жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« е°ҶдёәеӨ§е®¶иҜҰз»Ҷи®Іи§Јжңүе…іPythonдёӯPyAudioеҰӮдҪ•е®һзҺ°еҪ•йҹіиҮӘеҠЁеҢ–дәӨдә’е®һзҺ°й—®зӯ”пјҢе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еҒҡдёӘеҸӮиҖғпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
йҰ–е…ҲиҰҒе…Ҳ pip дёҖдёӘ PyAudio
pip install pyaudio
дёҖ.PyAudio е®һзҺ°йәҰе…ӢйЈҺеҪ•йҹі
然еҗҺе»әз«ӢдёҖдёӘpyж–Ү件,еӨҚеҲ¶еҰӮдёӢд»Јз Ғ
import pyaudio
import wave
CHUNK = 1024
FORMAT = pyaudio.paInt16
CHANNELS = 2
RATE = 16000
RECORD_SECONDS = 2
WAVE_OUTPUT_FILENAME = "Oldboy.wav"
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
print("ејҖе§ӢеҪ•йҹі,иҜ·иҜҙиҜқ......")
frames = []
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
frames.append(data)
print("еҪ•йҹіз»“жқҹ,иҜ·й—ӯеҳҙ!")
stream.stop_stream()
stream.close()
p.terminate()
wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
wf.close()е°қиҜ•дёҖдёӢ,еңЁзӣ®еҪ•дёӯеҮәзҺ°дәҶдёҖдёӘ Oldboy.wav ж–Ү件 , еҗ¬дёҖеҗ¬,иҝҳжҳҜеҫҲжё…жҷ°зҡ„еҳӣ
жҺҘдёӢжқҘ,жҲ‘们е°Ҷиҝҷж®өеҪ•йҹід»Јз Ғ,еҶҷеңЁдёҖдёӘеҮҪж•°йҮҢйқў,еҰӮжһңиҰҒеҪ•йҹізҡ„иҜқе°ұи°ғз”Ё
е»әз«ӢдёҖдёӘж–Ү件 pyrec.py 并е°ҶеҪ•йҹід»Јз Ғе’ҢеҮҪж•°еҶҷеңЁеҶ…
# pyrec.py ж–Ү件еҶ…е®№
import pyaudio
import wave
CHUNK = 1024
FORMAT = pyaudio.paInt16
CHANNELS = 2
RATE = 16000
RECORD_SECONDS = 2
def rec(file_name):
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
print("ејҖе§ӢеҪ•йҹі,иҜ·иҜҙиҜқ......")
frames = []
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
frames.append(data)
