жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
еҝ«иҰҒиҝҮе№ҙдәҶпјҢеӨ§е®¶йғҪеңЁеҝҷдәӣд»Җд№Ҳе‘ўпјҹдёҖеҲ°е№ҙеә•е…¬еҸёеҗ„з§ҚжҠўзҘЁпјҢеӨҮе№ҙиҙ§пјҢиў«иҝҷиҝҮе№ҙзҡ„ж°”ж°ӣдёҖзғҳпјҢйғҪеҪ’еҝғдјјз®ӯпјҢе“ӘиҝҳжңүеҝғжҖқдёҠзҸӯе•ҠгҖӮеҪ’еҝғдјјз®ӯ=дә§еҮәдҪҺдёӢ=дёҖиЎҢд»Јз ҒеҚҒдёӘй”ҷ=ж— иҒҠгҖӮдәҺжҳҜжғіиө·дәҶд»ҘеүҚеӯҰиҝҮдёҖж®өж—¶й—ҙзҡ„PythonпјҢиҮӘе·ұе№іж—¶д№ҹжҢәзҲұзңӢз”өеҪұзҡ„пјҢжүӢеҠЁзӮ№иҝӣеҺ»зңӢз”өеҪұиҜҰжғ…然еҗҺдёҖйғЁдёҖйғЁзҡ„еҺ»дёӢиҪҪеӨӘзғҰдәҶпјҢдҪ•дёҚз”ЁPythonеҶҷдёӘиҮӘеҠЁдёӢиҪҪз”өеҪұзҡ„е·Ҙе…·е‘ўпјҹиҜ¶пјҢиҝҷд№ҲдёҖжғіе°ұдёҚж— иҒҠдәҶгҖӮд»ҘеүҚиҝҳжІЎйӮЈд№ҲеӨҡXXдјҡе‘ҳзҡ„ж—¶еҖҷпјҢжғізңӢзңӢз”өеҪұйғҪжҳҜеҺ»XXеӨ©е ӮеҺ»жүҫз”өеҪұиө„жәҗпјҢеӨ§йғЁеҲҶжғізңӢзҡ„з”өеҪұиҝҳжҳҜжңүзҡ„пјҢе°ұе®ғдәҶпјҢзҲ¬е®ғпјҒ
иҜқиҜҙд»ҘеүҚзҺ©Pythonзҡ„ж—¶еҖҷзҲ¬иҝҮжҢәеӨҡзҪ‘з«ҷзҡ„пјҢйғҪжҳҜеңЁе…¬еҸёе№Ізҡ„(PythonдёҚеұһдәҺе…¬еҸёзҡ„дёҡеҠЎиҢғеӣҙпјҢзәҜеұһиҮӘе·ұжҠҳи…ҫзқҖеҘҪзҺ©)пјҢжҲ‘йӮЈдёӘиҙҹиҙЈиҝҗз»ҙзҡ„еҗҢдәӢеӨ©еӨ©и·‘иҝҮжқҘиҜҙпјҡдҪ еҸҲеңЁзҲ¬е•Ҙе•ҠпјҢдҪ еҺ»зңӢзңӢж–°й—»пјҢжҹҗжҹҗзҲ¬дёңиҘҝеҸҲиў«жҠ“дәҶпјҒеҮәдәҶдәӢдҪ иҮӘе·ұиҙҹиҙЈе•ҠпјҒе“Һе‘ҖжҲ‘зҡ„еЁҳдәІпјҢеҗ“зҡ„йғҪ没继з»ӯзҺ©дёӢеҺ»дәҶгҖӮиҝҷдёӘеҚҡе®ўжҳҜзҲ¬еҸ–жҹҗеӨ©е Ӯзҡ„иө„жәҗ(е…·дҪ“жҳҜе“ӘдёӘеӨ©е ӮдёӢйқўзҡ„д»Јз ҒйҮҢдјҡжңүзҡ„)пјҢдјҡдёҚдјҡиў«жҠ“е•ҠпјҹеҚ•зәҜзҡ„дҪңдёәжҠҖжңҜи®Ёи®әпјҢдёӘдәәз»ғжүӢпјҢдёҚеҒҡе•Ҷдёҡз”ЁйҖ”еә”иҜҘжІЎдәӢеҗ§пјҹеҶҷеҲ°иҝҷйҮҢе°ҸжүӢдёҚзҰҒеҫ®еҫ®йўӨжҠ–...
