жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
еҰӮжһңдҪ еңЁзҲ¬иҷ«иҝҮзЁӢдёӯжңүйҒҮеҲ°вҖңжӮЁзҡ„иҜ·жұӮеӨӘиҝҮйў‘з№ҒпјҢиҜ·зЁҚеҗҺеҶҚиҜ•вҖқпјҢжҲ–иҖ…иҜҙд»Јз Ғе®Ңе…ЁжӯЈзЎ®пјҢеҸҜжҳҜзҲ¬иҷ«иҝҮзЁӢдёӯзӘҒ然е°ұи®ҝй—®дёҚдәҶпјҢйӮЈд№ҲжҒӯе–ңдҪ пјҢдҪ зҡ„зҲ¬иҷ«иў«еҜ№ж–№иҜҶз ҙдәҶпјҢиҪ»еҲҷз»ҷдәҲеҸӢеҘҪжҸҗзӨәиӯҰе‘ҠпјҢдёҘйҮҚзҡ„еҸҜиғҪдјҡеҜ№дҪ зҡ„ipиҝӣиЎҢе°ҒзҰҒпјҢжүҖд»Ҙд»ЈзҗҶipйӮЈе°ұе°ӨдёәйҮҚиҰҒдәҶгҖӮд»ҠеӨ©жҲ‘们е°ұжқҘи°ҲдёҖдёӢд»ЈзҗҶIPпјҢеҺ»и§ЈеҶізҲ¬иҷ«иў«е°Ғзҡ„й—®йўҳгҖӮ
зҪ‘дёҠжңүи®ёеӨҡд»ЈзҗҶipпјҢе…Қиҙ№зҡ„гҖҒд»ҳиҙ№зҡ„гҖӮеӨ§еӨҡж•°е…¬еҸёзҲ¬иҷ«дјҡд№°иҝҷдәӣдё“дёҡзүҲпјҢеҜ№дәҺжҷ®йҖҡдәәжқҘиҜҙпјҢе…Қиҙ№зҡ„еҹәжң¬ж»Ўи¶іжҲ‘们йңҖиҰҒдәҶпјҢдёҚиҝҮе…Қиҙ№жңүдёҖдёӘејҠз«ҜпјҢж—¶ж•ҲжҖ§дёҚејәпјҢдёҚзЁіе®ҡпјҢжүҖд»ҘжҲ‘们е°ұйңҖиҰҒеҜ№йҮҮйӣҶзҡ„ipиҝӣиЎҢдёҖдёӘз®ҖеҚ•зҡ„йӘҢиҜҒгҖӮ
1.зӣ®ж ҮйҮҮйӣҶ
жң¬ж–Үдё»иҰҒй’ҲеҜ№иҘҝеҲәд»ЈзҗҶпјҢиҝҷдёӘзҪ‘з«ҷеҫҲж—©д№ӢеүҚз”ЁиҝҮпјҢдёҚиҝҮйӮЈдёӘж—¶еҖҷе®ғиҝҳжҸҗдҫӣе…Қиҙ№зҡ„apiпјҢзҺ°еңЁapiжҡӮдёҚжҸҗдҫӣдәҶпјҢжҲ‘们е°ұеҶҷдёӘз®ҖеҚ•зҡ„зҲ¬иҷ«еҺ»йҮҮйӣҶгҖӮ
жү“ејҖиҘҝеҲәд»ЈзҗҶпјҢжңүеҮ дёӘйЎөйқўпјҢжһңж–ӯйҖүжӢ©й«ҳеҢҝд»ЈзҗҶгҖӮ
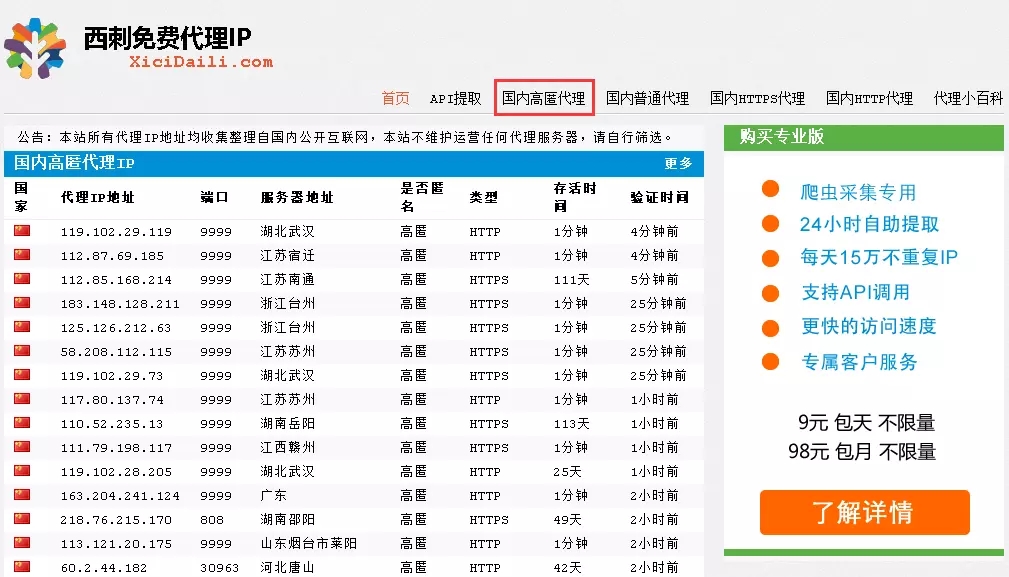
ChromeжөҸи§ҲеҷЁеҸій”®жЈҖжҹҘжҹҘзңӢnetworkпјҢдёҚйҡҫеҸ‘зҺ°пјҢжҜҸдёӘipең°еқҖйғҪеңЁtdж ҮзӯҫдёӯпјҢеҜ№дәҺжҲ‘们жқҘиҜҙе°ұз®ҖеҚ•и®ёеӨҡдәҶпјҢеҲқжӯҘзҡ„жғіжі•е°ұжҳҜиҺ·еҸ–жүҖжңүзҡ„ipпјҢ然еҗҺж ЎйӘҢеҸҜз”ЁжҖ§пјҢдёҚеҸҜз”Ёе°ұеү”йҷӨгҖӮ

е®ҡд№үеҢ№й…Қ规еҲҷ
import re ip_compile = re.compile(r'<td>(\d+\.\d+\.\d+\.\d+)</td>') # еҢ№й…ҚIP port_compile = re.compile(r'<td>(\d+)</td>') # еҢ№й…Қз«ҜеҸЈ
