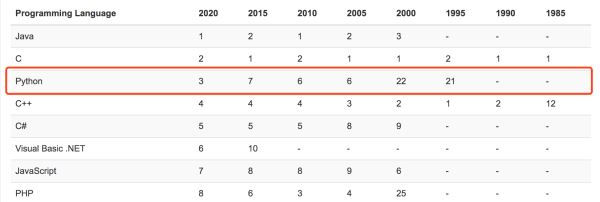
以tensorflow、pytorch等为主的机器学习/深度学习的开发框架大行其道,助推了python这门曾经以爬虫见长(python粉别生气)的编程语言在TIOBE编程语言排行榜上一路披荆斩棘,坐上前三甲的宝座,仅次于Java和C,将C++、JavaScript、PHP、C#等一众劲敌斩落马下。
当然,轩辕君向来是不提倡编程语言之间的竞争对比,每一门语言都有自己的优势和劣势,有自己应用的领域。
另一方面,TIOBE统计的数据也不能代表国内的实际情况,上面的例子只是侧面反映了Python这门语言如今的流行程度。
Java 还是 Python
说回咱们的需求上来,如今在不少的企业中,同时存在Python研发团队和Java研发团队,Python团队负责人工智能算法开发,而Java团队负责算法工程化,将算法能力通过工程化包装提供接口给更上层的应用使用。
可能大家要问了,为什么不直接用Java做AI开发呢?要弄两个团队。其实,现在包括TensorFlow在内的框架都逐渐开始支持Java平台,用Java做AI开发也不是不行(轩辕君的前同事就已经在这样做了),但限于历史原因,做AI开发的人本就不多,而这一些人绝大部分都是Python技术栈入坑,Python的AI开发生态已经建设的相对完善,所以造成了在很多公司中算法团队和工程化团队使用不同的语言。
现在该抛出本文的重要问题:Java工程化团队如何调用Python的算法能力?
答案基本上只有一个:Python通过Django/Flask等框架启动一个Web服务,Java中通过Restful API与之进行交互
上面的方式的确可以解决问题,但随之而来的就是性能问题。尤其是在用户量上升后,大量并发接口访问下,通过网络访问和Python的代码执行速度将成为拖累整个项目的瓶颈。
当然,不差钱的公司可以用硬件堆出性能,一个不行,那就多部署几个Python Web服务。
那除此之外,有没有更实惠的解决方案呢?这就是这篇文章要讨论的问题。
上面的性能瓶颈中,拖累执行速度的原因主要有两个:
众所周知,Python是一门解释型脚本语言,一般来说,在执行速度上:
解释型语言 < 中间字节码语言 < 本地编译型语言
自然而然,我们要努力的方向也就有两个:
结合上面的两个点,我们的目标也清晰起来:
将Python代码转换成Java可以直接本地调用的模块
对于Java来说,能够本地调用的有两种:
其实我们通常所说的Python指的是CPython,也就是由C语言开发的解释器来解释执行。而除此之外,除了C语言,不少其他编程语言也能够按照Python的语言规范开发出虚拟机来解释执行Python脚本:
如果能够在JVM中直接执行Python脚本,与Java业务代码的交互自然是最简单不过。但随后的调研发现,这条路很快就被堵死了:
这条路行不通,那还有一条:把Python代码转换成Native代码块,Java通过JNI的接口形式调用。
先将Python源代码转换成C代码,之后用GCC编译C代码为二进制模块so/dll,接着进行一次Java Native接口封装,使用Jar打包命令转换成Jar包,然后Java便可以直接调用。

流程并不复杂,但要完整实现这个目标,有两个关键问题需要解决:
1.Python代码如何转换成C代码?