еҫ—еҳһпјҢжӯ»е°ұжӯ»еҗ§пјҢжҲ‘дёҚе…Ҙең°зӢұи°Ғе…Ҙең°зӢұпјҢе…ҲзңӢжңҖз»Ҳе®һзҺ°ж•Ҳжһң:
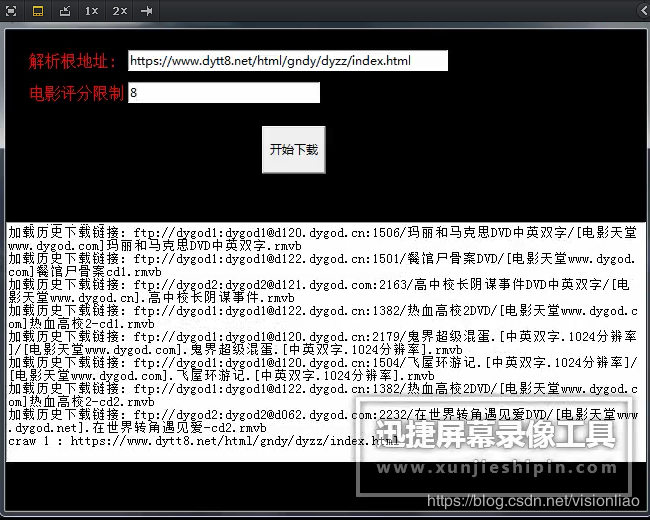
еҰӮдёҠпјҢиҝҷдёӘдёӢиҪҪе·Ҙе…·жҳҜжңүз•Ңйқўзҡ„(зүӣзҡ®еҗ§)пјҢеҸӘиҰҒиҫ“е…ҘдёҖдёӘж №ең°еқҖе’Ңз”өеҪұиҜ„еҲҶпјҢе°ұеҸҜд»ҘиҮӘеҠЁзҲ¬з”өеҪұдәҶпјҢиҰҒе®ҢжҲҗиҝҷдёӘе·Ҙе…·йңҖиҰҒе…·еӨҮд»ҘдёӢзҹҘиҜҶзӮ№пјҡ
е·®дёҚеӨҡе°ұиҝҷдәӣдәҶпјҢиҮідәҺе®һзҺ°зҡ„жҠҖжңҜз»ҶиҠӮзҡ„иҜқпјҢд№ҹдёҚеӨҡпјҢrequests+BeautifulSoupзҡ„дҪҝз”ЁпјҢreжӯЈеҲҷпјҢPythonж•°жҚ®зұ»еһӢпјҢPythonзәҝзЁӢпјҢdbmгҖҒpickleзӯүж•°жҚ®жҢҒд№…еҢ–еә“зҡ„дҪҝз”ЁпјҢзӯүзӯүпјҢиҝҷдёӘе·Ҙе…·д№ҹе°ұиҝҷд№ҲдәӣзҹҘиҜҶиҢғз•ҙдәҶгҖӮеҪ“然пјҢPythonжҳҜйқўеҗ‘еҜ№иұЎзҡ„пјҢзј–зЁӢжҖқжғіжҳҜжүҖжңүиҜӯиЁҖйҖҡз”Ёзҡ„пјҢиҝҷдёӘдёҚжҳҜдёҖжңқдёҖеӨ•зҡ„дәӢпјҢд№ҹжІЎеҠһжі•йҖҡиҝҮиҜӯиЁҖжҸҸиҝ°жё…жҘҡгҖӮеҗ„дҪҚеҜ№еҸ·е…Ҙеә§пјҢд»ҘдёҠе“ӘдёӘзҹҘиҜҶйқўдёҚи¶ізҡ„иҮӘе·ұеҺ»зҝ»иө„ж–ҷеӯҰд№ пјҢжҲ‘еҸҜжҳҜзӣҙжҺҘиҙҙд»Јз Ғзҡ„гҖӮ
иҜҙеҲ°Pythonзҡ„еӯҰд№ иҝҳжҳҜеӨҡиҜҙдёӨеҸҘеҗ§пјҢд»ҘеүҚеӯҰд№ PythonзҲ¬иҷ«зҡ„ж—¶еҖҷзңӢзҡ„жҳҜ @е·ҘеҢ иӢҘж°ҙ https://blog.csdn.net/yanboberзҡ„еҚҡе®ўпјҢиҝҷе“Ҙ们зҡ„Pythonж–Үз« еҶҷзҡ„зңҹдёҚй”ҷпјҢеҜ№дәҺжңүиҝҮзј–зЁӢз»ҸйӘҢеҚҙд»ҺжІЎжҺҘи§ҰиҝҮPythonзҡ„дәәеҫҲжңүеё®еҠ©пјҢеҹәжң¬дёҠеҫҲеҝ«е°ұиғҪдёҠжүӢдёҖдёӘе°ҸйЎ№зӣ®гҖӮеҫ—еҳһпјҢж’ёд»Јз Ғпјҡ
import url_manager
import html_parser
import html_download
import persist_util
from tkinter import *
from threading import Thread
import os
class SpiderMain(object):
def __init__(self):
self.mUrlManager = url_manager.UrlManager()
self.mHtmlParser = html_parser.HtmlParser()
self.mHtmlDownload = html_download.HtmlDownload()
self.mPersist = persist_util.PersistUtil()
# еҠ иҪҪеҺҶеҸІдёӢиҪҪй“ҫжҺҘ
def load_history(self):
history_download_links = self.mPersist.load_history_links()
if history_download_links is not None and len(history_download_links) > 0:
for download_link in history_download_links:
self.mUrlManager.add_download_url(download_link)
d_log("еҠ иҪҪеҺҶеҸІдёӢиҪҪй“ҫжҺҘ: " + download_link)
# дҝқеӯҳеҺҶеҸІдёӢиҪҪй“ҫжҺҘ
def save_history(self):
history_download_links = self.mUrlManager.get_download_url()
if history_download_links is not None and len(history_download_links) > 0:
self.mPersist.save_history_links(history_download_links)
def craw_movie_links(self, root_url, score=8):
count = 0;
self.mUrlManager.add_url(root_url)
