жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚpythonдёӯеҰӮдҪ•е®һзҺ°tkinterеӣҫеҪўз•Ңйқўд»Јз Ғз»ҹи®Ўе·Ҙе…·пјҢж–Үдёӯд»Ӣз»Қзҡ„йқһеёёиҜҰз»ҶпјҢе…·жңүдёҖе®ҡзҡ„еҸӮиҖғд»·еҖјпјҢж„ҹе…ҙи¶Јзҡ„е°Ҹдјҷдјҙ们дёҖе®ҡиҰҒзңӢе®ҢпјҒ
д»Јз Ғз»ҹи®Ўе·Ҙе…·
дҝ®ж”№дәҶеҜјеҮәexcelеҠҹиғҪпјҢжҠҠеҺҹжқҘзҡ„дё»ж–Ү件иҝӣиЎҢдәҶжӢҶеҲҶ
code_count_windows.py
#encoding=utf-8
import os,sys,time
from collections import defaultdict
from tkinter import *
import tkinter.messagebox
from tkinter import ttk
from tkinter import scrolledtext
import out_save
import code_count
root= Tk()
root.title("жңүж•Ҳд»Јз Ғз»ҹи®Ўе·Ҙе…·") #з•Ңйқўзҡ„title
def show(): #еҪ“жҢүй’®иў«зӮ№еҮ»пјҢе°ұи°ғз”ЁиҝҷдёӘж–№жі•
pathlist=e1.get() #и°ғз”Ёget()ж–№жі•еҫ—еҲ°еңЁж–Үжң¬жЎҶдёӯиҫ“е…Ҙзҡ„еҶ…е®№
file_types=e2.get().lower()
file_types_list=["py","java"]
if not pathlist:
tkinter.messagebox.showwarning('жҸҗзӨә',"иҜ·иҫ“е…Ҙж–Ү件и·Ҝеҫ„пјҒ")
return None
if not file_types:
tkinter.messagebox.showwarning('жҸҗзӨә',"иҜ·иҫ“е…ҘиҰҒз»ҹи®Ўзҡ„зұ»еһӢпјҒ")
return None
#print(type(file_types),file_types)
if '\u4e00'<=file_types<='\u9fa5' or not file_types in file_types_list: #еҲӨж–ӯж–Ү件зұ»еһӢиҫ“е…Ҙзҡ„жҳҜеҗҰжҳҜдёӯж–Ү
tkinter.messagebox.showwarning('й”ҷиҜҜ',"иҫ“е…Ҙз»ҹи®Ўзұ»еһӢжңүиҜҜпјҒ")
return None
text.delete(1.0,END) #еҲ йҷӨжҳҫзӨәж–Үжң¬жЎҶдёӯпјҢеҺҹжңүзҡ„еҶ…е®№
global code_dict
for path in pathlist.split(";"):
path=path.strip()
codes,code_dict,space,annotation=code_count.code_count(path,file_types) #е°ҶеҮҪж•°иҝ”еӣһзҡ„з»“жһңиөӢеҖјз»ҷеҸҳйҮҸпјҢж–№дҫҝиҫ“еҮә
max_code=max(zip(code_dict.values(),code_dict.keys()))
#print(codes,code_dict)
#print("ж•ҙдёӘ%sжңү%sзұ»еһӢж–Ү件%dдёӘпјҢе…ұжңү%dиЎҢд»Јз Ғ"%(path,file_types,len(code_dict),codes))
#print("д»Јз ҒжңҖеӨҡзҡ„жҳҜ%sпјҢжңү%dиЎҢд»Јз Ғ"%(max_code[1],max_code[0]))
for k,v in code_dict.items():
text.insert(INSERT,"ж–Ү件%s жңүж•Ҳд»Јз Ғж•°%s\n"%(k,v[0])) #е°Ҷж–Ү件еҗҚе’Ңжңүж•Ҳд»Јз Ғиҫ“еҮәеҲ°ж–Үжң¬жЎҶдёӯ
text.insert(INSERT,"ж•ҙдёӘ%sдёӢжңү%sзұ»еһӢж–Ү件%dдёӘпјҢе…ұжңү%dиЎҢжңүж•Ҳд»Јз Ғ\n"%(path,file_types,len(code_dict),codes)) #е°Ҷз»“жһңиҫ“еҮәеҲ°ж–Үжң¬жЎҶдёӯ
text.insert(INSERT,"е…ұжңү%dиЎҢжіЁйҮҠ\n"%(annotation))
text.insert(INSERT,"е…ұжңү%dиЎҢз©әиЎҢ\n"%(space))
