жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚдәҶеҰӮдҪ•дҪҝз”ЁMySQLзі»з»ҹж•°жҚ®еә“еҒҡжҖ§иғҪиҙҹиҪҪиҜҠж–ӯпјҢе…·жңүдёҖе®ҡеҖҹйүҙд»·еҖјпјҢж„ҹе…ҙи¶Јзҡ„жңӢеҸӢеҸҜд»ҘеҸӮиҖғдёӢпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« д№ӢеҗҺеӨ§жңү收иҺ·пјҢдёӢйқўи®©е°Ҹзј–еёҰзқҖеӨ§е®¶дёҖиө·дәҶи§ЈдёҖдёӢгҖӮ
жҹҗеӨ§еёҲжӣҫиҜҙиҝҮпјҢеғҸдәҶи§ЈиҮӘе·ұзҡ„иҖҒе©Ҷ дёҖж ·дәҶи§ЈиҮӘе·ұз®ЎзҗҶзҡ„ж•°жҚ®еә“пјҢдёӘдәәи®ӨдёәеҢ…еҗ«дәҶдёӨдёӘж–№йқўзҡ„дәҶи§Јпјҡ
1пјҢеңЁзЁіе®ҡжҖ§еұӮйқўжқҘиҜҙпјҢжӣҙеӨҡзҡ„жҳҜе…іжіЁй«ҳеҸҜз”ЁгҖҒиҜ»еҶҷеҲҶзҰ»гҖҒиҙҹиҪҪеқҮиЎЎпјҢзҒҫеӨҮз®ЎзҗҶзӯүзӯүhigh levelеұӮйқўзҡ„жҺӘж–ҪпјҲе°ұеҘҪжҜ”иҰҒдҝқиҜҒз”ҹжҙ»зҡ„зЁіе®ҡжҖ§пјү
2пјҢеңЁе®һдҫӢзә§еҲ«зҡ„жқҘиҜҙпјҢйңҖиҰҒе…іжіЁеҶ…еӯҳгҖҒIOгҖҒзҪ‘з»ңпјҢзғӯзӮ№иЎЁпјҢзғӯзӮ№зҙўеј•пјҢtop sqlпјҢжӯ»й”ҒпјҢйҳ»еЎһпјҢеҺҶеҸІдёҠжү§иЎҢејӮеёёзҡ„SQLпјҲеҘҪжҜ”з”ҹжҙ»е“ҒиҙЁз»ҶиҠӮпјүMySQLзҡ„performance_dataеә“е’Ңsysеә“жҸҗдҫӣдәҶйқһеёёдё°еҜҢзҡ„зі»з»ҹж—Ҙеҝ—ж•°жҚ®пјҢеҸҜд»Ҙеё®еҠ©жҲ‘们жӣҙеҘҪең°дәҶи§Јйқһеёёз»ҶиҠӮзҡ„пјҢиҝҷйҮҢз®ҖеҚ•ең°еҲ—дёҫеҮәжқҘдәҶдёҖдәӣеёёз”Ёзҡ„ж•°жҚ®гҖӮ
sysеә“жҳҜд»ҘиҫғдёәеҸҜиҜ»еҢ–зҡ„ж–№ејҸе°ҒиЈ…дәҶperformance_dataдёӯзҡ„жҹҗдәӣиЎЁпјҢеӣ жӯӨиҝҷдәӣдёӘж•°жҚ®жқҘжәҗиҝҳжҳҜperformance_dataеә“дёӯзҡ„ж•°жҚ®гҖӮ
иҝҷйҮҢзІ—з•ҘеҲ—дёҫеҮәдёӘдәәеёёз”Ёзҡ„дёҖдәӣзі»з»ҹж•°жҚ®пјҢеҸҜд»ҘеңЁе®һдҫӢзә§еҲ«жӣҙеҠ жё…жҘҡең°дәҶи§ЈMySQLзҡ„иҝҗиЎҢиҝҮзЁӢдёӯиө„жәҗеҲҶй…Қжғ…еҶөгҖӮ
Statusдёӯзҡ„дҝЎжҒҜ
MySQLзҡ„statusеҸҳйҮҸеҸӘжҳҜз»ҷеҮәдәҶдёҖдёӘжҖ»зҡ„дҝЎжҒҜпјҢд»ҺstatusеҸҳйҮҸдёҠж— жі•еҫ—зҹҘиҜҰз»Ҷиө„жәҗзҡ„ж¶ҲиҖ—пјҢжҜ”еҰӮIOжҲ–иҖ…еҶ…еӯҳзҡ„зғӯзӮ№еңЁе“ӘйҮҢпјҢеә“гҖҒиЎЁзҡ„зғӯзӮ№еңЁе“ӘйҮҢпјҢеҰӮжһңжғіиҰҒзҹҘйҒ“е…·дҪ“зҡ„жҳҺз»ҶдҝЎжҒҜе°ұйңҖиҰҒзі»з»ҹеә“дёӯзҡ„ж•°жҚ®гҖӮ
