жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚдәҶPythonиҮӘеҠЁеҢ–д№Ӣж•°жҚ®й©ұеҠЁзҡ„зӨәдҫӢеҲҶжһҗпјҢе…·жңүдёҖе®ҡеҖҹйүҙд»·еҖјпјҢж„ҹе…ҙи¶Јзҡ„жңӢеҸӢеҸҜд»ҘеҸӮиҖғдёӢпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« д№ӢеҗҺеӨ§жңү收иҺ·пјҢдёӢйқўи®©е°Ҹзј–еёҰзқҖеӨ§е®¶дёҖиө·дәҶи§ЈдёҖдёӢгҖӮ
еүҚиЁҖ
ж•°жҚ®й©ұеҠЁжҳҜдёҖз§ҚжҖқжғіпјҢи®©ж•°жҚ®е’Ңд»Јз ҒиҝӣиЎҢеҲҶзҰ»пјҢжҜ”еҰӮзҲ¬иҷ«ж—¶пјҢжҲ‘们йңҖиҰҒеҲҶйЎөзҲ¬еҸ–ж•°жҚ®ж—¶пјҢжҲ‘们еҫҖеҫҖжҠҠйЎөж•° page еҸӮж•°еҢ–пјҢж”ҫеңЁ for еҫӘзҺҜ range дёӯпјҢеҒҮеҰӮжІЎжңү range иҝҷдёӘиҮӘеёҰеҸҜд»Ҙз”ҹдә§ж•°еӯ—еәҸеҲ—зҡ„ж–№жі•еҸҜд»Ҙз”ЁпјҢжҲ‘们жҳҜдёҚжҳҜеҫ—жүӢеҠЁйҖҗдёӘж·»еҠ ?
зҺ°е®һеңәжҷҜдёӯе°ұеӯҳеңЁеӨ§йҮҸиҝҷж ·зҡ„дҫӢеӯҗпјҢжҜ”еҰӮжҲ‘д№ӢеүҚеҶҷзҡ„зҲ¬еҸ–дёҠжө·еҗ„ең°еҢәжҲҝз§ҹжғ…еҶөзҡ„ж—¶еҖҷпјҢеҜ№ең°еҢәиҝӣиЎҢйҒҚеҺҶзҡ„ж—¶еҖҷпјҢдёәдәҶеҒ·жҮ’пјҢжҲ‘зӣҙжҺҘжҠҠиҝҷдәӣең°еҢәзҡ„жӢјйҹіе…Ёз§°ж”ҫеңЁдәҶеҲ—иЎЁйҮҢпјҢз»„еҗҲжҲҗеҗ„ең°еҢәжҲҝжәҗзҡ„й“ҫжҺҘгҖӮжңҖеҗҺж–Үз« еҶҷе®ҢдәҶпјҢжңүиҜ»иҖ…еҸҚйҰҲпјҢе°‘дәҶеҫҗжұҮеҢәзҡ„з»ҹи®Ўж•°жҚ®гҖӮиҝҷз§Қе°Ҹж•°йҮҸзҡ„ж•°жҚ®йғҪеҮәзҺ°дәҶзә°жјҸпјҢеҸҜжғіиҖҢзҹҘпјҢеҜ№дәҺеӨ§йҮҸзҡ„ж•°жҚ®пјҢжҖҺд№ҲдҝқиҜҒж•°жҚ®зҡ„е®Ңж•ҙе’ҢеҮҶзЎ®жҖ§?жҲ‘们йңҖиҰҒжҠҠдёӨиҖ…еҲҶзҰ»пјҢж•°жҚ®дё“й—ЁеӮЁеӯҳеңЁзү№е®ҡж–Ү件(жҜ”еҰӮ Excel ж–Ү件)гҖӮ
