您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要介绍了python与字符编码问题的示例分析,具有一定借鉴价值,感兴趣的朋友可以参考下,希望大家阅读完这篇文章之后大有收获,下面让小编带着大家一起了解一下。
故事零:编码的定义
我们从“SOS“(国际通用求助信号)开始,它的摩斯密码的编码是:
“…---…”,想一下为什么选用S、O、S来作为求救信号?因为它简单,容易辨别且不容易发错呀!
那么,字符编码就是:
´给定一系列字符,对每个字符赋予一个数值,用数值来代表对应的字符,这一数值就是字符的编码。例如,我们给字符'A'赋予数值0x41,则0x41就是字符'A'的编码。字符编码是字符的表现、储存方式。
字符编码需要处理两件事:
(1)规定一个字符集中的字符由多少个字节表示;
(2)制定该字符集的字符编码表,即该字符集中每个字符对应的(二进制)值。
字符集:´给定一系列字符并赋予对应的编码后,所有这些字符和编码对组成的集合就是字符集。´比如,给定字符列表为{'A','B'}时,{'A'=>0x41,‘B'=>0x42}就是一个字符集。
常见字符集有:
ASCII
GB2312
GBK
GB18030
Big5
Unicode
一张图总结:

故事一:Python2与Python3的字符串类型?
python2中的字符串有str和unicode类型,而python3中字符串只有unicode类型。比如 ‘你好'是str字符串,而 u'你好'则是unicode字符串。
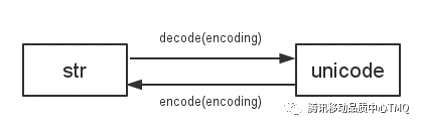
故事二:decode()和encode()傻傻分不清?
decode() 是将str字符串转化为unicode字符串;encode() 是将unicode字符串转化为str字符串。所以要做一些编码的转换通常是以unicode作为中间编码做转换。如name.decode(“GB2312”)表示将GB2312编码的字符串name转换成unicode编码,name.encode(“GB2312”)表示将unicode字符串name转换成GB2312编码。
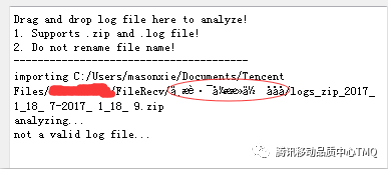
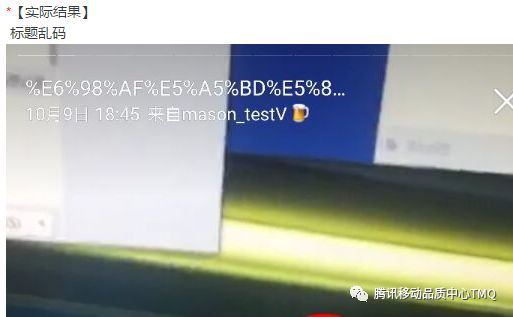
故事三:UnicodeEncodeError: ‘ascii' codec can't encode character?
我们先看看两张图,是不是很烦?
下面我们看个例子:

当用u'字符串'申明这个字符串变量时就指明了该字符串是使用unicode字符编码。当要将unicode字符串转换为str字符串或者写入文件时,python2默认使用ASCII 码保存数据,而ASCII 码无法识别大于128 的字符,于是报了上面的错误。
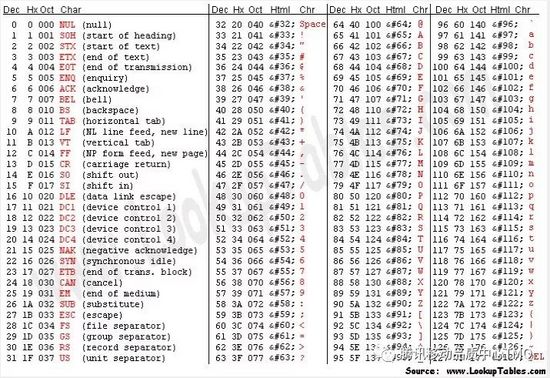
附ASCII码表:
故事四:unicode是什么?
unicode可以看做一个终极的字符编码方法,它给出了地球上常用字符的二进制映射,而且所有的二进制字符串唯一地表示一个字符。但是,unicode只给出了字符和二进制串的对应关系,并没有给出存储形式。而不同字符所占用的存储空间可能不同,比如ASCII 在unicode中只占用了一个字节即可,而常用汉字在unicode中需要占用两个字节,还有一些罗马字符可能需要三个或以上字节。如果直接存储的话可能导致无法分割字符串,也无法正确解码出字符。
故事五:UTF-8横空出世?
互联网的普及,强烈要求出现一种统一的编码方式。这时候UTF-8 出场。UTF-8 是unicode在计算机中的一种实现方式。UTF-8是一种变长编码,每个字符占1-4 个字节。UTF-8 将字节分为数值位和标识位,数值位真正保存字符编码数值,标识位表示这个字节是属于哪个字符的、或者该字符占多少个字节。UTF-8 编码方法:
单字节,首位为标识位0;多字节字符首字节标志位1··10开头,字符占多少字节则有多少1,其他字节标识位10开头;
§ 单字节字符: 0xxxxxxx (以0 开头标志位,数值位用x 表示)
§ 双字节字符: 110xxxxx 10xxxxxx
§ 三字节字符: 1110xxxx 10xxxxxx 10xxxxxx
§ 四字节字符: 11110xxx 10xxxxxx 10xxxxxx10xxxxxx
unicode变为UTF-8 编码非常简单,unicode二进制按照从低到高,填充UTF-8的数值位,除去那些不真正表示数值的标识位(字节开头的0,10,110,1110和11110),顺序也是由低到高。以汉字“你”为例,可见它的unicode编码为“4f60”(01001111 01100000)。

从“你”的unicode值范围可以看到需要三个字节,接着从低位字节向高位字节填充得到“你”的UTF-8 编码(高位没有填充完则用0补充)。

可以看到将UTF-8 用于标记位(红色)的位去掉,合并可以得到原始的unicode码。
故事六:"unicode-escape"与"unicode-unescape"
“\u”是表示unicode的转义字符,用\uxxxx这种方式表示unicode字符就是”unicode-escape”方式。说人话:´一句话:xxx.decode(“unicode-escape”)相当于把xxx解码成unicode类型并返回。
而用”%uxxxx”的方式表示unicode字符,这种方式就是”unicode-unescape”,常用于javascript。
番外故事七:读了那么多年书,你真的了解“全半角”?
全角---指一个字符占用两个标准字符位置。
半角---指一字符占用一个标准的字符位置。
引申:写程序时双引号、冒号、小括号等为啥如此纠结?
--我国专家在制定GB2312字符集时,ASCII里本来就有的数字、标点、字母都统统重新编了两个字节长的编码。
感谢你能够认真阅读完这篇文章,希望小编分享的“python与字符编码问题的示例分析”这篇文章对大家有帮助,同时也希望大家多多支持亿速云,关注亿速云行业资讯频道,更多相关知识等着你来学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。