жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жҺЁиҚҗз®—жі•еңЁдә’иҒ”зҪ‘иЎҢдёҡзҡ„еә”з”Ёйқһеёёе№ҝжіӣпјҢд»Ҡж—ҘеӨҙжқЎгҖҒзҫҺеӣўзӮ№иҜ„зӯүйғҪжңүдёӘжҖ§еҢ–жҺЁиҚҗпјҢжҺЁиҚҗз®—жі•жҠҪиұЎжқҘи®ІпјҢжҳҜдёҖз§ҚеҜ№дәҺеҶ…е®№ж»Ўж„ҸеәҰзҡ„жӢҹеҗҲеҮҪж•°пјҢж¶үеҸҠеҲ°з”ЁжҲ·зү№еҫҒе’ҢеҶ…е®№зү№еҫҒпјҢдҪңдёәжЁЎеһӢи®ӯз»ғжүҖйңҖз»ҙеәҰзҡ„дёӨеӨ§жқҘжәҗпјҢиҖҢзӮ№еҮ»зҺҮпјҢйЎөйқўеҒңз•ҷж—¶й—ҙпјҢиҜ„и®әжҲ–дёӢеҚ•зӯүйғҪеҸҜд»ҘдҪңдёәдёҖдёӘйҮҸеҢ–зҡ„ Y еҖјпјҢиҝҷж ·е°ұеҸҜд»ҘиҝӣиЎҢзү№еҫҒе·ҘзЁӢпјҢжһ„е»әеҮәдёҖдёӘж•°жҚ®йӣҶпјҢ然еҗҺйҖүжӢ©дёҖдёӘеҗҲйҖӮзҡ„зӣ‘зқЈеӯҰд№ з®—жі•иҝӣиЎҢи®ӯз»ғпјҢеҫ—еҲ°жЁЎеһӢеҗҺпјҢдёәе®ўжҲ·жҺЁиҚҗеҒҸеҘҪзҡ„еҶ…е®№пјҢеҰӮеӨҙжқЎзҡ„иҜқпјҢе°ұжҳҜе’ЁиҜўе’Ңж–Үз« пјҢзҫҺеӣўзҡ„е°ұжҳҜз”ҹжҙ»жңҚеҠЎеҶ…е®№гҖӮ
еҸҜйҖүжӢ©зҡ„жЁЎеһӢеҫҲеӨҡпјҢеҰӮеҚҸеҗҢиҝҮж»ӨпјҢйҖ»иҫ‘ж–Ҝи’ӮеӣһеҪ’пјҢеҹәдәҺDNNзҡ„жЁЎеһӢпјҢFMзӯүгҖӮжҲ‘们дҪҝз”Ёзҡ„ж–№ејҸжҳҜпјҢеҹәдәҺеҶ…е®№зӣёдјјеәҰи®Ўз®—иҝӣиЎҢеҸ¬еӣһпјҢд№ӢеҗҺйҖҡиҝҮFMжЁЎеһӢе’ҢйҖ»иҫ‘ж–Ҝи’ӮеӣһеҪ’жЁЎеһӢиҝӣиЎҢзІҫжҺ’жҺЁиҚҗпјҢдёӢйқўе°ұеҲҶеҲ«иҜҙдёҖдёӢпјҢжҲ‘们еҒҡиҝҷдёӘз”өеҪұжҺЁиҚҗзі»з»ҹиҝҮзЁӢдёӯпјҢд»Һж•°жҚ®еҮҶеӨҮпјҢзү№еҫҒе·ҘзЁӢпјҢеҲ°жЁЎеһӢи®ӯз»ғе’Ңеә”з”Ёзҡ„ж•ҙдёӘиҝҮзЁӢгҖӮ
жҲ‘们е®һзҺ°зҡ„иҝҷдёӘз”өеҪұжҺЁиҚҗзі»з»ҹпјҢзҲ¬еҸ–зҡ„ж•°жҚ®е®һйҷ…дёҠз»ҙеәҰжҳҜзӣёеҜ№е°‘зҡ„пјҢзү№еҲ«жҳҜз”ЁжҲ·иҝҷдёҖдҫ§зҡ„з»ҙеәҰпјҢжӯЈеёёжҺЁиҚҗзі»з»ҹж¶үеҸҠзҡ„з»ҙеәҰпјҢиҜёеҰӮйЎөйқўеҒңз•ҷж—¶й—ҙпјҢзӮ№еҮ»йў‘ж¬ЎпјҢ收и—Ҹзӯүиҝҷдәӣз»ҙеәҰйғҪжҳҜжІЎжңүзҡ„пјҢд»ҘеҸҠз”ЁжҲ·жң¬иә«зҡ„з»ҙеәҰд№ҹзӣёеҜ№иҰҒе°‘пјҢжІЎжңүең°еқҖгҖҒе№ҙйҫ„гҖҒжҖ§еҲ«зӯүиҝҷдәӣеҹәжң¬зҡ„з»ҙеәҰпјҢиҝҷж ·жҲ‘们зҲ¬еҸ–зҡ„ж•°жҚ®еҸӘжңүжү“еҲҶе’ҢиҜ„и®әиҝҷдәӣдҝЎжҒҜпјҢжүҖд»Ҙд№ӢеҗҺжҲ‘们еҸҲд»ҺиҝҷдәӣдҝЎжҒҜйҮҢеҶҚжӢҝеҮәдёҖдәӣз»ҹи®Ўз»ҙеәҰжқҘз”ЁгҖӮжҲ‘们зҲ¬еҸ–зҡ„з”өеҪұж•°жҚ®(йҷӨз”өеҪұиҜҰжғ…е’ҢеӣҫзүҮдҝЎжҒҜеӨ–)жҳҜеҰӮдёӢиҝҷж ·зҡ„еҪўејҸпјҡ
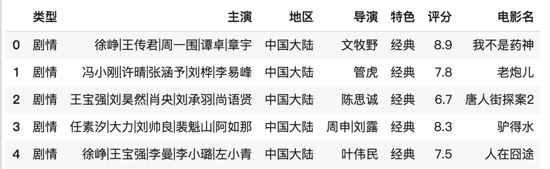
иҝҷйҮҢзҡ„ж•°жҚ®жҳҜжңүеҶ—дҪҷзҡ„пјҢеҸҲйҖҡиҝҮеҰӮдёӢзҡ„д»Јз ҒпјҢеҜ№ж•°жҚ®иҝӣиЎҢжҢүз»ҙеәҰеҗҲ并пјҢеҺ»йҷӨеҶ—дҪҷж•°жҚ®жқЎзӣ®пјҡ
# еӨ„зҗҶдё»еҮҪж•°пјҢиҙҹиҙЈе°ҶеӨҡдёӘеҶ—дҪҷж•°жҚ®еҗҲ并дёәдёҖжқЎз”өеҪұж•°жҚ®пјҢе°Ҷең°еҢәпјҢеҜјжј”пјҢдё»жј”пјҢзұ»еһӢпјҢзү№иүІзӯүз»ҙеәҰж•°жҚ®еҗҲ并
def mainfunc():
try:
unable_list = []
with connection.cursor() as cursor:
sql='select id,name from movie'
cout=cursor.execute(sql)
print("ж•°йҮҸпјҡ "+str(cout))
for row in cursor.fetchall():
#print(row[1])
movieinfo = df[df['з”өеҪұеҗҚ'] == row[1]]
if movieinfo.shape[0] == 0:
disable_movie(row[0])
print('disable movie ' + str(row[1]))
else:
g = lambda x:movieinfo[x].iloc[0]
types = movieinfo['зұ»еһӢ'].tolist()
types = reduce(lambda x,y:x+'|'+y,list(set(types)))
traits = movieinfo['зү№иүІ'].tolist()
traits = reduce(lambda x,y:x+'|'+y,list(set(traits)))
update_one_movie_info(type_=types, actors=g('дё»жј”'), region=g('ең°еҢә'), director=g('еҜјжј”'), trait=traits, rat=g('иҜ„еҲҶ'), id_=row[0])
connection.commit()
finally:
connection.close()
