您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
小编给大家分享一下Tensorflow中Device如何生成和管理,希望大家阅读完这篇文章之后都有所收获,下面让我们一起去探讨吧!
1. 关键术语描述
kernel
在神经网络模型中,每个node都定义了自己需要完成的操作,比如要做卷积、矩阵相乘等。
可以将kernel看做是一段能够跑在具体硬件设备上的算法程序,所以即使同样的2D卷积算法,我们有基于gpu的Convolution 2D kernel实例、基于cpu的Convolution 2D kernel实例。
device
负责运行kernel的具体硬件设备抽象。每个device实例,对应系统中一个具体的处理器硬件,比如gpu:0 device, gpu:1 device, cpu:0 device。一般来说,每个device实例同时包括处理器资源、内存资源。device的抽象支持硬件设备提供的并行处理能力。
2. device是什么
为方便描述,下面我们把在tensorflow里面运行的神经网络模型都统一称为graph。
我们知道,tensorflow主要针对的是跨硬件平台、分布式、并发运行的场景,参与运算的每个硬件资源,我们都抽象为device实例,便于管理。
device的主要职责:
管理处理器资源,为支持device内部的并行计算,进一步将其抽象为thread pool或streams:
cpu:使用thread pool来管理,thread之间可支持不同程度的并行计算能力
gpu: 针对nvidia gpu, 使用cuda streams来管理,根据不同的gpu型号,可支持不同数量的stream做并行计算
管理内存资源:为kernel的运行,分配和释放内存,进一步抽象为Allocator及其各种子类的实例来管理。
主机内存:
cpu kernel 计算时需要的内存。
gpu kernel的输出结果如果要放置到主机内存中时,gpu kernel也需要申请主机内存。
显存: gpu kernel 计算时需要的内存。
3. device的种类及应用场景
由于device要抽象的设备种类较多,我们主要描述一下本地运行的cpu device、gpu device实例类型。先用一个UML图来表示一下各种device抽象类的关系:
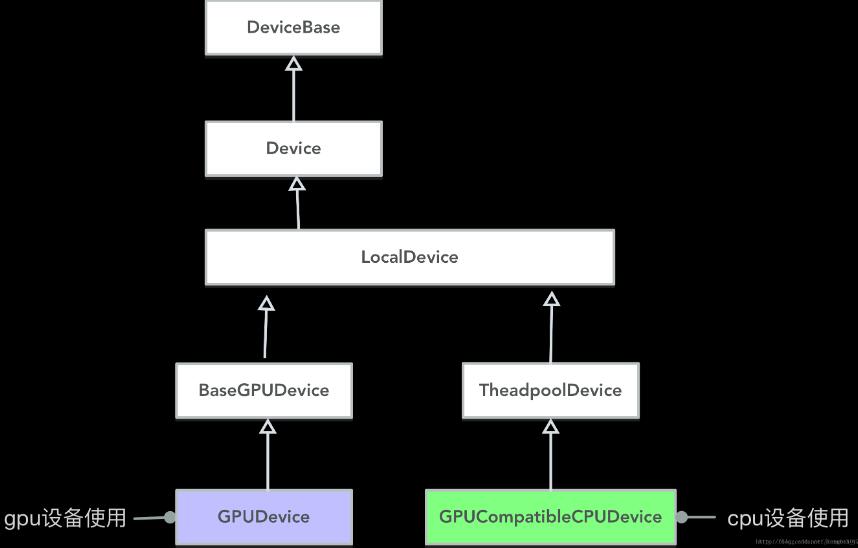
可以看到,cpu device实例使用的类是GPUCompatibleCPUDevice,主要是在ThreadPoolDevice的基础上,增加了gpu<-> cpu之间内存传输数据的优化措施。
gpu device实例使用的类是 GPUDevice 。
4. device实例的关键数据结构
