您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本文实例讲述了Django框架ORM数据库操作。分享给大家供大家参考,具体如下:
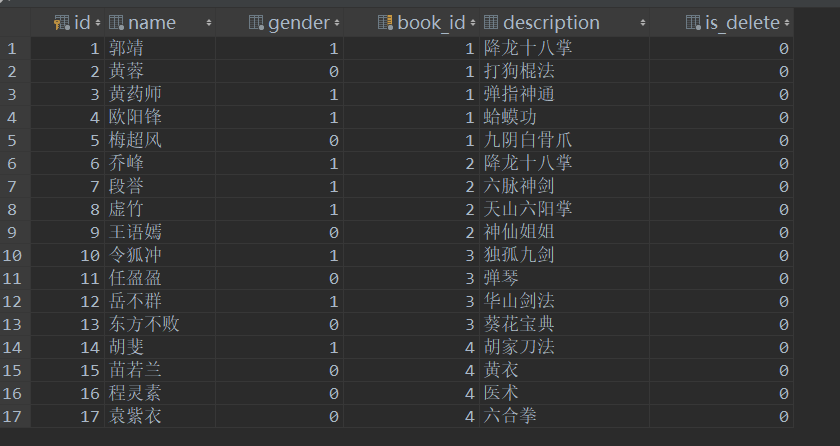
测试数据:BookInfo表

PeopleInfo表
1.save:
对象 = 模型类( 字段名 = 值, 字段名 = 值, … )
对象.save()
例:
>>> book = BookInfo( ... name='python入门', ... pub_date='2010-1-1' ... ) >>> book.save() >>> book <BookInfo: python入门>
2.create:
模型类.objects.create( 字段名 = 值, 字段名 = 值, … )
例:
>>> PeopleInfo.objects.create( ... name='itheima', ... book=book ... ) <PeopleInfo: itheima>
1.模型类对象delete:
对象 = 模型类.objects.get(条件)
对象.delete()
例:
>>> person = PeopleInfo.objects.get(name='传智播客')
>>> person.delete()
(1, {'book.PeopleInfo': 1})
2.模型类.objects.filter().delete():
模型类.objects.filter(条件).delete()
例:
>>> BookInfo.objects.filter(name='python入门').delete()
(1, {'book.BookInfo': 1, 'book.PeopleInfo': 0})
1.save:
对象 = 模型类.objects.get(条件)
对象.属性 = 值
对象.save()
例:
>>> person = PeopleInfo.objects.get(name='itheima') >>> person.name = 'itcast' >>> person.save() >>> person <PeopleInfo: itcast>
2.update:
模型类.objects.filter(条件).update(属性=值) (返回的是受影响的行数)
例:
>>> PeopleInfo.objects.filter(name='itcast').update(name='传智播客')
get:查询单一结果,不存在会抛出DoesNotExist异常。(查询结果不是1个也会报错)
all:查询多个结果。
count:查询结果数量。
用法:模型类.objects.get/all/count()
filter:过滤出多个结果
exclude:排除掉符合条件剩下的结果
get:过滤出单一结果
用法:属性名称__比较运算符 = 值
exact:相等
例:查询编号为1的图书。
BookInfo.objects.filter(id__exact=1)
可简写为:
BookInfo.objects.filter(id=1)
contains:包含
例:查询书名包含'传'的图书。
BookInfo.objects.filter(name__contains='传') <QuerySet [<BookInfo: 射雕英雄传>]>
startswith/endswith:以指定值开头/结尾
例:查询书名以'部'结尾的图书
>>> BookInfo.objects.filter(name__endswith='部') <QuerySet [<BookInfo: 天龙八部>]>
isnull:是否为空
例:查询书名为空的图书。
>>> BookInfo.objects.filter(name__isnull=True) <QuerySet []>
in:是否包含在范围内
例:查询编号为1或3或5的图书
>>> BookInfo.objects.filter(id__in=[1,3,5]) <QuerySet [<BookInfo: 射雕英雄传>, <BookInfo: 笑傲江湖>]>
gt/gte/lt/lte:比较查询,分别为大于,大于等于,小于,小于等于
例:查询编号大于3的图书
>>> BookInfo.objects.filter(id__gt=3) <QuerySet [<BookInfo: 雪山飞狐>]>
year/month/day/week_day/hour/minute/second:时间日期