print("еҪ•йҹіз»“жқҹ,иҜ·й—ӯеҳҙ!")
stream.stop_stream()
stream.close()
p.terminate()
wf = wave.open(file_name, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
wf.close()rec еҮҪж•°е°ұжҳҜжҲ‘们и°ғз”Ёзҡ„еҪ•йҹіеҮҪж•°,并且з»ҷд»–дёҖдёӘж–Ү件еҗҚ,д»–е°ұдјҡиҮӘеҠЁе°ҶеЈ°йҹіеҶҷе…ҘеҲ°ж–Ү件дёӯдәҶ
дәҢ.е®һзҺ°йҹійў‘ж јејҸиҮӘеҠЁиҪ¬жҚў 并 и°ғз”ЁиҜӯйҹіиҜҶеҲ«
еҪ•йҹізҡ„й—®йўҳи§ЈеҶідәҶ,иө¶еҝ«е’ҢзҷҫеәҰиҜӯйҹіиҜҶеҲ«жҺҘеңЁдёҖиө·дҪҝз”ЁдёҖдёӢ:
дёҚз®ЎдҪ зҡ„еҪ•йҹіжңүеӨҡд№ҲеӨҡд№Ҳжё…жҷ°,дҪ еҸ‘зҺ°зҷҫеәҰз»ҷдҪ иҝ”еӣһзҡ„ж°ёиҝңжҳҜ:
{'err_msg': 'speech quality error.', 'err_no': 3301, 'sn': '6397933501529645284'} # йҹіиҙЁдёҚжё…жҷ°е…¶е®һдёҚжҳҜжІЎеҗ¬жё…,иҖҢжҳҜзҷҫеәҰж”ҜжҢҒзҡ„йҹійў‘ж јејҸPCMжҗһзҡ„й¬ј
жүҖд»Ҙ,жҲ‘们иҰҒе°ҶеҪ•еҲ¶зҡ„wavйҹійў‘ж–Ү件иҪ¬жҚўдёәpcmж–Ү件
еҶҷдёҖдёӘж–Ү件 wav2pcm.py иҝҷдёӘж–Ү件йҮҢйқўзҡ„еҮҪж•°жҳҜдё“й—ЁдёәжҲ‘们иҪ¬жҚўwavж–Ү件зҡ„
дҪҝз”Ё os жЁЎеқ—дёӯзҡ„ os.system()ж–№жі• иҝҷдёӘж–№жі•жҳҜжү§иЎҢзі»з»ҹе‘Ҫд»Өз”Ёзҡ„, еңЁwindowsзі»з»ҹдёӯзҡ„е‘Ҫд»Өе°ұжҳҜ cmd йҮҢйқўеҶҷзҡ„дёңиҘҝ,dir , cd иҝҷзұ»зҡ„е‘Ҫд»Ө
# wav2pcm.py ж–Ү件еҶ…е®№
import os
def wav_to_pcm(wav_file):
# еҒҮи®ҫ wav_file = "йҹійў‘ж–Ү件.wav"
# wav_file.split(".") еҫ—еҲ°["йҹійў‘ж–Ү件","wav"] жӢҝеҮә第дёҖдёӘз»“жһң"йҹійў‘ж–Ү件" дёҺ ".pcm" жӢјжҺҘ зӯүеҲ°з»“жһң "йҹійў‘ж–Ү件.pcm"
pcm_file = "%s.pcm" %(wav_file.split(".")[0])
# е°ұжҳҜжӯӨеүҚжҲ‘们еңЁcmdзӘ—еҸЈдёӯиҫ“е…Ҙе‘Ҫд»Ө,иҝҷйҮҢйқўе°ұжҳҜеңЁи®©Pythonеё®жҲ‘们еңЁcmdдёӯжү§иЎҢе‘Ҫд»Ө
os.system("ffmpeg -y -i %s -acodec pcm_s16le -f s16le -ac 1 -ar 16000 %s"%(wav_file,pcm_file))