2.ж ЎйӘҢ иҝҷйҮҢжҲ‘дҪҝз”Ёж·ҳе®қipең°еқҖеә“жЈҖйӘҢеҸҜз”ЁжҖ§
2.1гҖҒе…ідәҺж·ҳе®қIPең°еқҖеә“
зӣ®еүҚжҸҗдҫӣзҡ„жңҚеҠЎеҢ…жӢ¬пјҡ
жҲ‘们зҡ„дјҳеҠҝпјҡ
2.2гҖҒжҺҘеҸЈиҜҙжҳҺ
иҜ·жұӮжҺҘеҸЈпјҲGETпјүпјҡ
ip.taobao.com/service/getвҖҰ
дҫӢпјҡhttp://ip.taobao.com/service/getIpInfo2.php?ip=111.177.181.44
е“Қеә”дҝЎжҒҜпјҡ
пјҲjsonж јејҸзҡ„пјүеӣҪ家 гҖҒзңҒпјҲиҮӘжІ»еҢәжҲ–зӣҙиҫ–еёӮпјүгҖҒеёӮпјҲеҺҝпјүгҖҒиҝҗиҗҘе•Ҷ
иҝ”еӣһж•°жҚ®ж јејҸпјҡ
{"code":0,"data":{"ip":"210.75.225.254","country":"\u4e2d\u56fd","area":"\u534e\u5317",
"region":"\u5317\u4eac\u5e02","city":"\u5317\u4eac\u5e02","county":"","isp":"\u7535\u4fe1",
"country_id":"86","area_id":"100000","region_id":"110000","city_id":"110000",
"county_id":"-1","isp_id":"100017"}}
е…¶дёӯcodeзҡ„еҖјзҡ„еҗ«д№үдёәпјҢ0пјҡжҲҗеҠҹпјҢ1пјҡеӨұиҙҘгҖӮ
жіЁж„ҸпјҡдёәдәҶдҝқйҡңжңҚеҠЎжӯЈеёёиҝҗиЎҢпјҢжҜҸдёӘз”ЁжҲ·зҡ„и®ҝй—®йў‘зҺҮйңҖе°ҸдәҺ10qpsгҖӮ
жҲ‘们е…ҲйҖҡиҝҮжөҸи§ҲеҷЁжөӢиҜ•дёҖдёӢ
иҫ“е…Ҙең°еқҖhttp://ip.taobao.com/service/getIpInfo2.php?ip=111.177.181.44

еҶҚж¬Ўиҫ“е…ҘдёҖдёӘең°еқҖhttp://ip.taobao.com/service/getIpInfo2.php?ip=112.85.168.98
д»Јз Ғж“ҚдҪң
import requests
check_api = "http://ip.taobao.com/service/getIpInfo2.php?ip="
api = check_api + ip
try:
response = requests.get(url=api, headers=api_headers, timeout=2)
print("ipпјҡ%s еҸҜз”Ё" % ip)
except Exception as e:
print("жӯӨip %s е·ІеӨұж•Ҳпјҡ%s" % (ip, e))
3.д»Јз Ғ
