жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жҰӮиҝ°
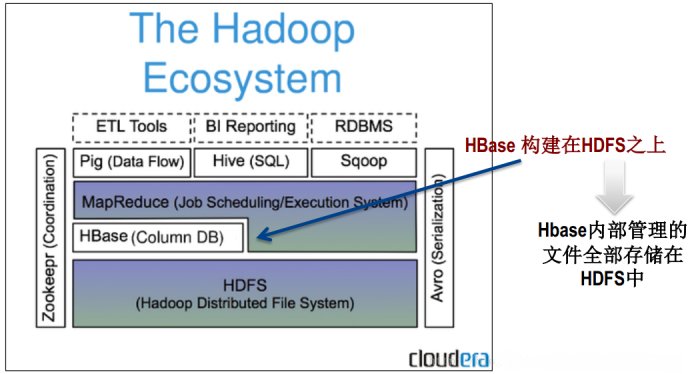
HBaseжҳҜдёҖдёӘжһ„е»әеңЁHDFSдёҠзҡ„еҲҶеёғејҸеҲ—еӯҳеӮЁзі»з»ҹпјӣ
HBaseжҳҜеҹәдәҺGoogleBigTableжЁЎеһӢејҖеҸ‘зҡ„пјҢе…ёеһӢзҡ„key/valueзі»з»ҹпјӣ
HBaseжҳҜApacheHadoopз”ҹжҖҒзі»з»ҹдёӯзҡ„йҮҚиҰҒдёҖе‘ҳпјҢдё»иҰҒз”ЁдәҺжө·йҮҸз»“жһ„еҢ–ж•°жҚ®еӯҳеӮЁпјӣ
д»ҺйҖ»иҫ‘дёҠи®ІпјҢHBaseе°Ҷж•°жҚ®жҢүз…§иЎЁгҖҒиЎҢе’ҢеҲ—иҝӣиЎҢеӯҳеӮЁгҖӮ
дёҺhadoopдёҖж ·пјҢHbaseзӣ®ж Үдё»иҰҒдҫқйқ жЁӘеҗ‘жү©еұ•пјҢйҖҡиҝҮдёҚж–ӯеўһеҠ е»үд»·зҡ„е•Ҷз”ЁжңҚеҠЎеҷЁпјҢжқҘеўһеҠ и®Ўз®—е’ҢеӯҳеӮЁиғҪеҠӣгҖӮ
HbaseиЎЁзҡ„зү№зӮ№
еӨ§пјҡдёҖдёӘиЎЁеҸҜд»Ҙжңүж•°еҚҒдәҝиЎҢпјҢдёҠзҷҫдёҮеҲ—пјӣ
ж— жЁЎејҸпјҡжҜҸиЎҢйғҪжңүдёҖдёӘеҸҜжҺ’еәҸзҡ„дё»й”®е’Ңд»»ж„ҸеӨҡзҡ„еҲ—пјҢеҲ—еҸҜд»Ҙж №жҚ®йңҖиҰҒеҠЁжҖҒзҡ„еўһеҠ пјҢеҗҢдёҖеј иЎЁдёӯдёҚеҗҢзҡ„иЎҢеҸҜд»ҘжңүжҲӘ然дёҚеҗҢзҡ„еҲ—пјӣ
йқўеҗ‘еҲ—пјҡйқўеҗ‘еҲ—пјҲж—Ҹпјүзҡ„еӯҳеӮЁе’ҢжқғйҷҗжҺ§еҲ¶пјҢеҲ—пјҲж—ҸпјүзӢ¬з«ӢжЈҖзҙўпјӣ
зЁҖз–Ҹпјҡз©әпјҲnullпјүеҲ—并дёҚеҚ з”ЁеӯҳеӮЁз©әй—ҙпјҢиЎЁеҸҜд»Ҙи®ҫи®Ўзҡ„йқһеёёзЁҖз–Ҹпјӣ
ж•°жҚ®еӨҡзүҲжң¬пјҡжҜҸдёӘеҚ•е…ғдёӯзҡ„ж•°жҚ®еҸҜд»ҘжңүеӨҡдёӘзүҲжң¬пјҢй»ҳи®Өжғ…еҶөдёӢзүҲжң¬еҸ·иҮӘеҠЁеҲҶй…ҚпјҢжҳҜеҚ•е…ғж јжҸ’е…Ҙж—¶зҡ„ж—¶й—ҙжҲіпјӣ
ж•°жҚ®зұ»еһӢеҚ•дёҖпјҡHbaseдёӯзҡ„ж•°жҚ®йғҪжҳҜеӯ—з¬ҰдёІпјҢжІЎжңүзұ»еһӢгҖӮ
В·Hbaseж•°жҚ®жЁЎеһӢ
HbaseйҖ»иҫ‘и§Ҷеӣҫ
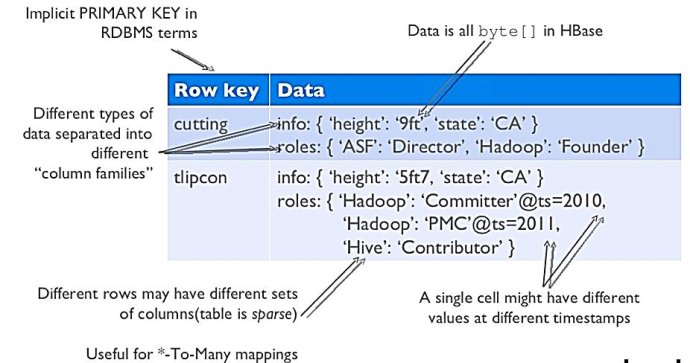
