жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
йЎ№зӣ®жҸҸиҝ°пјҡ
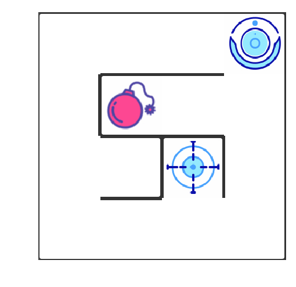
еңЁиҜҘйЎ№зӣ®дёӯпјҢдҪ е°ҶдҪҝз”ЁејәеҢ–еӯҰд№ з®—жі•пјҢе®һзҺ°дёҖдёӘиҮӘеҠЁиө°иҝ·е®«жңәеҷЁдәәгҖӮ
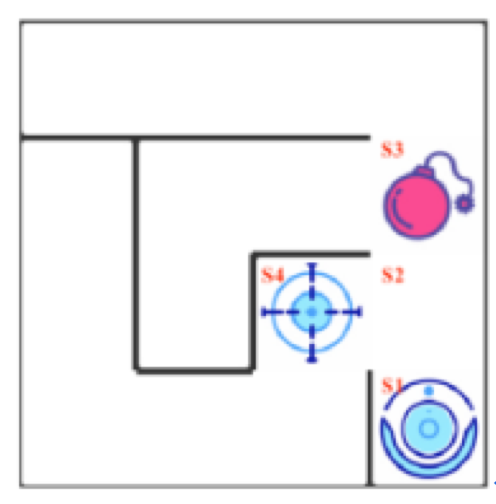
еҰӮдёҠеӣҫжүҖзӨәпјҢжҷәиғҪжңәеҷЁдәәжҳҫзӨәеңЁеҸідёҠи§’гҖӮеңЁжҲ‘们зҡ„иҝ·е®«дёӯпјҢжңүйҷ·йҳұпјҲзәўиүІГ—Г—Г—пјүеҸҠз»ҲзӮ№пјҲи“қиүІзҡ„зӣ®ж ҮзӮ№пјүдёӨз§Қжғ…жҷҜгҖӮжңәеҷЁдәәиҰҒе°ҪйҮҸйҒҝејҖйҷ·йҳұгҖҒе°Ҫеҝ«еҲ°иҫҫзӣ®зҡ„ең°гҖӮ
е°ҸиҪҰеҸҜжү§иЎҢзҡ„еҠЁдҪңеҢ…жӢ¬пјҡеҗ‘дёҠиө° uгҖҒеҗ‘еҸіиө° rгҖҒеҗ‘дёӢиө° dгҖҒеҗ‘е·Ұиө°lгҖӮ
жү§иЎҢдёҚеҗҢзҡ„еҠЁдҪңеҗҺпјҢж №жҚ®дёҚеҗҢзҡ„жғ…еҶөдјҡиҺ·еҫ—дёҚеҗҢзҡ„еҘ–еҠұпјҢе…·дҪ“иҖҢиЁҖпјҢжңүд»ҘдёӢеҮ з§Қжғ…еҶөгҖӮ
жҲ‘们йңҖиҰҒйҖҡиҝҮдҝ®ж”№ robot.py дёӯзҡ„д»Јз ҒпјҢжқҘе®һзҺ°дёҖдёӘ Q Learning жңәеҷЁдәәпјҢе®һзҺ°дёҠиҝ°зҡ„зӣ®ж ҮгҖӮ
Section 1 з®—жі•зҗҶи§Ј
1.1 ејәеҢ–еӯҰд№ жҖ»и§Ҳ
ејәеҢ–еӯҰд№ дҪңдёәжңәеҷЁеӯҰд№ з®—жі•зҡ„дёҖз§ҚпјҢе…¶жЁЎејҸд№ҹжҳҜи®©жҷәиғҪдҪ“еңЁвҖңи®ӯз»ғвҖқдёӯеӯҰеҲ°вҖңз»ҸйӘҢвҖқпјҢд»Ҙе®һзҺ°з»ҷе®ҡзҡ„д»»еҠЎгҖӮдҪҶдёҚеҗҢдәҺзӣ‘зқЈеӯҰд№ дёҺйқһзӣ‘зқЈеӯҰд№ пјҢеңЁејәеҢ–еӯҰд№ зҡ„жЎҶжһ¶дёӯпјҢжҲ‘们жӣҙдҫ§йҮҚйҖҡиҝҮжҷәиғҪдҪ“дёҺзҺҜеўғзҡ„дәӨдә’жқҘеӯҰд№ гҖӮйҖҡеёёеңЁзӣ‘зқЈеӯҰд№ е’Ңйқһзӣ‘зқЈеӯҰд№ д»»еҠЎдёӯпјҢжҷәиғҪдҪ“еҫҖеҫҖйңҖиҰҒйҖҡиҝҮз»ҷе®ҡзҡ„и®ӯз»ғйӣҶпјҢиҫ…д№Ӣд»Ҙж—ўе®ҡзҡ„и®ӯз»ғзӣ®ж ҮпјҲеҰӮжңҖе°ҸеҢ–жҚҹеӨұеҮҪж•°пјүпјҢйҖҡиҝҮз»ҷе®ҡзҡ„еӯҰд№ з®—жі•жқҘе®һзҺ°иҝҷдёҖзӣ®ж ҮгҖӮ然иҖҢеңЁејәеҢ–еӯҰд№ дёӯпјҢжҷәиғҪдҪ“еҲҷжҳҜйҖҡиҝҮе…¶дёҺзҺҜеўғдәӨдә’еҫ—еҲ°зҡ„еҘ–еҠұиҝӣиЎҢеӯҰд№ гҖӮиҝҷдёӘзҺҜеўғеҸҜд»ҘжҳҜиҷҡжӢҹзҡ„пјҲеҰӮиҷҡжӢҹзҡ„иҝ·е®«пјүпјҢд№ҹеҸҜд»ҘжҳҜзңҹе®һзҡ„пјҲиҮӘеҠЁй©ҫ驶жұҪиҪҰеңЁзңҹе®һйҒ“и·ҜдёҠ收йӣҶж•°жҚ®пјүгҖӮ