еүҚжҸҗиҰҒејҖеҗҜperformance_schemaпјҢеӣ дёәsysеә“зҡ„и§ҶеӣҫжҳҜеҹәдәҺperformance_schemaзҡ„еә“зҡ„гҖӮ
еҶ…еӯҳдҪҝз”Ёпјҡ
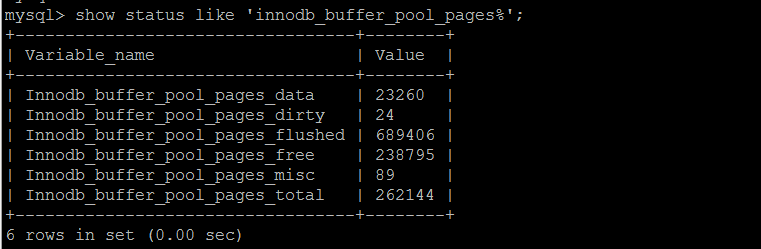
еҶ…еӯҳ/innodb_buffer_poolдҪҝз”Ё
жҰӮиҰҒinnodb_buffer_poolзҡ„дҪҝз”Ёжғ…еҶөsummaryпјҢе·ІзҹҘеҪ“еүҚе®һдҫӢ262144*16/1024 = 4096MB buffer pool,е·ІдҪҝз”Ё23260*16/1024 363MB
innodb_buffer_poolе·ІеҚ з”ЁеҶ…еӯҳзҡ„жҳҺз»ҶдҝЎжҒҜпјҢеҸҜд»ҘжҢүз…§еә“\иЎЁзҡ„з»ҙеәҰжқҘз»ҹи®Ў
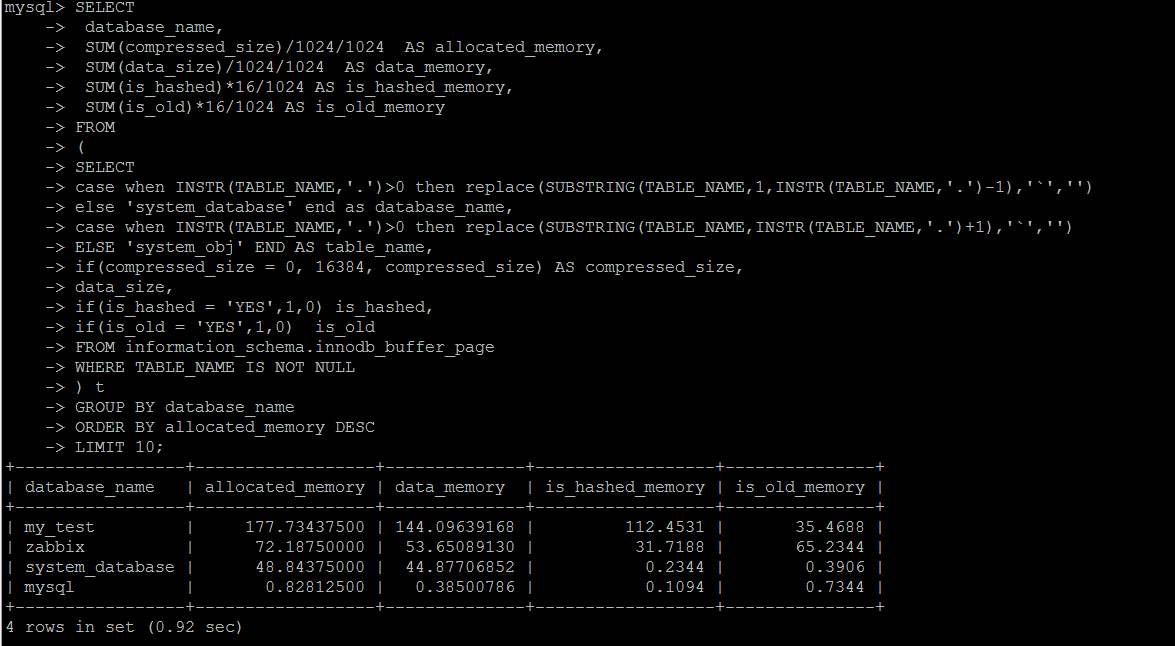
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED ; SELECT database_name, SUM(compressed_size)/1024/1024 AS allocated_memory, SUM(data_size)/1024/1024 AS data_memory, SUM(is_hashed)*16/1024 AS is_hashed_memory, SUM(is_old)*16/1024 AS is_old_memory FROM ( SELECT case when INSTR(TABLE_NAME,'.')>0 then replace(SUBSTRING(TABLE_NAME,1,INSTR(TABLE_NAME,'.')-1),'`','') else 'system_database' end as database_name, case when INSTR(TABLE_NAME,'.')>0 then replace(SUBSTRING(TABLE_NAME,INSTR(TABLE_NAME,'.')+1),'`','') ELSE 'system_obj' END AS table_name, if(compressed_size = 0, 16384, compressed_size) AS compressed_size, data_size, if(is_hashed = 'YES',1,0) is_hashed, if(is_old = 'YES',1,0) is_old FROM information_schema.innodb_buffer_page WHERE TABLE_NAME IS NOT NULL ) t GROUP BY database_name ORDER BY allocated_memory DESC LIMIT 10;
еә“\иЎЁзҡ„иҜ»еҶҷз»ҹи®ЎпјҢйҖ»иҫ‘еұӮйқўзҡ„зғӯзӮ№ж•°жҚ®з»ҹи®Ў
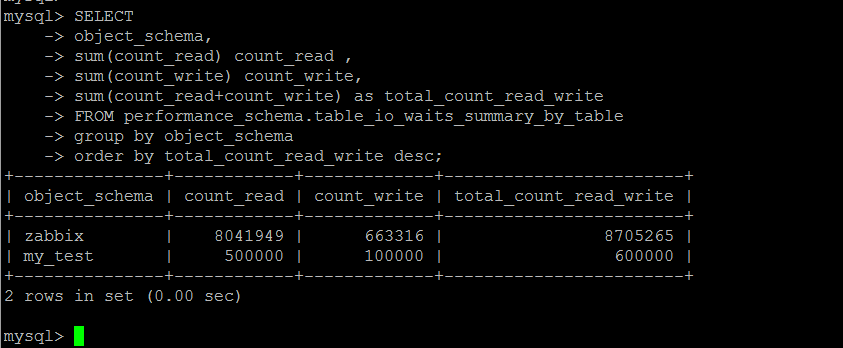