жіЁж„ҸдёҠеӣҫдёӯзҡ„иӢұж–ҮиҜҙжҳҺ
Hbaseеҹәжң¬жҰӮеҝө
RowKeyпјҡжҳҜBytearrayпјҢжҳҜиЎЁдёӯжҜҸжқЎи®°еҪ•зҡ„вҖңдё»й”®вҖқпјҢж–№дҫҝеҝ«йҖҹжҹҘжүҫпјҢRowkeyзҡ„и®ҫи®ЎйқһеёёйҮҚиҰҒгҖӮ
ColumnFamilyпјҡеҲ—ж—ҸпјҢжӢҘжңүдёҖдёӘеҗҚз§°(string)пјҢеҢ…еҗ«дёҖдёӘжҲ–иҖ…еӨҡдёӘзӣёе…іеҲ—
ColumnпјҡеұһдәҺжҹҗдёҖдёӘcolumnfamilyпјҢfamilyName:columnNameпјҢжҜҸжқЎи®°еҪ•еҸҜеҠЁжҖҒж·»еҠ
VersionNumberпјҡзұ»еһӢдёәLongпјҢй»ҳи®ӨеҖјжҳҜзі»з»ҹж—¶й—ҙжҲіпјҢеҸҜз”ұз”ЁжҲ·иҮӘе®ҡд№ү
Value(Cell)пјҡBytearray
В·Hbaseзү©зҗҶжЁЎеһӢ
жҜҸдёӘcolumnfamilyеӯҳеӮЁеңЁHDFSдёҠзҡ„дёҖдёӘеҚ•зӢ¬ж–Ү件дёӯпјҢз©әеҖјдёҚдјҡиў«дҝқеӯҳгҖӮ
Keyе’Ң Version numberеңЁжҜҸдёӘ column familyдёӯеқҮжңүдёҖд»Ҫпјӣ
HBaseдёәжҜҸдёӘеҖјз»ҙжҠӨдәҶеӨҡзә§зҙўеј•пјҢеҚіпјҡ
зү©зҗҶеӯҳеӮЁ:
1гҖҒTableдёӯжүҖжңүиЎҢйғҪжҢүз…§rowkeyзҡ„еӯ—е…ёеәҸжҺ’еҲ—пјӣ
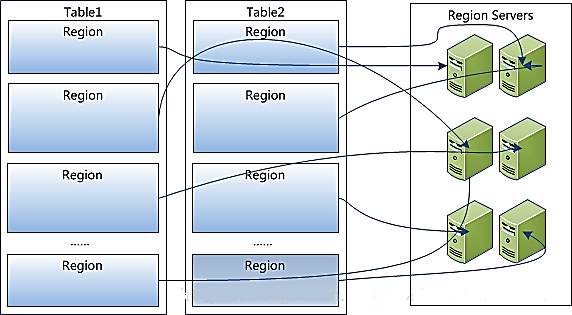
2гҖҒTableеңЁиЎҢзҡ„ж–№еҗ‘дёҠеҲҶеүІдёәеӨҡдёӘRegionпјӣ
3гҖҒRegionжҢүеӨ§е°ҸеҲҶеүІзҡ„пјҢжҜҸдёӘиЎЁејҖе§ӢеҸӘжңүдёҖдёӘregionпјҢйҡҸзқҖж•°жҚ®еўһеӨҡпјҢregionдёҚж–ӯеўһеӨ§пјҢеҪ“еўһеӨ§еҲ°дёҖдёӘйҳҖеҖјзҡ„ж—¶еҖҷпјҢregionе°ұдјҡзӯүеҲҶдјҡдёӨдёӘж–°зҡ„regionпјҢд№ӢеҗҺдјҡжңүи¶ҠжқҘи¶ҠеӨҡзҡ„regionпјӣ
4гҖҒRegionжҳҜHbaseдёӯеҲҶеёғејҸеӯҳеӮЁе’ҢиҙҹиҪҪеқҮиЎЎзҡ„жңҖе°ҸеҚ•е…ғпјҢдёҚеҗҢRegionеҲҶеёғеҲ°дёҚеҗҢRegionServerдёҠгҖӮ
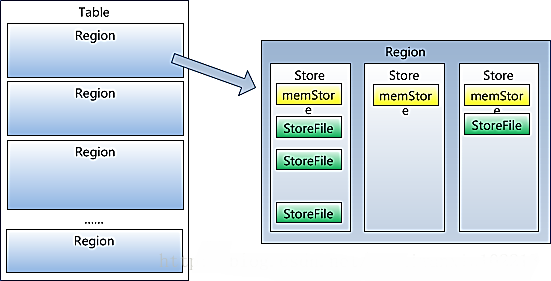
