您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
一、Prometheus介绍
Prometheus 是一套开源的系统监控和报警框架,灵感源自 Google 的 Borgmon 监控系统。2012 年,SoundCloud 的 Google 前员工创造了 Prometheus,并作为社区开源项目进行开发。2015 年,该项目正式发布。2016 年,Prometheus 加入云原生计算基金会(Cloud Native Computing Foundation),成为受欢迎度仅次于 Kubernetes 的项目。
二、Prometheus 具有以下特性
三、架构
prometheus是一个用Go编写的时序数据库,可以支持多种语言客户端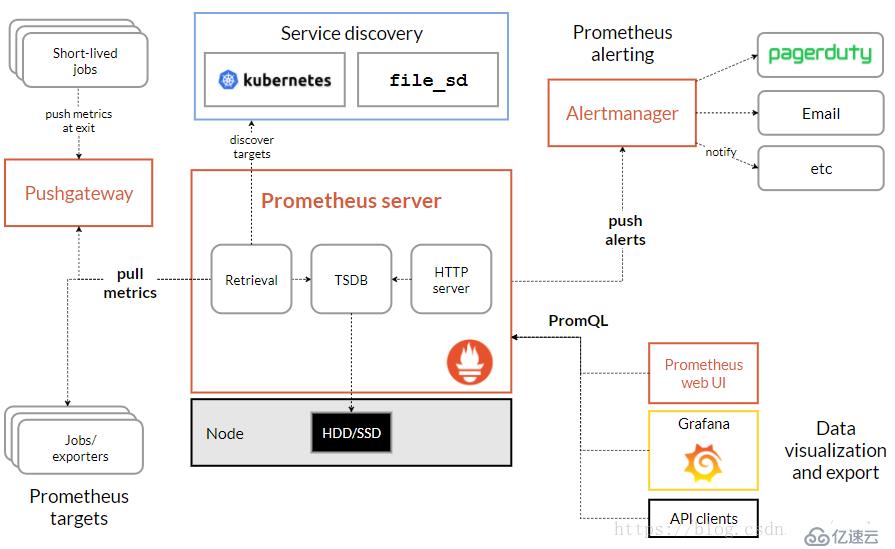
四、模块介绍
Prometheus Server
Prometheus Server 是监控系统的服务端,服务端通过服务发现的方式,抓取被监控服务的指标,或者通过 pushgateway 的间接抓取,抓取到指标数据后,通过特定的存储引擎进行存储,同时暴露一个 HTTP 服务,提供用 PromQL 来进行数据查询。注意,Prometheus 是定时采样数据,而不是全量数据。
Exporter
Prometheus 需要服务暴露 http 接口,如果服务本身没有,我们不需要改造服务,可以通过 exporter 来间接获取。Exporter 就充当了 Prometheus 采集的目标,而由各个 exporter 去直接获取指标。目前大多数的服务都有现成的 exporter,我们不需要重复造轮子,拿来用即可,如 MySQL,MongoDB 等,可以参考这里。
为什么要有两种模式呢?我们来比较一下这两种模式的特点。
1、Pull 模式:Prometheus 主动抓取的方式,可以由 Prometheus 服务端控制抓取的频率,简单清晰,控制权在 Prometheus 服务端。通过服务发现机制,可以自动接入新服务,去掉下线的服务,无需任何人工干预。对于各种常见的服务,官方或社区有大量 Exporter 来提供指标采集接口,基本无需开发。是官方推荐的方式。
2、Push 模式:由服务端主动上报至 Push Gateway,采集最小粒度由服务端决定,等于 Push Gateway 充当了中介的角色,收集各个服务主动上报的指标,然后再由 Prometheus 来采集。但是这样就存在了 Push Gateway 这个性能单点,而且 Push Gateway 也要处理持久化问题,不然宕机也会丢失部分数据。同时需要服务端提供主动上报的功能,可能涉及一些开发改动。不是首选的方式,但是在一些场景下很适用。例如,一些临时性的任务,存在时间可能非常短,如果采用 Pull 模式,可能抓取不到数据。
Alert Manager
Alert Manager 是 Prometheus 的报警组件,当 Prometheus 服务端发现报警时,推送 alert 到 Alert Manager,再由 Alert Manager 发送到通知端,如 Email,Slack,微信,钉钉等。Alert Manager 根据相关规则提供了报警的分组、聚合、抑制、沉默等功能。
五、下载
下载地址:https://prometheus.io/download/
下载server
wget -c https://github.com/prometheus/prometheus/releases/download/v2.15.0/prometheus-2.15.0.linux-amd64.tar.gz
下载node
wget -c https://github.com/prometheus/node_exporter/releases/download/v0.18.1/node_exporter-0.18.1.linux-amd64.tar.gz

六、配置说明
配置文件:prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration #报警监控配置
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']说明:
global:全局配置,其中scrape_interval表示抓取一次数据的间隔时间,evaluationinterval:表示进行告警规则检测的间隔时间;
alerting:告警管理器(Alertmanager)的配置,需要安装Alertmanager;
rulefiles:告警规则有哪些;
scrapeconfigs:抓取监控信息的目标。一个job_name就是一个目标,其targets就是采集信息的IP和端口。这里默认监控了Prometheus自己,可以通过修改这里来修改Prometheus的监控端口。Prometheus的每个exporter都会是一个目标,它们可以上报不同的监控信息,比如机器状态,或者mysql性能等等,不同语言sdk也会是一个目标,它们会上报你自定义的业务监控信息。
七、部署
部署流程:
1、在监控服务器上安装prometheus
2、在被监控环境上安装exporte
1、server启动方法:./prometheus --config.file=/data/prometheus-2.15.0.linux-amd64/prometheus.yml
2、node启动方法:nohup ./node_exporter &
3、将应用添加到系统服务
vim /etc/systemd/system/prometheus.service
[unit]
Description=Prometheus Monitoring System
Documentation=Prometheus Monitoring System
[Service]
ExecStart=/data/prometheus/prometheus \
--config.file=/data/prometheus/prometheus.yml \
--web.listen-address=:9090
##此处文件路径请对照安装目录
[Install]
WantedBy=multi-user.target然后就可以通过systemctl start|stop|status|enable promethues.service进行管理了
八、访问
http://127.0.0.1:9090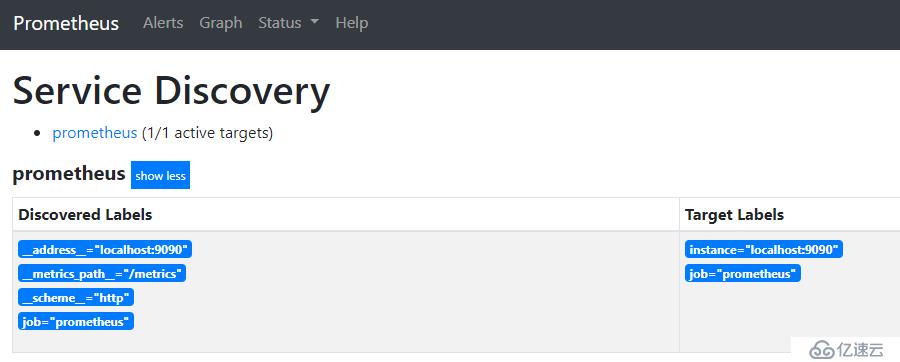
参考链接:prometheus安装
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。