жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
зӣ®зҡ„
дёӨе№ҙеүҚжӣҫдёәдәҶз§ҹжҲҝеҒҡиҝҮдёҖдёӘжүҫжҲҝжңәеҷЁдәә гҖҢзҲ¬еҸ–иұҶз“Јз§ҹжҲҝ并е®ҡж—¶жҺЁйҖҒеҲ°еҫ®дҝЎгҖҚпјҢз»ҙжҠӨдёҖж®өж—¶й—ҙеҗҺе°ұиҚ’еәҹдәҶгҖӮ
еҪ“ж—¶еӣ дёәд»Јз ҒжҜ”иҫғз®ҖеҚ•дёҖзӣҙжІЎејҖжәҗпјҢзҺ°еңЁжғіжғіиҜҙдёҚе®ҡејҖжәҗеҗҺд№ҹиғҪеё®еҠ©дёҖдәӣеҗҢеӯҰжӣҙеҘҪзҡ„жүҫеҲ°з§ҹжҲҝдҝЎжҒҜпјҢжүҖд»Ҙз®ҖеҚ•ж•ҙзҗҶеҗҺпјҢејҖжәҗеҲ° githubпјҢең°еқҖпјҡhttps://github.com/facert/zufang (жң¬ең°дёӢиҪҪ)
дёӢйқўжҳҜеҪ“ж—¶еҶҷзҡ„з®ҖеҚ•еҺҹзҗҶд»Ӣз»Қпјҡ
иә«еңЁеёқйғҪзҡ„дәәйғҪзҹҘйҒ“з§ҹжҲҝзҡ„еӣ°йҡҫпјҢжҜҸж¬ЎжүҫжҲҝйғҪжҳҜеҝғеҠӣдәӨзҳҒгҖӮе…¶дёӯиұҶз“Јз§ҹжҲҝе°Ҹз»„з®—жҳҜжҜ”иҫғйқ и°ұзҡ„жҲҝжәҗдәҶпјҢдҪҶжҳҜз”ұдәҺе°Ҹз»„дҝЎжҒҜз№ҒжқӮпјҢиҖҢдё”жІЎжңүжҗңзҙўзҡ„еҠҹиғҪпјҢжғіиҰҒе®һж—¶иҺ·еҸ–з§ҹжҲҝдҝЎжҒҜжҳҜ件еҫҲеӣ°йҡҫзҡ„дәӢжғ…пјҢжүҖд»ҘжңҖиҝ‘з»ҷиҮӘе·ұжҢ–дәҶдёӘеқ‘пјҢеҒҡдёӘеҫ®дҝЎжүҫжҲҝжңәеҷЁдәәпјҢе…ҲзңӢеӨ§жҰӮж•Ҳжһңеҗ§пјҢи§ҒдёӢеӣҫпјҡ
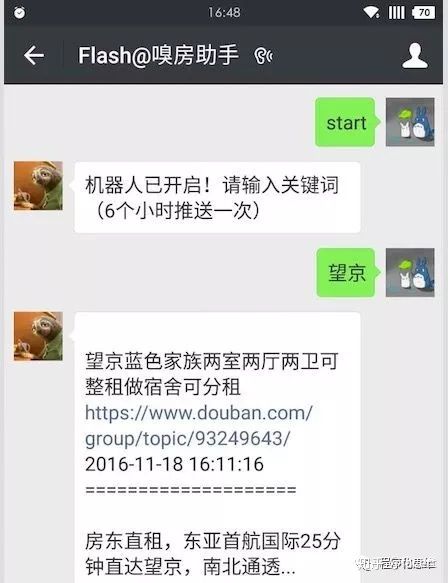

е®һзҺ°
иҜҙдёӢеӨ§жҰӮзҡ„жҠҖжңҜе®һзҺ°еҗ§пјҢйҰ–е…ҲжҳҜ scrapy зҲ¬иҷ«еҜ№дәҺиұҶз“ЈеҢ—дә¬з§ҹжҲҝзҡ„е°Ҹз»„е®һж—¶зҲ¬еҸ–пјҢ并еҒҡдәҶе…Ёж–ҮжЈҖзҙўпјҢеҜ№ title, description дҪҝз”Ё jieba е’Ң whoosh иҝӣиЎҢдәҶеҲҶиҜҚе’Ңзҙўеј•пјҢеҒҡжҲҗ apiгҖӮжҺҘдёӢжқҘе°ұжҳҜеә”з”Ёзҡ„жҺҘе…ҘпјҢзҪ‘дёҠжңүеҫ®дҝЎжңәеҷЁдәәзҡ„ејҖжәҗ [wxBot](http://github.com/liuwons/wxBo)пјҢжүҖд»ҘеҜ№е®ғиҝӣиЎҢдәҶдҝ®ж”№, е®һзҺ°дәҶе®ҡж—¶жҺЁйҖҒе’ҢжҢҒд№…еҢ–гҖӮжңҖеҗҺйЎәдҫҝжҠҠе…¬дј—еҸ·д№ҹеҒҡдәҶеҗҢж ·зҡ„еҠҹиғҪпјҢж”ҜжҢҒе®һж—¶з§ҹжҲҝдҝЎжҒҜжҗңзҙўгҖӮ
йғЁеҲҶд»Јз Ғ
scrapy ж”ҜжҢҒиҮӘе®ҡд№ү pipelineпјҢиғҪеҫҲж–№дҫҝзҡ„е®һзҺ°ж•°жҚ®еҪ•е…Ҙзҡ„ж—¶еҖҷе®һж—¶з”ҹжҲҗзҙўеј•пјҢи§Ғ code:
class IndexPipeline(object):
def __init__(self, index):
self.index = index
@classmethod
def from_crawler(cls, crawler):
return cls(
index=crawler.settings.get('WHOOSH_INDEX', 'indexes')
)
def process_item(self, item, spider):
self.writer = AsyncWriter(get_index(self.index, zufang_schema))
create_time = datetime.datetime.strptime(item['create_time'], "%Y-%m-%d %H:%M:%S")
self.writer.update_document(
url=item['url'].decode('utf-8'),
title=item['title'],
description=item['description'],
create_time=create_time
)
self.writer.commit()
return item
жҗңзҙў api д»Јз ҒеҫҲз®ҖеҚ•пјҡ
def zufang_query(keywords, limit=100):
ix = get_index('indexes', zufang_schema)
content = ["title", "description"]
query = MultifieldParser(content, ix.schema).parse(keywords)
result_list = []
with ix.searcher() as searcher:
results = searcher.search(query, sortedby="create_time", reverse=True, limit=limit)
for i in results:
result_list.append({'url': i['url'], 'title': i['title'], 'create_time': i['create_time']})
return result_list
жҖ»з»“
д»ҘдёҠе°ұжҳҜиҝҷзҜҮж–Үз« зҡ„е…ЁйғЁеҶ…е®№дәҶпјҢеёҢжңӣжң¬ж–Үзҡ„еҶ…е®№еҜ№еӨ§е®¶зҡ„еӯҰд№ жҲ–иҖ…е·ҘдҪңе…·жңүдёҖе®ҡзҡ„еҸӮиҖғеӯҰд№ д»·еҖјпјҢи°ўи°ўеӨ§е®¶еҜ№дәҝйҖҹдә‘зҡ„ж”ҜжҢҒгҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