д»Јз ҒдёӯеҠ е…ҘдәҶејӮеёёеӨ„зҗҶпјҢе…¶е®һиҮӘе·ұжүӢеҶҷзҡ„demoеҶҷдёҚеҶҷејӮеёёеӨ„зҗҶйғҪеҸҜд»ҘпјҢдҪҶжҳҜдёәдәҶж–№дҫҝе…¶д»–дәәи°ғиҜ•пјҢе»әи®®еңЁеҸҜиғҪеҮәзҺ°ејӮеёёзҡ„ең°ж–№еҠ е…ҘејӮеёёеӨ„зҗҶгҖӮ
import requests
import re
import random
from bs4 import BeautifulSoup
ua_list = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.75 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36",
"Mozilla / 5.0(Windows NT 6.1;WOW64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 45.0.2454.101Safari / 537.36"
]
def ip_parse_xici(page):
"""
:param page: йҮҮйӣҶзҡ„йЎөж•°
:return:
"""
ip_list = []
for pg in range(1, int(page)):
url = 'http://www.xicidaili.com/nn/' + str(pg)
user_agent = random.choice(ua_list)
my_headers = {
'Accept': 'text/html, application/xhtml+xml, application/xml;',
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Referer': 'http: // www.xicidaili.com/nn',
'User-Agent': user_agent
}
try:
r = requests.get(url, headers=my_headers)
soup = BeautifulSoup(r.text, 'html.parser')
except requests.exceptions.ConnectionError:
print('ConnectionError')
else:
data = soup.find_all('td')
# е®ҡд№үIPе’Ңз«ҜеҸЈPattern规еҲҷ
ip_compile = re.compile(r'<td>(\d+\.\d+\.\d+\.\d+)</td>') # еҢ№й…ҚIP
port_compile = re.compile(r'<td>(\d+)</td>') # еҢ№й…Қз«ҜеҸЈ
ips = re.findall(ip_compile, str(data)) # иҺ·еҸ–жүҖжңүIP
ports = re.findall(port_compile, str(data)) # иҺ·еҸ–жүҖжңүз«ҜеҸЈ
check_api = "http://ip.taobao.com/service/getIpInfo2.php?ip="