5гҖҒRegionиҷҪ然жҳҜеҲҶеёғејҸеӯҳеӮЁзҡ„жңҖе°ҸеҚ•е…ғпјҢдҪҶ并дёҚжҳҜеӯҳеӮЁзҡ„жңҖе°ҸеҚ•е…ғгҖӮRegionз”ұдёҖдёӘжҲ–иҖ…еӨҡдёӘStoreз»„жҲҗпјҢжҜҸдёӘstoreдҝқеӯҳдёҖдёӘcolumnsfamilyпјӣжҜҸдёӘStroreеҸҲз”ұдёҖдёӘmemStoreе’Ң0иҮіеӨҡдёӘStoreFileз»„жҲҗпјҢStoreFileеҢ…еҗ«HFileпјӣmemStoreеӯҳеӮЁеңЁеҶ…еӯҳдёӯпјҢStoreFileеӯҳеӮЁеңЁHDFSдёҠгҖӮ
В·HBaseжһ¶жһ„еҸҠеҹәжң¬з»„件
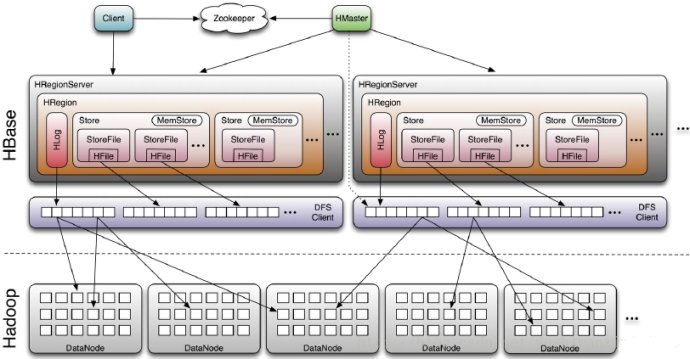
Hbaseеҹәжң¬з»„件иҜҙжҳҺпјҡ
Client
ГјеҢ…еҗ«и®ҝй—®HBaseзҡ„жҺҘеҸЈпјҢ并з»ҙжҠӨcacheжқҘеҠ еҝ«еҜ№HBaseзҡ„и®ҝй—®пјҢжҜ”еҰӮregionзҡ„дҪҚзҪ®дҝЎжҒҜ
Master
ГјдёәRegionserverеҲҶй…Қregion
ГјиҙҹиҙЈRegionserverзҡ„иҙҹиҪҪеқҮиЎЎ
ГјеҸ‘зҺ°еӨұж•Ҳзҡ„Regionserver并йҮҚж–°еҲҶй…Қе…¶дёҠзҡ„region
Гјз®ЎзҗҶз”ЁжҲ·еҜ№tableзҡ„еўһеҲ ж”№жҹҘж“ҚдҪң
RegionServer
ГјRegionserverз»ҙжҠӨregionпјҢеӨ„зҗҶеҜ№иҝҷдәӣregionзҡ„IOиҜ·жұӮ
ГјRegionserverиҙҹиҙЈеҲҮеҲҶеңЁиҝҗиЎҢиҝҮзЁӢдёӯеҸҳеҫ—иҝҮеӨ§зҡ„region
ZookeeperдҪңз”Ё
ГјйҖҡиҝҮйҖүдёҫпјҢдҝқиҜҒд»»дҪ•ж—¶еҖҷпјҢйӣҶзҫӨдёӯеҸӘжңүдёҖдёӘmasterпјҢMasterдёҺRegionServersеҗҜеҠЁж—¶дјҡеҗ‘ZooKeeperжіЁеҶҢ
Гјеӯҳиҙ®жүҖжңүRegionзҡ„еҜ»еқҖе…ҘеҸЈ
Гје®һж—¶зӣ‘жҺ§Regionserverзҡ„дёҠзәҝе’ҢдёӢзәҝдҝЎжҒҜгҖӮ并е®һж—¶йҖҡзҹҘз»ҷMaster
ГјеӯҳеӮЁHBaseзҡ„schemaе’Ңtableе…ғж•°жҚ®
Гјй»ҳи®Өжғ…еҶөдёӢпјҢHBaseз®ЎзҗҶZooKeeper е®һдҫӢпјҢжҜ”еҰӮпјҢ еҗҜеҠЁжҲ–иҖ…еҒңжӯўZooKeeper
ГјZookeeperзҡ„еј•е…ҘдҪҝеҫ—MasterдёҚеҶҚжҳҜеҚ•зӮ№ж•…йҡң