while self.mUrlManager.has_continue():
try:
count = count + 1
url = self.mUrlManager.get_url()
d_log("craw %d : %s" % (count, url))
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36',
'Referer': url
}
content = self.mHtmlDownload.down_html(url, retry_count=3, headers=headers)
if content is not None:
doc = content.decode('gb2312', 'ignore')
movie_urls, next_link = self.mHtmlParser.parser_movie_link(doc)
if movie_urls is not None and len(movie_urls) > 0:
for movie_url in movie_urls:
d_log('movie info url: ' + movie_url)
content = self.mHtmlDownload.down_html(movie_url, retry_count=3, headers=headers)
if content is not None:
doc = content.decode('gb2312', 'ignore')
movie_name, movie_score, movie_xunlei_links = self.mHtmlParser.parser_movie_info(doc, score=score)
if movie_xunlei_links is not None and len(movie_xunlei_links) > 0:
for xunlei_link in movie_xunlei_links:
# еҲӨж–ӯиҜҘз”өеҪұжҳҜеҗҰе·Із»ҸдёӢиҪҪиҝҮдәҶ
is_download = self.mUrlManager.has_download(xunlei_link)
if is_download == False:
# жІЎдёӢиҪҪиҝҮзҡ„з”өеҪұж·»еҠ еҲ°иҝ…йӣ·дёӢиҪҪеҲ—иЎЁ
d_log('ејҖе§ӢдёӢиҪҪ ' + movie_name + ', й“ҫжҺҘең°еқҖ: ' + xunlei_link)
self.mUrlManager.add_download_url(xunlei_link)
os.system(r'"D:\иҝ…йӣ·\Thunder\Program\Thunder.exe" {url}'.format(url=xunlei_link))
# жҜҸдёӢиҪҪдёҖйғЁз”өеҪұйғҪе®һж—¶жӣҙж–°ж•°жҚ®еә“пјҢиҝҷж ·еҸҜд»ҘдҝқиҜҒеҚідҪҝзЁӢеәҸејӮеёёйҖҖеҮәд№ҹдёҚдјҡйҮҚеӨҚдёӢиҪҪиҜҘз”өеҪұ
self.save_history()
if next_link is not None:
d_log('next link: ' + next_link)
self.mUrlManager.add_url(next_link)
except Exception as e:
d_log('й”ҷиҜҜдҝЎжҒҜ: ' + str(e))
def runner(rootLink=None, scoreLimit=None):
if rootLink is None:
return
spider = SpiderMain()
spider.load_history()
if scoreLimit is None:
spider.craw_movie_links(rootLink)
else:
spider.craw_movie_links(rootLink, score=float(scoreLimit))
spider.save_history()
# rootLink = 'https://www.dytt8.net/html/gndy/dyzz/index.html'
# rootLink = 'https://www.dytt8.net/html/gndy/dyzz/list_23_207.html'
def start(rootLink, scoreLimit):
loop_thread = Thread(target=runner, args=(rootLink, scoreLimit,), name='LOOP THREAD')
#loop_thread.setDaemon(True)
loop_thread.start()
#loop_thread.join() # дёҚиғҪи®©дё»зәҝзЁӢзӯүеҫ…пјҢеҗҰеҲҷGUIз•Ңйқўе°ҶеҚЎжӯ»