text.insert(INSERT,"д»Јз ҒжңҖеӨҡзҡ„жҳҜ%sпјҢжңү%sиЎҢжңүж•Ҳд»Јз Ғ\n\n"%(max_code[1],max_code[0][0]))
frame= Frame(root) #дҪҝз”ЁFrameеўһеҠ дёҖеұӮе®№еҷЁ
frame.pack(padx=50,pady=40) #и®ҫзҪ®еҢәеҹҹ
label= Label(frame,text="и·Ҝеҫ„пјҡ",font=("е®ӢдҪ“",15),fg="blue").grid(row=0,padx=10,pady=5,sticky=N) #еҲӣе»әж Үзӯҫ
labe2= Label(frame,text="зұ»еһӢпјҡ",font=("е®ӢдҪ“",15),fg="blue").grid(row=1,padx=10,pady=5)
e1= Entry(frame,foreground = 'blue',font = ('Helvetica', '12')) #еҲӣе»әж–Үжң¬иҫ“е…ҘжЎҶ
e2= Entry(frame,font = ('Helvetica', '12', 'bold'))
e1.grid(row=0,column=1,sticky=W) #еёғзҪ®ж–Үжң¬иҫ“е…ҘжЎҶ
e2.grid(row=1,column=1,sticky=W,)
labeltitle=Label(frame,text="иҫ“е…ҘеӨҡдёӘж–Ү件и·Ҝеҫ„иҜ·дҪҝз”Ё';'еҲҶеүІ",font=("е®ӢдҪ“",10,'bold'),fg="red")
labeltitle.grid(row=2,column=1,sticky=NW)
frame.bind_all("<F1>",lambda event:helpinf())
frame.bind_all("<Return>",lambda event:show())
frame.bind_all("<Alt-F4>",lambda event:sys.exit())
frame.bind_all("<Control-s>",lambda event:save())
#print(path,file_types)
button1= Button(frame ,text=" жҸҗдәӨ ",font=("е®ӢдҪ“",13),width=10,command=show).grid(row=3,column=0,padx=15,pady=5) #еҲӣе»әжҢүй’®
button2= Button(frame ,text=" йҖҖеҮә ",font=("е®ӢдҪ“",13),width=10,command=root.quit).grid(row=3,column=1,padx=15,pady=5)
#self.hi_there.pack()
text = scrolledtext.ScrolledText(frame,width=40,height=10,font=("е®ӢдҪ“",15)) #еҲӣе»әеҸҜж»ҡеҠЁзҡ„ж–Үжң¬жҳҫзӨәжЎҶ
text.grid(row=4,column=0,padx=40,pady=15,columnspan=2) #ж”ҫзҪ®ж–Үжң¬жҳҫзӨәжЎҶ
def save():
#print(text.get("0.0","end"))
if not text.get("0.0","end").strip(): #иҺ·еҸ–ж–Үжң¬жЎҶеҶ…е®№пјҢд»ҺејҖе§ӢеҲ°з»“жқҹ
tkinter.messagebox.showwarning('жҸҗзӨә',"иҝҳжІЎжңүз»ҹи®Ўж•°жҚ®пјҒ")
return None
savecount=''
nowtime=time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) #иҺ·еҸ–еҪ“еүҚж—¶й—ҙе№¶ж јејҸеҢ–иҫ“еҮә
savecount=nowtime+"\n"+text.get("0.0","end")
with open(file_path+"\save.txt",'w') as fp:
fp.write(savecount)
tkinter.messagebox.showinfo('жҸҗзӨә',"з»“жһңе·Ідҝқеӯҳ")
def history():
if os.path.exists(file_path+"\save.txt"):
with open(file_path+"\save.txt",'r') as fp:
historytxt=fp.read()
tkinter.messagebox.showinfo('еҺҶеҸІ',historytxt)