зӣ®ж ҮиЎЁжҳҜperformance_schema.table_io_waits_summary_by_tableпјҢжҹҗдәӣж–Үз« дёҠиҜҙжҳҜйҖ»иҫ‘IOпјҢе…¶е®һиҝҷйҮҢи·ҹйҖ»иҫ‘IOе№¶ж— е…ізі»пјҢиҝҷдёӘиЎЁдёӯзҡ„еӯ—ж®өеҗ«д№үжҳҜеҹәдәҺиЎЁпјҢиҜ»еҶҷзҡ„еҲ°зҡ„иЎҢж•°зҡ„з»ҹи®ЎгҖӮиҮідәҺзңҹжӯЈзҡ„йҖ»иҫ‘IOеұӮйқўзҡ„з»ҹи®ЎпјҢ笔иҖ…зӣ®еүҚиҝҳжңүдёҚзҹҘйҒ“жңүе“ӘдёӘеҸҜз”Ёзҡ„зі»з»ҹиЎЁжқҘжҹҘиҜўгҖӮиҝҷдёӘеә“еҸҜд»ҘеҫҲжё…жҘҡең°зңӢеҲ°иҝҷдёӘиЎЁдёӯзҡ„з»ҹи®Ўз»“жһңжҳҜжҖҺд№Ҳи®Ўз®—еҮәжқҘзҡ„гҖӮ
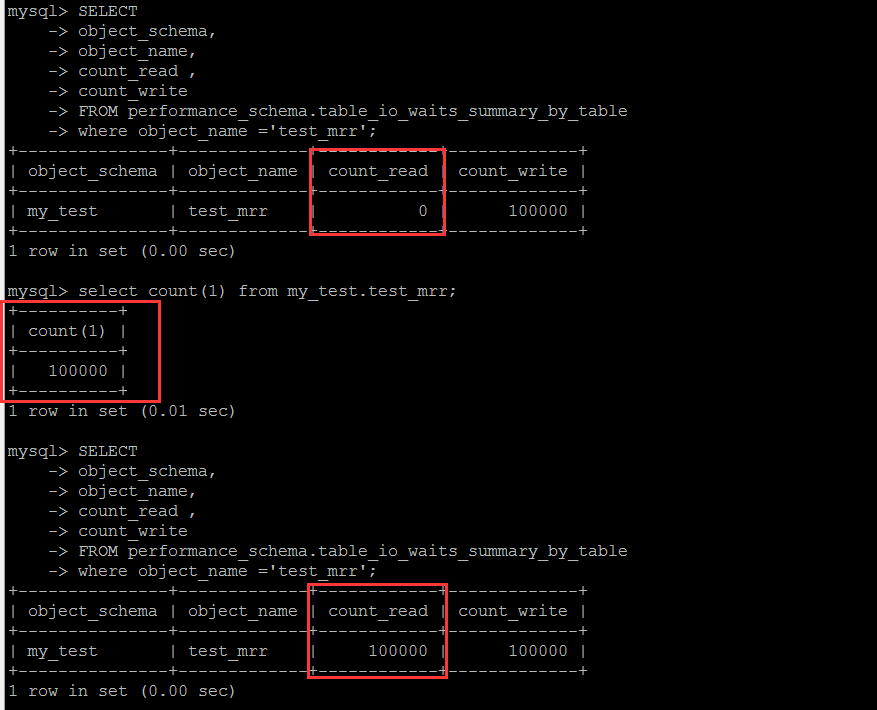
еҹәдәҺиЎЁзҡ„иҜ»еҶҷзҡ„иЎҢзҡ„ж¬Ўж•°з»ҹи®ЎпјҢиҝҷжҳҜдёҖдёӘзҙҜи®ЎеҖјпјҢеҚ•зәҜзҡ„зңӢиҝҷдёӘеҖјжң¬иә«пјҢдёӘдәәи§үеҫ—ж„Ҹд№үдёҚеӨ§пјҢйңҖиҰҒе®ҡ时收йӣҶи®Ўз®—е·®еҖјпјҢжүҚе…·еӨҮеҸӮиҖғж„Ҹд№үгҖӮ
д»ҘдёӢжҢүз…§еә“зә§еҲ«з»ҹи®ЎиЎЁзҡ„иҜ»еҶҷжғ…еҶөгҖӮ
еә“\иЎЁзҡ„иҜ»еҶҷз»ҹи®ЎпјҢзү©зҗҶIOеұӮйқўзҡ„зғӯзӮ№ж•°жҚ®з»ҹи®Ў
жҢүз…§зү©зҗҶIOзҡ„з»ҙеәҰз»ҹи®ЎзғӯзӮ№ж•°жҚ®пјҢе“Әдәӣеә“\иЎЁж¶ҲиҖ—дәҶеӨҡе°‘зү©зҗҶIOгҖӮиҝҷйҮҢеҺҹе§Ӣзі»з»ҹиЎЁдёӯзҡ„ж•°жҚ®жҳҜдёҖдёӘзҙҜи®Ўз»ҹи®Ўзҡ„еҖјпјҢжңҖжһҒз«Ҝзҡ„жғ…еҶөе°ұжҳҜдёҖдёӘиЎЁдёә0иЎҢпјҢеҚҙеӯҳеңЁеӨ§йҮҸзҡ„зү©зҗҶиҜ»еҶҷIOгҖӮ
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED ; SELECT database_name, IFNULL(cast(sum(total_read) as signed),0) AS total_read, IFNULL(cast(sum(total_written) as signed),0) AS total_written, IFNULL(cast(sum(total) AS SIGNED),0) AS total_read_written FROM ( SELECT substring(REPLACE(file, '@@datadir/', ''),1,instr(REPLACE(file, '@@datadir/', ''),'/')-1) AS database_name, count_read, case when instr(total_read,'KiB')>0 then replace(total_read,'KiB','')/1024 when instr(total_read,'MiB')>0 then replace(total_read,'MiB','')/1024 when instr(total_read,'GiB')>0 then replace(total_read,'GiB','')*1024 END AS total_read, case when instr(total_written,'KiB')>0 then replace(total_written,'KiB','')/1024 