您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章将为大家详细讲解有关python中怎么实现文字识别功能,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
Ubuntu版本:
1.tesseract-ocr安装
sudo apt-get install tesseract-ocr
2.pytesseract安装
sudo pip install pytesseract
3.Pillow 安装
sudo pip install pillow
开始写代码:
from PIL import Image
from pytesseract import pytesseract
image = Image.open('test.png')
code = pytesseract.image_to_string(image,lang='chi_sim')
print(code)报错了:

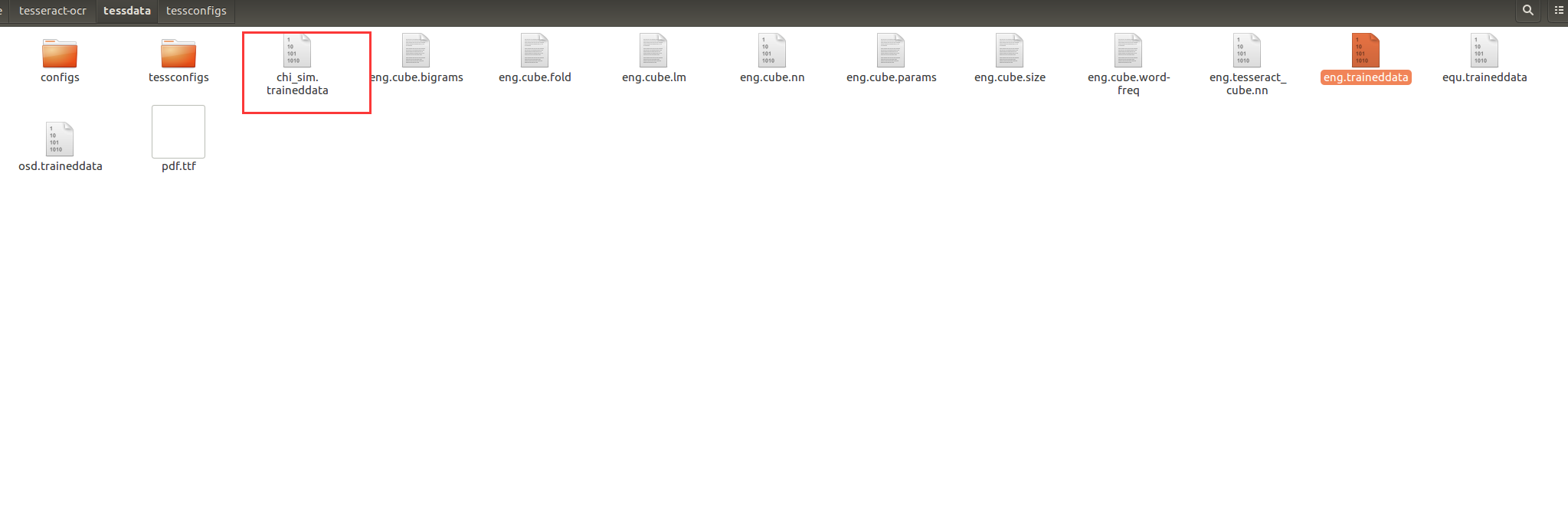
找到路径,发现没有chi_sim.traineddata这个训练包
# 安装训练数据(equ为数学公式包) sudo apt-get install tesseract-ocr-eng tesseract-ocr-chi-sim tesseract-ocr-equ
安装之后就会有训练包了,可以正常运行。
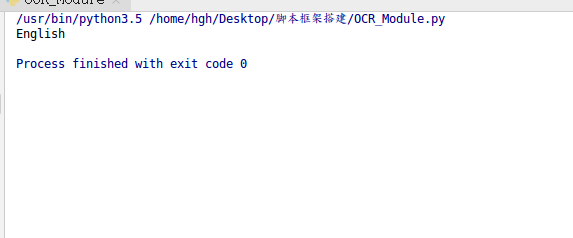
英文识别正确率较高,中文就比较鸡肋了。
关于python中怎么实现文字识别功能就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。