def helpinf():
tkinter.messagebox.showinfo('её®еҠ©',"""1.иҫ“е…ҘжӮЁиҰҒз»ҹи®Ўзҡ„д»Јз Ғж–Ү件и·Ҝеҫ„
2.иҫ“е…ҘжӮЁиҰҒз»ҹи®Ўзҡ„д»Јз Ғж–Ү件зұ»еһӢ
3.дҝқеӯҳеҠҹиғҪеҸӘиғҪдҝқеӯҳдёҠж¬ЎжҹҘиҜўзҡ„з»“жһң
еҝ«жҚ·й”®пјҡ
F1 жҹҘзңӢеё®еҠ©
ENTE жҸҗдәӨ
Alt-F4 йҖҖеҮә
Control-s дҝқеӯҳ
""")
def aboutinf():
tkinter.messagebox.showinfo('е…ідәҺ',"жӮЁзҺ°еңЁжӯЈеңЁдҪҝз”Ёзҡ„жҳҜжөӢиҜ•зүҲжң¬ by:з”°е·қ")
def out_save_xls(code_dict):
if not text.get("0.0","end").strip(): #иҺ·еҸ–ж–Үжң¬жЎҶеҶ…е®№пјҢд»ҺејҖе§ӢеҲ°з»“жқҹ
tkinter.messagebox.showwarning('жҸҗзӨә',"иҝҳжІЎжңүз»ҹи®Ўж•°жҚ®пјҒ")
return None
out_save.out_to_xls(code_dict)
tkinter.messagebox.showinfo('жҸҗзӨә',"з»“жһңе·ІеҜјеҮә")
menu=Menu(root)
submenu1=Menu(menu,tearoff=0)
menu.add_cascade(label='жҹҘзңӢ',menu=submenu1)
submenu1.add_command(label='еҺҶеҸІ',command=history)
submenu1.add_command(label='дҝқеӯҳ',command=save)
submenu1.add_command(label='еҜјеҮә',command=lambda :out_save_xls(code_dict))
submenu1.add_separator()
submenu1.add_command(label='йҖҖеҮә', command=root.quit)
submenu2=Menu(menu,tearoff=0)
menu.add_cascade(label='её®еҠ©',menu=submenu2)
submenu2.add_command(label='жҹҘзңӢеё®еҠ©',command=helpinf)
submenu2.add_command(label='е…ідәҺ',command=aboutinf)
root.config(menu=menu)
#д»ҘдёҠйғҪжҳҜиҸңеҚ•ж Ҹзҡ„и®ҫзҪ®
root.mainloop() #жү§иЎҢtkcode_count.py
#encoding=utf-8
import os,sys
import file_count
def code_count(path,file_types):
if os.path.exists(path):
os.chdir(path)
else:
#messagebox.showwarning("жӮЁиҫ“е…Ҙзҡ„и·Ҝеҫ„дёҚеӯҳеңЁпјҒ")
print("жӮЁиҫ“е…Ҙзҡ„и·Ҝеҫ„дёҚеӯҳеңЁпјҒ")
#sys.exit()
files_path=[]
file_types=file_types.split()
line_count=0
space_count=0
annotation_count=0
file_lines_dict=dict()
for root,dirs,files in os.walk(path):
for f in files:
files_path.append(os.path.join(root,f))
for file_path in files_path:
#print(os.path.splitext(file_path)[1][1:])
file_type=os.path.splitext(file_path)[1][1:]
if file_type in file_types:
if file_type.lower()=="java":
line_num,space_num,annotation_num=file_count.count_javafile_lines(file_path)
line_count+=line_num
space_count+=space_num
annotation_count+=annotation_num
file_lines_dict[file_path]=line_num,space_num,annotation_num