when instr(total_written,'MiB')>0 then replace(total_written,'MiB','') when instr(total_written,'GiB')>0 then replace(total_written,'GiB','')*1024 END AS total_written, case when instr(total,'KiB')>0 then replace(total,'KiB','')/1024 when instr(total,'MiB')>0 then replace(total,'MiB','') when instr(total,'GiB')>0 then replace(total,'GiB','')*1024 END AS total from sys.io_global_by_file_by_bytes WHERE FILE LIKE '%@@datadir%' AND instr(REPLACE(file, '@@datadir/', ''),'/')>0 )t GROUP BY database_name ORDER BY total_read_written DESC;
psпјҡдёӘдәәдёҚеӨӘе–ңж¬ўMySQLиҮӘе®ҡд№үзҡ„format_***еҮҪж•°пјҢиҝҷдёӘеҮҪж•°зҡ„еҲқиЎ·жҳҜеҘҪзҡ„пјҢжҠҠдёҖдәӣж•°жҚ®пјҲж—¶й—ҙпјҢеӯҳеӮЁз©әй—ҙпјүзӯүж јејҸеҢ–жҲҗжӣҙеҠ еҸҜиҜ»зҡ„жЁЎејҸгҖӮдҪҶжҳҜеҚҙдёҚж”ҜжҢҒеҚ•дҪҚзҡ„еҸӮж•°пјҢжӣҙеӨҡзҡ„ж—¶еҖҷжғід»ҘжҹҗдёӘеӣәе®ҡзҡ„еҚ•дҪҚжқҘжҳҫзӨәпјҢжҜ”еҰӮж јејҸеҢ–дёҖдёӘзҡ„ж—¶й—ҙпјҢж јејҸеҢ–еҗҺж №жҚ®еҚ•дҪҚеӨ§е°ҸеҸҜиғҪдјҡжҳҫзӨәеҫ®еҰҷпјҢжҲ–иҖ…жҳҜжҜ«з§’пјҢжҲ–иҖ…жҳҜз§’пјҢжҲ–иҖ…еҲҶй’ҹпјҢжҲ–иҖ…еӨ©гҖӮжҜ”еҰӮжғіжҠҠж—¶й—ҙз»ҹдёҖж јејҸеҢ–жҲҗз§’пјҢеҜ№дёҚиө·пјҢдёҚж”ҜжҢҒпјҢжҹҗдәӣдёӘж•°жҚ®дёҚд»…д»…жҳҜзңӢдёҖзңјйӮЈд№Ҳз®ҖеҚ•пјҢз”ҡиҮіжҳҜиҰҒиҜ»еҮәжқҘеӯҳжЎЈеҲҶжһҗзҡ„пјҢеӣ жӯӨиҝҷйҮҢдёҚе»әи®®д№ҹдёҚдјҡдҪҝз”ЁйӮЈдәӣдёӘformatеҮҪж•°
TOP SQL з»ҹи®Ў
еҸҜд»ҘжҢүз…§жү§иЎҢж—¶й—ҙпјҢйҳ»еЎһж—¶й—ҙпјҢиҝ”еӣһиЎҢж•°зӯүзӯүз»ҙеәҰз»ҹи®Ўtop sqlгҖӮ
еҸҰеӨ–еҸҜд»ҘжҢүз…§ж—¶й—ҙзӯӣйҖүlast_seenпјҢеҸҜд»Ҙз»ҹи®ЎжңҖиҝ‘жҹҗдёҖж®өж—¶й—ҙеҮәзҺ°иҝҮзҡ„top sql
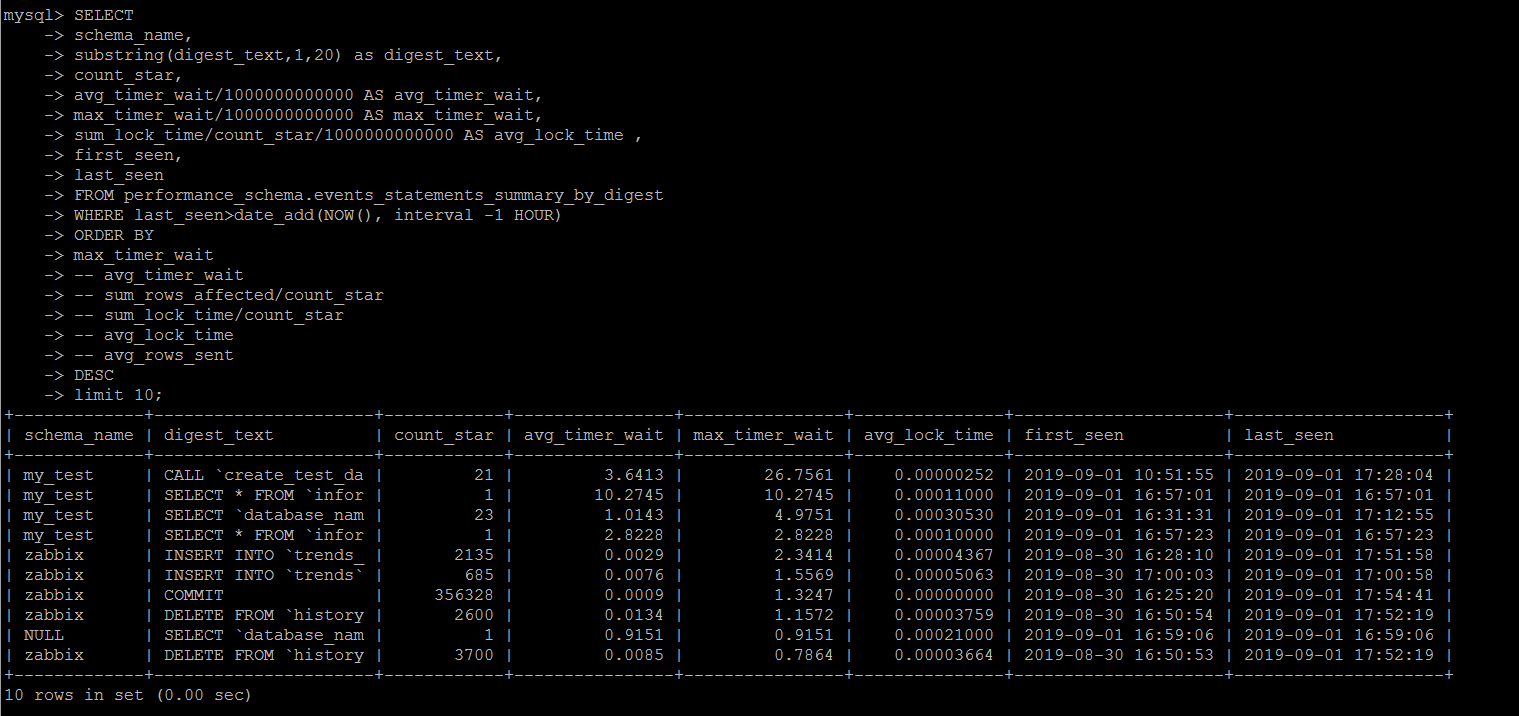