终于要轮到本文的主角登场了,将要用到的一个核心工具叫:Cython
请注意,这里的Cython和前面提到的CPython不是一回事。CPython狭义上是指C语言编写的Python解释器,是Windows、Linux下我们默认的Python脚本解释器。
而Cython是Python的一个第三方库,你可以通过pip install Cython进行安装。
官方介绍Cython是一个Python语言规范的超集,它可以将Python+C混合编码的.pyx脚本转换为C代码,主要用于优化Python脚本性能或Python调用C函数库。
听上去有点复杂,也有点绕,不过没关系,get一个核心点即可:Cython能够把Python脚本转换成C代码
来看一个实验:
# FileName: test.py
def test_function():
print("this is print from python script")
将上述代码通过Cython转化,生成test.c,长这个样子:
另外添加一个main.c,在其中实现C语言的main函数,并调用原python中的函数:
extern void test_function();
int main() {
test_function();
return 0;
}
输出结果:
可以正常工作!
2.转换后的C代码如何包装成JNI接口使用
1.Python源代码
def logic(param):
print('this is a logic function')
# 接口函数,导出给Java Native的接口
def JNI_API_TestFunction(param):
print("enter JNI_API_test_function")
logic(param)
print("leave JNI_API_test_function")
2.使用Cython工具转换成C代码
3.编译生成动态库
4.封装为Jar包
准备一个JNI调用的Interface:JNITest.java
public class JNITest {
native boolean Java_PkgName_module_initModule( );
native void Java_PkgName_module_uninitModule( );
native String Java_PkgName_module_TestFunction(String param);
}
这里有3个native方法:
接口声明文件+二进制动态库文件准备就绪,开始打包:
jar -cvf JNITest.jar ./JNITest
5.Java调用
上面演示的案例只是一个单独的py文件,而实际工作中,我们的项目通常是具有多个py文件,并且这些文件通常是构成了复杂的目录层级,互相之间各种import关系,错综复杂。
Cython这个工具有一个最大的坑在于:经过其处理的文件代码中会丢失代码文件的目录层级信息,如下图所示,C.py转换后的代码和m/C.py生成的代码没有任何区别。
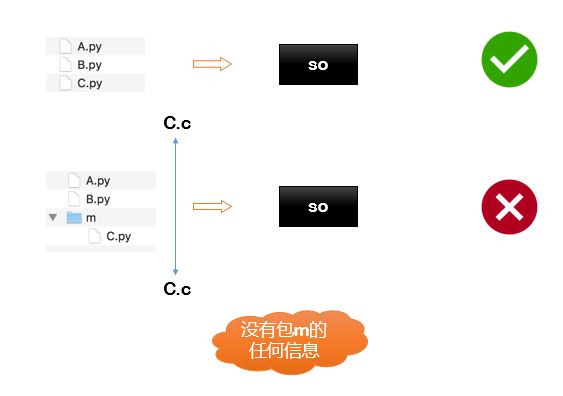
这就带来一个非常大的问题:A.py或B.py代码中如果有引用m目录下的C.py模块,目录信息的丢失将导致二者在执行import m.C时报错,找不到对应的模块!
幸运的是,经过实验表明,在上面的图中,如果A、B、C三个模块处于同一级目录下时,import能够正确执行。
轩辕君曾经尝试阅读Cython的源代码,并进行修改,将目录信息进行保留,使得生成后的C代码仍然能够正常import,但限于时间仓促,对Python解释器机理了解不足,在一番尝试之后选择了放弃。
在这个问题上卡了很久,最终选择了一种笨办法:将树形的代码层级目录展开成为平坦的目录结构,就上图中的例子而言,展开后的目录结构变成了
A.py
B.py
m_C.py
单是这样还不够,还需要对A、B中引用到C的地方全部进行修正为对m_C的引用。
这看起来很简单,但实际情况远比这复杂,在Python中,import可不只有import这么简单,有各种各样复杂的形式:
import package import module import package.module import module.class / function import package.module.class / function import package.* import module.* from module import * from module import module from package import * from package import module from package.module import class / function ...