if file_type.lower()=="py":
line_num,space_num,annotation_num=file_count.count_py_lines(file_path)
line_count+=line_num
space_count+=space_num
annotation_count+=annotation_num
file_lines_dict[file_path]=line_num,space_num,annotation_num
#file_info=file_show(line_num,space_num,annotation_num)
#print(file_info[0])
return line_count,file_lines_dict,space_count,annotation_countfile_count.py
#encoding=utf-8
import os
def count_py_lines(file_path):
line_count = 0
space_count=0
annotation_count=0
flag =True
try:
fp = open(file_path,"r",encoding="utf-8")
encoding_type="utf-8"
for i in fp:
pass
fp.close()
except:
#print(file_path)
encoding_type="gbk"
with open(file_path,"r",encoding=encoding_type,errors="ignore") as fp:
#print(file_path)
"""try:
fp.read()
except:
fp.close()"""
for line in fp:
if line.strip() == "":
space_count+=1
else:
if line.strip().endswith("'''") and flag == False:
annotation_count+=1
#print(line)
flag = True
continue
if line.strip().endswith('"""') and flag == False:
annotation_count+=1
#print('з»“е°ҫеҸҢеј•',line)
flag = True
continue
if flag == False:
annotation_count+=1
#print("z",line)
continue
"""if flag == False:
annotation_count+=1
print("z",line)"""
if line.strip().startswith("#encoding") \
or line.strip().startswith("#-*-"):
line_count += 1
elif line.strip().startswith('"""') and line.strip().endswith('"""') and line.strip() != '"""':
annotation_count+=1
#print(line)
elif line.strip().startswith("'''") and line.strip().endswith("'''") and line.strip() != "'''":
annotation_count+=1
#print(line)
elif line.strip().startswith("#"):
annotation_count+=1
#print(line)
elif line.strip().startswith("'''") and flag == True:
flag = False
annotation_count+=1
#print(line)
elif line.strip().startswith('"""') and flag == True:
flag = False
annotation_count+=1
#print('ејҖеӨҙеҸҢеј•',line)
else:
line_count += 1
return line_count,space_count,annotation_count
#path=input("иҜ·иҫ“е…ҘжӮЁиҰҒз»ҹи®Ўзҡ„з»қеҜ№и·Ҝеҫ„пјҡ")
#file_types=input("иҜ·иҫ“е…ҘжӮЁиҰҒз»ҹи®Ўзҡ„ж–Ү件зұ»еһӢпјҡ")
#print("ж•ҙдёӘ%sжңү%sзұ»еһӢж–Ү件%dдёӘпјҢе…ұжңү%dиЎҢд»Јз Ғ"%(path,file_types,len(code_dict),codes))
