жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
дҪҝз”ЁChromeгҖҒpython3.7гҖҒrequestsеә“е’ҢVSCodeиҝӣиЎҢзҲ¬еҸ–马иңӮзӘқй»„й№ӨжҘјзҡ„ж–Үеӯ—иҜ„и®ә(http://www.mafengwo.cn/poi/5426285.html)гҖӮ
йҰ–е…ҲпјҢжҲ‘们еӨҚеҲ¶дёҖж®өиҜ„и®әпјҢжҹҘзңӢзҪ‘йЎөжәҗд»Јз ҒпјҢжҢүCtrl+FжҹҘжүҫпјҢеҸ‘зҺ°жІЎжңүжүҫеҲ°иҜ„и®әпјҢиҜҙжҳҺиҜ„и®әеҶ…е®№дёҚеңЁhttp://www.mafengwo.cn/poi/5426285.htmlйЎөйқўгҖӮ

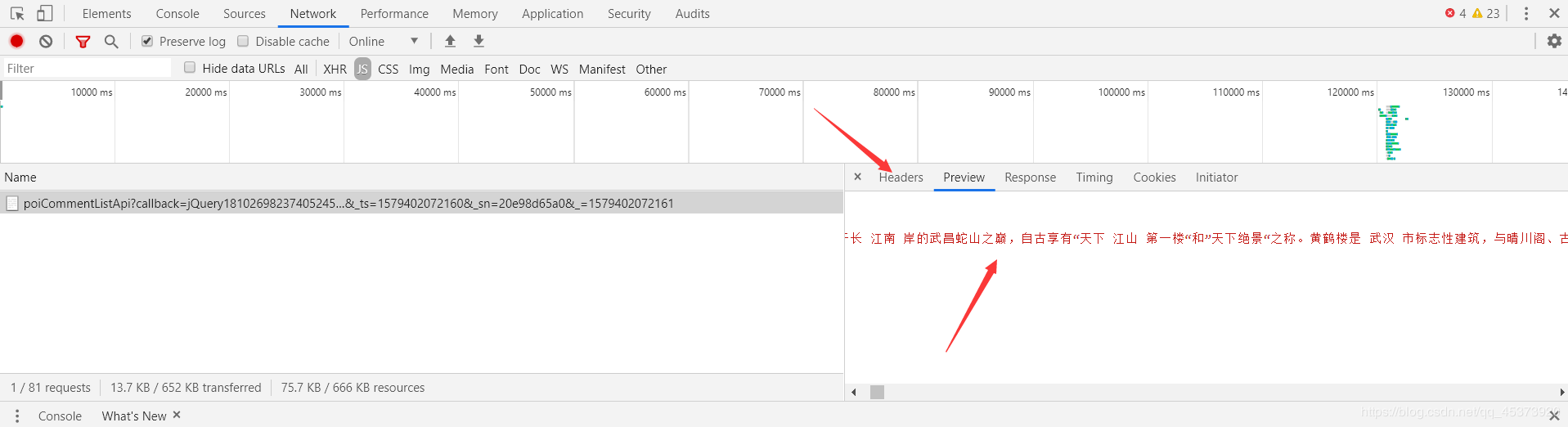
еӣһеҲ°йЎөйқўпјҢеҲ’еҲ°иҜ„и®әеҲ—иЎЁпјҢеҸій”®жЈҖжҹҘпјҢйҖүжӢ©NetworkпјҢ然еҗҺзӮ№еҮ»еҗҺдёҖйЎөзҝ»йЎөпјҢи§ӮеҜҹNetworkйҮҢзҡ„еҸҳеҢ–пјҢжҲ‘们иҰҒзҲ¬зҡ„ж–Ү件е°ұеңЁдёӢйқўзҡ„жҹҗдёӘж–Ү件йҮҢпјҲдё»иҰҒжүҫXHRе’ҢJSдёӨдёӘжЁЎеқ—пјүгҖӮйҖүжӢ©PreviewеҸҜд»ҘжӣҙеҘҪзҡ„и®©жҲ‘们еҜ»жүҫжҲ‘们жғіиҰҒзҡ„ж–Ү件пјҢ然еҗҺйҖүжӢ©HeadersжүҫеҲ°жҲ‘们иҰҒзҲ¬зҡ„urlгҖӮ
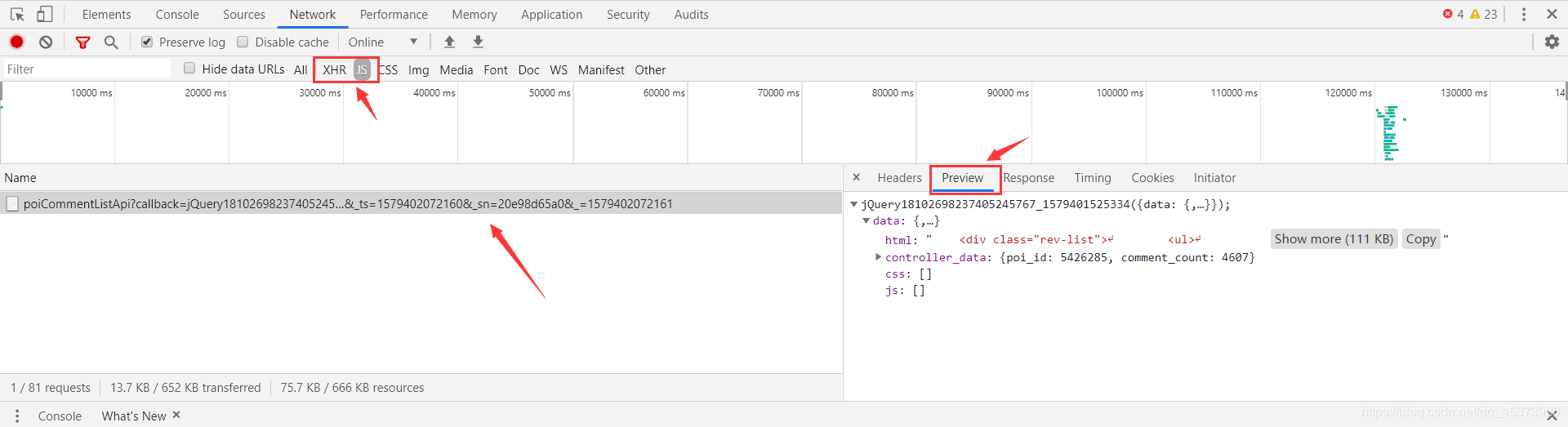
з»ҸиҝҮеҲҶжһҗжҲ‘们жүҫеҲ°иҰҒзҲ¬еҸ–зҡ„urlжҳҜhttp://pagelet.mafengwo.cn/poi/pagelet/poiCommentListApi?callback=jQuery18102698237405245767_1579401525334¶ms=%7B%22poi_id%22%3A%225426285%22%2C%22page%22%3A2%2C%22just_comment%22%3A1%7D&_ts=1579402072160&sn=20e98d65a0&=1579402072161
然иҖҢзӮ№иҝӣеҺ»жҳҜиҝҷж ·зҡ„