еңЁејәеҢ–еӯҰд№ дёӯжңүдә”дёӘж ёеҝғз»„жҲҗйғЁеҲҶпјҢе®ғ们еҲҶеҲ«жҳҜпјҡзҺҜеўғпјҲEnvironmentпјүгҖҒжҷәиғҪдҪ“пјҲAgentпјүгҖҒзҠ¶жҖҒпјҲStateпјүгҖҒеҠЁдҪңпјҲActionпјүе’ҢеҘ–еҠұпјҲRewardпјүгҖӮеңЁжҹҗдёҖж—¶й—ҙиҠӮзӮ№tпјҡ
жҷәиғҪдҪ“еңЁд»ҺзҺҜеўғдёӯж„ҹзҹҘе…¶жүҖеӨ„зҡ„зҠ¶жҖҒ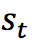
жҷәиғҪдҪ“ж №жҚ®жҹҗдәӣеҮҶеҲҷйҖүжӢ©еҠЁдҪң 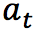
зҺҜеўғж №жҚ®жҷәиғҪдҪ“йҖүжӢ©зҡ„еҠЁдҪңпјҢеҗ‘жҷәиғҪдҪ“еҸҚйҰҲеҘ–еҠұ 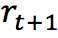
йҖҡиҝҮеҗҲзҗҶзҡ„еӯҰд№ з®—жі•пјҢжҷәиғҪдҪ“е°ҶеңЁиҝҷж ·зҡ„й—®йўҳи®ҫзҪ®дёӢпјҢжҲҗеҠҹеӯҰеҲ°дёҖдёӘеңЁзҠ¶жҖҒ йҖүжӢ©еҠЁдҪң зҡ„зӯ–з•Ҙ гҖӮ
1.2 и®Ўз®—QеҖј
еңЁжҲ‘们зҡ„йЎ№зӣ®дёӯпјҢжҲ‘们иҰҒе®һзҺ°еҹәдәҺ Q-Learning зҡ„ејәеҢ–еӯҰд№ з®—жі•гҖӮQ-Learning жҳҜдёҖдёӘеҖјиҝӯд»ЈпјҲValue Iterationпјүз®—жі•гҖӮдёҺзӯ–з•Ҙиҝӯд»ЈпјҲPolicy Iterationпјүз®—жі•дёҚеҗҢпјҢеҖјиҝӯд»Јз®—жі•дјҡи®Ўз®—жҜҸдёӘвҖқзҠ¶жҖҒвҖңжҲ–жҳҜвҖқзҠ¶жҖҒ-еҠЁдҪңвҖңзҡ„еҖјпјҲValueпјүжҲ–жҳҜж•Ҳз”ЁпјҲUtilityпјүпјҢ然еҗҺеңЁжү§иЎҢеҠЁдҪңзҡ„ж—¶еҖҷпјҢдјҡи®ҫжі•жңҖеӨ§еҢ–иҝҷдёӘеҖјгҖӮеӣ жӯӨпјҢеҜ№жҜҸдёӘзҠ¶жҖҒеҖјзҡ„еҮҶзЎ®дј°и®ЎпјҢжҳҜжҲ‘们еҖјиҝӯд»Јз®—жі•зҡ„ж ёеҝғгҖӮйҖҡеёёжҲ‘们дјҡиҖғиҷ‘жңҖеӨ§еҢ–еҠЁдҪңзҡ„й•ҝжңҹеҘ–еҠұпјҢеҚідёҚд»…иҖғиҷ‘еҪ“еүҚеҠЁдҪңеёҰжқҘзҡ„еҘ–еҠұпјҢиҝҳдјҡиҖғиҷ‘еҠЁдҪңй•ҝиҝңзҡ„еҘ–еҠұгҖӮ
еңЁ Q-Learning з®—жі•дёӯпјҢжҲ‘们жҠҠиҝҷдёӘй•ҝжңҹеҘ–еҠұи®°дёә Q еҖјпјҢжҲ‘们дјҡиҖғиҷ‘жҜҸдёӘ вҖқзҠ¶жҖҒ-еҠЁдҪңвҖң зҡ„ Q еҖјпјҢе…·дҪ“иҖҢиЁҖпјҢе®ғзҡ„и®Ўз®—е…¬ејҸдёәпјҡ