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED ; SELECT schema_name, digest_text, count_star, avg_timer_wait/1000000000000 AS avg_timer_wait, max_timer_wait/1000000000000 AS max_timer_wait, sum_lock_time/count_star/1000000000000 AS avg_lock_time , sum_rows_affected/count_star AS avg_rows_affected, sum_rows_sent/count_star AS avg_rows_sent , sum_rows_examined/count_star AS avg_rows_examined, sum_created_tmp_disk_tables/count_star AS avg_create_tmp_disk_tables, sum_created_tmp_tables/count_star AS avg_create_tmp_tables, sum_select_full_join/count_star AS avg_select_full_join, sum_select_full_range_join/count_star AS avg_select_full_range_join, sum_select_range/count_star AS avg_select_range, sum_select_range_check/count_star AS avg_select_range, first_seen, last_seen FROM performance_schema.events_statements_summary_by_digest WHERE last_seen>date_add(NOW(), interval -1 HOUR) ORDER BY max_timer_wait -- avg_timer_wait -- sum_rows_affected/count_star -- sum_lock_time/count_star -- avg_lock_time -- avg_rows_sent DESC limit 10;
йңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢиҝҷдёӘз»ҹи®ЎжҳҜжҢүз…§MySQLжү§иЎҢдёҖдёӘдәӢеҠЎж¶ҲиҖ—зҡ„иө„жәҗеҒҡз»ҹи®Ўзҡ„пјҢиҖҢдёҚжҳҜдёҖдёӘиҜӯеҸҘпјҢ笔иҖ…дёҖејҖе§ӢжҮөйҖјдәҶдёҖйҳөеӯҗпјҢдёҫдёӘз®ҖеҚ•зҡ„дҫӢеӯҗгҖӮ
еҸӮиҖғеҰӮдёӢпјҢиҝҷйҮҢжҳҜеҫӘзҺҜеҶҷдёӘж•°жҚ®зҡ„дёҖдёӘеӯҳеӮЁиҝҮзЁӢпјҢи°ғз”Ёж–№ејҸе°ұжҳҜcall create_test_data(N)пјҢеҶҷе…ҘNжқЎжөӢиҜ•ж•°жҚ®гҖӮ
жҜ”еҰӮcall create_test_data(1000000)е°ұжҳҜеҶҷе…Ҙ100Wзҡ„жөӢиҜ•ж•°жҚ®пјҢиҝҷдёӘжү§иЎҢиҝҮзЁӢиҖ—иҙ№дәҶеҮ еҲҶй’ҹзҡ„ж—¶й—ҙпјҢжҢү照笔иҖ…зҡ„жөӢиҜ•е®һдҫӢжғ…еҶөпјҢavg_timer_waitзҡ„з»ҙеәҰпјҢз»қеҜ№жҳҜдёҖдёӘTOP SQLгҖӮ
