您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章将为大家详细讲解有关pytorch中网络loss传播和参数更新的示例分析,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
相比于2018年,在ICLR2019提交论文中,提及不同框架的论文数量发生了极大变化,网友发现,提及tensorflow的论文数量从2018年的228篇略微提升到了266篇,keras从42提升到56,但是pytorch的数量从87篇提升到了252篇。
TensorFlow: 228--->266
Keras: 42--->56
Pytorch: 87--->252
在使用pytorch中,自己有一些思考,如下:
1. loss计算和反向传播
import torch.nn as nn criterion = nn.MSELoss().cuda() output = model(input) loss = criterion(output, target) loss.backward()
通过定义损失函数:criterion,然后通过计算网络真实输出和真实标签之间的误差,得到网络的损失值:loss;
最后通过loss.backward()完成误差的反向传播,通过pytorch的内在机制完成自动求导得到每个参数的梯度。
需要注意,在机器学习或者深度学习中,我们需要通过修改参数使得损失函数最小化或最大化,一般是通过梯度进行网络模型的参数更新,通过loss的计算和误差反向传播,我们得到网络中,每个参数的梯度值,后面我们再通过优化算法进行网络参数优化更新。
2. 网络参数更新
在更新网络参数时,我们需要选择一种调整模型参数更新的策略,即优化算法。
优化算法中,简单的有一阶优化算法:
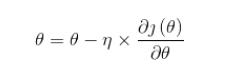
其中 就是通常说的学习率,
就是通常说的学习率,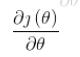 是函数的梯度;
是函数的梯度;
自己的理解是,对于复杂的优化算法,基本原理也是这样的,不过计算更加复杂。
在pytorch中,torch.optim是一个实现各种优化算法的包,可以直接通过这个包进行调用。
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
注意:
1)在前面部分1中,已经通过loss的反向传播得到了每个参数的梯度,然后再本部分通过定义优化器(优化算法),确定了网络更新的方式,在上述代码中,我们将模型的需要更新的参数传入优化器。
2)注意优化器,即optimizer中,传入的模型更新的参数,对于网络中有多个模型的网络,我们可以选择需要更新的网络参数进行输入即可,上述代码,只会更新model中的模型参数。对于需要更新多个模型的参数的情况,可以参考以下代码:
optimizer = torch.optim.Adam([{'params': model.parameters()}, {'params': gru.parameters()}], lr=0.01) 3) 在优化前需要先将梯度归零,即optimizer.zeros()。
3. loss计算和参数更新
import torch.nn as nn import torch criterion = nn.MSELoss().cuda() optimizer = torch.optim.Adam(model.parameters(), lr=0.01) output = model(input) loss = criterion(output, target) optimizer.zero_grad() # 将所有参数的梯度都置零 loss.backward() # 误差反向传播计算参数梯度 optimizer.step() # 通过梯度做一步参数更新
关于“pytorch中网络loss传播和参数更新的示例分析”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,使各位可以学到更多知识,如果觉得文章不错,请把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。