д№ҹе°ұжҳҜеҜ№дәҺеҪ“еүҚзҡ„вҖңзҠ¶жҖҒ-еҠЁдҪңвҖқ 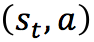 пјҢжҲ‘们иҖғиҷ‘жү§иЎҢеҠЁдҪң
пјҢжҲ‘们иҖғиҷ‘жү§иЎҢеҠЁдҪң 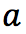 еҗҺзҺҜеўғз»ҷжҲ‘们зҡ„еҘ–еҠұ
еҗҺзҺҜеўғз»ҷжҲ‘们зҡ„еҘ–еҠұ пјҢд»ҘеҸҠжү§иЎҢеҠЁдҪң
пјҢд»ҘеҸҠжү§иЎҢеҠЁдҪң 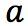 еҲ°иҫҫ
еҲ°иҫҫ 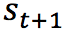 еҗҺпјҢжү§иЎҢд»»ж„ҸеҠЁдҪңиғҪеӨҹиҺ·еҫ—зҡ„жңҖеӨ§зҡ„QеҖј
еҗҺпјҢжү§иЎҢд»»ж„ҸеҠЁдҪңиғҪеӨҹиҺ·еҫ—зҡ„жңҖеӨ§зҡ„QеҖј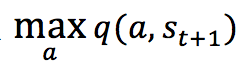 пјҢ
пјҢ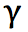 дёәжҠҳжүЈеӣ еӯҗгҖӮ
дёәжҠҳжүЈеӣ еӯҗгҖӮ
дёҚиҝҮдёҖиҲ¬ең°пјҢжҲ‘们дҪҝз”Ёжӣҙдёәдҝқе®Ҳең°жӣҙж–° Q иЎЁзҡ„ж–№жі•пјҢеҚіеј•е…ҘжқҫејӣеҸҳйҮҸ alphaпјҢжҢүеҰӮдёӢзҡ„е…¬ејҸиҝӣиЎҢжӣҙж–°пјҢдҪҝеҫ— Q иЎЁзҡ„иҝӯд»ЈеҸҳеҢ–жӣҙдёәе№ізј“гҖӮ
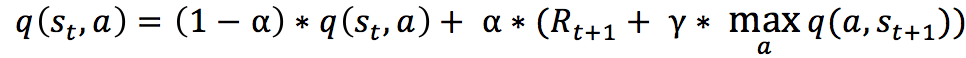
ж №жҚ®е·ІзҹҘжқЎд»¶жұӮ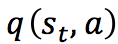 гҖӮ
гҖӮ
е·ІзҹҘпјҡеҰӮдёҠеӣҫпјҢжңәеҷЁдәәдҪҚдәҺ s1пјҢиЎҢеҠЁдёә uпјҢиЎҢеҠЁиҺ·еҫ—зҡ„еҘ–еҠұдёҺйўҳзӣ®зҡ„й»ҳи®Өи®ҫзҪ®зӣёеҗҢгҖӮеңЁ s2 дёӯжү§иЎҢеҗ„еҠЁдҪңзҡ„ Q еҖјдёәпјҡu: -24пјҢr: -13пјҢd: -0.29гҖҒl: +40пјҢОіеҸ–0.9гҖӮ
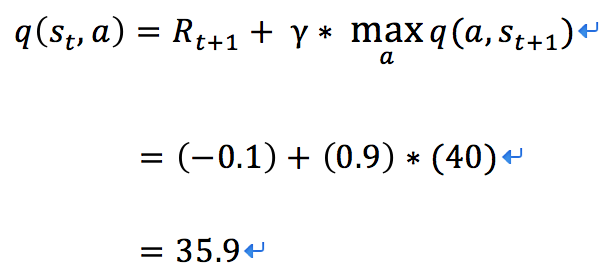
1.3 еҰӮдҪ•йҖүжӢ©еҠЁдҪң
еңЁејәеҢ–еӯҰд№ дёӯпјҢгҖҢжҺўзҙў-еҲ©з”ЁгҖҚй—®йўҳжҳҜйқһеёёйҮҚиҰҒзҡ„й—®йўҳгҖӮе…·дҪ“жқҘиҜҙпјҢж №жҚ®дёҠйқўзҡ„е®ҡд№үпјҢжҲ‘们дјҡе°ҪеҸҜиғҪең°и®©жңәеҷЁдәәеңЁжҜҸж¬ЎйҖүжӢ©жңҖдјҳзҡ„еҶізӯ–пјҢжқҘжңҖеӨ§еҢ–й•ҝжңҹеҘ–еҠұгҖӮдҪҶжҳҜиҝҷж ·еҒҡжңүеҰӮдёӢзҡ„ејҠз«Ҝпјҡ