дҪҶжҳҜеңЁжҹҘиҜўзҡ„ж—¶еҖҷпјҢе§Ӣз»ҲжІЎжңүеҸ‘зҺ°иҝҷдёӘеӯҳеӮЁиҝҮзЁӢзҡ„и°ғз”Ёиў«еҲ—дёәTOP SQLпјҢеҗҺйқўе°қиҜ•еңЁеӯҳеӮЁиҝҮзЁӢеҶ…йғЁеҠ дәҶдёҖдёӘдәӢзү©пјҢ然еҗҺе°ұйЎәеҲ©ең°ж”¶йӣҶеҲ°дәҶж•ҙдёӘTOP SQL.
еӣ жӯӨиҜҙperformance_schema.events_statements_summary_by_digestйҮҢйқўзҡ„з»ҹи®ЎпјҢжҳҜеҹәдәҺдәӢеҠЎзҡ„пјҢиҖҢдёҚжҳҜжҹҗдёҖдёӘжү№еӨ„зҗҶзҡ„жү§иЎҢж—¶й—ҙзҡ„гҖӮ
CREATE DEFINER=`root`@`%` PROCEDURE `create_test_data`( IN `loopcnt` INT ) LANGUAGE SQL NOT DETERMINISTIC CONTAINS SQL SQL SECURITY DEFINER COMMENT '' BEGIN -- START TRANSACTION; while loopcnt>0 do insert into test_mrr(rand_id,create_date) values (RAND()*100000000,now(6)); set loopcnt=loopcnt-1; end while; -- commit; END
еҸҰеӨ–дёҖзӮ№жҜ”иҫғжңүж„ҸжҖқзҡ„жҳҜпјҢиҝҷдёӘзі»з»ҹиЎЁжҳҜдёәж•°дёҚеӨҡзҡ„ж”ҜжҢҒtruncateзҡ„пјҢеҪ“然е®ғеңЁеҶ…йғЁпјҢд№ҹжҳҜеңЁдёҚж–ӯ收йӣҶзҡ„дёҖдёӘиҝҮзЁӢгҖӮ
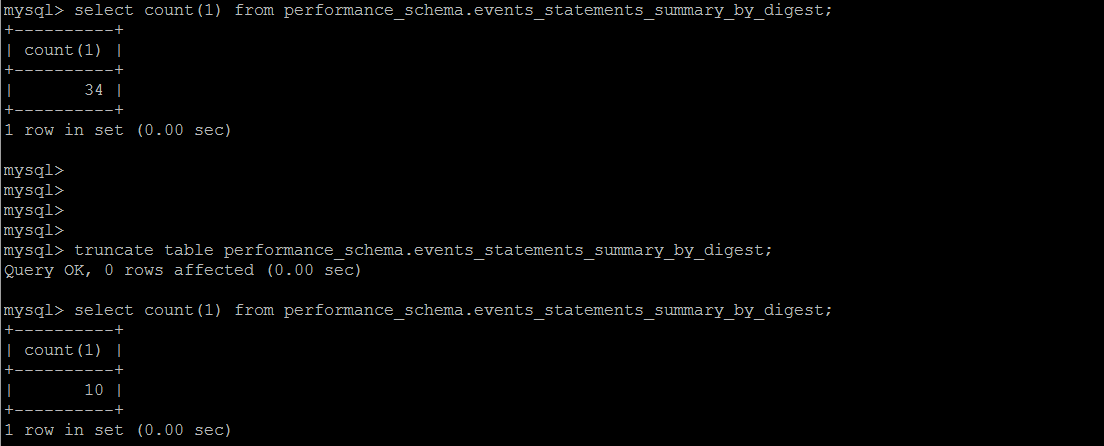
жү§иЎҢеӨұиҙҘзҡ„SQL з»ҹи®Ў
дёҖзӣҙд»Ҙдёәзі»з»ҹдёҚдјҡи®°еҪ•жү§иЎҢеӨұиҙҘзҡ„\и§Јжһҗй”ҷиҜҜзҡ„SQLпјҢжҜ”еҰӮжғіз»ҹи®Ўеӣ дёәи¶…ж—¶иҖҢжү§иЎҢеӨұиҙҘзҡ„иҜӯеҸҘпјҢеҗҺйқўжүҚеҸ‘зҺ°пјҢиҝҷдәӣдҝЎжҒҜпјҢMySQLдјҡе®Ңж•ҙең°и®°еҪ•дёӢжқҘ
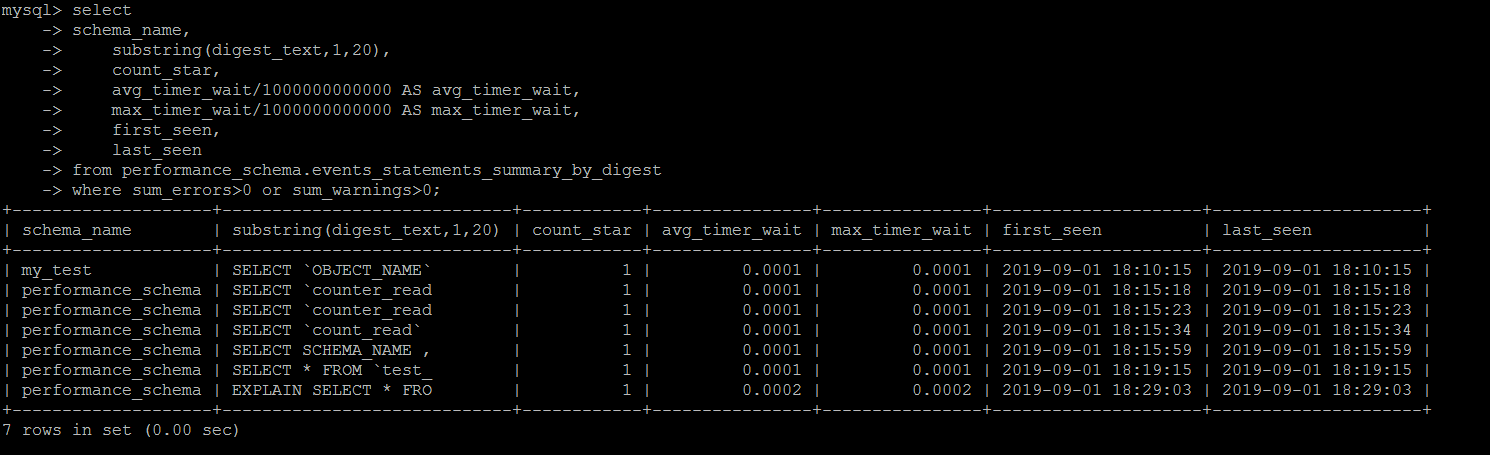
иҝҷйҮҢдјҡиҜҰз»Ҷи®°еҪ•жү§иЎҢй”ҷиҜҜзҡ„иҜӯеҸҘпјҢеҢ…жӢ¬жңҖз»Ҳжү§иЎҢеӨұиҙҘпјҲи¶…ж—¶д№Ӣзұ»зҡ„пјүпјҢиҜӯжі•й”ҷиҜҜпјҢжү§иЎҢиҝҮзЁӢдёӯдә§з”ҹдәҶиӯҰе‘Ҡд№Ӣзұ»зҡ„иҜӯеҸҘгҖӮз”Ёsum_errors>0 or sum_warnings>0еҺ»performance_schema.events_statements_summary_by_digestзӯӣйҖүдёҖдёӢеҚіеҸҜгҖӮ
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED ; select schema_name, digest_text, count_star, first_seen, last_seen from performance_schema.events_statements_summary_by_digest where sum_errors>0 or sum_warnings>0 order by last_seen desc;