btn_start.configure(state='disable')
# еҲ·ж–°GUIз•ҢйқўпјҢж–Үеӯ—ж»ҡеҠЁж•Ҳжһң
def d_log(log):
s = log + '\n'
txt.insert(END, s)
txt.see(END)
if __name__ == "__main__":
rootGUI = Tk()
rootGUI.title('XXз”өеҪұиҮӘеҠЁдёӢиҪҪе·Ҙе…·')
# и®ҫзҪ®зӘ—дҪ“иғҢжҷҜйўңиүІ
black_background = '#000000'
rootGUI.configure(background=black_background)
# иҺ·еҸ–еұҸ幕е®ҪеәҰе’Ңй«ҳеәҰ
screen_w, screen_h = rootGUI.maxsize()
# еұ…дёӯжҳҫзӨәзӘ—дҪ“
window_x = (screen_w - 640) / 2
window_y = (screen_h - 480) / 2
window_xy = '640x480+%d+%d' % (window_x, window_y)
rootGUI.geometry(window_xy)
lable_link = Label(rootGUI, text='и§Јжһҗж №ең°еқҖ: ',\
bg='black',\
fg='red', \
font=('е®ӢдҪ“', 12), \
relief=FLAT)
lable_link.place(x=20, y=20)
lable_link_width = lable_link.winfo_reqwidth()
lable_link_height = lable_link.winfo_reqheight()
input_link = Entry(rootGUI)
input_link.place(x=20+lable_link_width, y=20, relwidth=0.5)
lable_score = Label(rootGUI, text='з”өеҪұиҜ„еҲҶйҷҗеҲ¶: ', \
bg='black', \
fg='red', \
font=('е®ӢдҪ“', 12), \
relief=FLAT)
lable_score.place(x=20, y=20+lable_link_height+10)
input_score = Entry(rootGUI)
input_score.place(x=20+lable_link_width, y=20+lable_link_height+10, relwidth=0.3)
btn_start = Button(rootGUI, text='ејҖе§ӢдёӢиҪҪ', command=lambda: start(input_link.get(), input_score.get()))
btn_start.place(relx=0.4, rely=0.2, relwidth=0.1, relheight=0.1)
txt = Text(rootGUI)
txt.place(rely=0.4, relwidth=1, relheight=0.5)
rootGUI.mainloop()
spider_main.pyпјҢдё»д»Јз Ғе…ҘеҸЈпјҢдё»иҰҒжҳҜtkinter е®һзҺ°зҡ„дёҖдёӘз®ҖйҷӢзҡ„з•ҢйқўпјҢеҸҜд»Ҙиҫ“е…Ҙж №ең°еқҖпјҢз”өеҪұжңҖдҪҺиҜ„еҲҶгҖӮжүҖи°“зҡ„ж №ең°еқҖе°ұжҳҜжҹҗеӨ©е ӮзҪ‘з«ҷзҡ„дёҖзұ»з”өеҪұзҡ„е…ҘеҸЈпјҢжҜ”еҰӮиҝӣе…ҘйҰ–йЎөжңүеҰӮдёӢзҡ„еҲҶзұ»пјҢжңҖж–°з”өеҪұгҖҒж—Ҙйҹ©з”өеҪұгҖҒ欧зҫҺеҪұзүҮгҖҒ2019зІҫе“Ғдё“еҢәпјҢзӯүзӯүгҖӮиҝҷйҮҢд»Ҙ2019зІҫе“Ғдё“еҢәдёәдҫӢ(https://www.dytt8.net/html/gndy/dyzz/index.html)пјҢеҪ“然пјҢз”Ёе…¶е®ғзҡ„еҲҶзұ»ең°еқҖе…ҘеҸЈд№ҹжҳҜеҸҜд»Ҙзҡ„гҖӮиҜ„еҲҶе°ұжҳҜдёӘиҝҮж»Өз”өеҪұзҡ„жқЎд»¶пјҢиҰҒеӯҰдјҡеҜ№еһғеңҫз”өеҪұиҜҙдёҚпјҢжөӘиҙ№ж—¶й—ҙжөӘиҙ№иЎЁжғ…пјҢдҪ еҸҜд»ҘжҢҮе®ҡеӨ§дәҺзӯүдәҺ8еҲҶзҡ„з”өеҪұжүҚдёӢиҪҪпјҢд№ҹеҸҜд»ҘжҢҮе®ҡеӨ§дәҺзӯүдәҺ9еҲҶзӯүпјҢеҝ…йЎ»иҫ“е…Ҙж•°еӯ—е“ҲпјҢиҫ“е…Ҙдәӣд№ұдёғе…«зіҹзҡ„дёңиҘҝиҝӣеҺ»зЁӢеәҸдјҡеҙ©жәғпјҢиҝҷдёӘз»ҶиҠӮжҲ‘жҮ’еҫ—еӨ„зҗҶгҖӮ
