жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
SeleniumжҳҜеҪ“еүҚдё»жөҒзҡ„webиҮӘеҠЁеҢ–е·Ҙе…·пјҢжҸҗдҫӣдәҶеӨҡз§ҚжөҸи§ҲеҷЁзҡ„ж”ҜжҢҒпјҲChrome,Firefox, IEзӯүзӯүпјүпјҢеҪ“然еӨ§е®¶д№ҹеҸҜд»Ҙз”ЁиҮӘе·ұе–ңж¬ўзҡ„иҜӯиЁҖпјҲJavaпјҢC#пјҢPythonзӯүпјүжқҘеҶҷз”ЁдҫӢпјҢеҫҲе®№жҳ“дёҠжүӢгҖӮеҪ“еӨ§е®¶еҶҷе®Ң第дёҖдёӘиҮӘеҠЁеҢ–з”ЁдҫӢзҡ„ж—¶еҖҷиӮҜе®ҡж„ҹи§үвҖқе“Ү...еҘҪзүӣxвҖңпјҢдҪҶжҳҜеӨ§е®¶з”ЁдҪҷе…үжү«дәҶдёҖдёӢд»Јз ҒеҗҺпјҢеҶ…еҝғд№ҹи®ёжҳҜеҙ©жәғзҡ„пјҢеӣ дёәеӨӘд№ұдәҶпјҒеғҸиҝҷж ·пјҡ
__author__ = 'xua'
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import unittest
class TCRepeatLogin(unittest.TestCase):
def setUp(self):
#webdriver
self.driver = webdriver.Chrome(r'C:\Users\xua\Downloads\chromedriver_win32\chromedriver.exe')
self.driver.implicitly_wait(30)
self.base_url = "http://10.222.30.145:9000/"
def test_(self):
driver = self.driver
driver.get(self.base_url)
#enter username and password
driver.find_element_by_id("username").clear()
driver.find_element_by_id("username").send_keys("sbxadmin")
driver.find_element_by_id("password").clear()
driver.find_element_by_id("password").send_keys("IGTtest1"+Keys.RETURN)
#find dialog and check
dialogTitle = driver.find_element(By.XPATH,'//html/body/div[7]/div/div/div[1]/h4')
self.assertEqual("Sign in",dialogTitle.text)
#find cancel button and click
cancelBtn = driver.find_element(By.XPATH,'//html/body/div[7]/div/div/div[3]/button[2]')
cancelBtn.click()
def tearDown(self):
self.driver.close()
if __name__ == "__main__":
unittest.main()
д»ҺеҮ зӮ№жқҘеҲҶжһҗдёӢдёҠиҫ№зҡ„д»Јз Ғ:
1. жҳ“иҜ»жҖ§пјҡйқһеёёйҡҫзҗҶи§ЈгҖӮиҝҷд№ҲеӨҡfind elementпјҹиҝҷйҡҫйҒ“д№ҹжҳҜtest caseпјҹ
2. еҸҜжү©еұ•жҖ§пјҡйғҪжҳҜдёҖдёӘдёӘеӯӨз«Ӣзҡ„test caseпјҢж— жү©еұ•жҖ§еҸҜиЁҖ
3. еҸҜеӨҚз”ЁжҖ§пјҡж— е…¬е…ұж–№жі•пјҢеҫҲйҡҫжҸҗеҲ°еӨҚз”Ё
4. еҸҜз»ҙжҠӨжҖ§пјҡдёҖж—ҰйЎөйқўе…ғзҙ дҝ®ж”№пјҢеҲҷйңҖиҰҒзӣёеә”дҝ®ж”№жүҖжңүзӣёе…із”ЁдҫӢпјҢeffortеӨ§
еҹәдәҺд»ҘдёҠзҡ„й—®йўҳпјҢPythonдёәжҲ‘们жҸҗдҫӣдәҶPageжЁЎејҸжқҘз®ЎзҗҶжөӢиҜ•пјҢе®ғеӨ§жҰӮжҳҜиҝҷж ·еӯҗзҡ„пјҡ(TestCaseдёӯзҡ„иҷҡзәҝз®ӯеӨҙеә”иҜҘжҳҜжҢҮеҗ‘еҗ„дёӘpageпјҢ家йҮҢз”өи„‘жІЎиЈ…дҝ®ж”№иҪҜ件пјҢе°ұдёҚж”№дәҶ:))
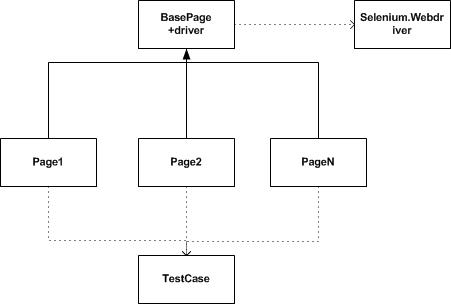
е…ідәҺPageжЁЎејҸпјҡ
1. жҠҪиұЎеҮәжқҘдёҖдёӘBasePageеҹәзұ»пјҢе®ғеҢ…еҗ«дёҖдёӘжҢҮеҗ‘Selenium.webdriverзҡ„еұһжҖ§
2. жҜҸдёҖдёӘwebpageйғҪ继жүҝиҮӘBasePageеҹәзұ»пјҢйҖҡиҝҮdriverжқҘиҺ·еҸ–жң¬йЎөйқўзҡ„е…ғзҙ пјҢжҜҸдёӘйЎөйқўзҡ„ж“ҚдҪңйғҪжҠҪиұЎдёәдёҖдёӘдёӘж–№жі•
3. TestCase继жүҝиҮӘunittest.Testcaseзұ»пјҢ并дҫқиө–зӣёеә”зҡ„Pageзұ»жқҘе®һзҺ°зӣёеә”зҡ„test caseжӯҘйӘӨ
еҲ©з”ЁPageжЁЎејҸе®һзҺ°дёҠиҫ№зҡ„з”ЁдҫӢпјҢд»Јз ҒеҰӮдёӢпјҡ
BasePage.py:
__author__ = 'xua'
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
#super class
class BasePage(object):
def __init__(self, driver):
self.driver = driver