例:查询1980年发表的图书。
>>> BookInfo.objects.filter(pub_date__year=1980) <QuerySet [<BookInfo: 射雕英雄传>]>
F对象:用来比较两个属性(使用前需要导入)
用法:F(属性名)
例:查询阅读量大于等于评论量的图书。
>>> from django.db.models import F
>>> BookInfo.objects.filter(readcount__gt=F('commentcount'))
<QuerySet [<BookInfo: 雪山飞狐>]>
Q对象:实现逻辑或or的查询
用法:Q(属性名__运算符=值),也可在前面加~表示not
例:查询阅读量大于20,或编号小于3的图书
>>> BookInfo.objects.filter(Q(readcount__gt=20)|Q(id__lt=3)) <QuerySet [<BookInfo: 射雕英雄传>, <BookInfo: 天龙八部>, <BookInfo: 雪山飞狐>]>
聚合函数:可使用aggregate()过滤器调用聚合函数(Avg,Count,Max,Min,Sum)
用法:模型类.objects.aggregate(聚合函数(字段名))
例:查询图书的总阅读量。
>>> from django.db.models import Sum
>>> BookInfo.objects.aggregate(Sum('readcount'))
{'readcount__sum': 126}
返回值为字典类型:{'属性名__聚合类小写':值}
注意:使用count一般不用使用过滤器
例:查询图书总数。
BookInfo.objects.count()
返回值为一个数字
用法:模型类.objects.all().order_by(属性名)
默认升序排序,属性名前加-为降序
例:
# 默认升序
>>> BookInfo.objects.all().order_by('readcount')
<QuerySet [<BookInfo: 射雕英雄传>, <BookInfo: 笑傲江湖>, <BookInfo: 天龙八部>, <BookInfo: 雪山飞狐>]>
# 降序
>>> BookInfo.objects.all().order_by('-readcount')
<QuerySet [<BookInfo: 雪山飞狐>, <BookInfo: 天龙八部>, <BookInfo: 笑傲江湖>, <BookInfo: 射雕英雄传>]>
一到多的访问:
用法:一对应的模型类对象.多对应的模型类名小写_set
例:查询id为1的书籍人物
>>> book = BookInfo.objects.get(id=1) >>> book.peopleinfo_set.all() <QuerySet [<PeopleInfo: 郭靖>, <PeopleInfo: 黄蓉>, <PeopleInfo: 黄药师>, <PeopleInfo: 欧阳锋>, <PeopleInfo: 梅超风>]>
多到一的访问:
用法:多对应的模型类对象.多对应的模型类中的关系类.属性名
例:查询id为1的人物的书籍
>>> person = PeopleInfo.objects.get(id=1) >>> person.book.name ‘射雕英雄传'
关联过滤查询:
用法:关联模型类名小写__属性名__条件运算符=值
例:查询图书,要求图书中人物的描述包含"八"
>>> book = BookInfo.objects.filter(peopleinfo__description__contains='八') >>> book <QuerySet [<BookInfo: 射雕英雄传>, <BookInfo: 天龙八部>]>
查询图书阅读量大于30的所有人物
>>> people = PeopleInfo.objects.filter(book__readcount__gt=30) >>> people <QuerySet [<PeopleInfo: 乔峰>, <PeopleInfo: 段誉>, <PeopleInfo: 虚竹>, <PeopleInfo: 王语嫣>, <PeopleInfo: 胡斐>, <PeopleInfo: 苗若兰>, <PeopleInfo: 程灵素>, <PeopleInfo: 袁紫衣>]>
希望本文所述对大家基于Django的Python程序设计有所帮助。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。