жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жҹҗеӨ©ж°”зҪ‘з«ҷпјҲwww.ж•°еӯ—.comпјүеӯҳжңү2011е№ҙиҮід»Ҡзҡ„еӨ©ж°”ж•°жҚ®пјҢжңүеӨ©зңӢеҲ°дёҖжң¬зҲ¬иҷ«ж•ҷжқҗжҸҗеҲ°дәҶзҲ¬еҸ–иҝҷдәӣж•°жҚ®зҡ„ж–№жі•пјҢеӯҰд№ д№ӢпјҢ并еҠ д»Ҙж”№иҝӣгҖӮ
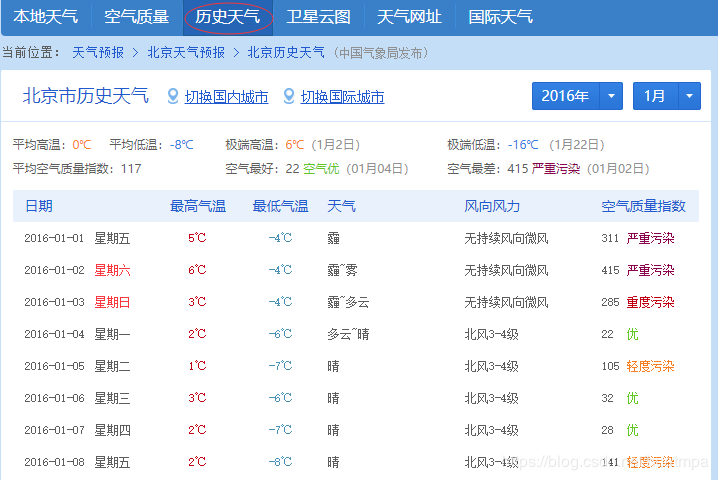
еҮҶеӨҮзҲ¬зҡ„еҺҶеҸІеӨ©ж°”
зҲ¬д№ӢеүҚе…ҲеҲҶжһҗurlгҖӮе·ҰдёҠжңүе№ҙд»ҪгҖҒжңҲд»Ҫзҡ„дёӢжӢүйҖүжӢ©жЎҶпјҢжҢүF12пјҢиҝӣеҺ»зңӢзңӢиғҪеҗҰжүҫеҲ°зңҹжӯЈзҡ„urlпјҡ
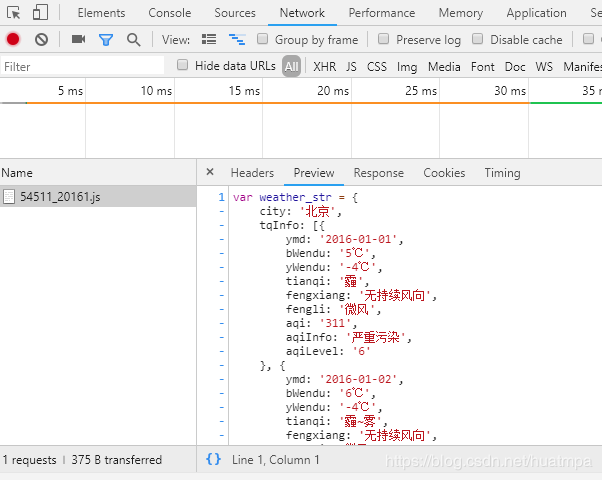
еҫҲе®№жҳ“е°ұжүҫеҲ°дәҶпјҢе·Ұиҫ№жҳҜеӮЁеӯҳжңҲеәҰж•°жҚ®зҡ„jsж–Ү件пјҢеҸіиҫ№жҳҜж–Ү件жәҗд»Јз ҒпјҢиІҢдјјjsonж јејҸгҖӮ
еҸҢеҮ»е·Ұиҫ№jsж–Ү件пјҢең°еқҖж ҸеҶ…еҮәзҺ°дәҶurlпјҡhttp://tianqi.ж•°еӯ—.com/t/wea_history/js/54511_20161.js
urlдёӯзҡ„вҖң54511вҖқжҳҜеҹҺеёӮд»Јз ҒпјҢвҖң20161вҖқжҳҜе№ҙд»Ҫе’ҢжңҲд»Ҫд»Јз ҒгҖӮдёӢдёҖжӯҘе°ұжҳҜжүҫеҲ°еҹҺеёӮд»Јз ҒеҲ—иЎЁпјҢжҢүеҹҺеёӮ+е№ҙд»Ҫ+жңҲд»Ҫжһ„йҖ urlеҲ—иЎЁпјҢе°ұиғҪејҖе§ӢйҒҚеҺҶзҲ¬еҸ–дәҶгҖӮ
еҹҺеёӮд»Јз Ғд№ҹеҫҲиҜҡе®һпјҢеҫҲеҝ«е°ұжүҫеҲ°дәҶпјҡ
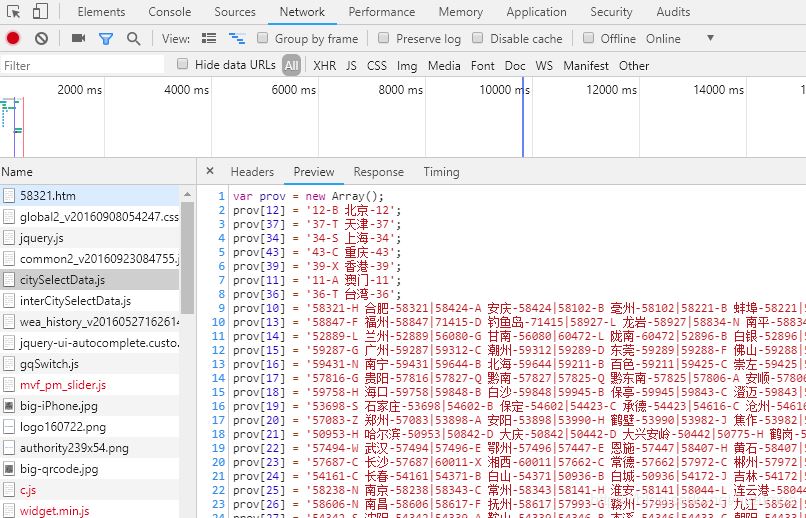
дёӢдёҖжӯҘеҫ—жҠҠеҹҺеёӮеҗҚз§°е’Ңд»Јз ҒжҸҗеҸ–еҮәжқҘпјҢжһ„йҖ дёҖдёӘвҖңеҹҺеёӮеҗҚз§°пјҡеҹҺеёӮд»Јз ҒвҖқзҡ„еӯ—е…ёпјҢжҲ–иҖ…з”ұе…ғз»„пјҲеҹҺеёӮеҗҚз§°пјҢеҹҺеёӮд»Јз Ғпјүз»„жҲҗзҡ„еҲ—иЎЁпјҢдҫӣзҲ¬еҸ–ж—¶йҒҚеҺҶгҖӮиҖғиҷ‘еҲ°жӯЈеҲҷжҸҗеҸ–ж—¶пјҢжһ„йҖ е…ғз»„жӣҙдҫҝжҚ·пјҢе°ұдёҚеҒҡжҲҗеӯ—е…ёдәҶгҖӮ