return pcm_fileиҝҷж ·жҲ‘们е°ұжңүдәҶжҠҠwavиҪ¬дёәpcmзҡ„еҮҪж•°дәҶ , еҶҚйҮҚж–°жһ„е»әдёҖж¬Ўе’ұ们зҡ„д»Јз Ғ

иҝҷж¬Ўзҡ„иҝ”еӣһз»“жһңиҝҳжҢәи®©дәәж»Ўж„Ҹзҡ„еҳӣ
{'corpus_no': '6569869134617218414', 'err_msg': 'success.', 'err_no': 0, 'result': ['иҖҒз”·еӯ©ж•ҷиӮІ'], 'sn': '8116162981529666859'}жӢҝеҲ°иҜӯйҹіиҜҶеҲ«зҡ„еӯ—з¬ҰдёІдәҶ,жҺҘдёӢжқҘз”Ёиҝҷж®өеӯ—з¬ҰдёІ иҜӯйҹіеҗҲжҲҗ, еӯҰд№ е’ұ们иҜҙеҮәжқҘзҡ„иҜқ
дёү.иҜӯйҹіеҗҲжҲҗ дёҺ FFmpeg ж’ӯж”ҫmp3 ж–Ү件
жӢҝеҲ°еӯ—з¬ҰдёІдәҶ,зӣҙжҺҘи°ғз”Ёsynthesisж–№жі•еҺ»еҗҲжҲҗеҗ§

иҝҷж®өд»Јз ҒиЎ”жҺҘдёҠдёҖж®өд»Јз Ғ,жҲҗеҠҹиҺ·еҫ—дәҶ synth.mp3 йҹійў‘ж–Ү件,并且确е®ҡдәҶе®һеңЁеӯҰд№ жҲ‘们иҜҙзҡ„иҜқ
жҺҘдёӢжқҘе°ұжҳҜи®©жҲ‘们зҡ„зЁӢеәҸиҮӘеҠЁе°Ҷ synth.mp3 йҹійў‘ж–Ү件ж’ӯж”ҫдәҶ е…¶е®һPyAudio жңүж’ӯж”ҫзҡ„еҠҹиғҪ,дҪҶжҳҜж“ҚдҪңжңүзӮ№еӨҚжқӮ
жүҖд»ҘжҲ‘们иҝҳжҳҜйҖүжӢ©з”Ёз®ҖеҚ•зҡ„ж–№ејҸи§ЈеҶіеӨҚжқӮзҡ„й—®йўҳ,е°ұжҳҜиҝҷд№Ҳз®ҖеҚ•зІ—жҡҙ,жҳҜеҗҰиҝҳи®°еҫ—FFmpeg е‘ў?
FFmpeg иҝҷдёӘзі»з»ҹе·Ҙе…·дёӯ,жңүдёҖдёӘ ffplay зҡ„е·Ҙе…·з”ЁжқҘжү“ејҖ并ж’ӯж”ҫйҹійў‘ж–Ү件зҡ„,дҪҝз”Ёж–№жі•еӨ§жҰӮжҳҜ: ffplay йҹійў‘ж–Ү件.mp3
е»әз«ӢдёҖдёӘplaymp3.pyж–Ү件, еҶҷдёҖдёӘ play_mp3 зҡ„еҮҪж•°з”ЁжқҘж’ӯж”ҫе·Із»ҸеҗҲжҲҗзҡ„иҜӯйҹі
# playmp3.py ж–Ү件еҶ…е®№
import os
def play_mp3(file_name):
os.system("ffplay %s"%(file_name))еӣһеҲ°дё»ж–Ү件,и°ғз”Ёplaymp3.pyж–Ү件дёӯзҡ„ play_mp3 еҮҪж•°

жү§иЎҢд»Јз Ғ,еҪ“дҪ зңӢеҲ° : ејҖе§ӢеҪ•йҹі,иҜ·иҜҙиҜқ......
иҜ·еӨ§еЈ°зҡ„иҜҙеҮә: еӯҰIT жүҫиҖҒз”·еӯ©ж•ҷиӮІ
然еҗҺдҪ е°ұдјҡеҗ¬еҲ°,дёҖдёӘеЁҮж»ҙж»ҙеЈ°йҹійҮҚеӨҚдҪ иҜҙзҡ„иҜқ
еӣӣ.з®ҖеҚ•й—®зӯ”
йҰ–е…ҲжҲ‘们иҰҒжҠҠд»Јз ҒйҮҚж–°жўізҗҶдёҖдёӢ:
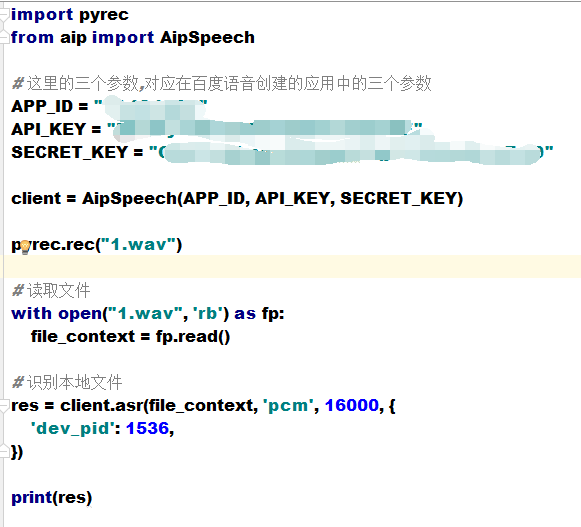