еӣ жӯӨжҲ‘们йңҖиҰҒдёҖз§ҚеҠһжі•пјҢжқҘи§ЈеҶіеҰӮдёҠзҡ„й—®йўҳпјҢеўһеҠ жңәеҷЁдәәзҡ„жҺўзҙўгҖӮз”ұжӯӨжҲ‘们иҖғиҷ‘дҪҝз”Ё epsilon-greedy з®—жі•пјҢеҚіеңЁе°ҸиҪҰйҖүжӢ©еҠЁдҪңзҡ„ж—¶еҖҷпјҢд»ҘдёҖйғЁеҲҶзҡ„жҰӮзҺҮйҡҸжңәйҖүжӢ©еҠЁдҪңпјҢд»ҘдёҖйғЁеҲҶзҡ„жҰӮзҺҮжҢүз…§жңҖдјҳзҡ„ Q еҖјйҖүжӢ©еҠЁдҪңгҖӮеҗҢж—¶пјҢиҝҷдёӘйҖүжӢ©йҡҸжңәеҠЁдҪңзҡ„жҰӮзҺҮеә”еҪ“йҡҸзқҖи®ӯз»ғзҡ„иҝҮзЁӢйҖҗжӯҘеҮҸе°ҸгҖӮ
еңЁеҰӮдёӢзҡ„д»Јз Ғеқ—дёӯпјҢе®һзҺ° epsilon-greedy з®—жі•зҡ„йҖ»иҫ‘пјҢ并иҝҗиЎҢжөӢиҜ•д»Јз ҒгҖӮ
import random
import operator
actions = ['u','r','d','l']
qline = {'u':1.2, 'r':-2.1, 'd':-24.5, 'l':27}
epsilon = 0.3 # д»Ҙ0.3зҡ„жҰӮзҺҮиҝӣиЎҢйҡҸжңәйҖүжӢ©
def choose_action(epsilon):
action = None
if random.uniform(0,1.0) <= epsilon: # д»ҘжҹҗдёҖжҰӮзҺҮ
action = random.choice(actions)# е®һзҺ°еҜ№еҠЁдҪңзҡ„йҡҸжңәйҖүжӢ©
else:
action = max(qline.items(), key=operator.itemgetter(1))[0] # еҗҰеҲҷйҖүжӢ©е…·жңүжңҖеӨ§ Q еҖјзҡ„еҠЁдҪң
return action
range(100): res += choose_action(epsilon) print(res) res = '' for i in range(100): res += choose_action(epsilon) print(res) ldllrrllllrlldlldllllllllllddulldlllllldllllludlldllllluudllllllulllllllllllullullllllllldlulllllrlr
Section 2 д»Јз Ғе®һзҺ°
2.1 Maze зұ»зҗҶи§Ј
жҲ‘们йҰ–е…Ҳеј•е…ҘдәҶиҝ·е®«зұ» MazeпјҢиҝҷжҳҜдёҖдёӘйқһеёёејәеӨ§зҡ„еҮҪж•°пјҢе®ғиғҪеӨҹж №жҚ®дҪ зҡ„иҰҒжұӮйҡҸжңәеҲӣе»әдёҖдёӘиҝ·е®«пјҢжҲ–иҖ…ж №жҚ®жҢҮе®ҡзҡ„ж–Ү件пјҢиҜ»е…ҘдёҖдёӘиҝ·е®«ең°еӣҫдҝЎжҒҜгҖӮ