'''
URLй“ҫжҺҘз®ЎзҗҶзұ»пјҢиҙҹиҙЈз®ЎзҗҶзҲ¬еҸ–дёӢжқҘзҡ„з”өеҪұй“ҫжҺҘең°еқҖпјҢеҢ…жӢ¬ж–°и§ЈжһҗеҮәжқҘзҡ„й“ҫжҺҘең°еқҖпјҢе’Ңе·Із»ҸдёӢиҪҪиҝҮзҡ„й“ҫжҺҘең°еқҖпјҢдҝқиҜҒзӣёеҗҢзҡ„й“ҫжҺҘең°еқҖеҸӘдјҡдёӢиҪҪдёҖж¬Ў
'''
class UrlManager(object):
def __init__(self):
self.urls = set()
self.used_urls = set()
self.download_urls = set()
def add_url(self, url):
if url is None:
return
if url not in self.urls and url not in self.used_urls:
self.urls.add(url)
def add_urls(self, urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self.add_url(url)
def has_continue(self):
return len(self.urls) > 0
def get_url(self):
url = self.urls.pop()
self.used_urls.add(url)
return url
def get_download_url(self):
return self.download_urls
def has_download(self, url):
return url in self.download_urls
def add_download_url(self, url):
if url is None:
return
if url not in self.download_urls:
self.download_urls.add(url)
url_manager.pyпјҢжіЁйҮҠйҮҢеҶҷзҡ„еҫҲжё…жҘҡдәҶпјҢеҹәжң¬дёҠжҜҸдёӘpyж–Ү件зҡ„е…ій”®ең°ж–№жҲ‘йғҪеҶҷдәҶжҜ”иҫғиҜҰз»Ҷзҡ„жіЁйҮҠ
import requests
from requests import Timeout
'''
HtmlDownloadпјҢйҖҡиҝҮдёҖдёӘй“ҫжҺҘең°еқҖе°ҶиҜҘhtmlйЎөйқўж•ҙдҪ“downдёӢжқҘпјҢ然еҗҺйҖҡиҝҮhtml_parser.pyи§Јжһҗе…¶дёӯжңүд»·еҖјзҡ„дҝЎжҒҜ
'''
class HtmlDownload(object):
def __init__(self):
self.request_session = requests.session()
self.request_session.proxies
def down_html(self, url, retry_count=3, headers=None, proxies=None, data=None):
if headers:
self.request_session.headers.update(headers)
try:
if data:
content = self.request_session.post(url, data=data, proxies=proxies)
print('result code: ' + str(content.status_code) + ', link: ' + url)
if content.status_code == 200:
return content.content
else:
content = self.request_session.get(url, proxies=proxies)
print('result code: ' + str(content.status_code) + ', link: ' + url)
if content.status_code == 200:
return content.content
except (ConnectionError, Timeout) as e:
print('HtmlDownload ConnectionError or Timeout: ' + str(e))
if retry_count > 0:
self.down_html(url, retry_count-1, headers, proxies, data)
return None
except Exception as e:
print('HtmlDownload Exception: ' + str(e))
html_download.pyпјҢе°ұжҳҜз”Ёrequestsе°ҶйқҷжҖҒзҪ‘йЎөзҡ„еҶ…е®№ж•ҙдҪ“downдёӢжқҘ