我们以常用的cpu device,gpu device为例, 用下图描述一下device实例的关键数据结构:
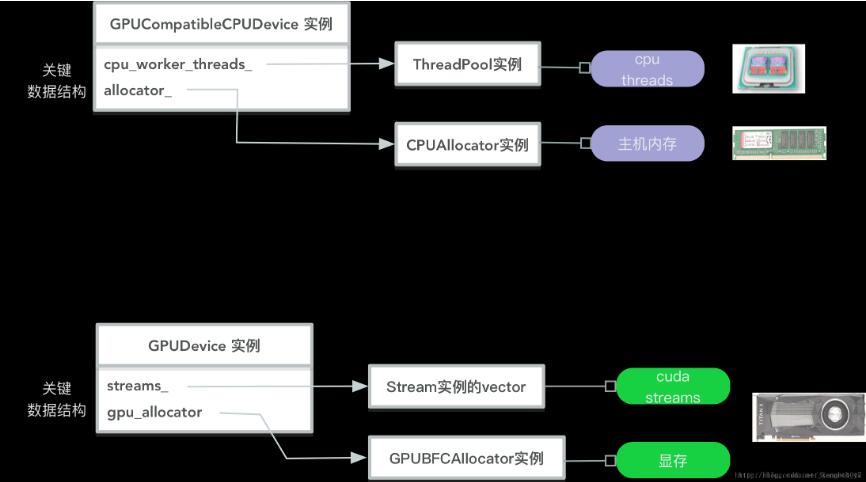
可以看到每个device实例内部都具备并行处理的能力:
GPUCompatibleCPUDevice实例 将 cpu 的计算资源抽象为thread pool,以支持多thread之间的并发执行; 将主机内存抽象为 CPUAllocator 实例来进行管理,为cpu kernel、gpu kernel提供主机内存的申请、释放功能; GPUDevice实例 将gpu的计算资源抽象为streams, 由于目前只支持NVIDIA的gpu,所以这里我们可以看作抽象为cuda streams,多个cuda streams之间的计算可以并发处理; 通过GPUBFCAllocator实例来管理显存,为gpu kernel提供显存的申请、释放功能。
5. device实例的创建
系统中可用的device实例,由session发起创建,归属于session实例。
device的创建,使用Factory 设计模式,session会调用所有注册的device factory,逐一产出 符合条件的device实例。
以DirectSession实例创建gpu device、cpu device为例,具体流程如下图所示。
为方便结合代码阅读,已包含主要的类、函数调用路径:
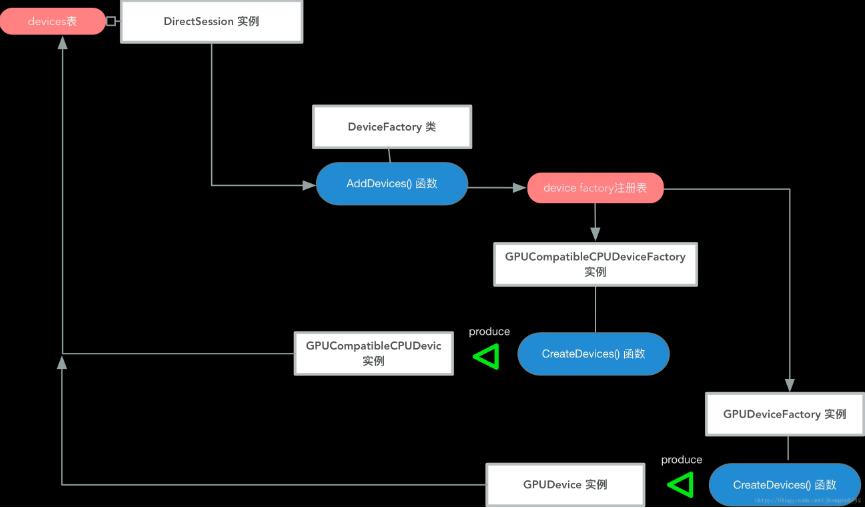
可以看到,最终产出 的gpu device、cpu device实例,都会保存至DirectSession实例的 devices_ 表中,由DirectSession实例进行分配和使用。
6. 在graph运行阶段device的使用
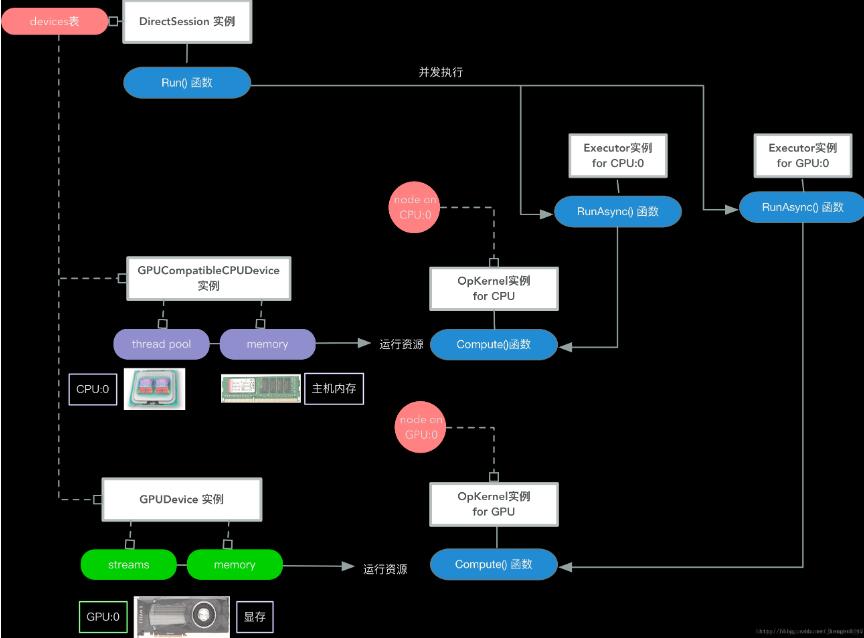
在graph的创建阶段,session为每个node分配一个具体的device实例,同时为每个node创建一个具体的kernel实例,这个kernel实例将会运行在分配的device实例上。(参见Tensorflow 核心流程剖析 2 – 神经网络模型的创建和分割)
接下来,在graph的运行阶段,session会依次处理graph中的node,调度node所分配的device实例,去运行node的kernel实例。
每个kernel 在运行时,会向其分配的device,申请需要的计算资源、内存资源等,完成具体的运算操作。
上述流程如下图所示。
为方便结合代码阅读,已包含主要的类、函数调用路径:
看完了这篇文章,相信你对“Tensorflow中Device如何生成和管理”有了一定的了解,如果想了解更多相关知识,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。