IndexдҪҝз”Ёжғ…еҶөз»ҹи®Ў
еҹәдәҺperformance_schema.table_io_waits_summary_by_index_usageиҝҷдёӘзі»з»ҹиЎЁпјҢе…¶з»ҹи®Ўзҡ„з»ҙеәҰеҗҢж ·жҳҜвҖңжҢүз…§жҹҗдёӘзҙўеј•жҹҘиҜўиҝ”еӣһзҡ„иЎҢж•°зҡ„з»ҹи®ЎвҖқгҖӮ
еҸҜд»ҘжҢүз…§е“Әдәӣзҙўеј•дҪҝз”ЁжңҖеӨҡ\жңҖе°‘зӯүжғ…еҶөиҝӣиЎҢз»ҹи®ЎгҖӮ
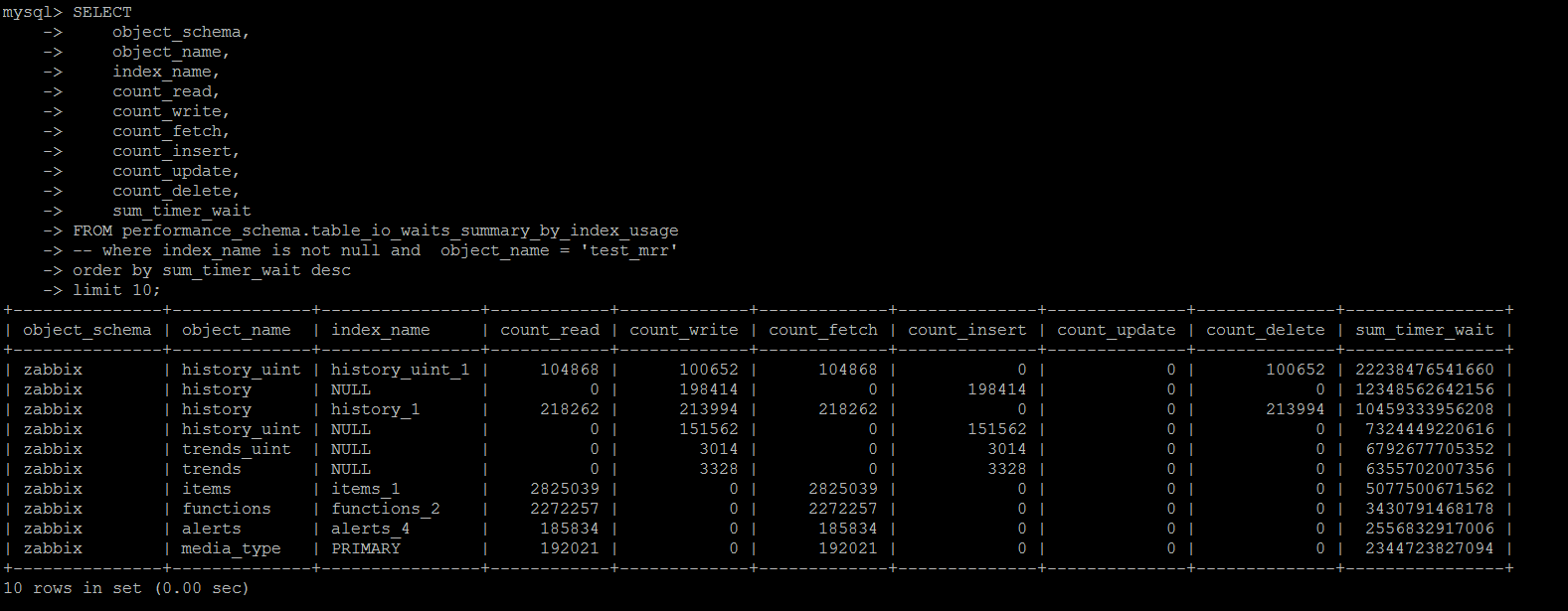
дёҚиҝҮиҝҷдёӘз»ҹи®ЎжңүдёҖдёӘз»ҷдәәжҪңеңЁдёҖдёӘиҜҜеҢәпјҡcount_read,count_write,count_fetch,count_insert,count_update,count_deleteз»ҹи®ЎдәҶжҹҗдёӘзҙўеј•дёҠдҪҝз”ЁеҲ°зҙўеј•зҡ„жғ…еҶөдёӢпјҢеҸ—еҪұе“Қзҡ„иЎҢж•°пјҢsum_timer_waitжҳҜзҙҜи®ЎеңЁиҜҘзҙўеј•дёҠзӯүеҫ…зҡ„ж—¶й—ҙгҖӮ
еҰӮжһңдҪҝз”ЁеҲ°дәҶиҜҘзҙўеј•пјҢдҪҶжҳҜжІЎжңүж•°жҚ®еҸ—еҪұе“ҚпјҲе°ұжҳҜжІЎжңүDMLиҜӯеҸҘзҡ„жқЎд»¶жІЎжңүе‘Ҫдёӯж•°жҚ®пјүпјҢе°Ҷcount_***дёҚдјҡз»ҹи®ЎиҝӣжқҘпјҢдҪҶжҳҜsum_timer_waitдјҡз»ҹи®ЎиҝӣжқҘ
иҝҷе°ұеӯҳеңЁдёҖдёӘе®№жҳ“еҸ—еҲ°иҜҜеҜјзҡ„ең°ж–№пјҢиҝҷдёӘзҙўеј•жҳҺжҳҺжІЎжңүе‘ҪдёӯиҝҮеҫҲеӨҡж¬ЎпјҢдҪҶжҳҜеҚҙдә§з”ҹдәҶеӨ§йҮҸзҡ„timer_waitпјҢзҙўеј•зңӢеҲ°зұ»дјјзҡ„дҝЎжҒҜпјҢд№ҹдёҚиғҪиҙёз„¶еҲ йҷӨзҙўеј•гҖӮ
зӯүеҫ…дәӢ件з»ҹи®Ў
MySQLж•°жҚ®еә“дёӯзҡ„д»»дҪ•дёҖдёӘеҠЁдҪңпјҢйғҪйңҖиҰҒзӯүеҫ…пјҲдёҖе®ҡзҡ„ж—¶й—ҙжқҘе®ҢжҲҗпјүпјҢдёҖе…ұжңүи¶…иҝҮ1000дёӘзӯүеҫ…дәӢ件пјҢеҲҶеұһдёҚжҮӮзҡ„зұ»еҲ«пјҢжҜҸдёӘзүҲжң¬йғҪдёҚдёҖж ·пјҢдё”й»ҳи®ӨдёҚжҳҜжүҖжңүзҡ„зӯүеҫ…дәӢ件йғҪеҗҜз”ЁгҖӮ
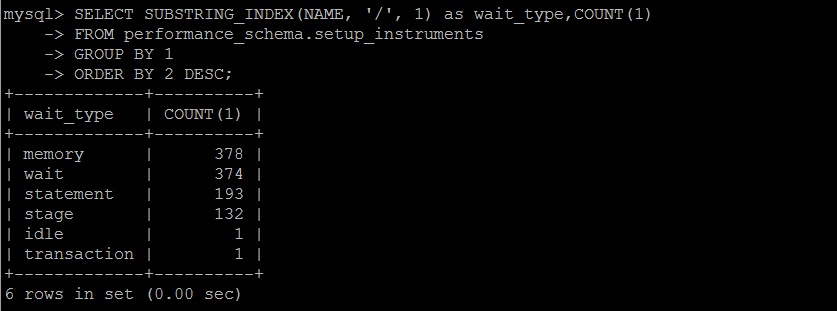
дёӘдәәи®Өдёәзӯүеҫ…дәӢ件иҝҷдёӘдёңиҘҝпјҢд»…еҒҡеҸӮиҖғпјҢдёҚе…·еӨҮй—®йўҳзҡ„иҜҠж–ӯжҖ§пјҢеҚідҫҝжҳҜеҶҚдјҳеҢ–жҲ–иҖ…дҪҺиҙҹиҪҪзҡ„ж•°жҚ®еә“пјҢзҙҜи®ЎдёҖж®өж—¶й—ҙпјҢжҹҗдәӣдәӢ件д»Қж—§дјҡз§ҜзҙҜеӨ§йҮҸзҡ„зӯүеҫ…дәӢ件гҖӮ