from bs4 import BeautifulSoup
from urllib.parse import urljoin
import re
import urllib.parse
import base64
'''
htmlйЎөйқўи§ЈжһҗеҷЁ
'''
class HtmlParser(object):
# и§Јжһҗз”өеҪұеҲ—иЎЁйЎөйқўпјҢиҺ·еҸ–з”өеҪұиҜҰжғ…йЎөйқўзҡ„й“ҫжҺҘ
def parser_movie_link(self, content):
try:
urls = set()
next_link = None
doc = BeautifulSoup(content, 'lxml')
div_content = doc.find('div', class_='co_content8')
if div_content is not None:
tables = div_content.find_all('table')
if tables is not None and len(tables) > 0:
for table in tables:
link = table.find('a', class_='ulink')
if link is not None:
print('movie name: ' + link.text)
movie_link = urljoin('https://www.dytt8.net', link.get('href'))
print('movie link ' + movie_link)
urls.add(movie_link)
next = div_content.find('a', text=re.compile(r".*?дёӢдёҖйЎө.*?"))
if next is not None:
next_link = urljoin('https://www.dytt8.net/html/gndy/dyzz/', next.get('href'))
print('movie next link ' + next_link)
return urls, next_link
except Exception as e:
print('и§Јжһҗз”өеҪұй“ҫжҺҘең°еқҖеҸ‘з”ҹй”ҷиҜҜ: ' + str(e))
# и§Јжһҗз”өеҪұиҜҰжғ…йЎөйқўпјҢиҺ·еҸ–з”өеҪұиҜҰз»ҶдҝЎжҒҜ
def parser_movie_info(self, content, score=8):
try:
movie_name = None # з”өеҪұеҗҚз§°
movie_score = 0 # з”өеҪұиҜ„еҲҶ
movie_xunlei_links = set() # з”өеҪұзҡ„иҝ…йӣ·дёӢиҪҪең°еқҖпјҢеҸҜиғҪеӯҳеңЁеӨҡдёӘ
doc = BeautifulSoup(content, 'lxml')
movie_name = doc.find('title').text.replace('иҝ…йӣ·дёӢиҪҪ_з”өеҪұеӨ©е Ӯ', '')
#print(movie_name)
div_zoom = doc.find('div', id='Zoom')
if div_zoom is not None:
# иҺ·еҸ–з”өеҪұиҜ„еҲҶ
span_txt = div_zoom.text
txt_list = span_txt.split('в—Һ')
if txt_list is not None and len(txt_list) > 0:
for tl in txt_list:
if 'IMDB' in tl or 'IMDb' in tl or 'imdb' in tl or 'IMdb' in tl:
txt_score = tl.split('/')[0]
print(txt_score)
movie_score = re.findall(r"\d+\.?\d*", txt_score)
if movie_score is None or len(movie_score) <= 0:
movie_score = 1
else:
movie_score = movie_score[0]
print(movie_name + ' IMDBеҪұзүҮеҲҶж•°: ' + str(movie_score))
if float(movie_score) < score:
print('з”өеҪұиҜ„еҲҶдҪҺдәҺ' + str(score) + ', еҝҪз•Ҙ')
return movie_name, movie_score, movie_xunlei_links
txt_a = div_zoom.find_all('a', href=re.compile(r".*?ftp:.*?"))