дёҫдёҖдёӘе°Ҹж —еӯҗпјҡзҷ»еҪ•жөҒзЁӢпјҢеңЁжөӢиҜ•зҡ„ж—¶еҖҷпјҢйҷӨдәҶжөӢиҜ•зҷ»еҪ•жҲҗеҠҹзҡ„еңәжҷҜпјҢжҲ‘们еҫҖеҫҖйңҖиҰҒжөӢеҲ°еҗ„з§Қзҷ»еҪ•ејӮеёёзҡ„еңәжҷҜгҖӮ
еҶҷеҮ жқЎеҫҲеёёи§Ғзҡ„жЎҲдҫӢеҰӮдёӢпјҡ
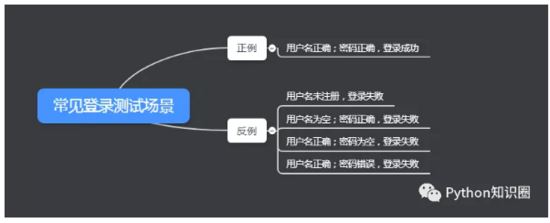
жҜ”еҰӮдёҠйқўеҶҷдәҶ 5 жқЎжЎҲдҫӢпјҢж•°жҚ®е’Ңи„ҡжң¬дёҚеҒҡеҲҶзҰ»зҡ„иҜқпјҢжҲ‘们еҶҷиҮӘеҠЁеҢ–жөӢиҜ•и„ҡжң¬йңҖиҰҒеҶҷ 5 жқЎгҖӮ

5 жқЎжЎҲдҫӢдёӯпјҢи„ҡжң¬йғҪжҳҜеҹәжң¬дёҖж ·зҡ„пјҢеҸӘжҳҜиҫ“е…ҘжЎҶиҫ“е…Ҙзҡ„ж•°жҚ®дёҚдёҖж ·зҪўдәҶгҖӮ
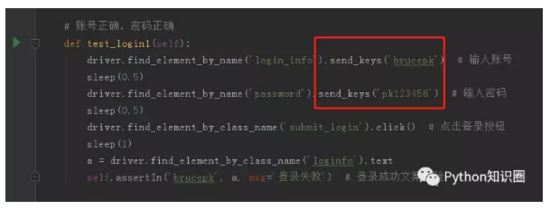
ж•°жҚ®еҲҶзҰ»
жҲ‘们е®Ңе…ЁеҸҜд»ҘжҠҠж•°жҚ®еӯҳеӮЁеңЁ Excel иЎЁдёӯпјҢжҲ‘们йҖҡиҝҮеҫӘзҺҜиҜ»еҸ– Excel иЎЁдёӯзҡ„ж•°жҚ®жқҘе®һзҺ°дёҖжқЎи„ҡжң¬жү§иЎҢеӨҡжқЎж•°жҚ®гҖӮ
жҲ‘们е…Ҳе°ҒиЈ…дёҖдёӘж“ҚдҪң Excel ж–Ү件зҡ„зұ»пјҢйңҖиҰҒе…Ҳе®үиЈ…еҜје…ҘеҢ… openpyxlгҖӮ
жҲ‘们用иҝҷдёӘеә“еҸҜд»ҘеҒҡдёҖдёӢеҠҹиғҪпјҡиҜ»еҸ–иЎЁж јж•°жҚ®гҖҒдҝқеӯҳжү§иЎҢз»“жһңгҖӮ
жҲ‘们е…ҲеңЁзұ»дёӢеҶҷдёҖдёӘжү“ејҖ Excel ж–Ү件зҡ„еҲқе§ӢеҢ–ж–№жі•пјҢжһ„йҖ ж–№жі•зҡ„дҪңз”ЁжҳҜпјҢеҪ“зұ»иў«е®һдҫӢеҢ–еҗҺпјҢдјҡз«ӢеҚіи°ғз”Ёжһ„йҖ ж–№жі•гҖӮ

иҜ»еҸ–иЎЁж јж•°жҚ®