Write-Ahead-LogпјҲWALпјү
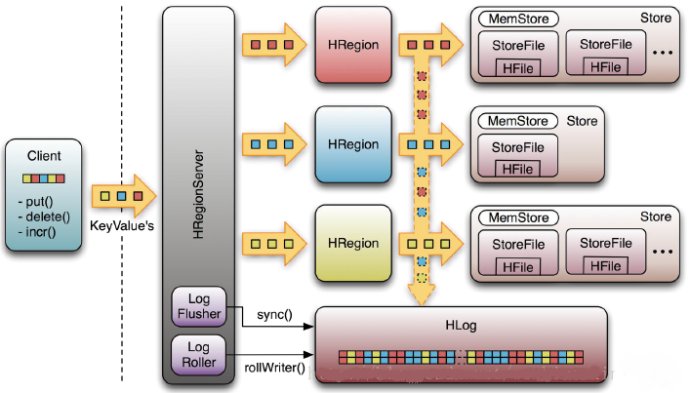
иҜҘжңәеҲ¶з”ЁдәҺж•°жҚ®зҡ„е®№й”ҷе’ҢжҒўеӨҚпјҡ
жҜҸдёӘHRegionServerдёӯйғҪжңүдёҖдёӘHLogеҜ№иұЎпјҢHLogжҳҜдёҖдёӘе®һзҺ°WriteAheadLogзҡ„зұ»пјҢеңЁжҜҸж¬Ўз”ЁжҲ·ж“ҚдҪңеҶҷе…ҘMemStoreзҡ„еҗҢж—¶пјҢд№ҹдјҡеҶҷдёҖд»Ҫж•°жҚ®еҲ°HLogж–Ү件дёӯпјҲHLogж–Үд»¶ж јејҸи§ҒеҗҺз»ӯпјүпјҢHLogж–Ү件е®ҡжңҹдјҡж»ҡеҠЁеҮәж–°зҡ„пјҢ并еҲ йҷӨж—§зҡ„ж–Ү件пјҲе·ІжҢҒд№…еҢ–еҲ°StoreFileдёӯзҡ„ж•°жҚ®пјүгҖӮеҪ“HRegionServerж„ҸеӨ–з»ҲжӯўеҗҺпјҢHMasterдјҡйҖҡиҝҮZookeeperж„ҹзҹҘеҲ°пјҢHMasterйҰ–е…ҲдјҡеӨ„зҗҶйҒ—з•ҷзҡ„HLogж–Ү件пјҢе°Ҷе…¶дёӯдёҚеҗҢRegionзҡ„Logж•°жҚ®иҝӣиЎҢжӢҶеҲҶпјҢеҲҶеҲ«ж”ҫеҲ°зӣёеә”regionзҡ„зӣ®еҪ•дёӢпјҢ然еҗҺеҶҚе°ҶеӨұж•Ҳзҡ„regionйҮҚж–°еҲҶй…ҚпјҢйўҶеҸ–еҲ°иҝҷдәӣregionзҡ„HRegionServerеңЁLoad Regionзҡ„иҝҮзЁӢдёӯпјҢдјҡеҸ‘зҺ°жңүеҺҶеҸІHLogйңҖиҰҒеӨ„зҗҶпјҢеӣ жӯӨдјҡReplayHLogдёӯзҡ„ж•°жҚ®еҲ°MemStoreдёӯпјҢ然еҗҺflushеҲ°StoreFilesпјҢе®ҢжҲҗж•°жҚ®жҒўеӨҚ
HBaseе®№й”ҷжҖ§
Masterе®№й”ҷпјҡZookeeperйҮҚж–°йҖүжӢ©дёҖдёӘж–°зҡ„Master
Гјж— MasterиҝҮзЁӢдёӯпјҢж•°жҚ®иҜ»еҸ–д»Қз…§еёёиҝӣиЎҢпјӣ
Гјж— masterиҝҮзЁӢдёӯпјҢregionеҲҮеҲҶгҖҒиҙҹиҪҪеқҮиЎЎзӯүж— жі•иҝӣиЎҢпјӣ
RegionServerе®№й”ҷпјҡе®ҡж—¶еҗ‘ZookeeperжұҮжҠҘеҝғи·іпјҢеҰӮжһңдёҖж—Ұж—¶й—ҙеҶ…жңӘеҮәзҺ°еҝғи·іпјҢMasterе°ҶиҜҘRegionServerдёҠзҡ„RegionйҮҚж–°еҲҶй…Қ