if txt_a is not None:
# иҺ·еҸ–з”өеҪұиҝ…йӣ·дёӢиҪҪең°еқҖпјҢbase64иҪ¬жҲҗиҝ…йӣ·ж јејҸ
for alink in txt_a:
xunlei_link = alink.get('href')
'''
иҝҷйҮҢе°Ҷз”өеҪұй“ҫжҺҘиҪ¬жҚўжҲҗиҝ…йӣ·зҡ„дё“з”ЁдёӢиҪҪй“ҫжҺҘпјҢеҗҺжқҘеҸ‘зҺ°дёҚиҪ¬жҚўиҝ…йӣ·д№ҹиғҪиҜҶеҲ«
xunlei_link = urllib.parse.quote(xunlei_link)
xunlei_link = xunlei_link.replace('%3A', ':')
xunlei_link = xunlei_link.replace('%40', '@')
xunlei_link = xunlei_link.replace('%5B', '[')
xunlei_link = xunlei_link.replace('%5D', ']')
xunlei_link = 'AA' + xunlei_link + 'ZZ'
xunlei_link = base64.b64encode(xunlei_link.encode('gbk'))
xunlei_link = 'thunder://' + str(xunlei_link, encoding='gbk')
'''
print(xunlei_link)
movie_xunlei_links.add(xunlei_link)
return movie_name, movie_score, movie_xunlei_links
except Exception as e:
print('и§Јжһҗз”өеҪұиҜҰжғ…йЎөйқўй”ҷиҜҜ: ' + str(e))
html_parser.pyпјҢз”Ёbs4и§ЈжһҗdownдёӢжқҘзҡ„htmlйЎөйқўеҶ…е®№пјҢж №жҚ®зҪ‘йЎө规еҲҷиҝҮеҺ»жҲ‘们йңҖиҰҒзҡ„дёңиҘҝпјҢиҝҷжҳҜзҲ¬иҷ«жңҖйҮҚиҰҒзҡ„ең°ж–№пјҢеҶҷзҲ¬иҷ«зҡ„зӣ®зҡ„е°ұжҳҜжғіиҰҒеҸ–еҮәеҜ№жҲ‘们жңүз”Ёзҡ„дёңиҘҝгҖӮ
import dbm
import pickle
import os
'''
ж•°жҚ®жҢҒд№…еҢ–е·Ҙе…·зұ»
'''
class PersistUtil(object):
def save_data(self, name='No Name', urls=None):
if urls is None or len(urls) <= 0:
return
try:
history_db = dbm.open('downloader_history', 'c')
history_db[name] = str(urls)
finally:
history_db.close()
def get_data(self):
history_links = set()
try:
history_db = dbm.open('downloader_history', 'r')
for key in history_db.keys():
history_links.add(str(history_db[key], 'gbk'))
except Exception as e:
print('йҒҚеҺҶdbmж•°жҚ®еӨұиҙҘ: ' + str(e))
return history_links
# дҪҝз”ЁpickleдҝқеӯҳеҺҶеҸІдёӢиҪҪи®°еҪ•
def save_history_links(self, urls):