然еҗҺжҲ‘们еҶҷдёҖдёӘиҜ»еҸ– Excel ж•°жҚ®зҡ„ж–№жі•пјҢиҜ»еҸ–ж•°жҚ®еҗҺиҝ”еӣһж•°жҚ®еҲ—иЎЁпјҢд»Ҙдҫҝд№ӢеҗҺи°ғз”ЁиҺ·еҸ–еҜ№еә”зҡ„ж•°жҚ®пјҢеӣ дёә第 1 еҲ—ж•°жҚ®жҳҜеәҸеҸ·пјҢжүҖд»ҘзӣҙжҺҘиҝ”еӣһ第 2 еҲ—д№ӢеҗҺзҡ„ж•°жҚ®гҖӮ
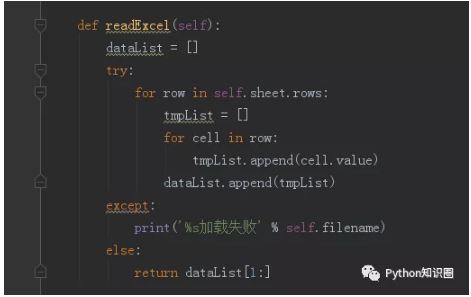
дҝқеӯҳжү§иЎҢз»“жһң
е®һйҷ…з»“жһңе’Ңйў„жңҹз»“жһңеҜ№жҜ”еҗҺпјҢжҲ‘们йңҖиҰҒж Үи®°жү§иЎҢз»“жһңжҳҜ pass жҲ–иҖ… failпјҢжҲ‘们йңҖиҰҒдҝқеӯҳз»“жһңпјҢдҝқеӯҳеҲ°еҜ№еә”зҡ„еҚ•е…ғж јдёӯгҖӮ

жҲ‘们зңӢзңӢжҲ‘们зҡ„жЎҲдҫӢж јејҸпјҡ
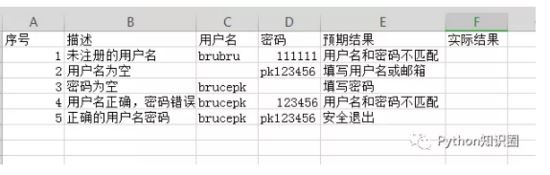
иҝҷж ·зҡ„иҜқпјҢжҲ‘们и„ҡжң¬е°ұдёҚз”ЁеҶҷ 5 жқЎдәҶпјҢи°ғз”Ё Excel ж–Ү件зҡ„ж•°жҚ®пјҢеҫӘзҺҜжү§иЎҢжЎҲдҫӢеҚіеҸҜпјҢдёҚд»…йҖ»иҫ‘жё…жҷ°пјҢиҝҳж–№дҫҝдәҶеҗҺжңҹзҡ„з»ҙжҠӨгҖӮ
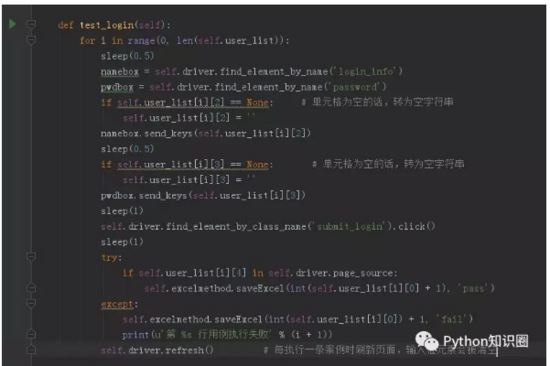
иҝҷж ·пјҢжөӢиҜ•ж•°жҚ®е’Ңи„ҡжң¬еҲҶзҰ»еҗҺпјҢдёҚеҗҢзҡ„жөӢиҜ•ж•°жҚ®з”ЁдёҚеҗҢзҡ„ Excel ж–Ү件дҝқеӯҳеҚіеҸҜгҖӮ
ж„ҹи°ўдҪ иғҪеӨҹи®Өзңҹйҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« пјҢеёҢжңӣе°Ҹзј–еҲҶдә«зҡ„вҖңPythonиҮӘеҠЁеҢ–д№Ӣж•°жҚ®й©ұеҠЁзҡ„зӨәдҫӢеҲҶжһҗвҖқиҝҷзҜҮж–Үз« еҜ№еӨ§е®¶жңүеё®еҠ©пјҢеҗҢж—¶д№ҹеёҢжңӣеӨ§е®¶еӨҡеӨҡж”ҜжҢҒдәҝйҖҹдә‘пјҢе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢжӣҙеӨҡзӣёе…ізҹҘиҜҶзӯүзқҖдҪ жқҘеӯҰд№ !
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