жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
йҰ–е…Ҳпјҡж–Үз« з”ЁеҲ°зҡ„и§Јжһҗеә“д»Ӣз»Қ
BeautifulSoupпјҡ
Beautiful SoupжҸҗдҫӣдёҖдәӣз®ҖеҚ•зҡ„гҖҒpythonејҸзҡ„еҮҪж•°з”ЁжқҘеӨ„зҗҶеҜјиҲӘгҖҒжҗңзҙўгҖҒдҝ®ж”№еҲҶжһҗж ‘зӯүеҠҹиғҪгҖӮ
е®ғжҳҜдёҖдёӘе·Ҙе…·з®ұпјҢйҖҡиҝҮи§Јжһҗж–ҮжЎЈдёәз”ЁжҲ·жҸҗдҫӣйңҖиҰҒжҠ“еҸ–зҡ„ж•°жҚ®пјҢеӣ дёәз®ҖеҚ•пјҢжүҖд»ҘдёҚйңҖиҰҒеӨҡе°‘д»Јз Ғе°ұеҸҜд»ҘеҶҷеҮәдёҖдёӘе®Ңж•ҙзҡ„еә”з”ЁзЁӢеәҸгҖӮ
Beautiful SoupиҮӘеҠЁе°Ҷиҫ“е…Ҙж–ҮжЎЈиҪ¬жҚўдёәUnicodeзј–з ҒпјҢиҫ“еҮәж–ҮжЎЈиҪ¬жҚўдёәutf-8зј–з ҒгҖӮ
дҪ дёҚйңҖиҰҒиҖғиҷ‘зј–з Ғж–№ејҸпјҢйҷӨйқһж–ҮжЎЈжІЎжңүжҢҮе®ҡдёҖдёӘзј–з Ғж–№ејҸпјҢиҝҷж—¶пјҢBeautiful