жҠҠиҜӯйҹіеҗҲжҲҗ иҜӯйҹіиҜҶеҲ«йғЁеҲҶзҡ„д»Јз ҒзӢ¬з«ӢжҲҗеҮҪж•°ж”ҫеҲ°baidu_ai.pyж–Ү件дёӯ
# baidu_ai.py ж–Ү件еҶ…е®№
from aip import AipSpeech
# иҝҷйҮҢзҡ„дёүдёӘеҸӮж•°,еҜ№еә”еңЁзҷҫеәҰиҜӯйҹіеҲӣе»әзҡ„еә”з”Ёдёӯзҡ„дёүдёӘеҸӮж•°
APP_ID = "xxxxx"
API_KEY = "xxxxxxx"
SECRET_KEY = "xxxxxxxx"
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
def audio_to_text(pcm_file):
# иҜ»еҸ–ж–Ү件 , з»ҲдәҺеҫ—еҲ°дәҶPCMж–Ү件
with open(pcm_file, 'rb') as fp:
file_context = fp.read()
# иҜҶеҲ«жң¬ең°ж–Ү件
res = client.asr(file_context, 'pcm', 16000, {
'dev_pid': 1536,
})
# д»Һеӯ—е…ёйҮҢйқўиҺ·еҸ–"result"зҡ„value еҲ—иЎЁдёӯ第1дёӘе…ғзҙ ,е°ұжҳҜиҜҶеҲ«еҮәжқҘзҡ„еӯ—з¬ҰдёІ"иҖҒз”·еӯ©ж•ҷиӮІ"
res_str = res.get("result")[0]
return res_str
def text_to_audio(res_str):
synth_file = "synth.mp3"
synth_context = client.synthesis(res_str, "zh", 1, {
"vol": 5,
"spd": 4,
"pit": 9,
"per": 4
})
with open(synth_file, "wb") as f:
f.write(synth_context)
return synth_file然еҗҺжҠҠжҲ‘们зҡ„дё»ж–Ү件иҝӣиЎҢдёҖдёӢдҝ®ж”№
import pyrec # еҪ•йҹіеҮҪж•°ж–Ү件
import wav2pcm # wavиҪ¬жҚўpcm еҮҪж•°ж–Ү件
import baidu_ai # иҜӯйҹіеҗҲжҲҗеҮҪж•°,иҜӯйҹіиҜҶеҲ«еҮҪж•° ж–Ү件
import playmp3 # ж’ӯж”ҫmp3 еҮҪж•° ж–Ү件
pyrec.rec("1.wav") # еҪ•йҹіе№¶з”ҹжҲҗwavж–Ү件,дҪҝз”Ёж–№ејҸдј е…Ҙж–Ү件еҗҚ
pcm_file = wav2pcm.wav_to_pcm("1.wav") # е°Ҷwavж–Ү件 иҪ¬жҚўжҲҗpcmж–Ү件 иҝ”еӣһ pcmзҡ„ж–Ү件еҗҚ
res_str = baidu_ai.audio_to_text(pcm_file) # е°ҶиҪ¬жҚўеҗҺзҡ„pcmйҹійў‘ж–Ү件иҜҶеҲ«жҲҗ ж–Үеӯ— res_str
synth_file = baidu_ai.text_to_audio(res_str) # е°Ҷres_str еӯ—з¬ҰдёІ еҗҲжҲҗиҜӯйҹі иҝ”еӣһж–Ү件еҗҚ synth_file
