您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
我用的是Anaconda3 ,用spyder编写pytorch的代码,在Anaconda3中新建了一个pytorch的虚拟环境(虚拟环境的名字就叫pytorch)。
以下内容仅供参考哦~~
1.首先打开Anaconda Prompt,然后输入activate pytorch,进入pytorch.
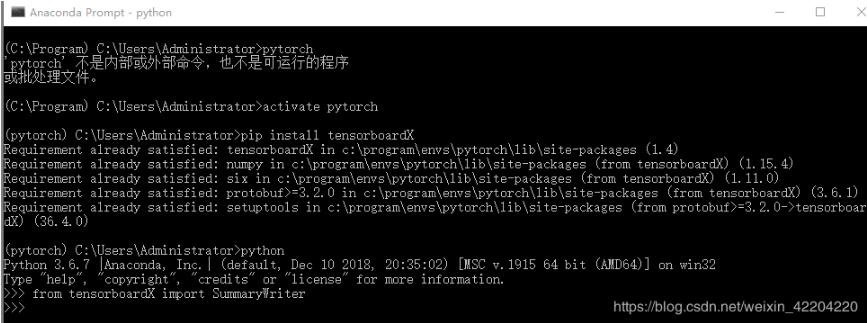
2.输入pip install tensorboardX,安装完成后,输入python,用from tensorboardX import SummaryWriter检验是否安装成功。如下图所示:
3.安装完成之后,先给大家看一下我的文件夹,如下图:
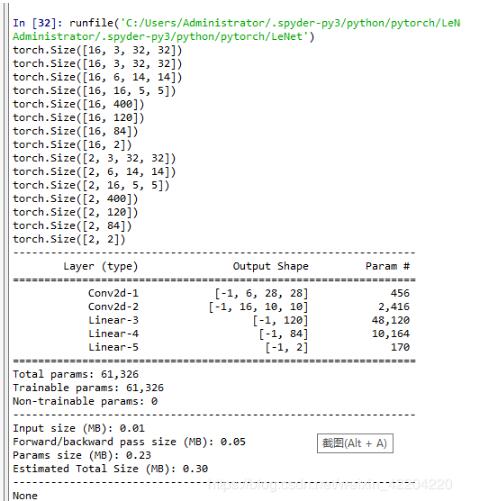
假设用LeNet5框架识别图像的准确率,LeNet.py代码如下:
import torch import torch.nn as nn from torchsummary import summary from torch.autograd import Variable import torch.nn.functional as F class LeNet5(nn.Module): #定义网络 pytorch定义网络有很多方式,推荐以下方式,结构清晰 def __init__(self): super(LeNet5,self).__init__() self.conv1 = nn.Conv2d(3, 6, 5) self.conv2 = nn.Conv2d(6, 16, 5) self.fc1 = nn.Linear(16*5*5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 2) def forward(self,x): # print(x.size()) x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2)) # print(x.size()) x = F.max_pool2d(F.relu(self.conv2(x)), 2) # print(x.size()) x = x.view(x.size()[0], -1)#全连接层均使用的nn.Linear()线性结构,输入输出维度均为一维,故需要把数据拉为一维 #print(x.size()) x = F.relu(self.fc1(x)) # print(x.size()) x = F.relu(self.fc2(x)) #print(x.size()) x = self.fc3(x) # print(x.size()) return x net = LeNet5() data_input = Variable(torch.randn(16,3,32,32)) print(data_input.size()) net(data_input) print(summary(net,(3,32,32)))
示网络结构如下图:
训练代码(LeNet_train_test.py)如下:
# -*- coding: utf-8 -*-
"""
Created on Wed Jan 2 15:53:33 2019
@author: Administrator
"""
import torch
import torch.nn as nn
import os
import numpy as np
import matplotlib.pyplot as plt
from torchvision import datasets,transforms
import torchvision
import LeNet
from torch import optim
import time
from torch.optim import lr_scheduler
from tensorboardX import SummaryWriter
writer = SummaryWriter('LeNet5')
data_transforms = {
'train':transforms.Compose([
#transforms.Resize(56),
transforms.RandomResizedCrop(32),#
transforms.RandomHorizontalFlip(),#已给定的概率随即水平翻转给定的PIL图像
transforms.ToTensor(),#将图片转换为Tensor,归一化至[0,1]
transforms.Normalize([0.485,0.456,0.406],[0.229, 0.224, 0.225])#用平均值和标准偏差归一化张量图像
]),
'val':transforms.Compose([
#transforms.Resize(56),
transforms.CenterCrop(32),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])
]),
}
data_dir = 'bees vs ants' #样本文件夹