иҝҷдёӘж—¶еҖҷеҜ№жҜ”дёҖдёӢиҝҷдёӨдёӘйЎөйқўзҡ„Request HeadersпјҢеҸ‘зҺ°еҺҹйЎөйқўеӨҡдәҶдёӘReferеҸӮж•°
еҺҹйЎөйқў


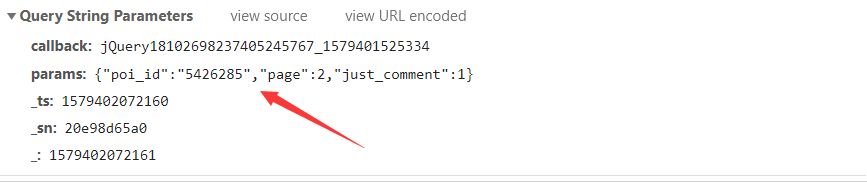
然еҗҺзңӢдёҖдёӢиҜ·жұӮgetиҜ·жұӮйңҖиҰҒзҡ„еҸӮж•°Query String ParametersпјҢе…¶дёӯpoi_idжҳҜжҷҜзӮ№idпјҢpageжҳҜиҜ„и®әйЎөйқўпјҲзҝ»йЎөеҸӘз”Ёж”№еҸҳpageзҡ„еҖје°ұиЎҢпјүгҖӮ
import re
import time
import requests
#иҜ„и®әеҶ…е®№жүҖеңЁзҡ„urlпјҢпјҹеҗҺйқўжҳҜgetиҜ·жұӮйңҖиҰҒзҡ„еҸӮж•°еҶ…е®№
comment_url='http://pagelet.mafengwo.cn/poi/pagelet/poiCommentListApi?'
requests_headers={
'Referer': 'http://www.mafengwo.cn/poi/5426285.html',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'
}#иҜ·жұӮеӨҙ
for num in range(1,6):
requests_data={
'params': '{"poi_id":"5426285","page":"%d","just_comment":1}' % (num) #з»ҸиҝҮжөӢиҜ•еҸӘйңҖиҰҒз”ЁparamsеҸӮж•°е°ұиғҪзҲ¬еҸ–еҶ…е®№
}
response =requests.get(url=comment_url,headers=requests_headers,params=requests_data)
if 200==response.status_code:
page = response.content.decode('unicode-escape', 'ignore').encode('utf-8', 'ignore').decode('utf-8')#зҲ¬еҸ–йЎөйқўе№¶дё”и§Јз Ғ
page = page.replace('\\/', '/')#е°Ҷ\/иҪ¬жҚўжҲҗ/
#ж—ҘжңҹеҲ—иЎЁ
date_pattern = r'<a class="btn-comment _j_comment" title="ж·»еҠ иҜ„и®ә">иҜ„и®ә</a>.*?\n.*?<span class="time">(.*?)</span>'
date_list = re.compile(date_pattern).findall(page)
#жҳҹзә§еҲ—иЎЁ
star_pattern = r'<span class="s-star s-star(\d)"></span>'
star_list = re.compile(star_pattern).findall(page)
#иҜ„и®әеҲ—иЎЁ
comment_pattern = r'<p class="rev-txt">([\s\S]*?)</p>'
comment_list = re.compile(comment_pattern).findall(page)
for num in range(0, len(date_list)):
#ж—Ҙжңҹ
date = date_list[num]
#жҳҹзә§иҜ„еҲҶ
star = star_list[num]
#иҜ„и®әеҶ…е®№пјҢеӨ„зҗҶдёҖдәӣж Үзӯҫе’Ңз¬ҰеҸ·
comment = comment_list[num]
comment = str(comment).replace(' ', '')
comment = comment.replace('<br>', '')
comment = comment.replace('<br />', '')
print(date+"\t"+star+"\t"+comment)
else:
print("зҲ¬еҸ–еӨұиҙҘ")
з»“жһң
д»ҘдёҠе°ұжҳҜжң¬ж–Үзҡ„е…ЁйғЁеҶ…е®№пјҢеёҢжңӣеҜ№еӨ§е®¶зҡ„еӯҰд№ жңүжүҖеё®еҠ©пјҢд№ҹеёҢжңӣеӨ§е®¶еӨҡеӨҡж”ҜжҢҒдәҝйҖҹдә‘гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