除此之外,在代码中还可能存在直接通过模块进行引用的写法。
展开成为平坦结构的代价就是要处理上面所有的情况!轩辕君无奈之下只有出此下策,如果各位大佬有更好的解决方案还望不吝赐教。
Python转换后的jar包开始用于实际生产中了,但随后发现了一个问题:
每当Java并发数一上去之后,JVM总是不定时出现Crash
随后分析崩溃信息发现,崩溃的地方正是在Native代码中的Python转换后的代码中。
崩溃的乌云笼罩在头上许久,冷静下来思考:
为什么测试的时候正常没有发现问题,上线之后才会崩溃?
再次翻看崩溃日志,发现在native代码中,发生异常的地方总是在malloc分配内存的地方,难不成内存被破坏了?
又敏锐的发现测试的时候只是完成了功能性测试,并没有进行并发压力测试,而发生崩溃的场景总是在多并发环境中。多线程访问JNI接口,那Native代码将在多个线程上下文中执行。
猛地一个警觉:99%跟Python的GIL锁有关系!

众所周知,限于历史原因,Python诞生于上世纪九十年代,彼时多线程的概念还远远没有像今天这样深入人心过,Python作为这个时代的产物一诞生就是一个单线程的产品。
虽然Python也有多线程库,允许创建多个线程,但由于C语言版本的解释器在内存管理上并非线程安全,所以在解释器内部有一个非常重要的锁在制约着Python的多线程,所以所谓多线程实际上也只是大家轮流来占坑。
原来GIL是由解释器在进行调度管理,如今被转成了C代码后,谁来负责管理多线程的安全呢?
由于Python提供了一套供C语言调用的接口,允许在C程序中执行Python脚本,于是翻看这套API的文档,看看能否找到答案。
幸运的是,还真被我找到了:
获取GIL锁:

释放GIL锁:

在JNI调用入口需要获得GIL锁,接口退出时需要释放GIL锁。
加入GIL锁的控制后,烦人的Crash问题终于得以解决!
准备两份一模一样的py文件,同样的一个算法函数,一个通过Flask Web接口访问,(Web服务部署于本地127.0.0.1,尽可能减少网络延时),另一个通过上述过程转换成Jar包。
在Java服务中,分别调用两个接口100次,整个测试工作进行10次,统计执行耗时:
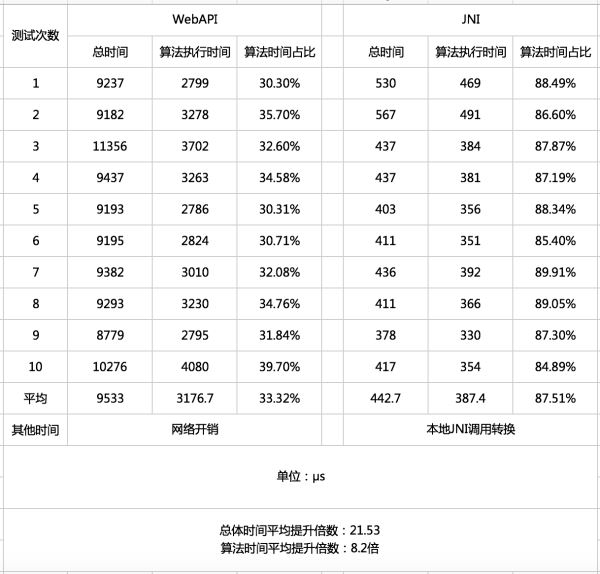
上述测试中,为进一步区分网络带来的延迟和代码执行本身的延迟,在算法函数的入口和出口做了计时,在Java执行接口调用前和获得结果的地方也做了计时,这样可以计算出算法执行本身的时间在整个接口调用过程中的占比。
本文提供了一种Java调用Python功能的新思路,仅供参考,其成熟度和稳定性还有待商榷,通过HTTP Restful接口访问仍然是跨语言对接的首选。
到此这篇关于Python代码一键转Jar包及Java调用Python新姿势的文章就介绍到这了,更多相关Python转Jar包内容请搜索亿速云以前的文章或继续浏览下面的相关文章希望大家以后多多支持亿速云!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。