image_datasets = {x:datasets.ImageFolder(os.path.join(data_dir,x),
data_transforms[x])
for x in ['train','val']
}
dataloaders = {x:torch.utils.data.DataLoader(image_datasets[x],batch_size =16,
shuffle = True,num_workers = 0)
for x in ['train','val']
}
dataset_sizes = {x:len(image_datasets[x]) for x in ['train','val']}
class_names = image_datasets['train'].classes
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
def imshow(inp,title = None):
#print(inp.size())
inp = inp.numpy().transpose((1,2,0))
mean = np.array([0.485,0.456,0.406])
std = np.array([0.229,0.224,0.225])
inp = std * inp + mean
inp = np.clip(inp,0,1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001)#为了让图像更新可以暂停一会
#Get a batch of training data
inputs,classes = next(iter(dataloaders['train']))
#print(inputs.size())
#print(inputs.size())
#Make a grid from batch
out = torchvision.utils.make_grid(inputs)
#print(out.size())
imshow(out,title=[class_names[x] for x in classes])
def train_model(model,criterion,optimizer,scheduler,num_epochs = 25):
since = time.time()
# best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch,num_epochs - 1))
print('-' * 10)
#Each epoch has a training and validation phase
for phase in ['train','val']:
if phase == 'train':
scheduler.step()
model.train() #Set model to training mode
else:
model.eval()
running_loss = 0.0
running_corrects = 0
#Iterate over data
for inputs,labels in dataloaders[phase]:
inputs = inputs.to(device)
# print(inputs.size())
labels = labels.to(device)
#print(inputs.size())
# print(labels.size())
#zero the parameter gradients(参数梯度为零)
optimizer.zero_grad()
#forward
#track history if only in train
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_,preds = torch.max(outputs,1)
loss = criterion(outputs,labels)
#backward + optimize only if in training phase
if phase == 'train':
loss.backward()
optimizer.step()
#statistics
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
if phase == 'train':
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase,epoch_loss,epoch_acc))
writer.add_scalar('Train/Loss', epoch_loss,epoch)
writer.add_scalar('Train/Acc',epoch_acc,epoch)
else:
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase,epoch_loss,epoch_acc))
writer.add_scalar('Test/Loss', epoch_loss,epoch)
writer.add_scalar('Test/Acc',epoch_acc,epoch)
if epoch_acc > best_acc:
best_acc = epoch_acc
print()
writer.close()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60 , time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
#load best model weights
#model.load_state_dict()#best_model_wts)
return model
def visualize_model(model,num_images = 6):
was_training = model.training
model.eval()
images_so_far = 0
plt.figure()
with torch.no_grad():
for i,(inputs,labels) in enumerate(dataloaders['val']):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_,preds = torch.max(outputs,1)
for j in range(inputs.size()[0]):
images_so_far += 1
ax = plt.subplot(num_images //2,2,images_so_far)
ax.axis('off')
ax.set_title('predicted: {}'.format(class_names[preds[j]]))
imshow(inputs.cpu().data[j])
if images_so_far == num_images:
model.train(mode = was_training)
return
model.train(mode=was_training)
net = LeNet.LeNet5()
net = net.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(),lr = 0.001,momentum = 0.9)
exp_lr_scheduler = lr_scheduler.StepLR(optimizer,step_size = 7,gamma = 0.1)
net = train_model(net,criterion,optimizer,exp_lr_scheduler,num_epochs = 25)
#net1 = train_model(net,criterion,optimizer,exp_lr_scheduler,num_epochs = 25)
visualize_model(net)
plt.ioff()
plt.show()
最终的二分类结果为:
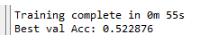
样本图像是pytorch官网中介绍迁移学习时用到的,蚂蚁与蜜蜂的二分类图像,图像大小不一。LeNet5 的输入图像是32*32,所以进行分类时会损失一定的图像像素,导致识别率较低。
下面介绍显示loss和acc曲线,在以上训练代码中,writer = SummaryWriter('LeNet5'),表示在训练过程中会生成LeNet5文件夹,保存loss曲线和acc曲线的文件,如下图:
首先解释一下这个文件夹为什么是1,因为我之前训练了很多次,在LeNet5文件夹下有很多1文件夹中这样的文件,待会用Anaconda Prompt来显示loss和acc的时候,它只识别一个文件,所以我就重新建了一个1文件夹,并将刚刚运行完毕的文件放到文件夹中。在LeNet_train_test.py中, writer.add_scalar('Train/Loss', epoch_loss,epoch)和
writer.add_scalar('Train/Acc',epoch_acc,epoch),这两行代码就是生成train数据集的loss和acc曲线,同理测试数据集亦是如此。
好啦,下面开始显示loss和acc:
1.打开Anaconda Prompt,再次进入pytorch虚拟环境,
2.输入tensorboard --logdir=C:\Users\Administrator\.spyder-py3\python\pytorch\LeNet\LeNet5\1,红色部分是来自上图文件夹的根目录,按回车键,会出现tensorboard的版本和一个网址,总体显示效果如下图:

复制网址到浏览器中,在此处是复制:http://8AEYUVZ5PNOFCBX:6006 到浏览器中,

最终结果如下图:
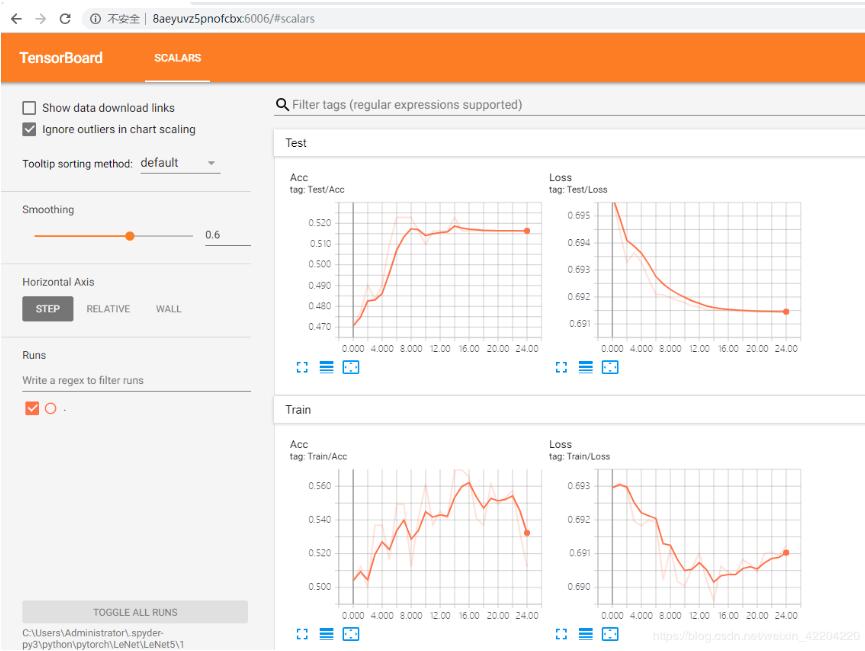
好啦,以上就是如何显示loss曲线和acc曲线以及LeNet5模型建立及训练的过程啦。
如果,文中有哪些地方描述的不恰当,请大家批评指正,不喜欢也不要喷我,好不好~~~
以上这篇pytorch绘制并显示loss曲线和acc曲线,LeNet5识别图像准确率就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持亿速云。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。