#print("д»Јз ҒжңҖеӨҡзҡ„жҳҜ%sпјҢжңү%dиЎҢд»Јз Ғ"%(max_code[1],max_code[0]))
def count_javafile_lines(file_path):
line_count = 0
space_count=0
annotation_count=0
flag =True
#read_type=''
try:
fp = open(file_path,"r",encoding="utf-8")
encoding_type="utf-8"
for i in fp:
pass
fp.close()
except:
#print(file_path)
encoding_type="gbk"
with open(file_path,"r",encoding=encoding_type) as fp:
#print(file_path)
for line in fp:
if line.strip() == "":
space_count+=1
else:
if line.strip().endswith("*/") and flag == False:
flag = True
annotation_count+=1
continue
if flag == False:
annotation_count+=1
continue
elif line.strip().startswith('/*') and line.strip().endswith('*/'):
annotation_count+=1
elif line.strip().startswith('/**') and line.strip().endswith('*/'):
annotation_count+=1
elif line.strip().startswith("//") and flag == True:
flag = False
continue
else:
line_count += 1
return line_count,space_count,annotation_countout_save.py
#encoding=utf-8
import os,time
from openpyxl import Workbook
from openpyxl import load_workbook
def out_to_xls(file_dict):
nowtime=time.strftime("%Y-%m-%d %H-%M-%S", time.localtime()) #иҺ·еҸ–еҪ“еүҚж—¶й—ҙе№¶ж јејҸеҢ–иҫ“еҮә
file_path=os.path.dirname(__file__)
if os.path.exists(file_path+'\out_save.xlsx'):
#print("y")
wb=load_workbook(file_path+'\out_save.xlsx')
ws=wb.create_sheet(nowtime)
ws['A1']='ж–Ү件еҗҚ' #еўһеҠ иЎЁеӨҙ
ws['B1']='жңүж•Ҳд»Јз Ғ'
ws['C1']='з©әзҷҪиЎҢж•°'
ws['D1']='жіЁйҮҠиЎҢж•°'
for file_name,file_data in file_dict.items(): #еҫӘзҺҜеҫ—еҲ°зҡ„ж–Ү件еӯ—е…ё
ws.append([file_name]+list(file_data)) #еӣ дёәе·ҘдҪңиЎЁзҡ„appendж–№жі•еҸӘиғҪж·»еҠ дёҖдёӘlistпјҢжүҖд»ҘжҠҠж–Ү件еҗҚе’Ңж–Ү件з»ҹи®Ўж•°жҚ®ж”ҫеңЁдёҖдёӘlistйҮҢ
wb.save(file_path+'\out_save.xlsx') #жҠҠеҜјеҮәзҡ„еҶ…е®№дҝқеӯҳеҲ°ж–Ү件зӣ®еҪ•дёӢ
else:
#print("no")
wb=Workbook() #еҲӣе»әдёҖдёӘе·ҘдҪңз°ҝ
ws=wb.create_sheet(nowtime,index=0) #ж–°е»әеҗҚз§°дёәеҪ“еүҚж—¶й—ҙзҡ„sheetжҸ’еңЁејҖеӨҙпјҢж–№дҫҝеҒҡз»ҹи®ЎеҸҠи®°еҪ•
ws['A1']='ж–Ү件еҗҚ' #еўһеҠ иЎЁеӨҙ
ws['B1']='жңүж•Ҳд»Јз Ғ'
ws['C1']='з©әзҷҪиЎҢж•°'
ws['D1']='жіЁйҮҠиЎҢж•°'
for file_name,file_data in file_dict.items(): #еҫӘзҺҜеҫ—еҲ°зҡ„ж–Ү件еӯ—е…ё