еҲ°е…¶д»–RegionServerдёҠпјҢеӨұж•ҲжңҚеҠЎеҷЁдёҠвҖңйў„еҶҷвҖқж—Ҙеҝ—з”ұдё»жңҚеҠЎеҷЁиҝӣиЎҢеҲҶеүІе№¶жҙҫйҖҒз»ҷж–°зҡ„RegionServer
Zookeeperе®№й”ҷпјҡZookeeperжҳҜдёҖдёӘеҸҜйқ ең°жңҚеҠЎпјҢдёҖиҲ¬й…ҚзҪ®3жҲ–5дёӘZookeeperе®һдҫӢ
Regionе®ҡдҪҚжөҒзЁӢпјҡ
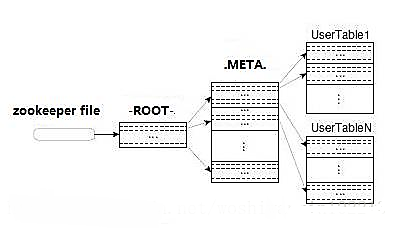
еҜ»жүҫRegionServer
ZooKeeper-->-ROOT-(еҚ•Region)-->.META.-->з”ЁжҲ·иЎЁ
-ROOT-
ГјиЎЁеҢ…еҗ«.META.иЎЁжүҖеңЁзҡ„regionеҲ—иЎЁпјҢиҜҘиЎЁеҸӘдјҡжңүдёҖдёӘRegionпјӣ
ГјZookeeperдёӯи®°еҪ•дәҶ-ROOT-иЎЁзҡ„locationгҖӮ
.META.
ГјиЎЁеҢ…еҗ«жүҖжңүзҡ„з”ЁжҲ·з©әй—ҙregionеҲ—иЎЁпјҢд»ҘеҸҠRegionServerзҡ„жңҚеҠЎеҷЁең°еқҖгҖӮ
В·HbaseдҪҝз”ЁеңәжҷҜ
storing large amounts of data(100s ofTBs) needhigh write throughput needefficient random access(key lookups) within large datasets needto scale gracefully with data forstructured and semi-structured data don'tneed fullRDMS capabilities(cross row/cross table transaction,joins,etc.)
еӨ§ж•°жҚ®йҮҸеӯҳеӮЁпјҢеӨ§ж•°жҚ®йҮҸй«ҳ并еҸ‘ж“ҚдҪң
йңҖиҰҒеҜ№ж•°жҚ®йҡҸжңәиҜ»еҶҷж“ҚдҪң
иҜ»еҶҷи®ҝй—®еқҮжҳҜйқһеёёз®ҖеҚ•зҡ„ж“ҚдҪң
В·HbaseдёҺHDFSеҜ№жҜ”
дёӨиҖ…йғҪе…·жңүиүҜеҘҪзҡ„е®№й”ҷжҖ§е’Ңжү©еұ•жҖ§пјҢйғҪеҸҜд»Ҙжү©еұ•еҲ°жҲҗзҷҫдёҠеҚғдёӘиҠӮзӮ№пјӣ
HDFSйҖӮеҗҲжү№еӨ„зҗҶеңәжҷҜ
дёҚж”ҜжҢҒж•°жҚ®йҡҸжңәжҹҘжүҫ
дёҚйҖӮеҗҲеўһйҮҸж•°жҚ®еӨ„зҗҶ
дёҚж”ҜжҢҒж•°жҚ®жӣҙж–°

е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