Soupе°ұдёҚиғҪиҮӘеҠЁиҜҶеҲ«зј–з Ғж–№ејҸдәҶгҖӮ然еҗҺпјҢдҪ д»…д»…йңҖиҰҒиҜҙжҳҺдёҖдёӢеҺҹе§Ӣзј–з Ғж–№ејҸе°ұеҸҜд»ҘдәҶгҖӮ
Beautiful Soupе·ІжҲҗдёәе’ҢlxmlгҖҒhtml6libдёҖж ·еҮәиүІзҡ„pythonи§ЈйҮҠеҷЁпјҢдёәз”ЁжҲ·зҒөжҙ»ең°жҸҗдҫӣдёҚеҗҢзҡ„и§Јжһҗзӯ–з•ҘжҲ–ејәеҠІзҡ„йҖҹеәҰгҖӮ
зҲ¬еҸ–е°ҸиҜҙеҺҹеӣ иғҢжҷҜпјҡ
д»ҘеүҚеҫҲе–ңж¬ўзңӢиө·зӮ№зҪ‘дёҠйқўзҡ„е°ҸиҜҙпјҢдҪҶжҳҜеҫҲеӨҡйғҪиҰҒй’ұпјҢз©·еӯҰз”ҹжІЎеӨҡе°‘й’ұпјҢе°ұеҸ‘зҺ°дәҶ笔趣зҪ‘гҖӮ
笔趣зңӢжҳҜдёҖдёӘе°ҸиҜҙзҪ‘з«ҷпјҢиҝҷйҮҢжңүеҫҲеӨҡиө·зӮ№дёӯж–ҮзҪ‘зҡ„е…Қиҙ№е°ҸиҜҙпјҢиҖҢдё”иҝҷдёӘзҪ‘з«ҷеҸӘиғҪеңЁзәҝжөҸи§ҲпјҢдёҚж”ҜжҢҒе°ҸиҜҙжү“еҢ…дёӢиҪҪгҖӮ