иҝҷдәӣдәӢ件зҡ„зӯүеҫ…дәӢ件пјҢдёҚдёҖе®ҡйғҪжҳҜиҙҹйқўжҖ§зҡ„пјҢжҜ”еҰӮдәӢзү©зҡ„й”Ғзӯүеҫ…пјҢжҳҜеңЁе№¶еҸ‘жү§иЎҢиҝҮзЁӢдёӯеҝ…然дјҡз”ҹжҲҗзҡ„пјҢиҝҷдёӘзӯүеҫ…дәӢ件зҡ„з»ҹи®Ўз»“жһңпјҢд№ҹжҳҜзҙҜи®Ўзҡ„пјҢеҚ•зәҜзҡ„зңӢдёҖдёӘзӣҙжҺҘзҡ„еҖјпјҢдёҚе…·еӨҮд»»дҪ•еҸӮиҖғж„Ҹд№үгҖӮ
йҷӨйқһе®ҡжңҹ收йӣҶпјҢеҒҡе·®еҖји®Ўз®—пјҢж №жҚ®е®һйҷ…жғ…еҶөпјҢжүҚе…·еӨҮеҸӮиҖғж„Ҹд№үгҖӮ
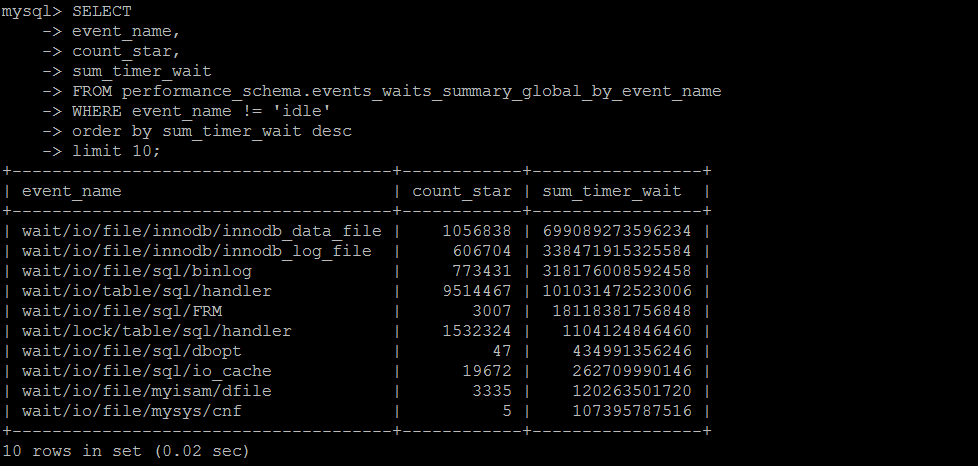
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED ; SELECT SUBSTRING_INDEX(NAME, '/', 1) as wait_type,COUNT(1) FROM performance_schema.setup_instruments GROUP BY 1 ORDER BY 2 DESC; SELECT event_name, count_star, sum_timer_wait FROM performance_schema.events_waits_summary_global_by_event_name WHERE event_name != 'idle' order by sum_timer_wait desc limit 100;
жңҖеҗҺпјҢйңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢ
1пјҢMySQLжҸҗдҫӣзҡ„иҜёеӨҡзҡ„зі»з»ҹиЎЁпјҲи§Ҷеӣҫпјүдёӯзҡ„ж•°жҚ®пјҢеҚ•зәҜзҡ„зңӢиҝҷдёӘеҖјжң¬иә«пјҢеӣ дёәе®ғжҳҜдёҖдёӘзҙҜи®ЎеҖјпјҢдёӘдәәи§үеҫ—ж„Ҹд№үдёҚеӨ§пјҢе°Өе…¶жҳҜavg_***пјҢйңҖиҰҒз»“еҗҲеӨҡж–№йқўзҡ„з»јеҗҲеӣ зҙ пјҢеҒҡеҸӮиҖғдҪҝз”ЁгҖӮ
2пјҢд»»дҪ•зі»з»ҹиЎЁзҡ„жҹҘиҜўпјҢйғҪеҸҜиғҪеҜ№зі»з»ҹжҖ§иғҪзҡ„жң¬иә«йҖ жҲҗдёҖе®ҡзҡ„еҪұе“ҚпјҢдёҚиҰҒеҶҚеҜ№зі»з»ҹеҸҜиғҪдә§з”ҹиҫғеӨ§иҙҹйқўеҪұе“Қзҡ„жғ…еҶөдёӢеҒҡж•°жҚ®зҡ„з»ҹ计收йӣҶгҖӮ
ж„ҹи°ўдҪ иғҪеӨҹи®Өзңҹйҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« пјҢеёҢжңӣе°Ҹзј–еҲҶдә«зҡ„вҖңеҰӮдҪ•дҪҝз”ЁMySQLзі»з»ҹж•°жҚ®еә“еҒҡжҖ§иғҪиҙҹиҪҪиҜҠж–ӯвҖқиҝҷзҜҮж–Үз« еҜ№еӨ§е®¶жңүеё®еҠ©пјҢеҗҢж—¶д№ҹеёҢжңӣеӨ§е®¶еӨҡеӨҡж”ҜжҢҒдәҝйҖҹдә‘пјҢе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢжӣҙеӨҡзӣёе…ізҹҘиҜҶзӯүзқҖдҪ жқҘеӯҰд№ !
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