д№ӢеҗҺејҖе§ӢеҮҶеӨҮз”ЁжҲ·ж•°жҚ®пјҢжҲ‘们д»Һз”ЁжҲ·жү“еҲҶзҡ„ж•°жҚ®дёӯпјҢз»ҹи®ЎеҮәжҜҸдёҖдёӘз”ЁжҲ·зҡ„жү“еҲҶзҡ„жңҖеӨ§еҖјпјҢжңҖе°ҸеҖјпјҢдёӯдҪҚж•°еҖје’Ңе№іеқҮеҖјзӯүпјҢд»ҺиҖҢдҪңдёәз”ЁжҲ·зҡ„дёҖдёӘйҷ„еҠ еұһжҖ§пјҢеӯҳеӮЁдәҺuserproexиЎЁдёӯпјҡ
'insert into userproex(userid, rmax, rmin, ravg, rcount, rsum, rmedian) values(\'%s\', %s, %s, %s, %s, %s, %s)' % (userid, rmax, rmin, ravg, rcount, rsum, rmedium) 'update userproex set rmax=%s, rmin=%s, ravg=%s, rmedian=%s, rcount=%s, rsum=%s where userid=\'%s\'' % (rmax, rmin, ravg, rmedium, rcount, rsum, userid)
д»ҘдёҠдёӨдёӘSQLжҳҜжңҖз»ҲжҸ’е…ҘиЎЁзҡ„ж—¶еҖҷз”ЁеҲ°зҡ„пјҢд»ЈиЎЁеҮҶеӨҮз”ЁжҲ·ж•°жҚ®зҡ„жңҖз»ҲжӯҘйӘӨпјҢе…¶дҪҷз»ҶиҠӮеҸҜд»ҘеҸӮиҖғж–Үжң«зҡ„githubд»“еә“пјҢдёҚеңЁжӯӨиөҳиҝ°пјҢж•°жҚ®еӨ„зҗҶиҝҳз”ЁеҲ°дәҶдёҖдәӣSQLпјҢд»ҘеҸҠе…¶д»–еӨ„зҗҶз»ҶиҠӮгҖӮ
зі»з»ҹдёҠзәҝиҝҗиЎҢж—¶пјҢ第дёҖж¬ЎжҳҜе…ЁйҮҸзҡ„ж•°жҚ®еӨ„зҗҶпјҢд№ӢеҗҺдјҡжҳҜеўһйҮҸеӨ„зҗҶиҝҮзЁӢпјҢиҝҷдёӘеҗҺйқўиҝҳдјҡжҸҗеҲ°гҖӮ
жҲ‘们зӣ®еүҚжҠҠз”ЁжҲ·ж•°жҚ®е’Ңз”өеҪұзҡ„ж•°жҚ®зҡ„еҺҹе§Ӣж•°жҚ®з®—жҳҜеҮҶеӨҮеҘҪдәҶпјҢдёӢдёҖжӯҘејҖе§Ӣзү№еҫҒе·ҘзЁӢгҖӮеҒҡзү№еҫҒе·ҘзЁӢзҡ„жҖқи·ҜжҳҜпјҢеҜ№type, actors, director, traitеӣӣдёӘзұ»еһӢж•°жҚ®еҲҶеҲ«жһ„е»әдёҖдёӘйў‘еәҰз»ҹи®Ўеӯ—е…ёпјҢз”ЁдәҺд№ӢеҗҺзҡ„one-hotзј–з ҒпјҢд»Јз ҒеҰӮдёӢпјҡ
def get_dim_dict(df, dim_name):
type_list = list(map(lambda x:x.split('|') ,df[dim_name]))
type_list = [x for l in type_list for x in l]
def reduce_func(x, y):
for i in x:
if i[0] == y[0][0]:
x.remove(i)
x.append(((i[0],i[1] + 1)))
return x