Maze("file_name") ж №жҚ®жҢҮе®ҡж–Ү件еҲӣе»әиҝ·е®«пјҢжҲ–иҖ…дҪҝз”Ё Maze(maze_size=(height, width))жқҘйҡҸжңәз”ҹжҲҗдёҖдёӘиҝ·е®«гҖӮtrap number еҸӮж•°пјҢеңЁеҲӣе»әиҝ·е®«зҡ„ж—¶еҖҷпјҢи®ҫе®ҡиҝ·е®«дёӯйҷ·йҳұзҡ„ж•°йҮҸгҖӮg=Maze("xx.txt")пјҢйӮЈд№ҲзӣҙжҺҘиҫ“е…Ҙ g еҚіеҸҜгҖӮеңЁеҰӮдёӢзҡ„д»Јз Ғеқ—дёӯпјҢеҲӣе»әдҪ зҡ„иҝ·е®«е№¶еұ•зӨәгҖӮ
from Maze import Maze %matplotlib inline %confer InlineBackend.figure_format = 'retina' ## to-do: еҲӣе»әиҝ·е®«е№¶еұ•зӨә g=Maze(maze_size=(6,8), trap_number=1) g Maze of size (12, 12 )

дҪ еҸҜиғҪе·Із»ҸжіЁж„ҸеҲ°пјҢеңЁиҝ·е®«дёӯжҲ‘们已з»Ҹй»ҳи®Өж”ҫзҪ®дәҶдёҖдёӘжңәеҷЁдәәгҖӮе®һйҷ…дёҠпјҢжҲ‘们дёәиҝ·е®«й…ҚзҪ®дәҶзӣёеә”зҡ„ APIпјҢжқҘеё®еҠ©жңәеҷЁдәәзҡ„移еҠЁдёҺж„ҹзҹҘгҖӮе…¶дёӯдҪ йҡҸеҗҺдјҡдҪҝз”Ёзҡ„дёӨдёӘ API дёә maze.sense_robot() еҸҠ maze.move_robot() гҖӮ
maze.sense_robot() дёәдёҖдёӘж— еҸӮж•°зҡ„еҮҪж•°пјҢиҫ“еҮәжңәеҷЁдәәеңЁиҝ·е®«дёӯзӣ®еүҚзҡ„дҪҚзҪ®гҖӮmaze.move_robot(direction) еҜ№иҫ“е…Ҙзҡ„移еҠЁж–№еҗ‘пјҢ移еҠЁжңәеҷЁдәәпјҢ并иҝ”еӣһеҜ№еә”еҠЁдҪңзҡ„еҘ–еҠұеҖјгҖӮйҡҸжңә移еҠЁжңәеҷЁдәәпјҢ并记еҪ•дёӢиҺ·еҫ—зҡ„еҘ–еҠұпјҢеұ•зӨәеҮәжңәеҷЁдәәжңҖеҗҺзҡ„дҪҚзҪ®гҖӮ
rewards = [] ## еҫӘзҺҜгҖҒйҡҸжңә移еҠЁжңәеҷЁдәә10ж¬ЎпјҢи®°еҪ•дёӢеҘ–еҠұ for i in range(10): res = g.move_robot(random. Choice(actions)) rewards.append(res) ## иҫ“еҮәжңәеҷЁдәәжңҖеҗҺзҡ„дҪҚзҪ® print(g.sense_robot()) ## жү“еҚ°иҝ·е®«пјҢи§ӮеҜҹжңәеҷЁдәәдҪҚзҪ® g (0,9)

2.2 Robot зұ»е®һзҺ°
Robot зұ»жҳҜжҲ‘们йңҖиҰҒйҮҚзӮ№е®һзҺ°зҡ„йғЁеҲҶгҖӮеңЁиҝҷдёӘзұ»дёӯпјҢжҲ‘们йңҖиҰҒе®һзҺ°иҜёеӨҡеҠҹиғҪпјҢд»ҘдҪҝеҫ—жҲ‘们жҲҗеҠҹе®һзҺ°дёҖдёӘејәеҢ–еӯҰд№ жҷәиғҪдҪ“гҖӮжҖ»дҪ“жқҘиҜҙпјҢд№ӢеүҚжҲ‘们жҳҜдәәдёәең°еңЁзҺҜеўғдёӯ移еҠЁдәҶжңәеҷЁдәәпјҢдҪҶжҳҜзҺ°еңЁйҖҡиҝҮе®һзҺ° Robot иҝҷдёӘзұ»пјҢжңәеҷЁдәәе°ҶдјҡиҮӘе·ұ移еҠЁгҖӮйҖҡиҝҮе®һзҺ°еӯҰд№ еҮҪж•°пјҢRobot зұ»е°ҶдјҡеӯҰд№ еҲ°еҰӮдҪ•йҖүжӢ©жңҖдјҳзҡ„еҠЁдҪңпјҢ并且жӣҙж–°ејәеҢ–еӯҰд№ дёӯеҜ№еә”зҡ„еҸӮж•°гҖӮ