ws.append([file_name]+list(file_data)) #еӣ дёәе·ҘдҪңиЎЁзҡ„appendж–№жі•еҸӘиғҪж·»еҠ дёҖдёӘlistпјҢжүҖд»ҘжҠҠж–Ү件еҗҚе’Ңж–Ү件з»ҹи®Ўж•°жҚ®ж”ҫеңЁдёҖдёӘlistйҮҢ
wb.remove(wb.get_sheet_by_name("Sheet"))
wb.save(file_path+'\out_save.xlsx') #жҠҠеҜјеҮәзҡ„еҶ…е®№дҝқеӯҳеҲ°ж–Ү件зӣ®еҪ•дёӢжң¬ж¬Ўжӣҙж–°пјҡ
1.дҝ®ж”№еҜјеҮәеҠҹиғҪ
2.жӣҙж–°дәҶеҪ“дёҚиҫ“е…Ҙи·Ҝеҫ„е’Ңзұ»еһӢж—¶зӮ№еҮ»жҸҗдәӨжҢүй’®зӣҙжҺҘйҖҖеҮәзҡ„й—®йўҳ
жӣҙж–°д»Јз Ғдёәпјҡ
1.out_to_xlsж–№жі•
#encoding=utf-8
import os,time
from openpyxl import Workbook
from openpyxl import load_workbook
def out_to_xls(file_dict):
nowtime=time.strftime("%Y-%m-%d %H-%M-%S", time.localtime()) #иҺ·еҸ–еҪ“еүҚж—¶й—ҙе№¶ж јејҸеҢ–иҫ“еҮә
file_path=os.path.dirname(__file__)
if os.path.exists(file_path+'\out_save.xlsx'):
#print("y")
wb=load_workbook(file_path+'\out_save.xlsx')
ws=wb.create_sheet(nowtime)
ws['A1']='ж–Ү件еҗҚ' #еўһеҠ иЎЁеӨҙ
ws['B1']='жңүж•Ҳд»Јз Ғ'
ws['C1']='з©әзҷҪиЎҢж•°'
ws['D1']='жіЁйҮҠиЎҢж•°'
for file_name,file_data in file_dict.items(): #еҫӘзҺҜеҫ—еҲ°зҡ„ж–Ү件еӯ—е…ё
ws.append([file_name]+list(file_data)) #еӣ дёәе·ҘдҪңиЎЁзҡ„appendж–№жі•еҸӘиғҪж·»еҠ дёҖдёӘlistпјҢжүҖд»ҘжҠҠж–Ү件еҗҚе’Ңж–Ү件з»ҹи®Ўж•°жҚ®ж”ҫеңЁдёҖдёӘlistйҮҢ
wb.save(file_path+'\out_save.xlsx') #жҠҠеҜјеҮәзҡ„еҶ…е®№дҝқеӯҳеҲ°ж–Ү件зӣ®еҪ•дёӢ
else:
#print("no")
wb=Workbook() #еҲӣе»әдёҖдёӘе·ҘдҪңз°ҝ
ws=wb.create_sheet(nowtime,index=0) #ж–°е»әеҗҚз§°дёәеҪ“еүҚж—¶й—ҙзҡ„sheetжҸ’еңЁејҖеӨҙпјҢж–№дҫҝеҒҡз»ҹи®ЎеҸҠи®°еҪ•
ws['A1']='ж–Ү件еҗҚ' #еўһеҠ иЎЁеӨҙ
ws['B1']='жңүж•Ҳд»Јз Ғ'
ws['C1']='з©әзҷҪиЎҢж•°'
ws['D1']='жіЁйҮҠиЎҢж•°'
for file_name,file_data in file_dict.items(): #еҫӘзҺҜеҫ—еҲ°зҡ„ж–Ү件еӯ—е…ё
ws.append([file_name]+list(file_data)) #еӣ дёәе·ҘдҪңиЎЁзҡ„appendж–№жі•еҸӘиғҪж·»еҠ дёҖдёӘlistпјҢжүҖд»ҘжҠҠж–Ү件еҗҚе’Ңж–Ү件з»ҹи®Ўж•°жҚ®ж”ҫеңЁдёҖдёӘlistйҮҢ
wb.remove(wb.get_sheet_by_name("Sheet"))
wb.save(file_path+'\out_save.xlsx') #жҠҠеҜјеҮәзҡ„еҶ…е®№дҝқеӯҳеҲ°ж–Ү件зӣ®еҪ•дёӢ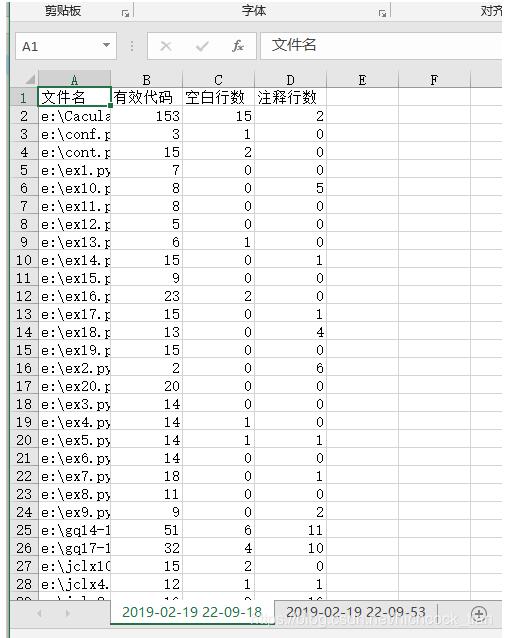
д»ҘдёҠжҳҜвҖңpythonдёӯеҰӮдҪ•е®һзҺ°tkinterеӣҫеҪўз•Ңйқўд»Јз Ғз»ҹи®Ўе·Ҙе…·вҖқиҝҷзҜҮж–Үз« зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒеёҢжңӣеҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүеё®еҠ©пјҢжӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