x.append(y[0])
return x
l = filter(lambda x:x != None, map(lambda x:[(x, 1)], type_list))
type_zip = reduce(reduce_func, list(l))
type_dict = {}
for i in type_zip:
type_dict[i[0]] = i[1]
return type_dict
ж¶үеҸҠеҲ°зҡ„еҶ—дҪҷж•°жҚ®д№ҹиҰҒеҲ йҷӨ
df_ = df.drop(['ADD_TIME', 'enable', 'rat', 'id', 'name'], axis=1)
е°Ҷз”өеҪұж•°жҚ®иҪ¬жҚўдёәеӯ—е…ёеҲ—иЎЁпјҢз”ұдәҺжј”е‘ҳе’ҢеҜјжј”еқҮиҝҮдёҮз»ҙпјҢе®һйҷ…и®Ўз®—ж—¶иҝҮдәҺзЁҖз–ҸпјҢеҪ“жј”е‘ҳжҲ–еҜјжј”еҸӘеҮәзҺ°дёҖж¬Ўж—¶пјҢж Үи®°дёәеҶ·й—Ёжј”е‘ҳжҲ–еҜјжј”
movie_dict_list = []
for i in df_.index:
movie_dict = {}
#type
for s_type in df_.iloc[i]['type'].split('|'):
movie_dict[s_type] = 1
#actors
for s_actor in df_.iloc[i]['actors'].split('|'):
if actors_dict[s_actor] < 2:
movie_dict['other_actor'] = 1
else:
movie_dict[s_actor] = 1
#regios
movie_dict[df_.iloc[i]['region']] = 1
#director
for s_director in df_.iloc[i]['director'].split('|'):
if director_dict[s_director] < 2:
movie_dict['other_director'] = 1
else:
movie_dict[s_director] = 1
#trait
for s_trait in df_.iloc[i]['trait'].split('|'):
movie_dict[s_trait] = 1
movie_dict_list.append(movie_dict)
дҪҝз”ЁDictVectorizerиҝӣиЎҢеҗ‘йҮҸеҢ–пјҢеҒҡOne-hotзј–з Ғ
v = DictVectorizer() X = v.fit_transform(movie_dict_list)