йҰ–е…Ҳ Robot жңүеӨҡдёӘиҫ“е…ҘпјҢе…¶дёӯ alpha=0.5, gamma=0.9, epsilon0=0.5 иЎЁеҫҒејәеҢ–еӯҰд№ зӣёе…ізҡ„еҗ„дёӘеҸӮж•°зҡ„й»ҳи®ӨеҖјпјҢиҝҷдәӣеңЁд№ӢеүҚдҪ е·Із»ҸдәҶи§ЈеҲ°пјҢMaze еә”дёәжңәеҷЁдәәжүҖеңЁиҝ·е®«еҜ№иұЎгҖӮ
йҡҸеҗҺи§ӮеҜҹ Robot.update еҮҪж•°пјҢе®ғжҢҮжҳҺдәҶеңЁжҜҸж¬Ўжү§иЎҢеҠЁдҪңж—¶пјҢRobot йңҖиҰҒжү§иЎҢзҡ„зЁӢеәҸгҖӮжҢүз…§иҝҷдәӣзЁӢеәҸпјҢеҗ„дёӘеҮҪж•°зҡ„еҠҹиғҪд№ҹе°ұжҳҺдәҶдәҶгҖӮ
иҝҗиЎҢеҰӮдёӢд»Јз ҒжЈҖжҹҘж•ҲжһңпјҲи®°еҫ—е°Ҷ maze еҸҳйҮҸдҝ®ж”№дёәдҪ еҲӣе»әиҝ·е®«зҡ„еҸҳйҮҸеҗҚпјүгҖӮ
import random
import operator
class Robot(object):
def __init__(self, maze, alpha=0.5, gamma=0.9, epsilon0=0.5):
self. Maze = maze
self.valid_actions = self.maze.valid_actions
self.state = None
self.action = None
# Set Parameters of the Learning Robot
self.alpha = alpha
self.gamma = gamma
self.epsilon0 = epsilon0
self. Epsilon = epsilon0
self.t = 0
self.Qtable = {}
self. Reset()
def. reset(self):
"""
Reset the robot
"""
self.state = self.sense_state()
self.create_Qtable_line(self.state)
def. set status(self, learning=False, testing=False):
"""
Determine whether the robot is learning its q table, or
executing the testing procedure.
"""
self. Learning = learning
self.testing = testing
def. update_parameter(self):
"""
Some of the paramters of the q learning robot can be altered,
update these parameters when necessary.