for i in range(len(ips)):
if i < len(ips):
ip = ips[i]
api = check_api + ip
api_headers = {
'User-Agent': user_agent
}
try:
response = requests.get(url=api, headers=api_headers, timeout=2)
print("ipпјҡ%s еҸҜз”Ё" % ip)
except Exception as e:
print("жӯӨip %s е·ІеӨұж•Ҳпјҡ%s" % (ip, e))
del ips[i]
del ports[i]
ips_usable = ips
ip_list += [':'.join(n) for n in zip(ips_usable, ports)] # еҲ—иЎЁз”ҹжҲҗејҸ
print('第{}йЎөipйҮҮйӣҶе®ҢжҲҗ'.format(pg))
print(ip_list)
if __name__ == '__main__':
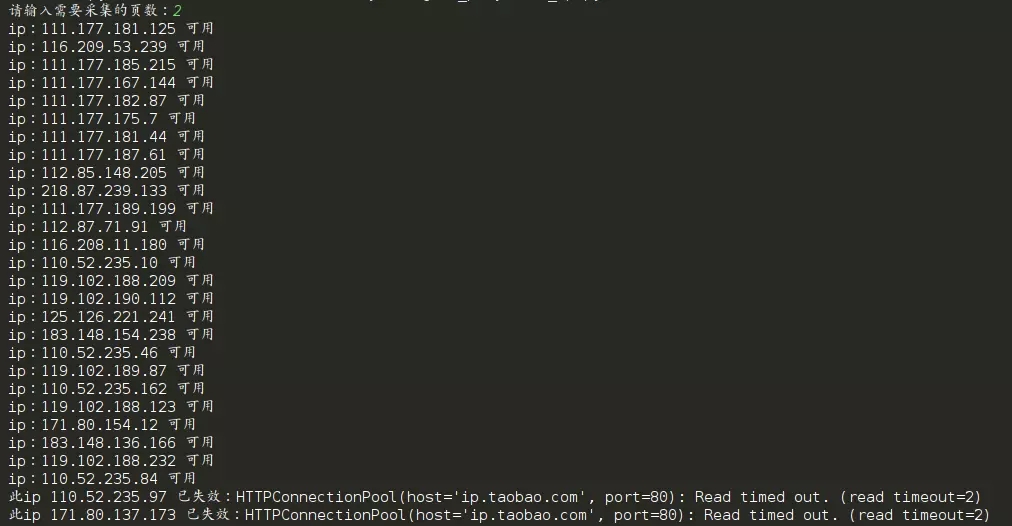
xici_pg = input("иҜ·иҫ“е…ҘйңҖиҰҒйҮҮйӣҶзҡ„йЎөж•°пјҡ")
ip_parse_xici(page=xici_pg)
иҝҗиЎҢд»Јз Ғпјҡ
4.дёәдҪ зҡ„зҲ¬иҷ«еҠ е…Ҙд»ЈзҗҶip
е»әи®®еӨ§е®¶еҸҜд»ҘжҠҠйҮҮйӣҶзҡ„ipеӯҳе…Ҙж•°жҚ®еә“пјҢиҝҷж ·жҜҸж¬ЎзҲ¬иҷ«зҡ„ж—¶еҖҷзӣҙжҺҘи°ғз”ЁеҚіеҸҜпјҢйЎәдҫҝжҸҗдёҖдёӢд»Јз ҒдёӯжҖҺд№ҲеҠ е…Ҙд»ЈзҗҶipгҖӮ
import requests
url = 'www.baidu.com'
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36",
}
proxies = {
"http": "http://111.177.181.44:9999",
# "https": "https://111.177.181.44:9999",
}
res = requests.get(url=url, headers=headers, proxies=proxies)
еҘҪдәҶпјҢеҰҲеҰҲеҶҚд№ҹдёҚжӢ…еҝғжҲ‘зҲ¬иҷ«иў«е°ҒдәҶ
д»ҘдёҠжүҖиҝ°жҳҜе°Ҹзј–з»ҷеӨ§е®¶д»Ӣз»Қзҡ„зҲ¬иҷ«иў«е°Ғзҡ„й—®йўҳиҜҰи§Јж•ҙеҗҲпјҢеёҢжңӣеҜ№еӨ§е®¶жңүжүҖеё®еҠ©пјҢеҰӮжһңеӨ§е®¶жңүд»»дҪ•з–‘й—®иҜ·з»ҷжҲ‘з•ҷиЁҖпјҢе°Ҹзј–дјҡеҸҠж—¶еӣһеӨҚеӨ§е®¶зҡ„гҖӮеңЁжӯӨд№ҹйқһеёёж„ҹи°ўеӨ§е®¶еҜ№дәҝйҖҹдә‘зҪ‘з«ҷзҡ„ж”ҜжҢҒпјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