иҝҷж ·зҡ„ж•°жҚ®пјҢдёӢйқўеҒҡдҪҷејҰзӣёдјјеәҰе·Із»ҸеҸҜд»ҘдәҶпјҢиҝҷжҳҜзү№еҫҒе·ҘзЁӢзҡ„еҹәжң¬зҡ„дёҖдёӘеӨ„зҗҶпјҢжЁЎеһӢжүҖдҪҝз”Ёзҡ„ж•°жҚ®пјҢйңҖиҰҒе°Ҷз”өеҪұпјҢиҜ„еҲҶпјҢз”ЁжҲ·еҒҡдёҖдёӘж•°жҚ®жӢјжҺҘпјҢжһ„е»әи®ӯз»ғж ·жң¬пјҢ并дҝқеӯҳCSVпјҢжіЁж„ҸиҝҷдёӘCSVдёҚз”ЁжҜҸж¬Ўе…ЁйҮҸжһ„е»әпјҢиҖҢжҳҜйҷӨ第дёҖж¬ЎеӨ–йғҪжҳҜеўһйҮҸжһ„е»әпјҢйҖҡиҝҮmqlogдёӯзұ»еһӢдёә'c'зҡ„ж¶ҲжҒҜпјҢеўһйҮҸжһ„е»әд»ҘcommentпјҲиҜ„еҲҶпјүдёәдё»зҡ„и®ӯз»ғж ·жң¬пјҢжӢјжҺҘд№ӢеҗҺзҡ„еҪўејҸеҰӮдёӢпјҡ
USERID cf2349f9c01f9a5cd4050aebd30ab74f movieid 10533913 type еү§жғ…|еҘҮе№»|еҶ’йҷ©|е–ңеү§ actors иүҫзұіВ·жіўеӢ’|иҸІеҲ©дёқВ·еҸІеҜҶж–Ҝ|зҗҶжҹҘеҫ·В·еқҺеҫ·|жҜ”е°”В·е“Ҳеҫ·е°”|еҲҳжҳ“ж–ҜВ·еёғиҺұе…Ӣ region зҫҺеӣҪ director еҪјзү№В·йҒ“ж јзү№|зҪ—зәіе°”еӨҡВ·еҫ·е°”В·еҚЎй—Ё trait ж„ҹдәә|з»Ҹе…ё|еҠұеҝ— rat 8.7 rmax 5 rmin 2 ravg 3.85714 rcount 7 rmedian 4 TIME_DIS 15
иҝҷдёӘж•°жҚ®зҡ„actorsзӯүеӯ—ж®өе’ҢдёҠйқўзҡ„еӨ„зҗҶжҳҜдёҖж ·зҡ„пјҢдёәдәҶд№ӢеҗҺlibfmзҡ„дҪҝз”ЁпјҢеңЁиҝҷйҮҢйңҖиҰҒиҪ¬жҚўдёәlibsvmзҡ„ж•°жҚ®ж јејҸ
dump_svmlight_file(train_X_scaling, train_y_, train_file)
жЁЎеһӢдҪҝз”ЁдёҠйҒөеҫӘе…ҲеҸ¬еӣһпјҢеҗҺзІҫжҺ’зҡ„зӯ–з•ҘпјҢе…ҲйҖҡиҝҮдҪҷејҰзӣёдјјеәҰи®Ўз®—дёҖдёӘзӣёдјјеәҰзҹ©йҳөпјҢ然еҗҺж №жҚ®иҝҷдёӘзҹ©йҳөпјҢдёәз”ЁжҲ·жҺЁиҚҗзӣёдјјзҡ„MдёӘз”өеҪұпјҢеңЁйҖҡиҝҮи®ӯз»ғеҘҪзҡ„FMпјҢLRжЁЎеһӢпјҢеҜ№иҝҷдёӘMдёӘз”өеҪұеҒҡеҒҸеҘҪйў„дј°пјҢFMдјҡйў„дј°дёҖдёӘз”ЁжҲ·жү“еҲҶпјҢLRдјҡйў„дј°дёҖдёӘзӮ№еҮ»жҰӮзҺҮпјҢз»јеҗҲз»“жһңжҺЁйҖҒз»ҷз”ЁжҲ·дҪңдёәжҺЁиҚҗз”өеҪұгҖӮ
жЁЎеқ—еҲ—иЎЁ
дёәдәҶиғҪеӨҹиҫ“еҮәдёҖдёӘеҸҜж„ҹеҸ—зҡ„зі»з»ҹпјҢжҲ‘们йҮҮиҙӯдәҶйҳҝйҮҢдә‘жңҚеҠЎеҷЁдҪңдёәж•°жҚ®еә“жңҚеҠЎеҷЁе’Ңеә”з”ЁжңҚеҠЎеҷЁпјҢеңЁзәҝдёҠжҗӯе»әдәҶз”өеҪұжҺЁиҚҗзі»з»ҹзҡ„第дёҖзүҲпјҢең°еқҖжҳҜ:
www.technologyx.cn
еҸҜд»ҘжіЁеҶҢпјҢд№ҹеҸҜд»ҘдҪҝз”Ёе·Іжңүз”ЁжҲ·пјҡ
| з”ЁжҲ·еҗҚ | еҜҶз Ғ |
|---|---|
| gavin | 123 |
| gavin2 | 123 |
| wuenda | 123 |
ж¬ўиҝҺзҷ»еҪ•дҪҝз”Ёж„ҹеҸ—дёҖдёӢгҖӮ

и®ҫи®ЎжҖқи·Ҝ
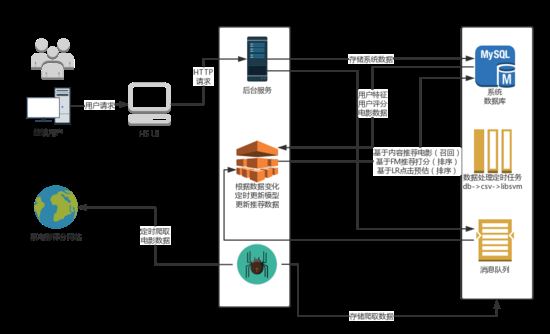
з”Ёз®ҖеҚ•ең°ж–№ејҸиЎЁиҝ°дёҖдёӢи®ҫи®ЎжҖқи·ҜпјҢ
1.еҗҺз«ҜжңҚеҠЎrecsys_webдҫқиө–дәҺзі»з»ҹж•°жҚ®еә“зҡ„жҺЁиҚҗиЎЁвҖҳrecmovie'еұ•зӨәз»ҷз”ЁжҲ·жҺЁиҚҗеҶ…е®№
2.з”ЁжҲ·еҜ№з”өеҪұжү“еҲҶеҗҺпјҲжҡӮж—¶жІЎжңүеҜ№зӮ№еҮ»еҠЁдҪңиҝӣиЎҢе“Қеә”пјүпјҢеҗҺеҸ°еә”з”Ёдјҡеҗ‘mqlogиЎЁжҸ’е…ҘдёҖжқЎж•°жҚ®пјҲж¶ҲжҒҜпјүгҖӮ
3.ж–°з”ЁжҲ·жіЁеҶҢпјҢзі»з»ҹдјҡжҸ’е…ҘmqlogдёӯдёҖжқЎж–°з”ЁжҲ·жіЁеҶҢж¶ҲжҒҜ
4.ж–°з”өеҪұж·»еҠ пјҢзі»з»ҹдјҡжҸ’е…ҘmqlogдёӯдёҖжқЎж–°з”өеҪұж·»еҠ ж¶ҲжҒҜ
5.жҺЁиҚҗжЁЎеқ—recsys_coreдјҡжӢүеҸ–з”ЁжҲ·зҡ„жү“еҲҶж¶ҲжҒҜпјҢ并且并иЎҢзҡ„еҒҡд»ҘдёӢж“ҚдҪңпјҡ
a.еўһйҮҸзҡ„жӣҙж–°и®ӯз»ғж ·жң¬
b.еҝ«йҖҹпјҲеӣ жңҚеҠЎеҷЁжҜ”иҫғеҚЎпјҢзӣ®еүҚи®ҫе®ҡдәҶ延时пјүеҜ№з”ЁжҲ·иЎҢдёәиҝӣиЎҢеҹәдәҺеҶ…е®№жҺЁиҚҗзҡ„еҸ¬еӣһ
c.и®ӯз»ғж ·жң¬жӣҙж–°жЁЎеһӢ
d.дҪҝз”ЁFMпјҢLRжЁЎеһӢеҜ№Item basedжүҖеҸ¬еӣһзҡ„ж•°жҚ®иҝӣиЎҢзІҫжҺ’
e.еӨ„зҗҶж–°з”ЁжҲ·жіЁеҶҢж¶ҲжҒҜпјҢзӣ‘еҗ¬еҲ°з”ЁжҲ·жіЁеҶҢж¶ҲжҒҜеҗҺпјҢеҜ№иҜҘз”ЁжҲ·зҡ„еұһжҖ§еҲқе§ӢеҢ–(з»ҹи®ЎеҖј)гҖӮ
f.еӨ„зҗҶж–°з”өеҪұж·»еҠ ж¶ҲжҒҜпјҢжӣҙж–°еҹәдәҺеҶ…е®№зӣёдјјеәҰиҖҢз”ҹжҲҗзҡ„зӣёдјјеәҰзҹ©йҳө
жіЁпјҡ
з”ұдәҺзәҝдёҠиө„жәҗеҢ®д№ҸпјҢд№ҹдёҚжғідҪҝзі»з»ҹеўһеҠ еӨҚжқӮеәҰпјҢжүҖд»ҘжІЎжңүзӣҙжҺҘдҪҝз”ЁMQ组件пјҢиҖҢжҳҜд»Ҙж•°жҚ®еә“иЎЁдҪңдёәд»ЈжӣҝгҖӮ
