您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
一朋友在群里问有没有什么办法能够一次性把这个链接 里的文章保存下来。点开可以看到,其实就是一个文章合集。所以需求就是,把这个文档中的链接里的文章挨个保存下来。保存形式可以有很多种,可以是图片,也可以是网页。这里因为使用 puppeteer 库的原因,故选择保存格式格式为PDF。
需求解构
完成整个动作,主要分为这两个部分。获取文档内所有文章的链接;把每个链接里的内容保存为PDF文件。
对于获取链接,有两条路,一是使用request模块请求该网址获取文档;二是把网页保存到本地使用fs模块获取文档内容。拿到文档也就是整个HTML文档后,一开始没想到什么好法子来拿到全部文章链接。如果直接在网页那就好办,直接DOM的 quertSelectorAll API配合CSS选择器就可以非常方便地拿到所有 a 链接中的 href 属性。但这里是Node,是DOM外之地。又想到的是直接使用正则匹配,后来还是放弃了这个做法。在google搜了下才发现竟然忘了 cheerio 这个好东西。 cheerio 是一个专门为服务端设计的快速灵活而简洁得jQuery实现。
对于保存网页内容,我所知道的常规操作是保存为PDF文件,恰巧之前刚知道的 puppeteer 满足这样的需求。 puppeteer 是一个由 chrome devtools 团队维护的提供了控制chrome浏览器高级API的一个Node库。除去爬取网页内容保存为PDF文件外,它还可以作为服务端渲染的一个方案以及实现自动化测试的一个方案。
需求实现
获取链接
先上这部分代码
const getHref = function () {
let file = fs.readFileSync('./index.html').toString()
const $ = cheerio.load(file)
let hrefs = $('#sam').find('a')
for (e in hrefs) {
if (hrefs[e].attribs && hrefs[e].attribs['href']) {
hrefArr.push({
index: e,
href: hrefs[e].attribs['href']
})
}
}
fs.writeFileSync('hrefJson.json', JSON.stringify(hrefArr))
}
因为后面的代码都依赖到读取的文件,所以这里用的是readFileSync方法。如果没有声明返回内容的格式,那默认是Buffer格式。可以选择填写 utf8 格式,或者直接在该方法后面使用 toString 方法。
两行代码用cheerio拿到所有所有链接的DOM元素后,挨个将其处理为方便后面要用到的格式。考虑到可能存在a标签没有href属性的情况,这里还对其进行了判断,不过这也是后面调试程序时才发现的bug。
如果需要将所有的链接另外保存起来,使用 writeFile 方法。
存为PDF
同样,先上这部分代码。
const saveToPdf = function () {
async () => {
const browser = await puppeteer.launch({
executablePath: './chrome-win/chrome.exe',
});
// 链接计数
let i = 0
async function getPage() {
const page = await browser.newPage();
await page.goto(hrefArr[i]['href'], { waitUntil: 'domcontentloaded' });
// 网页标题
let pageTitle
if (hrefArr[i]['href'].includes('weixin')) {
pageTitle = await page.$eval('meta[property="og:title"]', el => el.content)
} else {
pageTitle = await page.$eval('title', el => el.innerHTML)
}
let title = pageTitle.trim()
// 去掉斜杆
let titlea = title.replace(/\s*/g, "")
// 去掉竖线
let titleb = titlea.replace(/\|/g, "");
await page.pdf({ path: `${i}${titleb}.pdf` });
i++
if (i < hrefArr.length) {
getPage()
} else {
await browser.close();
}
}
getPage()
}
}
因为需要等待chrome浏览器的打开,以及其他可能的异步请求。最外层使用了async 配合箭头函数将真正的执行代码包住。
在用 npm 安装 puppetter 时,因为默认会下载chrome浏览器,而服务器在国外,一般都无法下载成功。当然也有相应的解决方案,这里我就不展开了。如果安装 puppeteer ,可以参开 这篇文章 或者直接谷歌搜下。
在前一部分说到,我们需要把不止一个链接里的内容保存为PDF,所以使用了变量 i 来标识每一次需要访问的链接。
对于获取网页标题,当时确实费了点时间才处理好拿到已有链接的网页标题。所以链接中主要有两种网站的链接,一类是微信公众号文章,另一类是新浪财新这种网站。微信文章里头没有像新浪这样直接给出 title 内容。

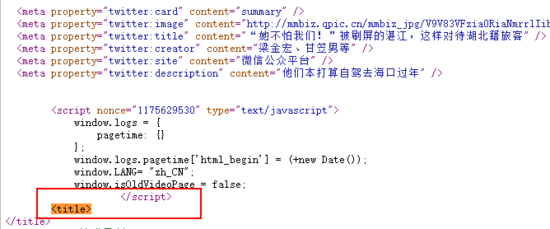
这个时候就要用到 page 类中的 $eval 方法, $eval 方法主要有两个参数,一是选择器,二是在浏览器上下文中执行的函数。$eval方法会页面中运行document.querySelector方法,并将其返回值传递给第二个参数,也就是我们写好的方法中。以获取新浪网页文章title为例, title 为传入选择器,我们需要的是其标签内容。
pageTitle = await page.$eval('title', el => el.innerHTML)
在产生文件名的过程中,由于文件夹还是文件路径的一部分。此时还需要考虑到windows文件路径规范。但网页中的标题并不受此规范限制,由此产生矛盾。这个问题也是后面调试的时候才发现,一开始写代码并没有想到这个问题。即需要去除标题中的斜杠竖杆还有空格等字符。
每获取完一个链接的内容后,就将链接位置标识 i + 1,知道所有链接内容保存完毕,关闭打开的网页。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持亿速云。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。