class LoginPage(BasePage):
#page element identifier
usename = (By.ID,'username')
password = (By.ID, 'password')
dialogTitle = (By.XPATH,'//html/body/div[7]/div/div/div[1]/h4')
cancelButton = (By.XPATH,'//html/body/div[7]/div/div/div[3]/button[2]')
#Get username textbox and input username
def set_username(self,username):
name = self.driver.find_element(*LoginPage.usename)
name.send_keys(username)
#Get password textbox and input password, then hit return
def set_password(self, password):
pwd = self.driver.find_element(*LoginPage.password)
pwd.send_keys(password + Keys.RETURN)
#Get pop up dialog title
def get_DiaglogTitle(self):
digTitle = self.driver.find_element(*LoginPage.dialogTitle)
return digTitle.text
#Get "cancel" button and then click
def click_cancel(self):
cancelbtn = self.driver.find_element(*LoginPage.cancelButton)
cancelbtn.click()
Test_Login.py:
__author__ = 'xua'
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.alert import Alert
import unittest
import time
import BasePage
class Test_Login(unittest.TestCase):
#Setup
def setUp(self):
self.driver = webdriver.Chrome(r'C:\Users\xua\Downloads\chromedriver_win32\chromedriver.exe')
self.driver.implicitly_wait(30)
self.base_url = "http://10.222.30.145:9000/"
#tearDown
def tearDown(self):
self.driver.close()
def test_Login(self):
#Step1: open base site
self.driver.get(self.base_url)
#Step2: Open Login page
login_page = BasePage.LoginPage(self.driver)
#Step3: Enter username
login_page.set_username("sbXadmin")
#Step4: Enter password
login_page.set_password("IGTtest1")
#Checkpoint1: Check popup dialog title
self.assertEqual(login_page.get_DiaglogTitle(),"Sign in")
#Step5: Cancel dialog
login_page.click_cancel()
if __name__ == "__main__":
unittest.main()
OkпјҢ йӮЈд№ҲжҲ‘们еӣһеӨҙжқҘзңӢпјҢPageжЁЎејҸжҳҜеҗҰи§ЈеҶідәҶдёҠиҫ№зҡ„еӣӣдёӘж–№йқўзҡ„й—®йўҳпјҡ
1. жҳ“иҜ»жҖ§: зҺ°еңЁеҚ•зңӢtest_loginж–№жі•пјҢзЎ®е®һжңүзӮ№test caseзҡ„ж ·еӯҗдәҶпјҢжҜҸдёҖжӯҘйғҪеҫҲжҳҺдәҶ
2. еҸҜжү©еұ•жҖ§пјҡз”ұдәҺжҠҠжҜҸдёӘpageзҡ„е…ғзҙ ж“ҚдҪңйғҪйӣҶжҲҗеҲ°дёҖдёӘpageзұ»дёӯпјҢжүҖд»ҘеўһеҲ ж”№жҹҘйғҪе’Ңж–№дҫҝ
3. еҸҜеӨҚз”ЁжҖ§: pageзҡ„еҹәжң¬ж“ҚдҪңйғҪеҸҳжҲҗдәҶдёҖдёӘдёӘзҡ„ж–№жі•пјҢеңЁдёҚеҗҢзҡ„test caseдёӯеҸҜд»ҘйҮҚеӨҚдҪҝз”Ё
4. еҸҜз»ҙжҠӨжҖ§пјҡеҰӮжһңйЎөйқўдҝ®ж”№пјҢеҸӘйңҖдҝ®ж”№зӣёеә”pageзұ»дёӯзҡ„ж–№жі•еҚіеҸҜпјҢж— йңҖдҝ®ж”№жҜҸдёӘtest case
жҖ»з»“пјҡ
PageжЁЎејҸз»ҷжҲ‘们жҸҗдҫӣдәҶдёҖдёӘеҫҲеҘҪзҡ„йЎөйқўе’Ңз”ЁдҫӢе®һзҺ°зҡ„еҲҶзҰ»жңәеҲ¶пјҢйҷҚдҪҺдәҶиҖҰеҗҲпјҢжҸҗй«ҳдәҶеҶ…иҒҡпјҢеҸҜд»ҘдҪҝжҲ‘们еңЁwebиҮӘеҠЁеҢ–дёӯеҒҡеҲ°жёёеҲғжңүдҪҷгҖӮ
д»ҘдёҠе°ұжҳҜжң¬ж–Үзҡ„е…ЁйғЁеҶ…е®№пјҢеёҢжңӣеҜ№еӨ§е®¶зҡ„еӯҰд№ жңүжүҖеё®еҠ©пјҢд№ҹеёҢжңӣеӨ§е®¶еӨҡеӨҡж”ҜжҢҒдәҝйҖҹдә‘гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