жүҖд»Ҙжң¬ж¬ЎзҲ¬еҸ–е‘ўпјҢе°ұжҳҜд»ҺиҜҘзҪ‘з«ҷзҲ¬еҸ–并дҝқеӯҳдёҖдёӘеҗҚдёәгҖҠдёҖеҝөж°ёжҒ’гҖӢзҡ„е°ҸиҜҙгҖӮ
еҸҰеӨ–жң¬ж¬ЎзҲ¬еҸ–еҸӘжҳҜеҒҡдҫӢеӯҗжј”зӨәпјҢиҜ·ж”ҜжҢҒжӯЈзүҲиө„жәҗпјҒпјҒпјҒпјҒпјҒпјҒпјҒпјҒпјҒпјҒпјҒ
йӮЈд№Ҳз®ҖеҚ•зҡ„зҲ¬еҸ–ејҖе§Ӣпјҡ
в‘ жү“ејҖurlй“ҫжҺҘпјҢжҢүF12жҲ–иҖ…еҸій”®- жЈҖжҹҘ иҝӣе…ҘејҖеҸ‘иҖ…е·Ҙе…·
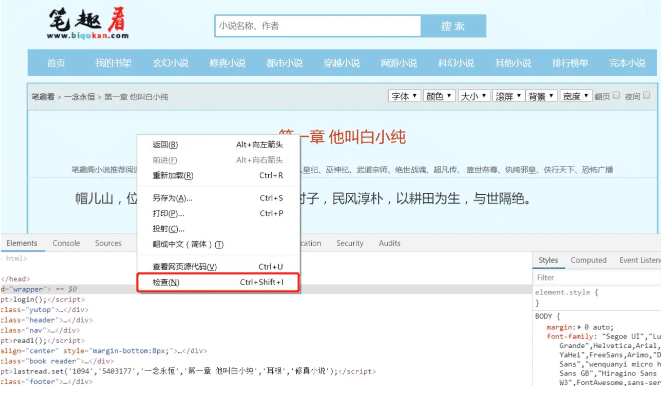
в‘Ў еңЁејҖеҸ‘иҖ…е·Ҙе…·дёӯпјҢжҚ•иҺ·жҲ‘们иҰҒжүҫеҲ°зҡ„иҜ·жұӮжқЎзӣ®дҝЎжҒҜ
йҖүжӢ©дё»ж–Үз« зҡ„дёҖйғЁеҲҶеҶ…е®№пјҢйҖүжӢ©еӨҚеҲ¶зІҳиҙҙйӮЈдёҖйғЁеҲҶпјҢ
然еҗҺеҶҚжү“ејҖејҖеҸ‘иҖ…е·Ҙе…·ж Ҹпјҡ
вҖңnetworkвҖ”йҖүжӢ©ж”ҫеӨ§й•ңеӣҫж ҮsreachвҖ”然еҗҺеҶҚжҗңзҙўж ҸзІҳиҙҙжҲ‘们иҰҒжҗңзҙўзҡ„еҶ…е®№вҖқ