"""
if self.testing:
# TODO 1. No random choice when testing
self. Epsilon = 0
else:
# TODO 2. Update parameters when learning
self. Epsilon *= 0.95
return self. Epsilon
def. sense_state(self):
"""
Get the current state of the robot. In this
"""
# TODO 3. Return robot's current state
return self.maze.sense_robot()
def. create_Qtable_line(self, state):
"""
Create the qtable with the current state
"""
# TODO 4. Create qtable with current state
# Our qtable should be a two level dict,
# Qtable[state] ={'u':xx, 'd':xx, ...}
# If Qtable[state] already exits, then do
# not change it.
self.Qtable.setdefault(state, {a: 0.0 for a in self.valid_actions})
def. choose_action(self):
"""
Return an action according to given rules
"""
def. is_random_exploration():
# TODO 5. Return whether do random choice
# hint: generate a random number, and compare
# it with epsilon
return random.uniform(0, 1.0) <= self. Epsilon
if self. Learning:
if is_random_exploration():
# TODO 6. Return random choose aciton
return random. Choice(self.valid_actions)
else:
# TODO 7. Return action with highest q value
return max(self.Qtable[self.state].items(), key=operator.itemgetter(1))[0]
elif self.testing:
# TODO 7. choose action with highest q value
return max(self.Qtable[self.state].items(), key=operator.itemgetter(1))[0]
else:
# TODO 6. Return random choose aciton
return random. Choice(self.valid_actions)
def. update_Qtable(self, r, action, next_state):
"""
Update the qtable according to the given rule.
"""
if self. Learning:
# TODO 8. When learning, update the q table according
# to the given rules
self.Qtable[self.state][action] = (1 - self.alpha) * self.Qtable[self.state][action] + self.alpha * (
r + self.gamma * max(self.Qtable[next_state].values()))
def. update(self):
"""
Describle the procedure what to do when update the robot.
Called every time in every epoch in training or testing.
Return current action and reward.
"""
self.state = self.sense_state() # Get the current state
self.create_Qtable_line(self.state) # For the state, create q table line
action = self.choose_action() # choose action for this state