def getCity():
html = reqs.get('https://tianqi.2345.com/js/citySelectData.js').content
text = html.decode('gbk')
city = re.findall('([1-5]\d{4})\-[A-Z]\s(.*?)\-\d{5}',text) #еҸӘжҸҗеҸ–дәҶең°зә§еёӮеҸҠд»ҘдёҠеҹҺеёӮзҡ„еҗҚз§°е’Ңд»Јз ҒпјҢ5д»ҘдёҠзҡ„жҳҜеҺҝзә§еёӮ
city = list(set(city)) #еҺ»жҺүйҮҚеӨҚеҹҺеёӮж•°жҚ®
print('еҹҺеёӮеҲ—иЎЁиҺ·еҸ–жҲҗеҠҹ')
return city
жҺҘдёӢжқҘжҳҜжһ„йҖ urlеҲ—иЎЁпјҢж„ҹи°ўж•ҷжқҗдё»зј–зҡ„жҸҗйҶ’пјҢиҝҷйҮҢйҒҝе…ҚдәҶдёҖдёӘеӨ§еқ‘гҖӮеҺҹжқҘ2017е№ҙд№ӢеүҚзҡ„urlз»“жһ„е’ҢеҗҺйқўзҡ„дёҚдёҖж ·пјҢеңЁиҝҷйҮҢз…§жҗ¬дәҶдё»зј–зҡ„жһ„йҖ ж–№жі•пјҡ
def getUrls(cityCode):
urls = []
for year in range(2011,2020):
if year <= 2016:
for month in range(1, 13):
urls.append('https://tianqi.ж•°еӯ—.com/t/wea_history/js/%s_%s%s.js' % (cityCode,year, month))
else:
for month in range(1,13):
if month<10:
urls.append('https://tianqi.ж•°еӯ—.com/t/wea_history/js/%s0%s/%s_%s0%s.js' %(year,month,cityCode,year,month))
else:
urls.append('https://tianqi.ж•°еӯ—.com/t/wea_history/js/%s%s/%s_%s%s.js' %(year,month,cityCode,year,month))