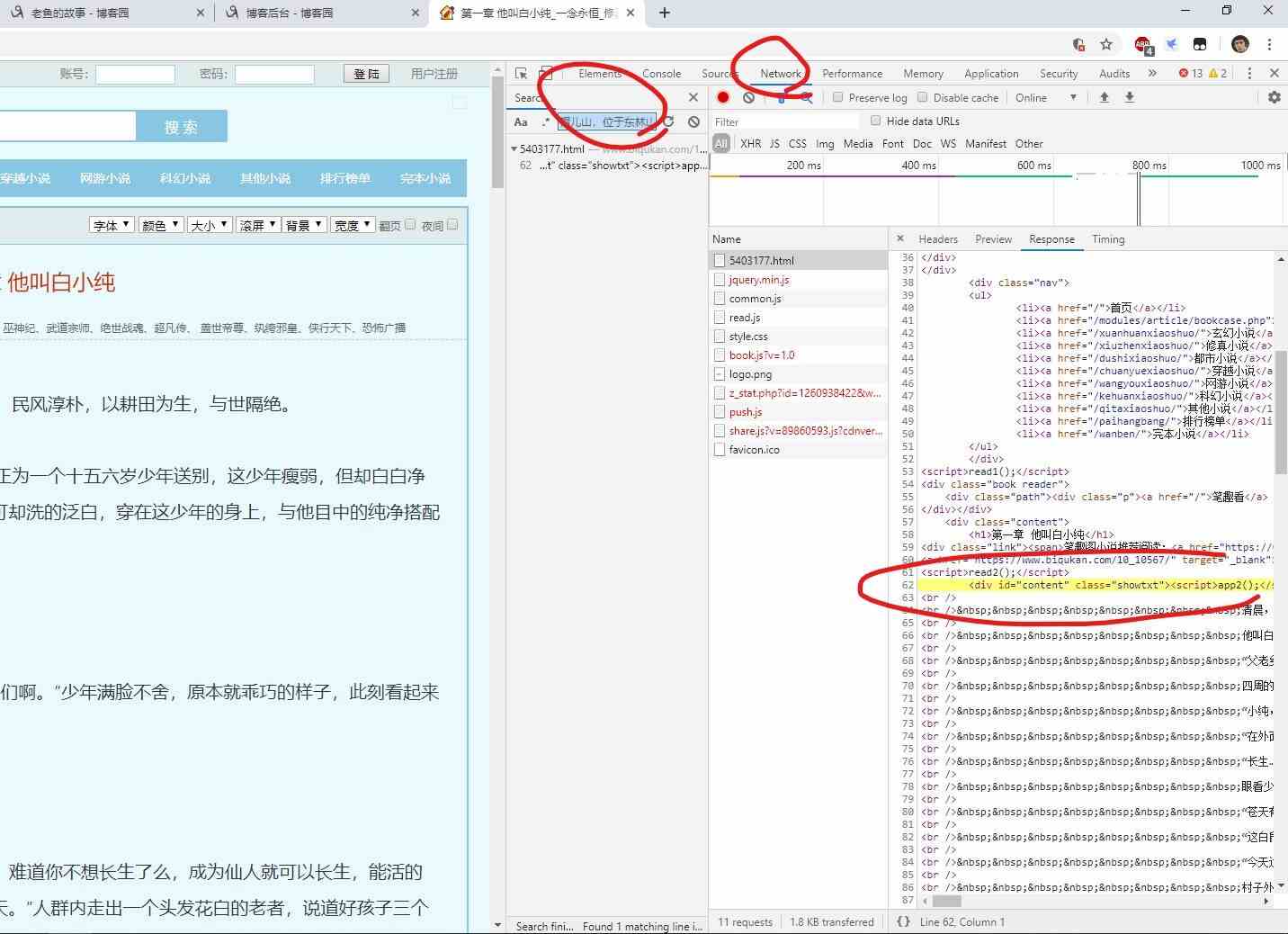
然еҗҺдјҡеңЁдёӢж–№еҫ—еҲ°жқЎзӣ®дҝЎжҒҜпјҢзӮ№еҮ»пјҢйЎөйқўдјҡи·іиҪ¬еҲ°еҠ иҪҪжӯЈж–Үзҡ„иҜ·жұӮе“Қеә”жқЎзӣ®дёӯгҖӮ
жҲ‘们еҸҜд»ҘзңӢеҲ°пјҡ
жӯЈж–ҮйғЁеҲҶжҳҜеӨ„дәҺ id дёә content е’Ң class дёә showtxt зҡ„ div дёӯгҖӮ
в‘ў жһ„йҖ urlиҜ·жұӮ
дёҠйқўзҡ„дҝЎжҒҜжҳҜдёҚеӨҹзҡ„пјҢеӣ дёәзҺ°еңЁзҡ„зҪ‘з«ҷйғҪжңүдәҶеҸҚзҲ¬иғҪеҠӣпјҢжҲ‘们жүҖйңҖиҰҒжҳҜжЁЎжӢҹдёҖжқЎжӯЈеёёд»ҺжөҸи§ҲеҷЁдёӯеҸ‘еҮәзҡ„urlиҜ·жұӮй“ҫжҺҘгҖӮ
иҝҷйҮҢжҲ‘们дјҡз”ЁеҲ°пјҡ User-AgentпјҲжөҸи§ҲеҷЁж ҮиҜҶпјү
иҝҳжҳҜејҖеҸ‘иҖ…е·Ҙе…·пјҢзӮ№еҮ»HeadersпјҢе°ұеҸҜд»ҘзңӢеҲ°Request-ResponseжқЎзӣ®жҳҺз»ҶгҖӮ
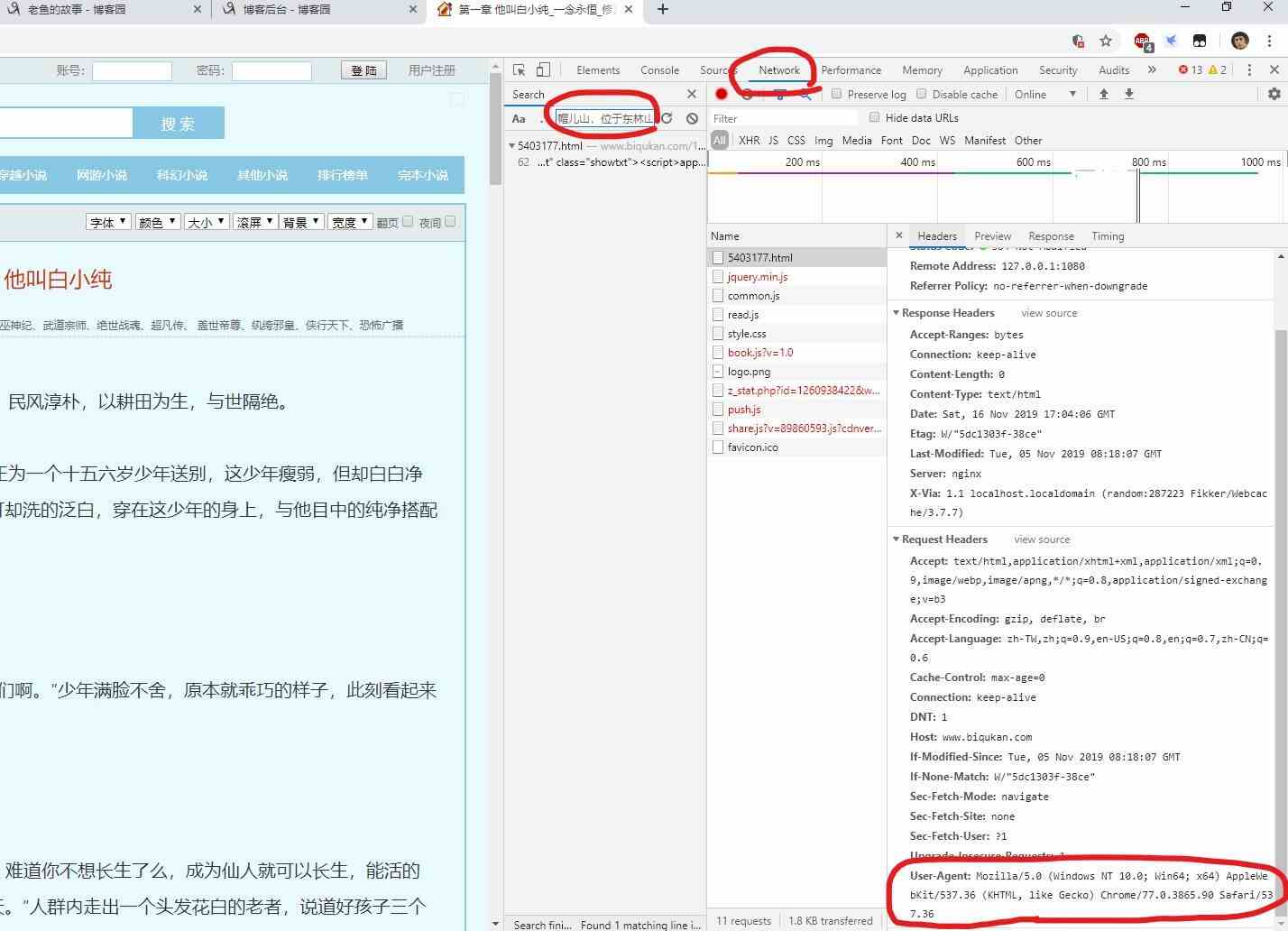