reward = self.maze.move_robot(action) # move robot for given action
next_state = self.sense_state() # get next state
self.create_Qtable_line(next_state) # create q table line for next state
if self. Learning and not self.testing:
self.update_Qtable(reward, action, next_state) # update q table
self.update_parameter() # update parameters
return action, reward
# from Robot import Robot
# g=Maze(maze_size=(6,12), trap_number=2)
g=Maze("test_world\maze_01.txt")
robot = Robot(g) # и®°еҫ—е°Ҷ maze еҸҳйҮҸдҝ®ж”№дёәдҪ еҲӣе»әиҝ·е®«зҡ„еҸҳйҮҸеҗҚ
robot.set_status(learning=True,testing=False)
print(robot.update())
g
пјҲ'd', -0.1пјү
Maze of size (12, 12)
2.3 з”Ё Runner зұ»и®ӯз»ғ Robot
еңЁе®ҢжҲҗдәҶдёҠиҝ°еҶ…е®№д№ӢеҗҺпјҢжҲ‘们е°ұеҸҜд»ҘејҖе§ӢеҜ№жҲ‘们 Robot иҝӣиЎҢи®ӯз»ғ并и°ғеҸӮдәҶгҖӮжҲ‘们еҮҶеӨҮдәҶеҸҲдёҖдёӘйқһеёёжЈ’зҡ„зұ» Runner пјҢжқҘе®һзҺ°ж•ҙдёӘи®ӯз»ғиҝҮзЁӢеҸҠеҸҜи§ҶеҢ–гҖӮдҪҝз”ЁеҰӮдёӢзҡ„д»Јз ҒпјҢдҪ еҸҜд»ҘжҲҗеҠҹеҜ№жңәеҷЁдәәиҝӣиЎҢи®ӯз»ғгҖӮ并且дҪ дјҡеңЁеҪ“еүҚж–Ү件еӨ№дёӯз”ҹжҲҗдёҖдёӘеҗҚдёә filename зҡ„и§Ҷйў‘пјҢи®°еҪ•дәҶж•ҙдёӘи®ӯз»ғзҡ„иҝҮзЁӢгҖӮйҖҡиҝҮи§ӮеҜҹиҜҘи§Ҷйў‘пјҢдҪ иғҪеӨҹеҸ‘зҺ°и®ӯз»ғиҝҮзЁӢдёӯзҡ„й—®йўҳпјҢ并且дјҳеҢ–дҪ зҡ„д»Јз ҒеҸҠеҸӮж•°гҖӮ
е°қиҜ•еҲ©з”ЁдёӢеҲ—д»Јз Ғи®ӯз»ғжңәеҷЁдәәпјҢ并иҝӣиЎҢи°ғеҸӮгҖӮеҸҜйҖүзҡ„еҸӮж•°еҢ…жӢ¬пјҡ
epochepsilon0 (epsilon еҲқеҖј)epsilon иЎ°еҮҸпјҲеҸҜд»ҘжҳҜзәҝжҖ§гҖҒжҢҮж•°иЎ°еҮҸпјҢеҸҜд»Ҙи°ғж•ҙиЎ°еҮҸзҡ„йҖҹеәҰпјүпјҢдҪ йңҖиҰҒеңЁ Robot.py дёӯи°ғж•ҙalphagammafrom Runner import Runner g = Maze(maze_size=maze_size,trap_number=trap_number) r = Robot(g,alpha=alpha, epsilon0=epsilon0, gamma=gamma) r.set_status(learning=True) runner = Runner(r, g) runner.run_training(epoch, display_direction=True) #runner.generate_movie(filename = "final1.mp4") # дҪ еҸҜд»ҘжіЁйҮҠиҜҘиЎҢд»Јз ҒпјҢеҠ еҝ«иҝҗиЎҢйҖҹеәҰпјҢдёҚиҝҮдҪ е°ұж— жі•и§ӮеҜҹеҲ°и§Ҷйў‘дәҶгҖӮ g
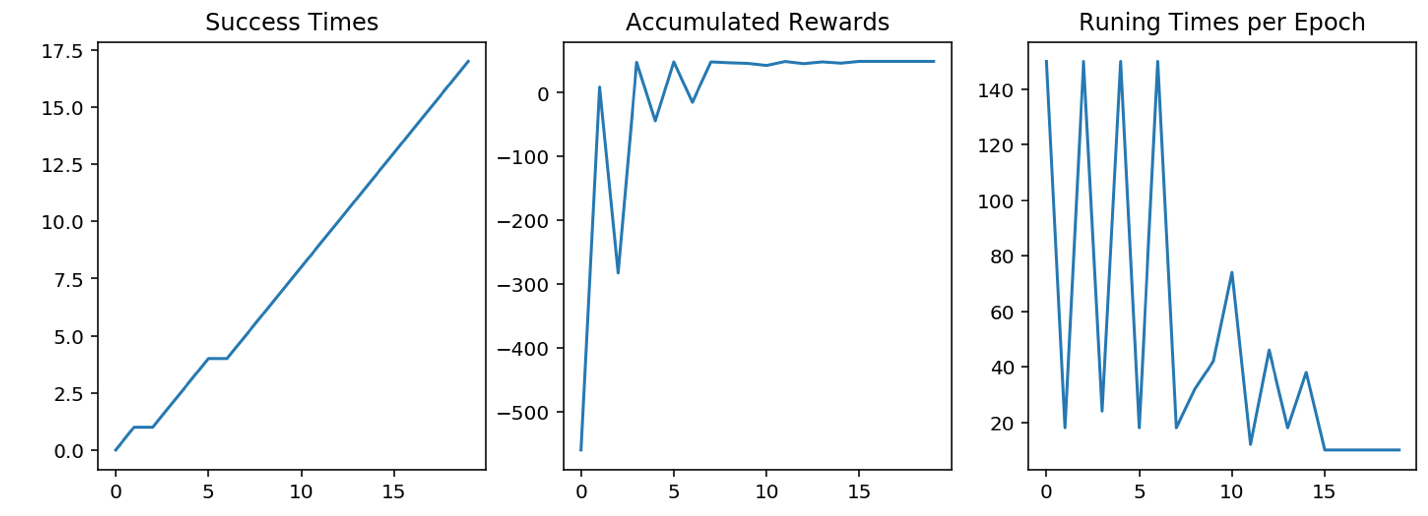
дҪҝз”Ё runner.plot_results() еҮҪж•°пјҢиғҪеӨҹжү“еҚ°жңәеҷЁдәәеңЁи®ӯз»ғиҝҮзЁӢдёӯзҡ„дёҖдәӣеҸӮж•°дҝЎжҒҜгҖӮ
дҪҝз”Ё runner.plot_results() иҫ“еҮәи®ӯз»ғз»“жһң
runner.plot_results()
д»ҘдёҠе°ұжҳҜжң¬ж–Үзҡ„е…ЁйғЁеҶ…е®№пјҢеёҢжңӣеҜ№еӨ§е®¶зҡ„еӯҰд№ жңүжүҖеё®еҠ©пјҢд№ҹеёҢжңӣеӨ§е®¶еӨҡеӨҡж”ҜжҢҒдәҝйҖҹдә‘гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