return urls
жҺҘдёӢжқҘе®ҡд№үдёҖдёӘзҲ¬еҸ–йЎөйқўзҡ„еҮҪж•°getHtml()пјҢиҝҷдёӘжҳҜ常规ж“ҚдҪңпјҢз”ЁrequestsжЁЎеқ—е°ұиЎҢдәҶпјҡ
def getHtml(url):
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:14.0) Gecko/20100101 Firefox/14.0.1',
'Referer': '******'}
request = reqs.get(url,headers = header)
text = request.content.decode('gbk') #з»ҸиҜ•и§ЈжһҗпјҢиҝҷйҮҢеҫ—з”ЁgbkжЁЎејҸ
time.sleep(random.randint(1,3)) #йҡҸжңәжҡӮеҒңпјҢеҮҸиҪ»жңҚеҠЎеҷЁеҺӢеҠӣ
return text
然еҗҺе°ұжҳҜйҮҚзӮ№йғЁеҲҶдәҶпјҢж•°жҚ®и§ЈжһҗдёҺжҸҗеҸ–гҖӮ
иҜ•дәҶиҜ•jsonи§ЈжһҗпјҢеҸ‘зҺ°ж•ҲжһңдёҚеҘҪпјҢеӣ дёәйЎөйқўж–Үжң¬йҮҢйқўеҗ«жқӮиҙЁгҖӮ
иҝҳжҳҜз”ЁжӯЈеҲҷиЎЁиҫҫејҸеҗ§пјҢиғҪеӨҹжҸҗеҸ–жңүж•Ҳж•°жҚ®пјҢе°ҪеҸҜиғҪе°‘жөӘиҙ№жңәеҷЁж—¶й—ҙгҖӮ
2016е№ҙејҖе§Ӣзҡ„ж•°жҚ®е’Ңд№ӢеүҚе№ҙд»ҪдёҚдёҖж ·пјҢеӨҡдәҶPM2.5жұЎжҹ“зү©жғ…еҶөпјҢеӣ жӯӨжһ„йҖ жӯЈеҲҷиЎЁиҫҫејҸж—¶пјҢиҝҳдёҚиғҪз”ЁеҒ·жҮ’жЁЎејҸгҖӮ
str1 = "{ymd:'(.*?)',bWendu:'(.*?)в„ғ',yWendu:'(.*?)в„ғ',tianqi:'(.*?)',fengxiang:'(.*?)',fengli:'(.*?)',aqi:'(.*?)',aqiInfo:'(.*?)',aqiLevel:'(.*?)'.*?}"
str2 = "{ymd:'(.*?)',bWendu:'(.*?)в„ғ',yWendu:'(.*?)в„ғ',tianqi:'(.*?)',fengxiang:'(.*?)',fengli:'(.*?)'.*?}"