в‘Ј еҸ‘еҮәиҜ·жұӮпјҡ
жңүдәҶеӯ—ж®өзҡ„иҜҰз»ҶеҶ…е®№пјҢжҲ‘们е°ұеҸҜд»Ҙзј–еҶҷеҮәиҜ·жұӮзҪ‘йЎөзҡ„д»Јз Ғ
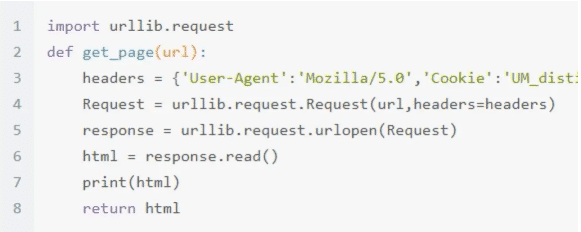
в‘Ө иҺ·еҫ—зӣёеә”еҶ…е®№пјҢ然еҗҺиҝҗиЎҢпјҢеҫ—еҲ°еҶ…е®№еҰӮдёӢ:
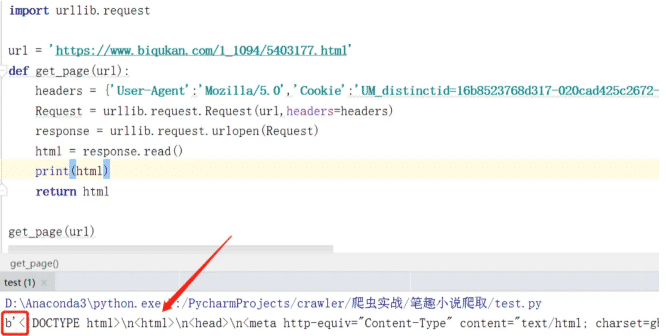
и§Јжһҗе“Қеә”ж•°жҚ®
дёӢйқўпјҢжҲ‘们дҪҝз”ЁBeautifulSoupиҝӣиЎҢи§Јжһҗ иҝҗиЎҢвҖҰ.д»Јз Ғз»“жһңеҰӮеӣҫпјҡ
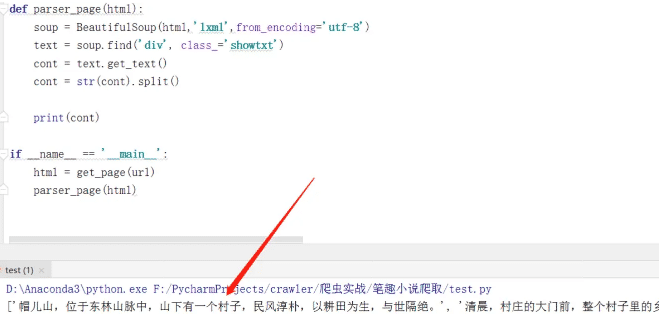
еҲ°иҝҷйҮҢпјҢе°ҸиҜҙе°ұзҲ¬еҸ–е®ҢжҲҗдәҶгҖӮ
д»ҘдёҠе°ұжҳҜжң¬ж–Үзҡ„е…ЁйғЁеҶ…е®№пјҢеёҢжңӣеҜ№еӨ§е®¶зҡ„еӯҰд№ жңүжүҖеё®еҠ©пјҢд№ҹеёҢжңӣеӨ§е®¶еӨҡеӨҡж”ҜжҢҒдәҝйҖҹдә‘гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