playmp3.play_mp3(synth_file) # ж’ӯж”ҫ synth_file然еҗҺе°ұжҳҜеӨ§еұ•е®Ҹеӣҫзҡ„ж—¶еҖҷдәҶ,еұ•ејҖдҪ 们зҡ„жғіиұЎеҠӣ:
res_str жҳҜеӯ—з¬ҰдёІ,еҰӮжһңеӯ—з¬ҰдёІзӯүдәҺ"дҪ еҸ«д»Җд№ҲеҗҚеӯ—"зҡ„ж—¶еҖҷ,жҲ‘们е°ұиҰҒз»ҷд»–дёҖдёӘеӣһзӯ”:жҲ‘зҡ„еҗҚеӯ—еҸ«иҖҒз”·еӯ©ж•ҷиӮІ
ж–°е»әдёҖдёӘFAQ.pyзҡ„ж–Ү件然еҗҺе»әз«ӢдёҖдёӘеҮҪж•°faq:
# FAQ.py ж–Ү件еҶ…е®№ def faq(Q): if Q == "дҪ еҸ«д»Җд№ҲеҗҚеӯ—": # й—®йўҳ return "жҲ‘зҡ„еҗҚеӯ—жҳҜиҖҒз”·еӯ©ж•ҷиӮІ" # зӯ”жЎҲ гҖҖгҖҖreturn "жҲ‘дёҚзҹҘйҒ“дҪ еңЁиҜҙд»Җд№Ҳ" #й—®йўҳжІЎжңүзӯ”жЎҲж—¶иҝ”
еңЁдё»ж–Ү件дёӯеҜје…ҘиҝҷдёӘеҮҪж•°,并е°ҶиҜӯйҹіиҜҶеҲ«еҗҺзҡ„еӯ—з¬ҰдёІдј е…ҘеҮҪж•°дёӯ

зҺ°еңЁжқҘе°қиҜ•дёҖдёӢ:"дҪ еҸ«д»Җд№ҲеҗҚеӯ—","дҪ д»Ҡе№ҙеҮ еІҒдәҶ"
жҲҗеҠҹдәҶ,зҺ°еңЁдҪ еҸҜд»ҘеҜ№ FAQ.py иҝҷдёӘж–Ү件иҝӣиЎҢжӣҙеӨҡзҡ„й—®йўҳеҢ№й…ҚдәҶ
иҝҳжҳҜйӮЈеҸҘиҜқ,еҲ«зҺ©е„ҝеқҸдәҶ
жҖқиҖғйўҳ:
1.еҰӮдҪ•е®һзҺ°дёҖзӣҙй—®зӯ”дёҚз”Ёй—®дёҖж¬ЎеҒңдёҖж¬Ў?
2.й—®йўҳйӮЈд№ҲеӨҡ,жҳҜдёҚжҳҜиҰҒеҶҷиҝҷд№ҲеӨҡй—®йўҳе‘ў?
3.еҰӮжһңжҲ‘й—®дҪ жҳҜи°Ғ,жҳҜдёҚжҳҜиҰҒйҮҚеӨҚд№ҹдёҖж¬Ў жҲ‘зҡ„еҗҚеӯ—еҸ«иҖҒз”·еӯ©ж•ҷиӮІ зҡ„зӯ”жЎҲе‘ў?
Pythonдё»иҰҒеә”з”ЁдәҺпјҡ1гҖҒWebејҖеҸ‘пјӣ2гҖҒж•°жҚ®з§‘еӯҰз ”з©¶пјӣ3гҖҒзҪ‘з»ңзҲ¬иҷ«пјӣ4гҖҒеөҢе…ҘејҸеә”з”ЁејҖеҸ‘пјӣ5гҖҒжёёжҲҸејҖеҸ‘пјӣ6гҖҒжЎҢйқўеә”з”ЁејҖеҸ‘гҖӮ
е…ідәҺвҖңPythonдёӯPyAudioеҰӮдҪ•е®һзҺ°еҪ•йҹіиҮӘеҠЁеҢ–дәӨдә’е®һзҺ°й—®зӯ”вҖқиҝҷзҜҮж–Үз« е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢдҪҝеҗ„дҪҚеҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶпјҢеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢиҜ·жҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