#иҝҷдёӘе°ұжҳҜеҒ·жҮ’жЁЎејҸпјҢеҸ–еҮәжқҘзҡ„еҶ…е®№зӣҙжҺҘеӯҳе…Ҙе…ғз»„дёӯ
еҰӮжһңдёҘж јд»Ҙ2016е№ҙдёәз•ҢпјҢз”ЁдёҖдёӢеҒ·жҮ’жЁЎејҸиҝҳиЎҢпјҢдҪҶжң¬дәәеңЁиҝҷйҮҢйҒҮеқ‘дәҶпјҢеҺҹжқҘдёӘеҲ«еҹҺеёӮзҡ„жұЎжҹ“зү©дҝЎжҒҜжҳҜж—¶жңүж—¶ж— зҡ„пјҢжҗһдёҚжё…еңЁжҹҗе№ҙжҹҗжңҲзҡ„жҹҗеӨ©е°ұеҮәзҺ°дәҶпјҢеӣ жӯӨиҝҳеҫ—жһ„йҖ дёҖдёӘйҖҡз”ЁзүҲзҡ„пјҢжҠҠж•°жҚ®йғҪжҸҗеҮәжқҘпјҢеҶҚжҠҠж— з”Ёзҡ„еӯ—з¬ҰеҺ»жҺүгҖӮ
def getDf(url):
html = getHtml(url)
pa = re.compile(r'{(ymd.+?)}') #з”Ё'{ymd'жү“еӨҙпјҢжҠҠдёҚжҳҜжҜҸж—ҘеӨ©ж°”зҡ„е…¶е®ғж•°жҚ®еҝҪз•ҘжҺү
text = re.findall(pa,html)
list0 = []
for item in text:
s = item.split(',') #еҲҶеүІжҲҗжҜҸж—Ҙж•°жҚ®
d = [i.split(':') for i in s] #жҸҗеҸ–еҶ’еҸ·еүҚеҗҺзҡ„ж•°жҚ®еҗҚз§°е’Ңж•°жҚ®еҖј
t = {k:v.strip("'").strip('в„ғ') for k,v in d} #з”Ёж•°жҚ®еҗҚз§°е’Ңж•°жҚ®еҖјжһ„йҖ еӯ—е…ё
list0.append(t)
df = pd.DataFrame(list0) #еҠ е…ҘpandasеҲ—иЎЁдёӯпјҢдҫҝдәҺдҝқеӯҳ
return df
ж•°жҚ®зҡ„дҝқеӯҳпјҢиҝҷйҮҢйҖүжӢ©дәҶsqlite3иҪ»дҫҝеһӢж•°жҚ®еә“пјҢеҸҜд»ҘдҝқеӯҳжҲҗdbж–Ү件пјҡ
def work(city,url):
con =sql.connect('d:\\еӨ©ж°”.db')
try:
df = getDf(url)
df.insert(0,'еҹҺеёӮеҗҚз§°',city) #ж–°еўһдёҖеҲ—еҹҺеёӮеҗҚз§°