йЎ№зӣ®жәҗз Ғең°еқҖ: https://github.com/GavinHacker/recsys_core
жЁЎеһӢзӣёе…ізҡ„жЁЎеқ—д»Ӣз»Қ
еўһйҮҸзҡ„еӨ„зҗҶз”ЁжҲ·commentпјҢеҚіеўһйҮҸеӨ„зҗҶиҜ„еҲҶжЁЎеқ—
иҝҷдёӘжЁЎеқ—иҙҹиҙЈзӣ‘еҗ¬жқҘиҮӘmqlogзҡ„ж¶ҲжҒҜпјҢеҰӮжһңж¶ҲжҒҜзұ»еһӢжҳҜз”ЁжҲ·зҡ„ж–°зҡ„comment,еҲҷеҜ№ж¶ҲжҒҜиҝӣиЎҢжӢүеҸ–пјҢ并зӣёеә”зҡ„жҠҠж–°зҡ„commentеҗҲ并еҲ°жҖ»зҡ„и®ӯз»ғж ·жң¬йӣҶеҗҲпјҢ并дҝқеӯҳеҲ°дёҖдёӘдёҙж—¶зӣ®еҪ•
然еҗҺжӣҙж–°ж•°жҚ®еә“зҡ„configиЎЁпјҢжҠҠжңҖж–°зҡ„ж ·жң¬йӣҶеҗҲ(csvж јејҸ)зҡ„и·Ҝеҫ„жӣҙж–°дёҠеҺ»
иҝҗиЎҢжҲӘеӣҫ
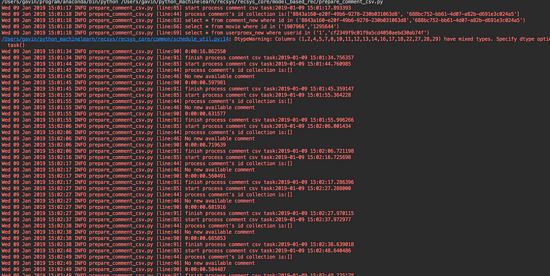
ж¶ҲжҒҜйҳҹеҲ—зҡ„жҲӘеӣҫ
жҠҠcsvеӨ„зҗҶдёәlibsvmж•°жҚ®
иҝҷдёӘжЁЎеқ—иҙҹиҙЈжҠҠжңҖж–°зҡ„csvж–Ү件пјҢејӮжӯҘзҡ„еӨ„зҗҶжҲҗlibSVMж јејҸзҡ„ж•°жҚ®пјҢд»ҘдҫӣlibFMе’ҢLRжЁЎеһӢдҪҝз”ЁпјҢж №жҚ®зі»з»ҹзҡ„жҖ§иғҪзЎ®е®ҡд»»еҠЎзҡ„й—ҙйҡ”ж—¶й—ҙ
иҝҗиЎҢжҲӘеӣҫ
еҹәдәҺеҶ…е®№зӣёдјјеәҰжҺЁиҚҗ
еҪ“зӣ‘еҗ¬еҲ°з”ЁжҲ·жңүж–°зҡ„commentж—¶пјҢиҜҘжЁЎеқ—е°ҶиҝӣиЎҢеҹәдәҺеҶ…е®№зӣёдјјеәҰзҡ„жҺЁиҚҗпјҢ并жҢүз…§з”өеҪұиҜ„еҲҶжҺЁиҚҗ
иҝҗиЎҢжҲӘеӣҫ

libFMйў„жөӢ
http://www.libfm.org/
еҜ№е·Іжңүзҡ„еҹәдәҺеҶ…е®№жҺЁиҚҗеҸ¬еӣһзҡ„з”өеҪұиҝӣиЎҢжЁЎеһӢйў„жөӢжү“еҲҶпјҢе‘ҲзҺ°ж—¶жҢүз…§жү“еҲҶжҺ’еәҸ
еҰӮдёӢеӣҫдёәжү“еҲҶжӣҙж–°
йҖ»иҫ‘еӣһеҪ’йў„жөӢ
еҜ№ж ·жң¬йӣҶдёӯзҡ„жү“еҲҶеҒҡ0пјҢ1еӨ„зҗҶпјҢж №жҚ®жӯЈиҙҹж ·жң¬е№іиЎЎпјҢ> 3еҲҶдёәе–ңж¬ў еҚі1пјҢ <=3 дёә0 еҚідёҚе–ңж¬ўпјҢиҝҷж ·дҪҝз”ЁйҖ»иҫ‘еӣһеҪ’еҒҡжҳҜеҗҰе–ңж¬ўзҡ„зӮ№еҮ»жҰӮзҺҮйў„дј°пјҢж №жҚ®жҰӮзҺҮжҺ’еәҸ
йЎ№зӣ®жәҗз Ғең°еқҖ: https://github.com/GavinHacker/recsys_core
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