if urls is None or len(urls) <= 0:
return
with open('DownloaderHistory', 'wb') as pickle_file:
pickle.dump(urls, pickle_file)
# иҺ·еҸ–дҝқеӯҳеңЁpickleдёӯзҡ„еҺҶеҸІдёӢиҪҪи®°еҪ•
def load_history_links(self):
if os.path.exists('DownloaderHistory'):
with open('DownloaderHistory', 'rb') as pickle_file:
return pickle.load(pickle_file)
else:
return None
persist_util.pyпјҢж•°жҚ®жҢҒд№…еҢ–е·Ҙе…·зұ»гҖӮ
иҝҷж ·д»Јз ҒйғЁеҲҶе°ұе®ҢжҲҗдәҶпјҢиҜҙдёӢиҝ…йӣ·пјҢжҲ‘е®үиЈ…зҡ„жҳҜжңҖж–°зүҲзҡ„иҝ…йӣ·XпјҢдёҖе®ҡиҰҒеҰӮдёӢеӣҫдёҖж ·еңЁиҝ…йӣ·и®ҫзҪ®жү“ејҖдёҖй”®дёӢиҪҪеҠҹиғҪпјҢеҗҰеҲҷжҜҸж¬Ўж–°еўһдёҖдёӘдёӢиҪҪд»»еҠЎйғҪдјҡеј№еҮәз”ЁжҲ·зЎ®и®ӨжЎҶзҡ„пјҢиҝҳжңүе°ұжҳҜи°ғз”Ёиҝ…йӣ·дёӢиҪҪиө„жәҗзҡ„д»Јз Ғпјҡos.system(r'"D:\иҝ…йӣ·\Thunder\Program\Thunder.exe" {url}'.format(url=xunlei_link))пјҢдёҖе®ҡиҰҒеҺ»еҲ°иҝ…йӣ·е®үиЈ…зӣ®еҪ•жүҫеҲ°Thunder.exeж–Ү件пјҢдёҚиғҪз”Ёеҝ«жҚ·ж–№ејҸзҡ„ең°еқҖ(жҲ‘зҡ„з”өи„‘->иҝ…йӣ·->еҸій”®еұһжҖ§->зӣ®ж ҮпјҢиҝ…йӣ·XиҝҷйҮҢжҳҫзӨәзҡ„и·Ҝеҫ„жҳҜеҝ«жҚ·ж–№ејҸзҡ„и·Ҝеҫ„пјҢдёҚиғҪз”ЁиҝҷдёӘ)пјҢеҗҰеҲҷжүҫдёҚеҲ°зЁӢеәҸгҖӮ
еҲ°иҝҷйҮҢдҪ еә”иҜҘе°ұеҸҜд»Ҙз”өеҪұзҲ¬иө·жқҘдәҶпјҢеҰҘеҰҘзҡ„гҖӮеҪ“然пјҢдҪ жғіиҰҒдјҳеҢ–д№ҹеҸҜд»ҘпјҢзЁӢеәҸжңүеҫҲеӨҡеҸҜд»ҘдјҳеҢ–зҡ„ең°ж–№пјҢжҜ”еҰӮзәҝзЁӢйӮЈдёҖеқ—пјҢжҜ”еҰӮж•°жҚ®жҢҒд№…еҢ–йӮЈйҮҢ..... еҲқеӯҰиҖ…еҸҜд»ҘйҖҡиҝҮиҝҷдёӘз»ғжүӢпјҢ然еҗҺиҮӘе·ұеҺ»еҲҶжһҗеҲҶжһҗйқҷжҖҒзҪ‘з«ҷзҡ„规еҲҷпјҢжҠҠи§ЈжһҗhtmlйӮЈдёҖеқ—зҡ„д»Јз Ғж”№ж”№е°ұеҸҜд»ҘзҲ¬е…¶е®ғзҡ„зҪ‘з«ҷдәҶпјҢжҜ”еҰӮйӮЈдәӣжңүзқҖеҚұйҷ©еҠЁдҪңзҡ„з”өеҪұ... дёҚиҝҮиҝҷзұ»з”өеҪұиҝҳжҳҜе°‘зңӢдёәеҰҷпјҢиҰҒеӨҡиҜ»д№ҰпјҢеҒ¶е°”зңӢдәҶд№ҹиҰҒж“Ұж“Ұе№ІеҮҖпјҢжҙ—жҙ—е№ІеҮҖпјҢиҰҒи®ІеҚ«з”ҹгҖӮ
д»ҘдёҠе°ұжҳҜжң¬ж–Үзҡ„е…ЁйғЁеҶ…е®№пјҢеёҢжңӣеҜ№еӨ§е®¶зҡ„еӯҰд№ жңүжүҖеё®еҠ©пјҢд№ҹеёҢжңӣеӨ§е®¶еӨҡеӨҡж”ҜжҢҒдәҝйҖҹдә‘гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