df.to_sql('total', con, if_exists='append', index=False)
print(url,'дёӢиҪҪе®ҢжҲҗ')
except Exception as e:
print("еҮәзҺ°й”ҷиҜҜ:\n",e)
finally:
con.commit()
con.close()
еңЁиҝҷйҮҢиҝҳжңүдёҖдёӘе°Ҹеқ‘пјҢ第дёҖж¬ЎиҝһжҺҘж•°жҚ®еә“ж–Ү件时пјҢеҰӮжһңж–Ү件дёҚеӯҳеңЁпјҢдјҡиҮӘеҠЁж·»еҠ пјҢеҗҺз»ӯеңЁеҶҷе…Ҙж•°жҚ®ж—¶пјҢеҰӮжһңж•°жҚ®дёӯж–°еўһдәҶеӯ—ж®өпјҢеҶҷе…Ҙж—¶дјҡжҠҘй”ҷгҖӮеҸҜд»Ҙе…ҲжҠҠж•°жҚ®еә“ж–Ү件еӯ—ж®өйғҪи®ҫзҪ®еҘҪпјҢдҪҶиҝҷж ·еӨӘзҙҜпјҢжүҖд»Ҙжң¬дәәеҸҲжҗһдәҶдёӘеҒ·жҮ’зҡ„ж–№ејҸпјҢеҚіе…Ҳдј е…ҘдёҖдёӘ2019е№ҙжҹҗжңҲзҡ„еҚ•дёӘurlжҗһдёҖдёӢпјҢиҮӘеҠЁж·»еҠ еҘҪеӯ—ж®өпјҢеҗҺйқўеҶҚеҶҷе…Ҙж—¶е°ұжІЎй—®йўҳдәҶгҖӮжң¬дәәи§үеҫ—иҝҷдёӘеә”иҜҘиҝҳжңүжӣҙдҪізҡ„и§ЈеҶіеҠһжі•пјҢзӣ®еүҚиҝҳеңЁжҢ–жҺҳдёӯгҖӮ
ж•°жҚ®дҝқеӯҳеҗҺзҡ„зҠ¶жҖҒеҰӮдёӢпјҡ
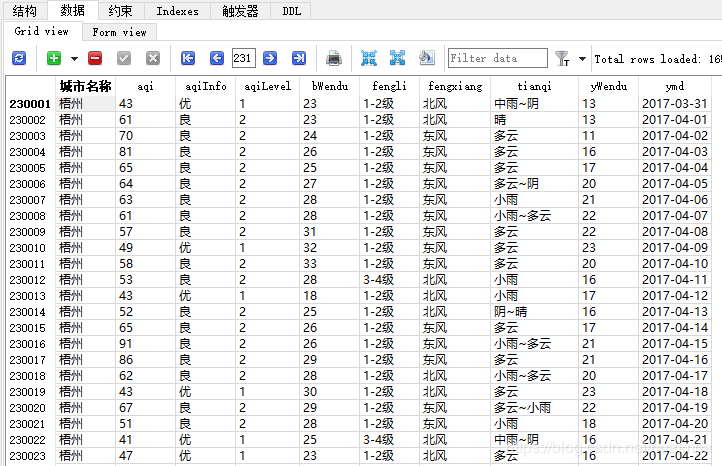
жң¬жқҘиҖғиҷ‘иҝҮз”ЁеӨҡзәҝзЁӢзҲ¬иҷ«пјҢжғіжғіеҸҲи§үеҫ—既然дәә家没жңүи®ҫзҪ®еҸҚзҲ¬жҺӘж–ҪпјҢе’ұ们д№ҹдёҚиғҪеӨӘдёҚеҺҡйҒ“дәҶпјҢе°ұеҚ•зәҝзЁӢеҗ§гҖӮ
жңҖз»ҲзҲ¬дәҶ334дёӘеҹҺеёӮпјҢ100еӨҡдёҮжқЎж•°жҚ®гҖӮ
д»ҘдёҠе°ұжҳҜжң¬ж–Үзҡ„е…ЁйғЁеҶ…е®№пјҢеёҢжңӣеҜ№еӨ§е®¶зҡ„еӯҰд№ жңүжүҖеё®еҠ©пјҢд№ҹеёҢжңӣеӨ§е®¶еӨҡеӨҡж”ҜжҢҒдәҝйҖҹдә‘гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